Attention Is All You Need
关键词:Self-Attention、Transformer
? 研究主题
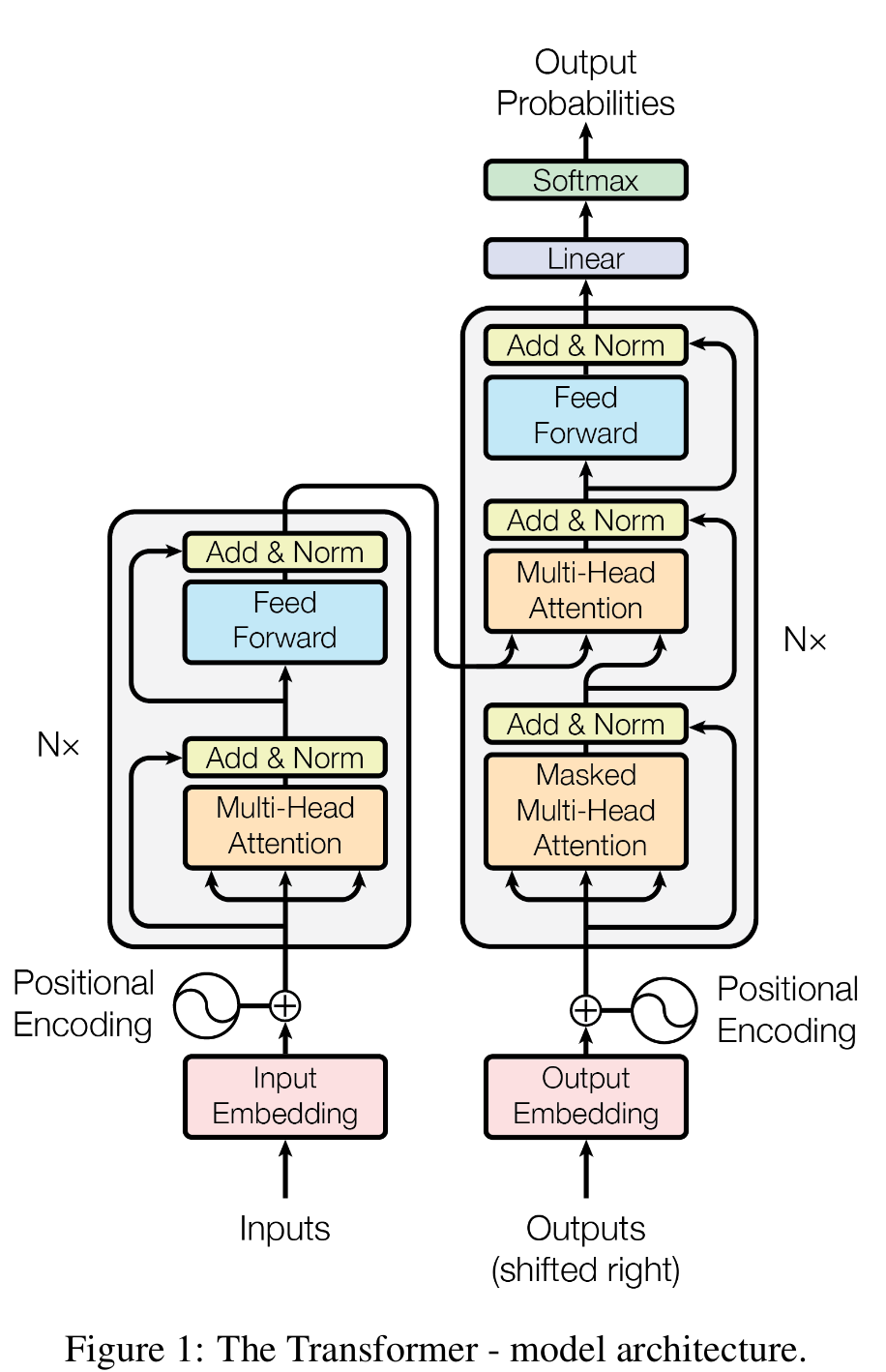
设计仅基于注意力机制的网络Transformer
Transformer仍然采用Encoder-Decoder结构,但脱离了Seq2Seq结构,不采用RNN或CNN单元
✨创新点:
- 由于Seq2Seq结构的顺序计算,阻碍了训练计算的并行化,因此设计了Transformer架构,提高并行度实现快速训练;
- 提出了Scaled Dot-Product Attention与Multi-Head Attention;
- 没有采用传统的One-Hot编码,而是设计了包含位置信息的Positional Encoding;
? 讨论&解释
Scaled Dot-Product Attention
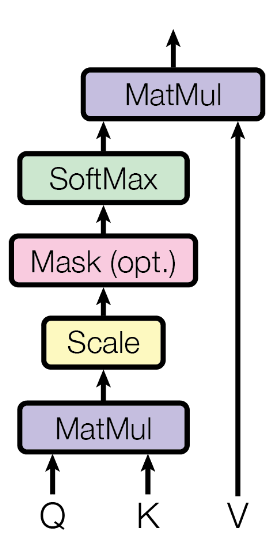
- QKV来自输入X的Position编码后得到的三个矩阵,采用可学习参数Wq、Wk、Wv与X点乘得到;
- Scale:由于K的维度较大,QK^T得到的值较大,导致softmax结果进入极小区间;
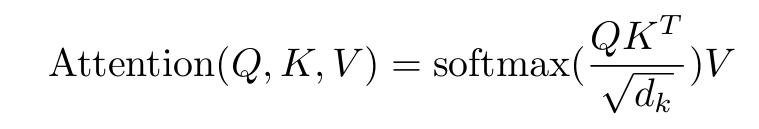
Multi-Head Attention
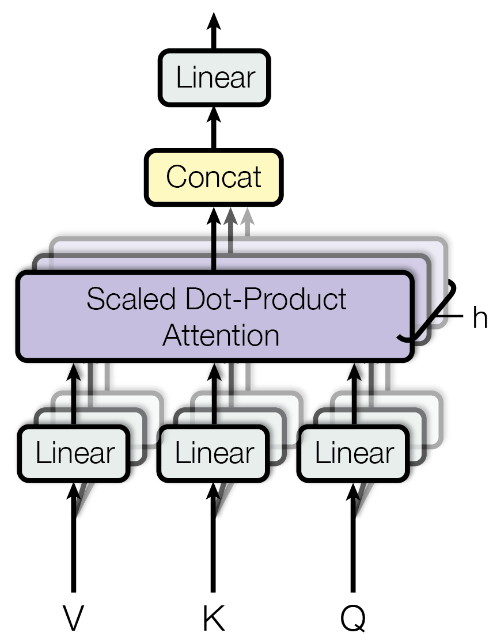
- 将权重Wvkq切分成h块,因此生成的QKV也为h块,分别对每块QKV进行Scaled Dot-Product Attention计算,再讲得到的结果head进行拼接后,再通过线性层输出
- “Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.” (Vaswani 等, 2023, p. 5) (pdf) 由于每个头的维度减少,总计算成本与全维度的单头注意力相似。
- “Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.” (Vaswani 等, 2023, p. 5) (pdf) 多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息。对于单一注意力头,平均会抑制这种情况。
一个更简洁的计算过程如下图所示(来源):

Position-wise Feed-Forward Networks
即两层线性层,可用两层内核大小为1的卷积层代替
Positional Encoding
为解决全部采用Attention机制导致的位置信息丢失,为input添加了位置编码,有两种实现方式:
- 采用固定的位置编码,公式如下:
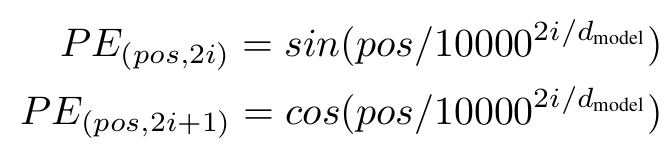
- 采用可学习的位置编码,即为QKV添加一个可学习的矩阵PE
论文中提到:两种实现版本性能表现接近
其他细节
- Transformer中采用的norm为Layer Normalization;
- 解码器中Masked Multi-Head Attention,确保每个时间步生成的词语仅基于过去的输出和当前预测的词,mask后续位置;
? 设计与实现
Transformer结构