数据采集第四次实践作业
作业一
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
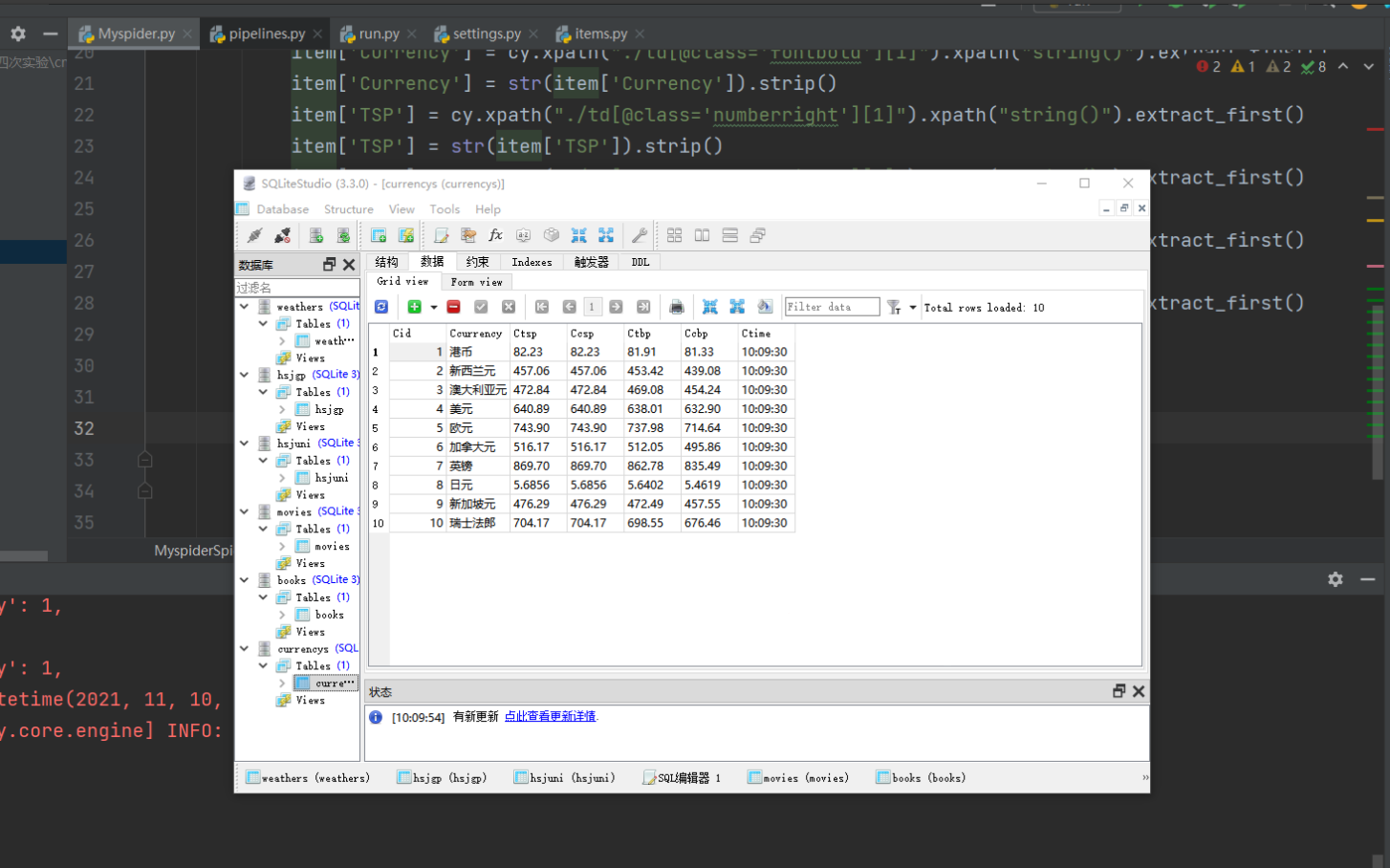
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接
部分代码如下:
data = response.text selector = scrapy.Selector(text=data) for cnt in range(2, 12): item = Item() cy = selector.xpath("//table[@class='data']/tr[%d]" % cnt) #序号 item['id'] = cnt - 1 #名称 item['Currency'] = cy.xpath("./td[@class='fontbold'][1]").xpath("string()").extract_first() item['Currency'] = str(item['Currency']).strip() #TSP item['TSP'] = cy.xpath("./td[@class='numberright'][1]").xpath("string()").extract_first() item['TSP'] = str(item['TSP']).strip() #CSP item['CSP'] = cy.xpath("./td[@class='numberright'][2]").xpath("string()").extract_first() item['CSP'] = str(item['CSP']).strip() #TBP item['TBP'] = cy.xpath("./td[@class='numberright'][3]").xpath("string()").extract_first() item['TBP'] = str(item['TBP']).strip() #CBP item['CBP'] = cy.xpath("./td[@class='numberright'][4]").xpath("string()").extract_first() item['CBP'] = str(item['CBP']).strip() #当前时间 item['time'] = cy.xpath("./td[8]").xpath("string()").extract_first() item['time'] = str(item['time']).strip() yield item cnt += 1
2.2.4 pipelines.py
首先编写数据库类,有打开数据库,插入数据,关闭数据库三种方法
`class CurrencyDB:
def openDB(self):
self.con = sqlite3.connect("currencys.db") #建立数据库链接,若没有对应数据库则创建
self.cursor = self.con.cursor() #建立游标
try:
self.cursor.execute("create table currencys "
"(Cid int(4),Ccurrency varchar(16),"
"Ctsp varchar(32),Ccsp varchar(64),"
"Ctbp varchar(32),Ccbp varchar(8),Ctime varchar(64))")
except:
self.cursor.execute("delete from currencys")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, Cid, Ccurrency, Ctsp, Ccsp, Ctbp, Ccbp, Ctime):
try:
self.cursor.execute("insert into currencys(Cid, Ccurrency, Ctsp, Ccsp, Ctbp, Ccbp, Ctime) values (?,?,?,?,?,?,?)",
(Cid, Ccurrency, Ctsp, Ccsp, Ctbp, Ccbp, Ctime))
except Exception as err:
print(err)`
结果:
作业二:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
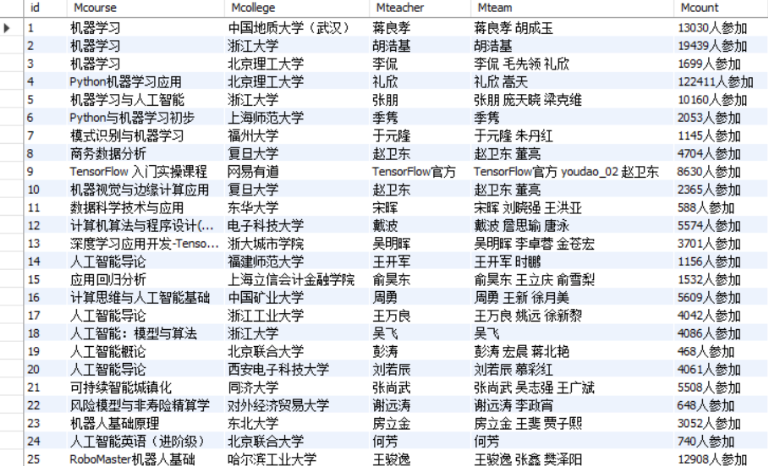
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接
代码如下:
`from time import daylight, sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import datetime
import time
from selenium.webdriver.common.keys import Keys
from lxml import etree
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
count = 1
def startUp(self,url):
# # Initializing Chrome browser
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host = "127.0.0.1",port = 3306,user = "root",passwd = "********",db = "mydb",charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("delete from stock") #如果表已经存在就删掉
self.opened = True
self.page_num = 1
except Exception as err:
print("连接数据库失败")
self.opened = False
self.driver.get(url)
#这里的search框用id属性显示定位不到
#1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)
#2.找到它老爸后,再找下个层级就能定位到了
#3.要是它老爸的属性也不是很明显
time.sleep(2)
accession = self.driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
# print(accession)
# time.sleep(3)
accession.click()
time.sleep(3)
#其它登入方式
other = self.driver.find_element_by_xpath('//div[@class="ux-login-set-scan-code_ft"]/span')
other.click()
time.sleep(5)
self.driver.switch_to.frame(self.driver.find_element_by_xpath("//iframe[starts-with(@id, 'x-URS-iframe')]"))
email = self.driver.find_element_by_xpath('//input[@name="email"]')
email.send_keys('2105114977@qq.com')
time.sleep(2)
pswd = self.driver.find_element_by_xpath('//input[@name="password"]')
pswd.send_keys('********')
time.sleep(2)
go = self.driver.find_element_by_xpath('//div[@class="f-cb loginbox"]/a')
go.click()
time.sleep(5)
search = self.driver.find_element_by_xpath('//div[@class="u-baseinputui"]/input[@type="text"]') #找到搜索的input框
time.sleep(3)
search.send_keys(key)
search.send_keys(Keys.ENTER)
def closeUp(self):
try:
if(self.opened):
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("爬取完毕,关闭数据库")
except Exception as err:
print("关闭数据库失败")
def insertDB(self,id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief):
try:
self.cursor.execute("insert into mooc(id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief) values (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief))
except Exception as err:
print("插入数据失败!",err)
def processSpider(self):
time.sleep(3)
print(self.driver.current_url)
div_list = self.driver.find_elements_by_xpath('//div[@class="m-course-list"]/div/div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
#print(len(div_list))
for div in div_list:
Mcourse = div.find_element_by_xpath('.//div[@class="t1 f-f0 f-cb first-row"]').text
Mcollege = div.find_element_by_xpath('.//a[@class="t21 f-fc9"]').text
Mteacher = div.find_element_by_xpath('.//a[@class="f-fc9"]').text
Mcount = div.find_element_by_xpath('.//span[@class="hot"]').text
#详情页,这里通过点击图片来实现
detail = div.find_element_by_xpath('.//div[@class="u-img f-fl"]')
detail.click()
time.sleep(2) #等待详情页面加载,准备爬取我们所需要的其它内容
windows = self.driver.window_handles #获取当前所有页面句柄
self.driver.switch_to.window(windows[1]) #切换到刚刚点击的新页面
teams = self.driver.find_elements_by_xpath('//div[@class="um-list-slider_con_item"]//h3[@class="f-fc3"]')
Mteam = ""
for team in teams:
Mteam = Mteam + team.text
if(team!=teams[-1]):
Mteam += " "
#print(Mteam) #测试团队爬取情况
Mprocess = self.driver.find_element_by_xpath('//div[@class="course-enroll-info_course-info_term-info"]//div[@class="course-enroll-info_course-info_term-info_term-time"]/span[2]').text
Mbrief = self.driver.find_element_by_xpath('//div[@class="course-heading-intro_intro"]').text
#print(Mprocess,Mbrief)
self.driver.close() #把详情页窗口关闭
self.driver.switch_to.window(windows[0]) #切换回最初的页面
#通过观察浏览器的行为,确实可以爬取到我们所需要的所有信息了,接下来只要把我们的数据存储到数据库即可
#print(self.count,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
self.insertDB(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
self.count += 1
#爬取完毕一个页面的数据了,这里就爬取2页的数据
#这题先找disable的话在第一页会先点击上一页
try:
next_button = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]//a[@class="th-bk-main-gh"]')
#print(next_button)
next_button.click()
time.sleep(2)
if(self.page_num<2):
self.page_num += 1
self.processSpider()
except:
self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]//a[@class="th-bk-disable-gh"]') #当前页面是否是最后一页
key = "机器学习"
url = "https://www.icourse163.org"
myspider = MySpider()
start = datetime.datetime.now()
myspider.startUp(url)
myspider.processSpider()
myspider.closeUp()
end = datetime.datetime.now()
print("一共爬取了"+str(myspider.count-1)+"条数据,"+"一共花费了"+str(end-start)+"的时间")`
结果:
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建
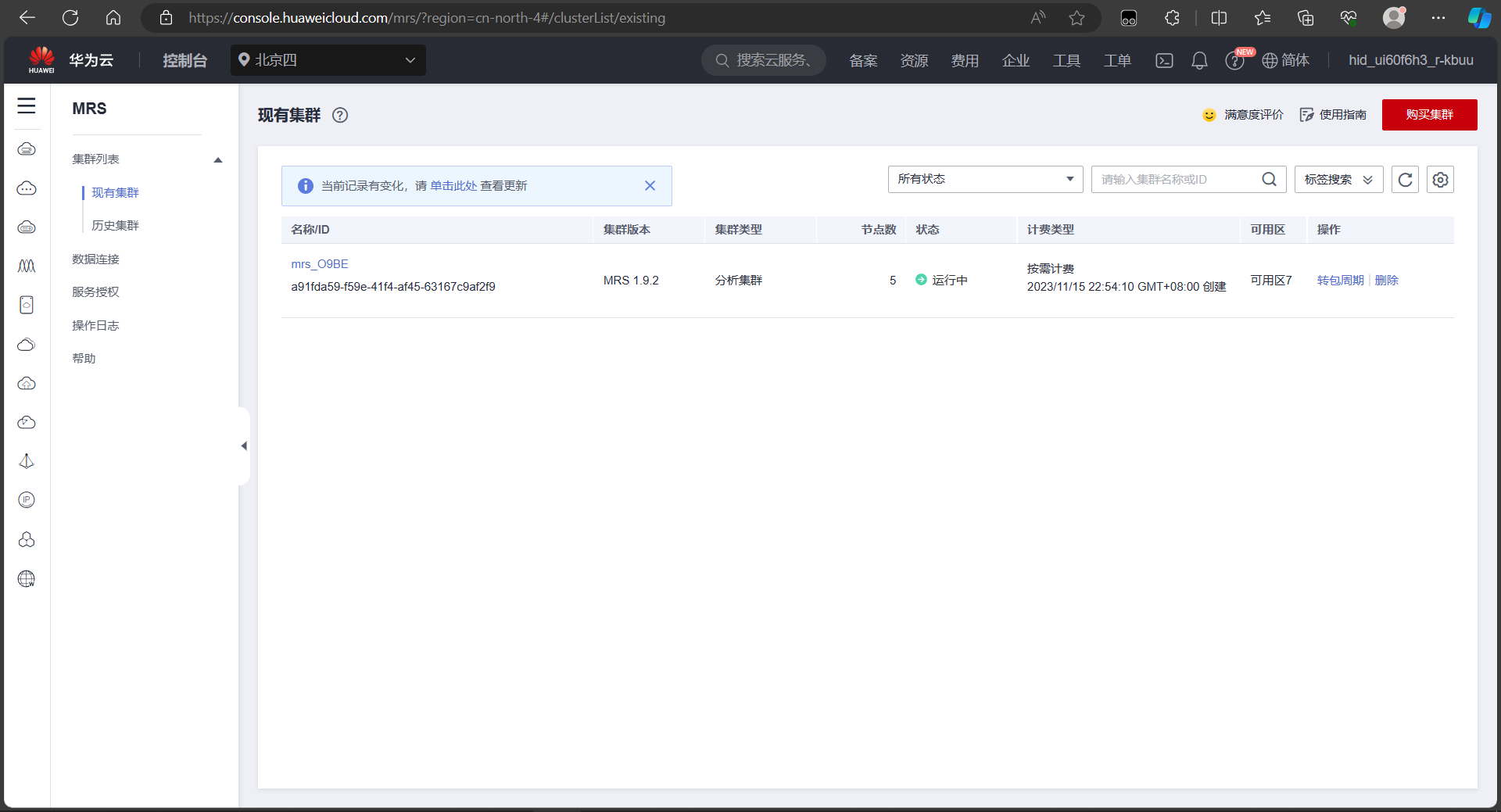
任务一:开通MapReduce服务
实时分析开发实战:
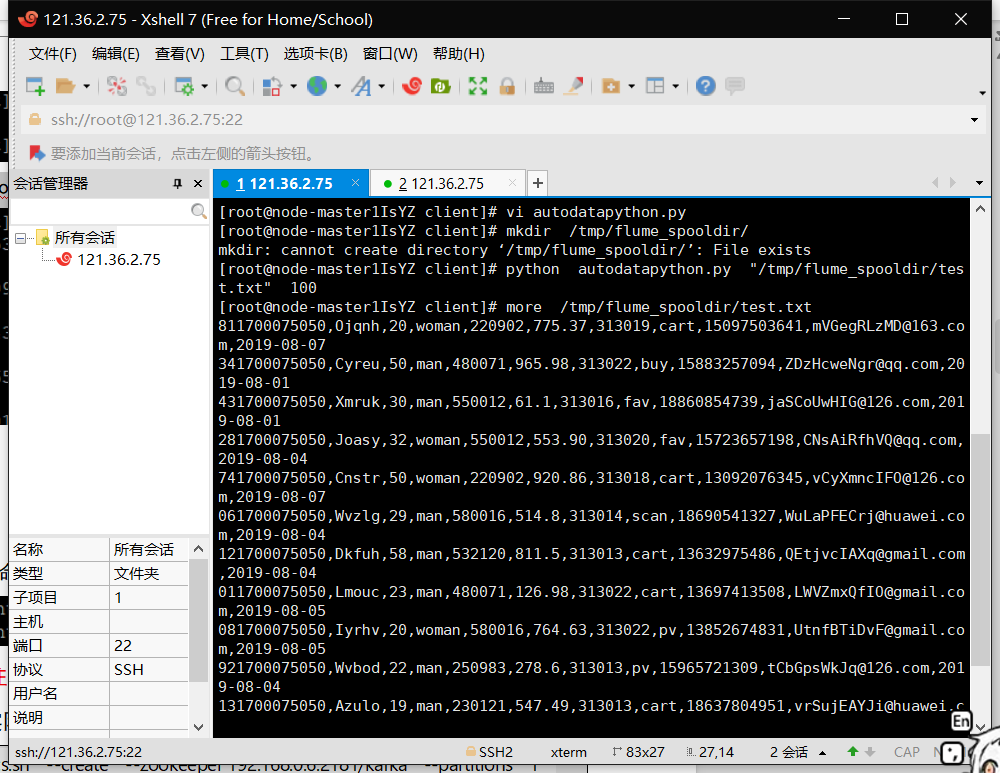
任务一:Python脚本生成测试数据
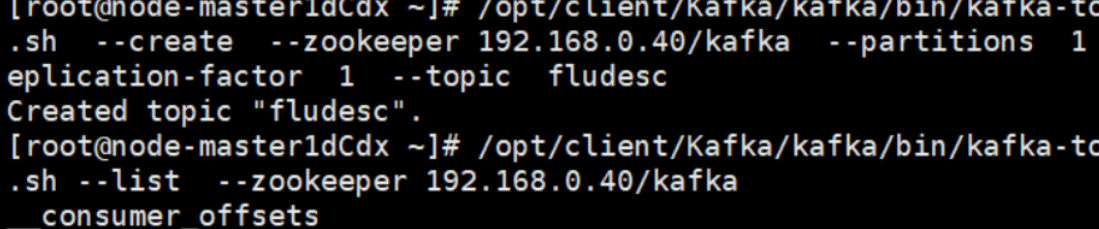
任务二:配置Kafka
任务三:安装Flume客户端
任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。
结果截图:
开通MapReduce服务
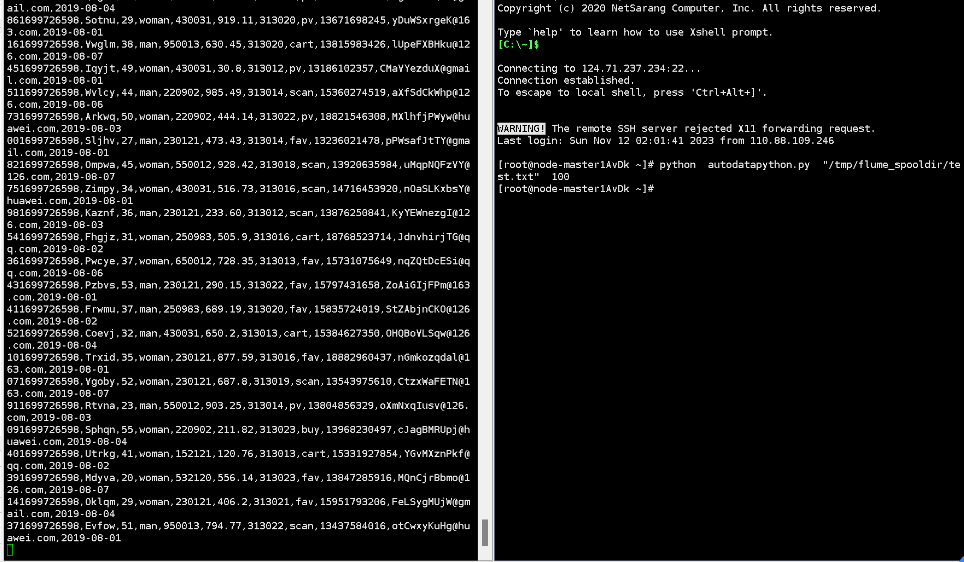
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三:安装Flume客户端


·任务四:配置Flume采集数据