CAKE:用于多视域知识图谱补全的可扩展常识感知框架
ACL2022
Abstract
知识图谱存储大规模事实三元组,然而不可避免的是图谱仍然具有不完整性。(问题)以往的只是图谱补全模型仅仅依赖于事实域数据进行实体之间缺失关系的预测,忽略了宝贵的常识知识。以往的知识图嵌入技术存在无效负抽样和事实域链接预测的不确定性等问题,限制了知识图嵌入的性能。为了解决上述挑战,(解决)本文提出了一种新颖且可扩展的常识感知知识嵌入(CAKE)框架,用于从具有实体概念的事实三元组中自动提取常识。生成的常识增强了有效的自我监督,以促进高质量负抽样(NS)和共有常识与事实域链接预测。在KGC任务上的实验结果表明,该框架可以提高原始KGE模型的性能,并且所提出的常识感知神经网络模块优于其他神经网络技术。此外,我们提出的框架可以很容易地适应各种KGE模型,并解释预测结果。

图1:两个例子展示了需要解决的挑战。挑战1:给定一个阳性三元组,一些生成的阴性三元组是假阴性或低质量的。挑战2:对于链接预测,由于KG嵌入的不确定性,实体加利福尼亚州的排名高于正确实体美国。但从常识上看,正确的答案实体应该属于概念国家。

解释
Introduction & Related Work
该论文的所做综述总结如下:
以往的KGC模型可以分为三大类:
-
- 基于规则学习的模型挖掘归纳推理的逻辑规则,如AMIE+,DRUM和AnyBurl。自动从KGs中挖掘逻辑规则,并将这些规则应用于归纳链接预测。然而,这些模型由于耗时的规则搜索和评估而效率低下
- 基于路径的模型,如多跳推理的搜索路径。基于路径的模型搜索连接头尾实体的路径,包括路径排序方法和基于强化学习的模型。然而,基于多跳路径的模型在路径搜索上也花费了大量的时间
- KGE模型,如TransE及其变体学习实体和关系的嵌入,对三元组的可信性进行评分,用于链接预测。与其他方法相比,KGE方法在KGC上具有更高的效率和更好的性能。然而,嵌入的自然不确定性限制了仅依靠事实的KGC的精度。更具体地说,KGE模型通常需要一个基础负抽样(NS)程序来随机或有目的地抽样一些在KG中未观察到的三元组作为训练的负三元组
在现有的KGC模型中,KGE方法具有更高的效率和更好的性能。具体来说,基于KGE的知识图谱补全pipline可以分为两个阶段:
-
- 在训练阶段学习知识图谱嵌入。学习嵌入知识图谱依赖于负采样的基本过程
- 在推理阶段进行链接预测。链接预测目的是根据学习到的KG嵌入,对候选三元组的分数进行排序,从而推断出三元组中缺失的实体或关系
然而,这两个独立的阶段都有缺点:
(1)无效的负采样:所有以前的负采样无法避免同时对假阴性三元组和低质量阴性三元组进行采样。例如,给定如图1所示的正三元组(Los Angeles, LocatedIn, california),现有的NS策略可能会采样损坏的三元组,例如(San francisco, LocatedIn, california),这实际上是一个缺失的正确三元组,即假负三元组。另一方面,一些生成的负三元组,如(San francisco, LocatedIn, Apple pie)的质量太差,对训练KGE模型没有什么意义。
(2)事实视图链接预测的不确定性:以数据驱动的方式仅基于事实进行链接预测,由于KG嵌入与符号表示相比存在偏差,因此存在不确定性,限制了KGC的准确性。以图1中的尾实体预测(David, Nationality, ?)为例。从常识上看,正确的尾部实体应该属于国家概念。然而,与常识不符的实体加利福尼亚州甚至通过对具有KG嵌入的候选三元组进行评分而排名最高。
尽管一些KGE方法利用外部信息,包括实体类型、文本描述和实体图像。这种辅助信息很难访问,并且增强了实体的单一表示,而不是提供常识语义。然而,有价值的常识总是通过昂贵的手工标注获得的,因此其高成本导致相对较低的覆盖率。此外,现有的大型常识知识库只包含概念,而不包含与相应实体的链接,导致它们无法用于KGC任务。
为了解决上述问题,
我们提出了一种新颖且可扩展的常识感知知识嵌入(CAKE)框架,以改进KGE训练中的神经网络,并利用常识的自我监督来提高KGC的性能。具体而言,我们尝试通过实例抽取技术从KGs中自动构建显式常识,然后利用常识和复杂关系的特征,有目的地生成高质量的负三元组,而不是随机抽样。进一步,进行多视域链接预测,确定常识视域中属于正确概念的候选实体,并从事实的角度使用学习到的KG嵌入预测答案实体。总之,我们的工作贡献有三个方面:我们提出了一个可扩展的KGC框架,该框架具有自动常识生成机制,可以从事实三元组和实体概念中提取有价值的常识。我们开发了一种常识性的负采样策略,用于生成有效和高质量的负三元组。同时,为了提高KGC的精度,提出了一种多视图链路预测机制。在四个基准数据集上进行了广泛的实验,说明了我们整个框架和每个模块的有效性和可扩展性。
KGE的负采样
根据局部闭世界假设,现有的KGE负采样(NS)技术可分为五类:
(1)随机均匀抽样:大多数KGE模型通过随机替换均匀分布中的正三元组中的实体或关系来生成负三元组。
(2)基于对抗性的采样:KBGAN将KGE模型与softmax概率相结合,在对抗性训练框架中选择高质量的负三组。自对抗抽样的性能与KBGAN类似,但它使用的是没有生成器的自评分函数。
(3)基于域的采样:基于域的NS和类型约束的NS都利用域或类型约束对属于正确域的损坏实体进行采样。
(4)高效采样:NSCaching利用包含负三元组候选项的缓存来提高采样效率。
(5)无采样:NS-KGE通过将KGE的损失函数转换为统一的平方损失,消除了NS过程。
然而,所有以前的NS算法都不能解决假阴性三元组的问题,因为这些NS技术,除了不采样,会尝试以更高的概率对损坏的三元组进行采样,而它们可能是正确的,只是在KG中缺失。基于域的NS严重依赖于单一类型的约束,而不是常识,限制了负三元组的多样性。KBGAN在NS框架中引入了生成对抗网络(generative adversarial networks, GAN),使得原始模型变得更加复杂和难以训练。无采样需要将每个原始KGE模型转换成平方损失,这削弱了KGE模型的性能。NS策略的缺陷降低了KGE的训练,进一步限制了KGC的性能。
常识知识图谱
与事实三元组不同,常识可以为KGs注入丰富的抽象知识,但由于手工标注的成本高,有价值的常识难以获取。近年来,许多研究试图构建一般的常识图,如ConceptNet ,Microsoft概念图和ATOMIC。然而,这些常识性图只包含概念,而没有到相应实体的链接,导致它们不适用于KGC任务。另一方面,虽然一些KGE模型,如JOIE使用了大多数KGE内置的本体,即NELL和DBpedia,但本体中的关系,如isA、partOf和relatedT主要代表类型层次,而不是明确的常识。这种关系对KGC来说是无用的,因为本体论关系和事实关系之间很少有重叠。
Methodology
在本节中,将介绍新的可伸缩的CAKE框架。如图2所示,整个管道由三个开发模块组成:自动常识生成(ACG)模块、常识感知负采样(CANS)模块和多视域链路预测(MVLP)模块。首先,ACG模块通过实例抽象机制从具有实体概念的事实三元组中提取常识。然后,CANS模块使用生成的常识来产生高质量的负三元组,它考虑了复杂关系的特征。之后,我们的方法将正三元组和加权负三元组输入到KGE模型中,用于学习实体和关系嵌入。最后,MVLP模块以一种从粗到精的方式进行链接预测,方法是从常识的角度过滤候选项,并从事实的角度预测候选项中含有KG嵌入的答案实体。
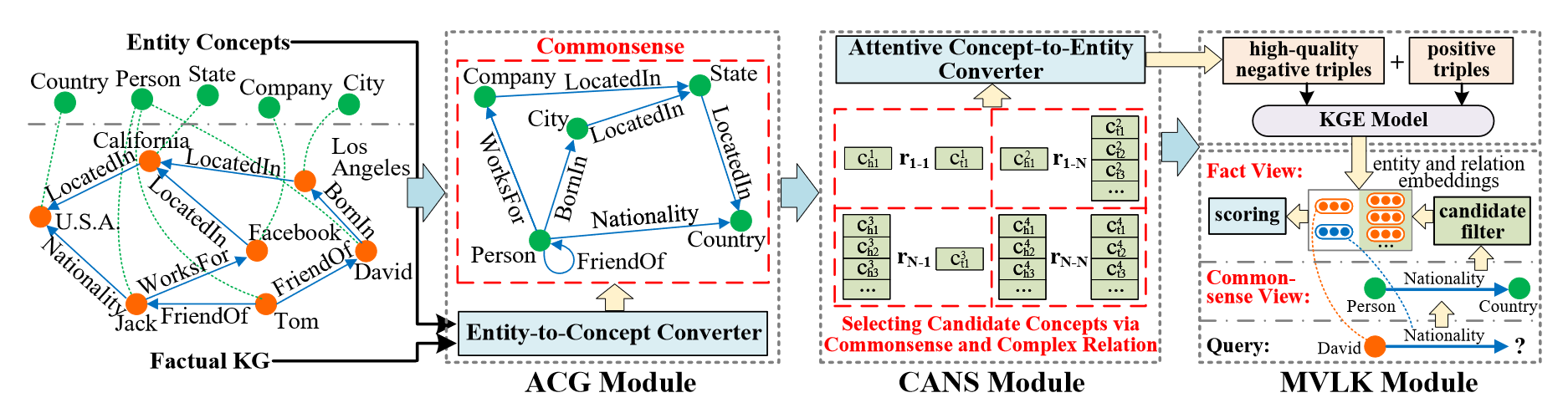
图2 CAKE框架的概述。橙色的圆点表示实体。绿色圆点表示实体概念。在CANS模块中,r1−1、r1−N、rN−1、rN−N分别表示1-1、1-N、N-1、N-N的各种复关系。![]() 和
和![]() 表示由常识选择的第i个头概念和第j个关系特有的复杂关系特征。
表示由常识选择的第i个头概念和第j个关系特有的复杂关系特征。
Notations and Problem Formalization

Automatic Commonsense Generation(ACG)
定义的常识表示而言,本方法理论上可以从任何KG自动生成常识,只要存在一些与KG中的实体相关联的概念。具体来说,开发了一个实体到概念的转换器,将每个事实三元组中的实体替换为相应的概念。同时,常识性关系也包含了事实性KGs中的实例级关系,如图2所示,事实三元组(David, Nationality, U.S.A.)可以转换为概念级三元组(P person, Nationality, Country)。特别是,单个集合C1中的常识是通过清除重复的概念级三元组来实现的。然后,我们将包含相同关系的概念级三元组合并到一个集合中,以集合形式C2构造常识。
Commonsense-Aware Negative Sampling(CANS)
为了减少假负样本,利用1-1、1-N、N-1和N-N的复杂特征用于负抽样。
在此基础上,提出了两种具体的采样策略:
(1)唯一性采样:对于破坏一个唯一实体,如N-1关系的尾部实体,除了原始的正三元组外,被破坏的三元组肯定是实际的负三元组。此外,与正确实体共享至少一个概念的错误实体被视为高质量的负三元组,有助于获得更一致的训练信号。
(2)非唯一抽样:为了破坏非唯一实体,如由N-1关系链接的头部实体,由于头部实体的非唯一性,与正确实体属于同一概念的实体更有可能是假阴性的。因此,在训练中,这些为假阴性的负三元组的权重应该尽可能低。同时我们尝试对符合常识C2的三元组进行抽样以获得高质量。
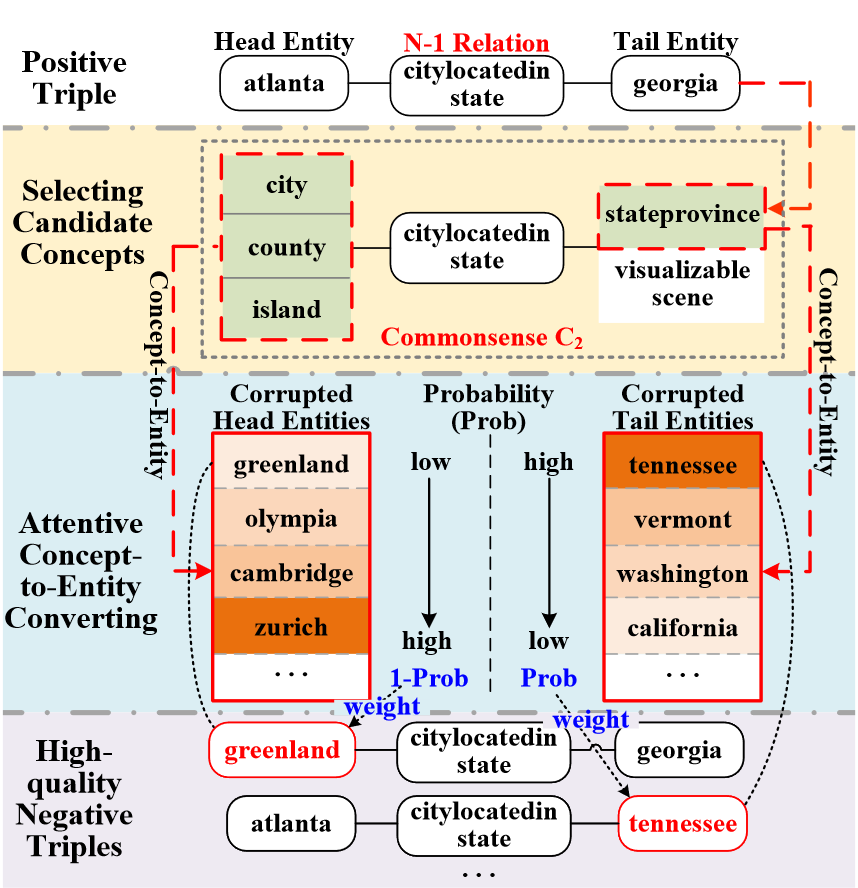
图3 在NELL-995上设计的CANS模块生成包含N-1关系的高质量负三元组的示例
为了更好地理解,图3显示了一个生成具有N-1关系的高质量负三元组的示例。整个NS过程可以分为两个步骤。步骤1:选择具有常识性C2的候选概念。根据常识C2和非唯一抽样确定候选头部概念“城市”、“县”和“岛”。此外,基于唯一性抽样策略,将候选尾巴概念选择为与Georgia相同的概念state - province。步骤2:注意概念到实体的转换。为了减少假阴性,同时确保负三元组的高质量,从以下分布中采样属于候选概念的损坏实体:
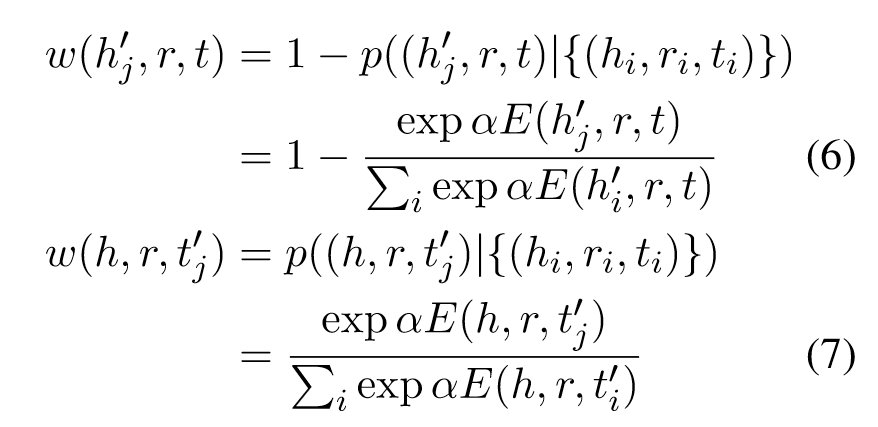
其中h′i和t′i是通过非唯一采样和唯一性采样得到的损坏的头尾实体。ω和p分别表示负三元组的权重和概率。α是由自对抗采样驱动的采样温度(Sun et al., 2019)。值得注意的是,考虑到概率较高的三元组更有可能是正三元组,因此,为防止假阴性问题,将包含损坏头部实体的负三元组的权重定义为(6)。此外,由于不存在假阴性问题,含有概率较高的损坏尾实体的负三元组被赋予了更高质量的权重。选择具有高权重的受损头部实体greenland和受损尾部实体tennessee来生成高质量的负三元组。同样,通过对头部实体的唯一性抽样和对尾部实体的非唯一性抽样来生成具有1-N关系的高质量负三元组。另外,只要对头尾实体都进行唯一性抽样,就可以得到1-1关系的负三元组。相反,生成N-N关系的负三元组只需要非唯一性抽样。
Traning the KGE Model
基于CANS得到的负三元组,我们训练KGE模型学习实体嵌入和关系嵌入,以扩大正三元组和高质量负三元组之间的分数差距。在本工作中,我们采用以下损失函数作为优化目标:
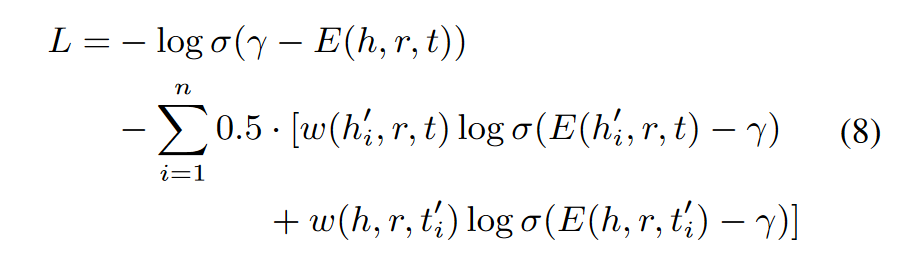
其中γ是边界。σ是sigmoid函数。
Multi-View Link Prediction(MVLP)
利用常识与事实之间相同的关系,常识可以直接为链接预测结果提供一个确定的范围。因此,我们开发了一种新的多视图链接预测(MVLK)机制,在一个从粗到精的范式,以促进更可能的预测结果。首先,在粗预测阶段,我们从常识的角度选择候选实体。具体来说,以查询(h, r, ?)为例,常识C1用于过滤尾部实体的合理概念。将尾实体的候选概念集定义为
![]()
其中Chi为h的第i个概念,Cti为常识(Chi, r, Cti)中的尾概念。然后,可以确定属于概念集C1t的实体作为候选实体,因为它们满足常识,从常识的角度来看比其他实体更有可能是正确的尾部实体。然后,在精细预测阶段,我们从事实的角度对粗预测阶段得出的每个候选实体ei进行评分,如下所示
 式中E(h, r, ei)为训练KGE模型所用的得分函数。随后,预测结果将候选实体的得分按升序排序,并输出排名较高的实体。
式中E(h, r, ei)为训练KGE模型所用的得分函数。随后,预测结果将候选实体的得分按升序排序,并输出排名较高的实体。
自己的总结
本论文提出了一种新颖且可扩展的KGC框架。具体创新点分为两个部分:负采样策略和链接预测策略。
负采样策略提出常识层的三元组表示方法,在负采样阶段通过锁定头尾实体的上层常识概念进行原三元组的破坏,并且将三元组分为四类1-1、1-N、N-1、N-N利用CANS模块生成高质量的负采样本。
链接预测策略首次利用前期的常识层进行候选实体的选择,精准缩小链接预测的范围。最后,对已选出的候选实体进行评分,按照得分对其进行排序,输出排名较高的实体。
- Commonsense-Aware Commonsense Completion Multi-View Frameworkcommonsense-aware commonsense completion multi-view commonsense-aware multi-view commonsense commonsense-guided completion convolution multi-view clustering attribute representations bootstrapping multi-view detection completion机制linux insufficient completion ora diskgroup