1. 目标
使用Glue同步AWS OpenSearch数据到Redshift。
2. 加载测试数据
AOS创建索引并写入:
curl -X POST -u 'xx:xxx' 'https://vpc-knn-4r272pshdggabtlhihabz7clba.ap-northeast-1.es.amazonaws.com/dot_common/_doc' \ -H 'Content-Type:application/json' \ -d '{ "accs_time": "1687883837862", "brower": "", "brower_version": "", "carrier": "TELKOMSEL", "city": "", "country": "ID", "countryCode": "ID", "ctime": 1687883840795, "event": "google-login", "ip": "192.168.1.6", "latitude": "", "longitude": "", "manufacturer": "OPPO", "metadata": { "action": "login", "transactionId":"1234567890" }, "model": "CPH1729", "networkType": "NETWORK_WIFI", "os": "7.1.1", "os_version": "25", "source": "Android" }'
3. spark代码
查看maven:
https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-spark-20
es 6.5的 spark connector 对应的版本是spark2。Spark3版本对应的es connector,最低版本为7.12版。
AOS 对应兼容版为7.10.2,所以下面以7.10.2为例
下载依赖:
wget https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-spark-20_2.11/7.10.2/elasticsearch-spark-20_2.11-7.10.2.jar wget https://repo1.maven.org/maven2/commons-httpclient/commons-httpclient/3.0.1/commons-httpclient-3.0.1.jar # redshift 依赖 wget https://repo1.maven.org/maven2/io/github/spark-redshift-community/spark-redshift_2.11/4.1.1/spark-redshift_2.11-4.1.1.jar # redshift jdbc wget https://repo1.maven.org/maven2/com/amazon/redshift/redshift-jdbc42/2.1.0.8/redshift-jdbc42-2.1.0.8.jar
pyspark shell测试:
# 启动shell pyspark --jars ./elasticsearch-spark-20_2.11-7.10.2.jar,commons-httpclient-3.0.1.jar,spark-redshift_2.11-4.1.1.jar \ --conf "spark.es.nodes=https://vpc-knn-xxxx.ap-northeast-1.es.amazonaws.com" \ --conf "spark.es.port=443" \ --conf "spark.es.nodes.wan.only=true" \ --conf "spark.es.net.ssl=true" \ --conf "spark.es.net.http.auth.user=xx" \ --conf "spark.es.net.http.auth.pass=xxx"
# 代码
from pyspark.sql.functions import explode # 读取ES数据 query = '{ "query": { "match_all": {} }}' esdata = spark.read.format("org.elasticsearch.spark.sql").option("es.query", query) df = esdata.load("dot_common") # metadata字段为struct,展开为列 explodeDF = df.withColumn("action", df.metadata.action).withColumn("transactionId", df.metadata.transactionId).drop(df.metadata) # 写入Redshift username = "tang" password = "xxxx" url = "jdbc:redshift://demo.xxxx.ap-northeast-1.redshift.amazonaws.com:5439/dev?user=" + username + "&password=" + password explodeDF.write. \ format("io.github.spark_redshift_community.spark.redshift"). \ option("aws_iam_role", "arn:aws:iam::xxxx:role/redshift-glue-s3-access-role"). \ option("url", url). \ option("dbtable", "demo_table"). \ option("tempformat", "CSV"). \ option("tempdir", "s3://xxx/tmp"). \ option("s3_endpoint","s3.ap-northeast-1.amazonaws.com"). \ mode("overwrite"). \ save()
Redshift内结果:

4. Glue运行
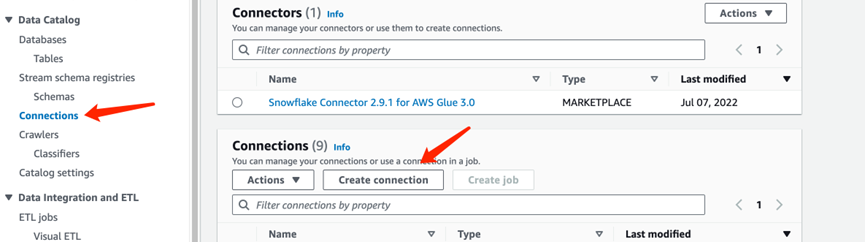
4.1. 创建到Redshift的Connection
创建此目的是为了让Glue可以在网络层连接到Redshift。
在Glue DataCatalog下的Connections里创建新的连接:
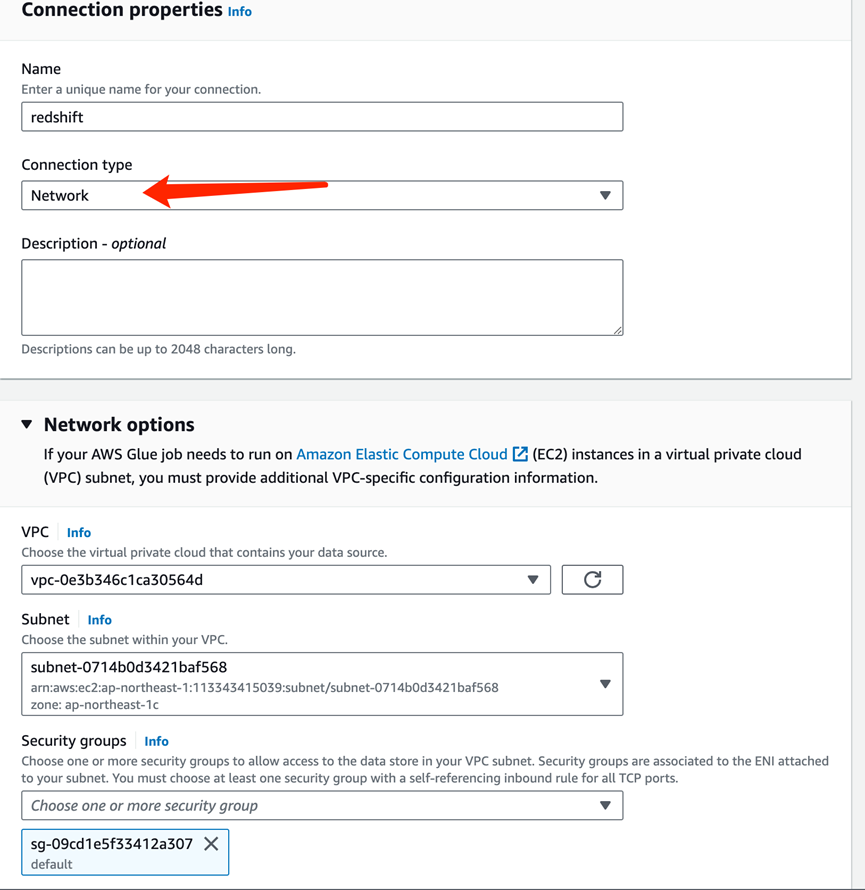
类型选择Network。vpc、子网与redshift属同一子网,同时redshift的安全组允许Glue安全组访问:
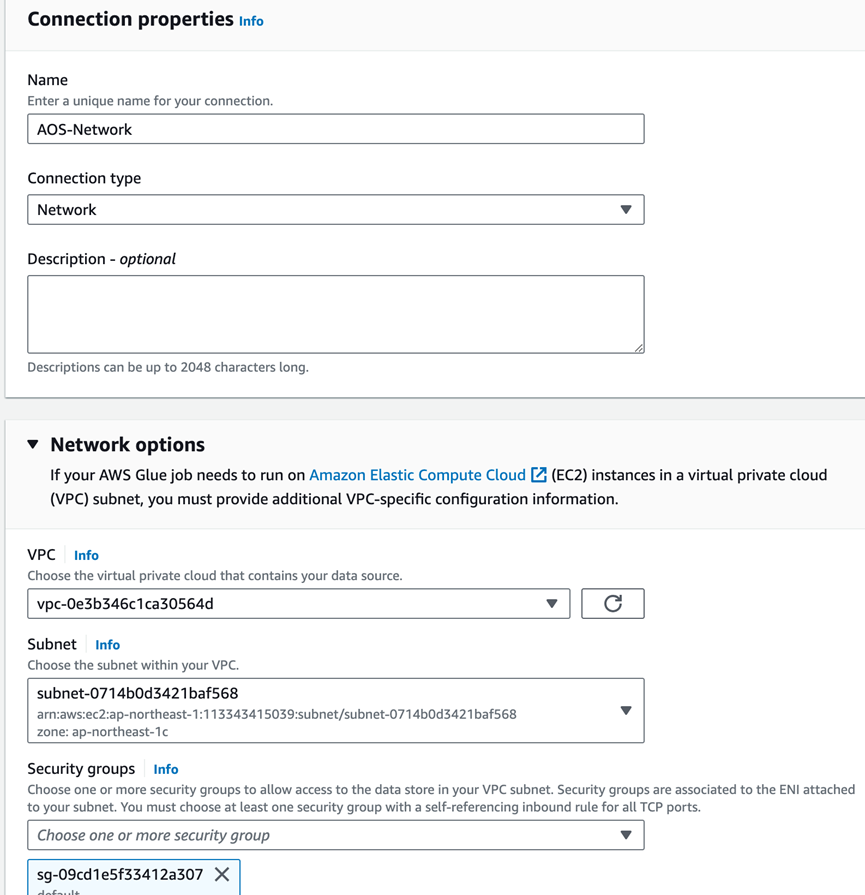
4.2. 创建到OpenSearch的连接
与上一步一样:
4.3. Glue 代码
Glue参考代码:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import explode ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) # 读取ES数据 query = '{ "query": { "match_all": {} }}' esdata = spark.read.format("org.elasticsearch.spark.sql") \ .option("es.nodes", "https://vpc-knn-xxxx.ap-northeast-1.es.amazonaws.com") \ .option("es.port","443") \ .option("es.nodes.wan.only", "true") \ .option("es.net.ssl", "true") \ .option("es.net.http.auth.user", "tang") \ .option("es.net.http.auth.pass", "xxx") \ .option("es.query", query)
df = esdata.load("dot_common") # metadata字段为struct,展开为列 explodeDF = df.withColumn("action", df.metadata.action).withColumn("transactionId", df.metadata.transactionId).drop(df.metadata) # 写入Redshift username = "tang" password = "xxx" url = "jdbc:redshift://demo.xxxx.ap-northeast-1.redshift.amazonaws.com:5439/dev?user=" + username + "&password=" + password explodeDF.write. \ format("io.github.spark_redshift_community.spark.redshift"). \ option("aws_iam_role", "arn:aws:iam::xxxx:role/redshift-glue-s3-access-role"). \ option("url", url). \ option("dbtable", "demo_table"). \ option("tempformat", "CSV"). \ option("tempdir", "s3://xxx/tmp"). \ option("s3_endpoint","s3.ap-northeast-1.amazonaws.com"). \ mode("overwrite"). \ save() job.commit()
4.4. Glue Job配置
Glue Job配置:
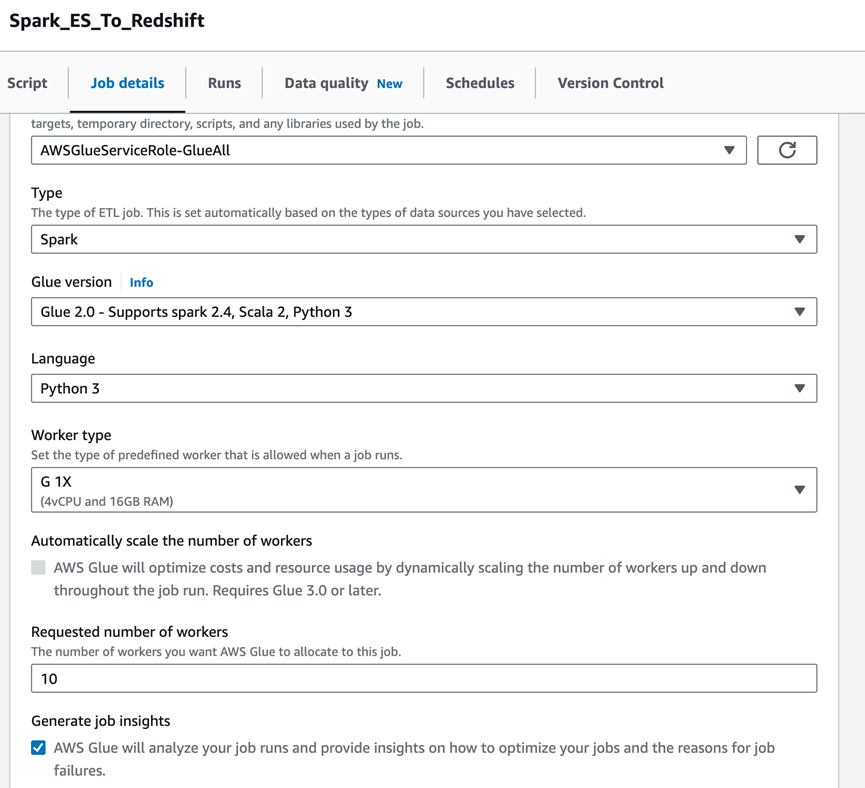
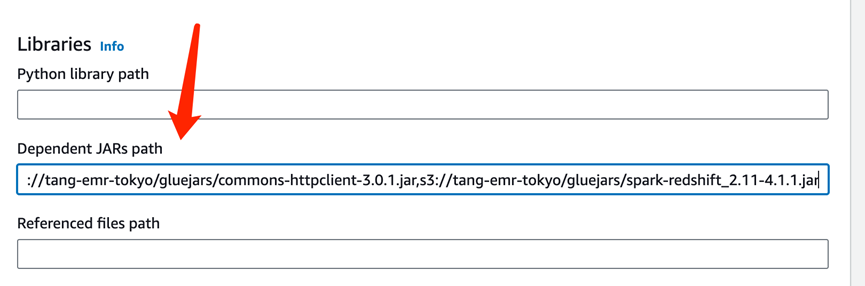
配置连接与依赖:
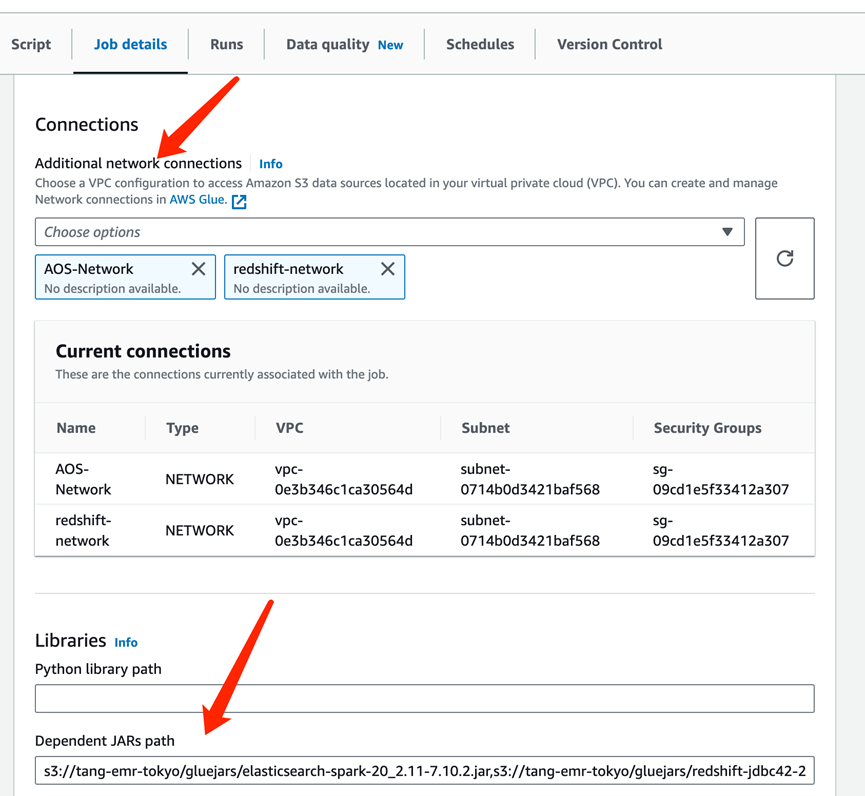
将前面使用到的jar上传到s3:elasticsearch-spark-20_2.11-7.10.2.jar,redshift-jdbc42-2.1.0.8.jar,commons-httpclient-3.0.1.jar,spark-redshift_2.11-4.1.1.jar
并在Glue Job里指定加入这些依赖(逗号隔开):