一、选题背景
在现在,虽然我国实行楼市调控,使得总体的房价稳定下来,但是我国房价还是处于一个高水平之上。在这种情况下,大批在郑奋斗的年轻人选择租房,所以此次数据分析可以使在郑的年轻人了解郑州租房现状,让年轻人在租房时可以选到更加适合的房源。
二、爬虫设计方案
1、爬虫网址
郑州租房信息_郑州出租房源|房屋出租价格【郑州贝壳租房】 (lianjia.com)
https://zz.lianjia.com/zufang/
三、数据分析
1.获取郑州租房信息,对网站进行爬取,并且对数据进行数字化
1 #步骤1 导入库 2 3 #NumPy 4 import numpy as np 5 6 #pandas数据结构 7 import pandas as pd 8 9 #requests库 10 import requests 11 import time 12 import re 13 14 #seabron库 15 import seaborn as sns 16 import statsmodels.api as sm 17 import statsmodels.formula.api as smf 18 19 #Matplotlib库 20 import matplotlib.pyplot as plt 21 22 #BeautifulSoup库 23 from bs4 import BeautifulSoup
1 # 步骤2 数据爬取:获取一个区域的租房链接地址 2 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 \ 5 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} 6 7 def get_areas(url): 8 try: 9 print('start grabing areas') 10 11 resposne = requests.get(url, headers=headers, timeout=30) 12 html = resposne.content 13 soup = BeautifulSoup(html, 'html.parser') 14 15 all_sights = soup.findAll('li', 'filter__item--level2') 16 areas = [] 17 areas_links = [] 18 19 for item in all_sights: 20 if not item.get_text()=='\n不限\n': 21 areas.append(item.get_text()) 22 areas_links.append('https://zz.lianjia.com/zufang/'+item.find('a').get('href')) 23 24 return areas, areas_links 25 26 except Exception as e: 27 print('爬取网站出现了一点问题,问题如下:') 28 print(e) 29 return '' 30 31 print(type(get_areas(url))) 32 print(get_areas(url))
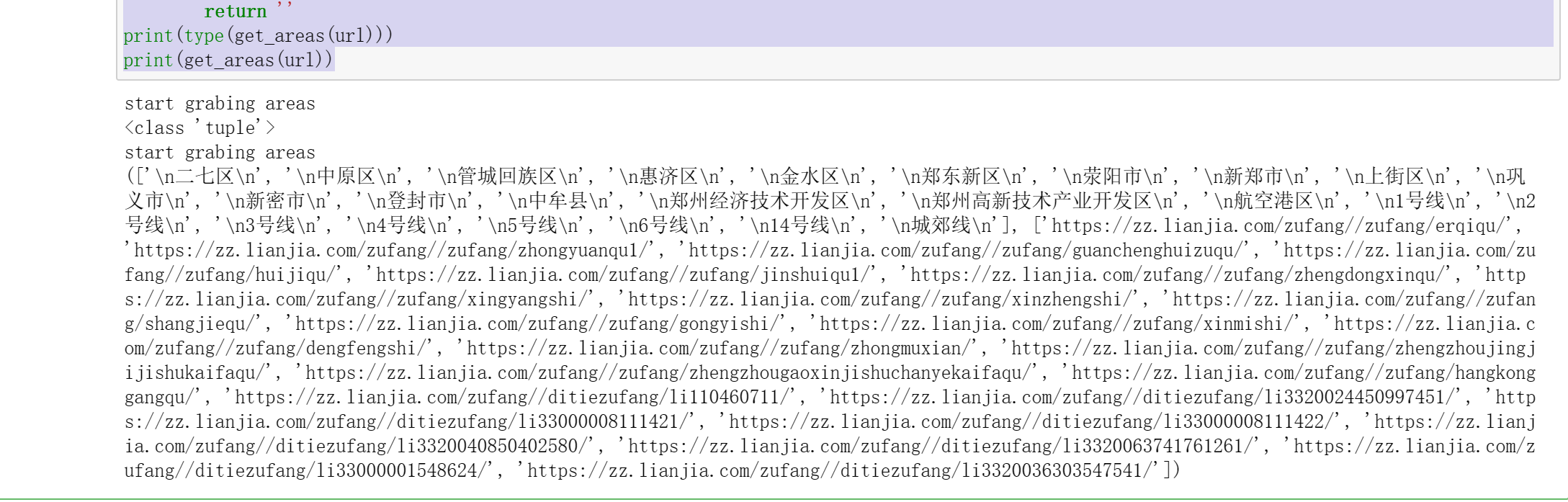
1 # 步骤3 数据爬取:获取该区域下的租房信息链接 2 3 def get_pages(area, area_link): 4 print("开始抓取页面") 5 resposne = requests.get(area_link, headers=headers) 6 html = resposne.content 7 soup = BeautifulSoup(html, 'html.parser') 8 pages = int(soup.findAll('div', 'content__pg')[0].get('data-totalpage')) 9 10 print("这个区域有" + str(pages) + "页") 11 info = [] 12 for page in range(1,pages+1): 13 url = 'https://bj.lianjia.com/zufang/dongcheng/pg' + str(page) 14 print("\r开始抓取%s页的信息, 已爬取%s条数据"%(str(page), 15 len(info)), end='') 16 info += get_house_info(area, url) 17 return info
1 # 步骤4 数据爬取:解析租房房产信息 2 3 def get_house_info(area, url, info=[]): 4 5 #time.sleep(2) 6 7 try: 8 resposne = requests.get(url, headers=headers) 9 html = resposne.content 10 soup = BeautifulSoup(html, 'html.parser') 11 12 all_text = soup.findAll('div', 'content__list--item') 13 14 for item in all_text: 15 item = item.get_text() 16 item = item.replace(' ', '').split('\n') 17 while "" in item: 18 item.remove("") 19 while "/" in item: 20 item.remove("/") 21 info.append(item) 22 return info 23 24 except Exception as e: 25 print(e) 26 time.sleep(2) 27 return get_house_info(area, url)
1 # 步骤5 数据爬取:开始爬虫任务 2 3 info = [] 4 url = 'https://zz.lianjia.com/zufang/' 5 areas, area_link = get_areas(url) 6 info = get_pages(areas[1], area_link[1])
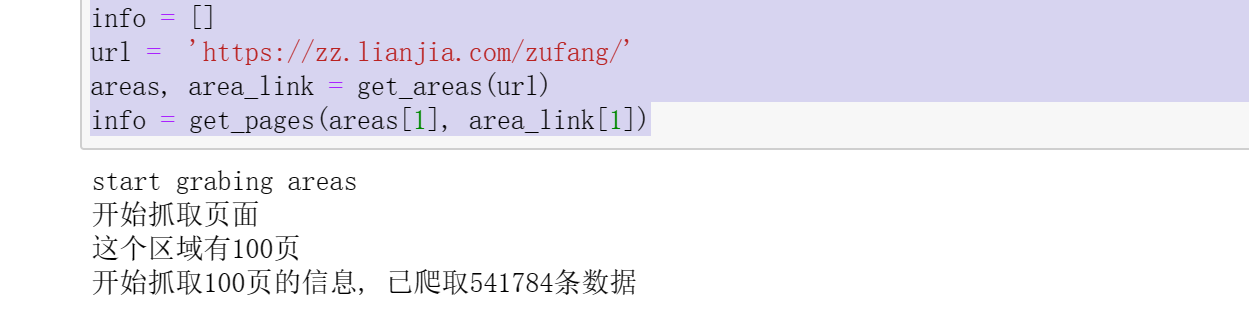
1 # 步骤6 数据爬取:简单数据清洗与保存数据 2 3 def keys(info, key=''): 4 ls = [] 5 for item in info: 6 if key in item: 7 ls.append(key) 8 else: 9 ls.append('') 10 return ls 11 12 def clean_data(info, key=''): 13 title = [item[0] for item in info] 14 address = [item[1] for item in info] 15 area = [item[2] for item in info] 16 toward = [item[3] for item in info] 17 style = [item[4] for item in info] 18 floor = [item[5] for item in info] 19 20 source = [item[6] for item in info] 21 time = [item[7] for item in info] 22 price = [item[-1] for item in info] 23 24 subway = keys(info, '近地铁') 25 decorate = keys(info, '精装') 26 heating = keys(info, '集中供暖') 27 new_room = keys(info, '新上') 28 time_for_look = keys(info, '随时看房') 29 30 return pd.DataFrame({ 31 'title': title, 32 'address': address, 33 'area': area, 34 'toward': toward, 35 'style': style, 36 'floor': floor, 37 'source': source, 38 'time': time, 39 'price': price, 40 'subway': subway, 41 'decorate': decorate, 42 'heating': heating, 43 'new_room': new_room, 44 'time_for_look': time_for_look 45 }) 46 47 data = clean_data(info) 48 data.to_csv('data.csv', index=True)
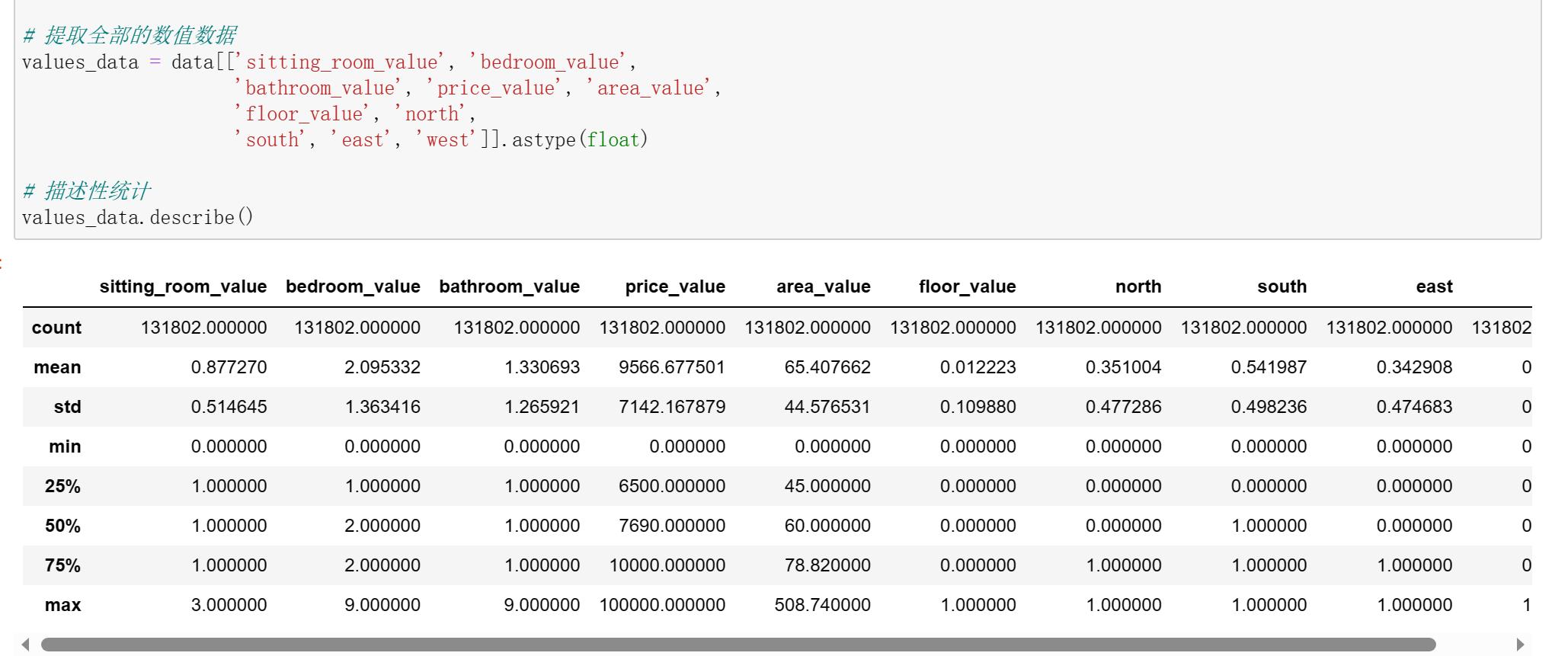
1 #步骤7 读取已爬取的数据,并对数据进行数字化 2 3 data = pd.read_csv('./data.csv') 4 5 # 客厅数量 6 7 data['sitting_room_value'] = data['style'].apply(lambda x: x.split('厅')[0][-1]) 8 data['sitting_room_value'] = data['sitting_room_value'].replace('卫', 0) 9 10 # 卧室浴室数量 11 12 data['bedroom_value'] = data['style'].apply(lambda x: x[0]) 13 data['bathroom_value'] = data['style'].apply(lambda x: x[-2]) 14 15 # 价格、面积、楼层 16 17 data['price_value'] = data['price'].apply(lambda x: x[:-3]) 18 data['area_value'] = data['area'].apply(lambda x: x[:-1]) 19 data['floor_value'] = data['floor'].apply(lambda x: x.split('(')[-1][0]) 20 21 # 租房方位朝向 22 23 def toward(x, key=''): 24 if key in x: 25 return key 26 else: 27 return 0 28 29 data['north'] = data['toward'].apply(lambda x: toward(x, '北')).replace('北', 1) 30 data['south'] = data['toward'].apply(lambda x: toward(x, '南')).replace('南', 1) 31 data['east'] = data['toward'].apply(lambda x: toward(x, '东')).replace('东', 1) 32 data['west'] = data['toward'].apply(lambda x: toward(x, '西')).replace('西', 1) 33 34 col = list(data.columns) 35 data[col] = data[col].apply(pd.to_numeric, errors='coerce').fillna(0.0) 36 data = pd.DataFrame(data, dtype='float') 37 38 # 提取全部的数值数据 39 40 values_data = data[['sitting_room_value', 'bedroom_value', 41 'bathroom_value', 'price_value', 'area_value', 42 'floor_value', 'north', 43 'south', 'east', 'west']].astype(float) 44 45 # 描述性统计 46 47 values_data.describe()
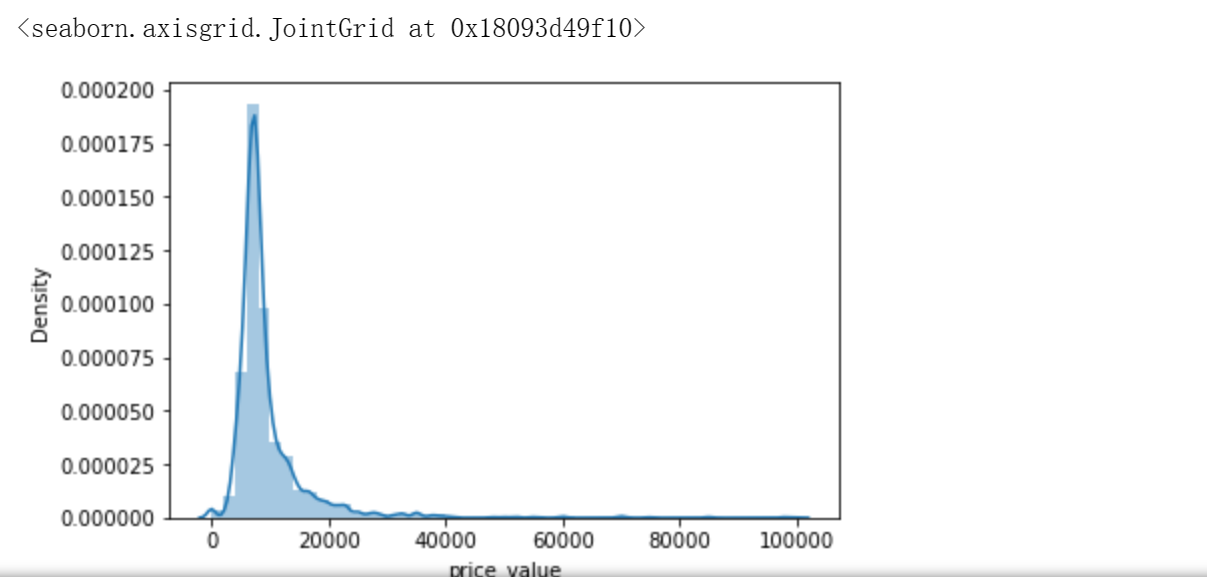
2.郑州租房信息已有,为了直观观察郑州租房情况,对数据进行可视化处理
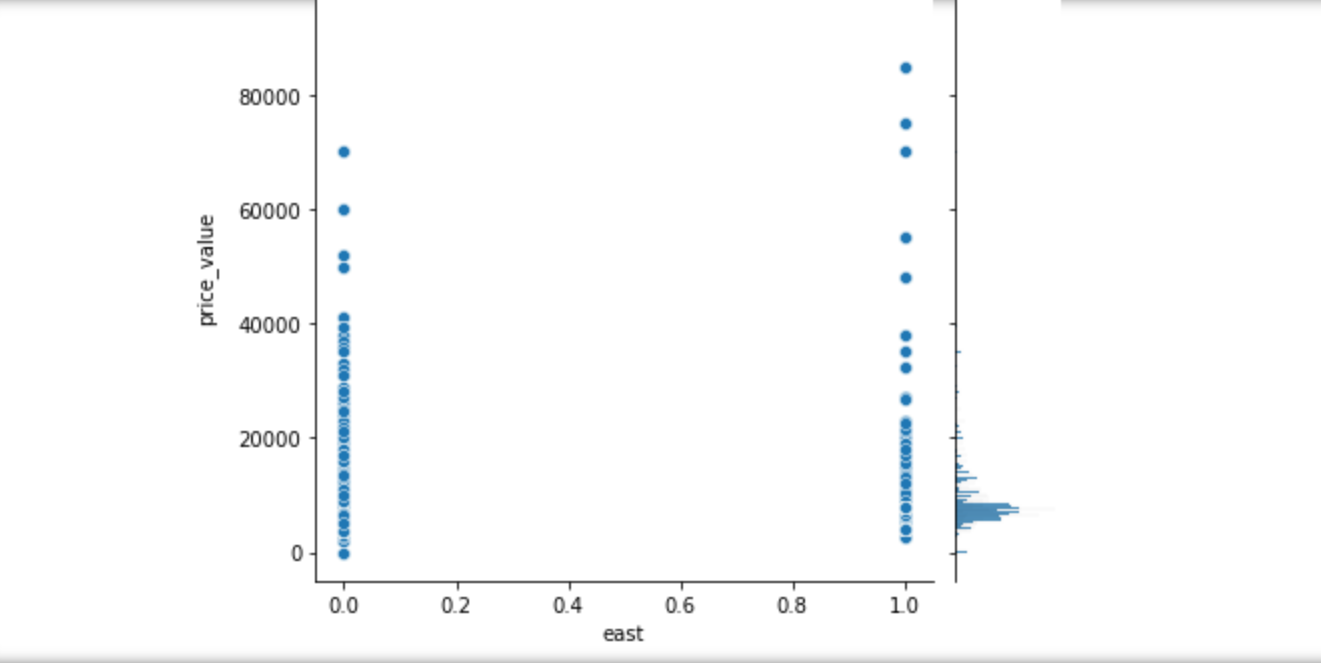
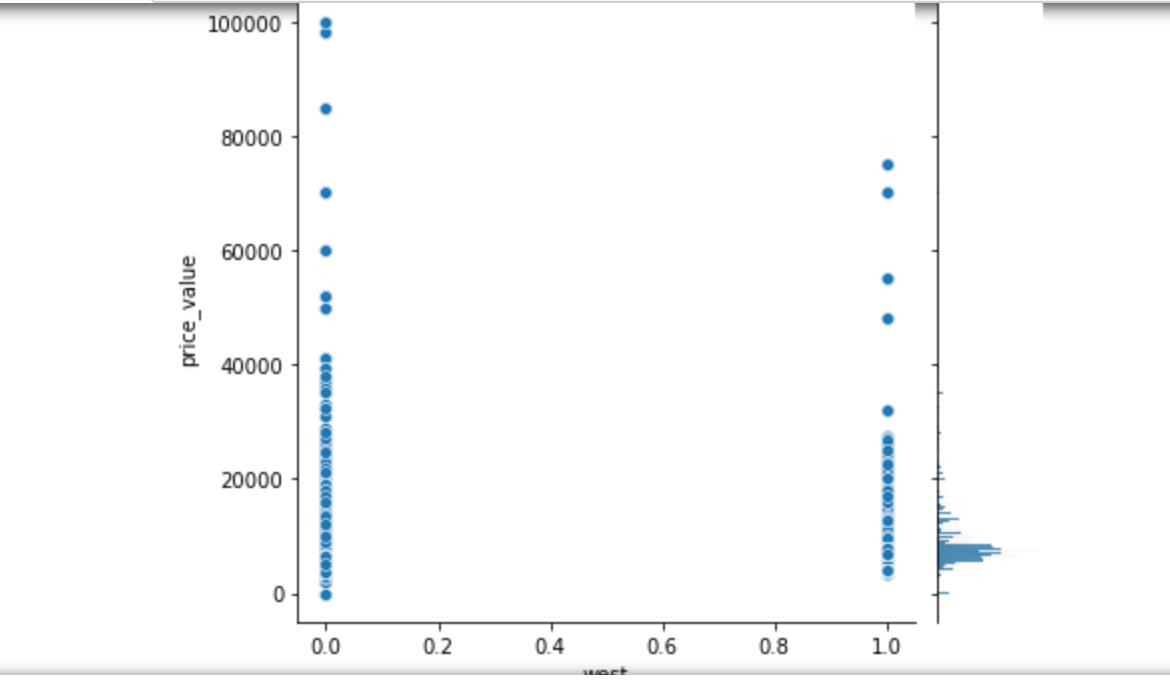
1 # 步骤8 数据分析:使用seaborn进行简单数据可视化 2 # 8.1 分析价格分布 3 4 sns.distplot(values_data['price_value'], kde=True) 5 6 # 8.2 分析价格与其他变量的关系 7 #面积和价格的关系 8 #楼层和价格的关系 9 #卧室数量和关系的价格 10 #浴室数量和关系的价格 11 #客厅数量和价格关系 12 13 sns.jointplot(x='area_value', y='price_value', data=values_data) 14 sns.jointplot(x='floor_value', y='price_value', data=values_data) 15 sns.jointplot(x='bedroom_value', y='price_value', data=values_data) 16 sns.jointplot(x='bathroom_value', y='price_value', data=values_data) 17 sns.jointplot(x='bathroom_value', y='price_value', data=values_data) 18 sns.jointplot(x='sitting_room_value', y='price_value', data=values_data) 19 #房子朝向和价格关系 20 #房子朝向北 21 #房子朝向南 22 #房子朝向东 23 #房子朝向西 24 25 sns.jointplot(x='north', y='price_value', data=values_data) 26 sns.jointplot(x='south', y='price_value', data=values_data) 27 sns.jointplot(x='east', y='price_value', data=values_data) 28 sns.jointplot(x='west', y='price_value', data=values_data)
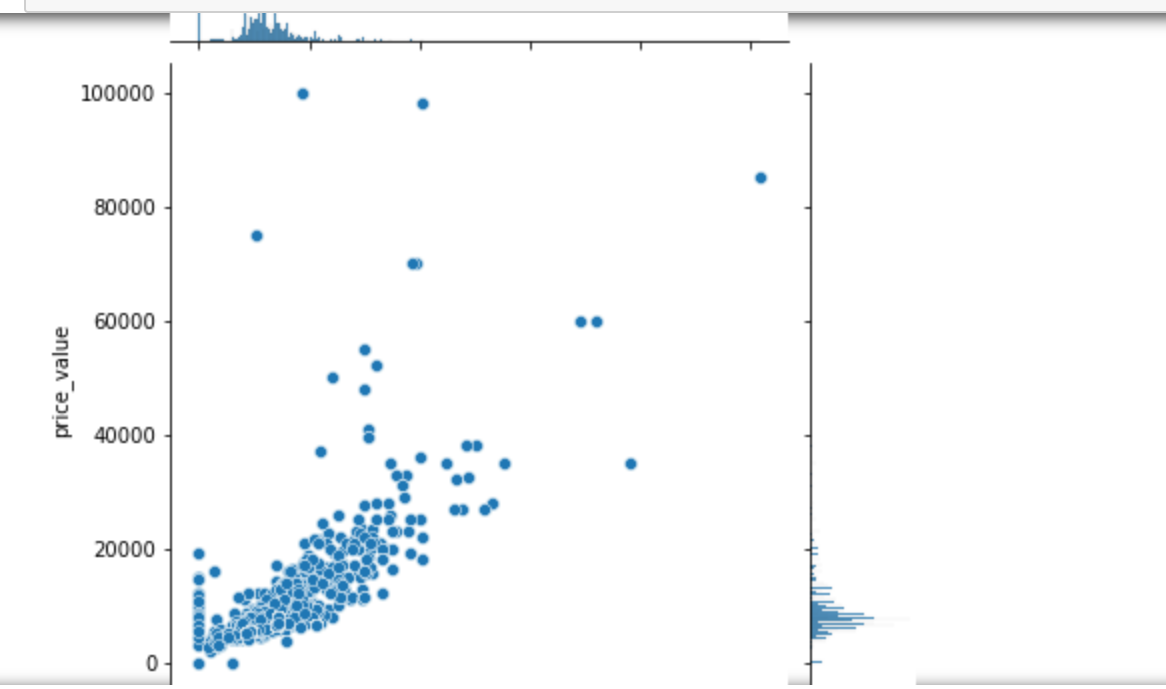
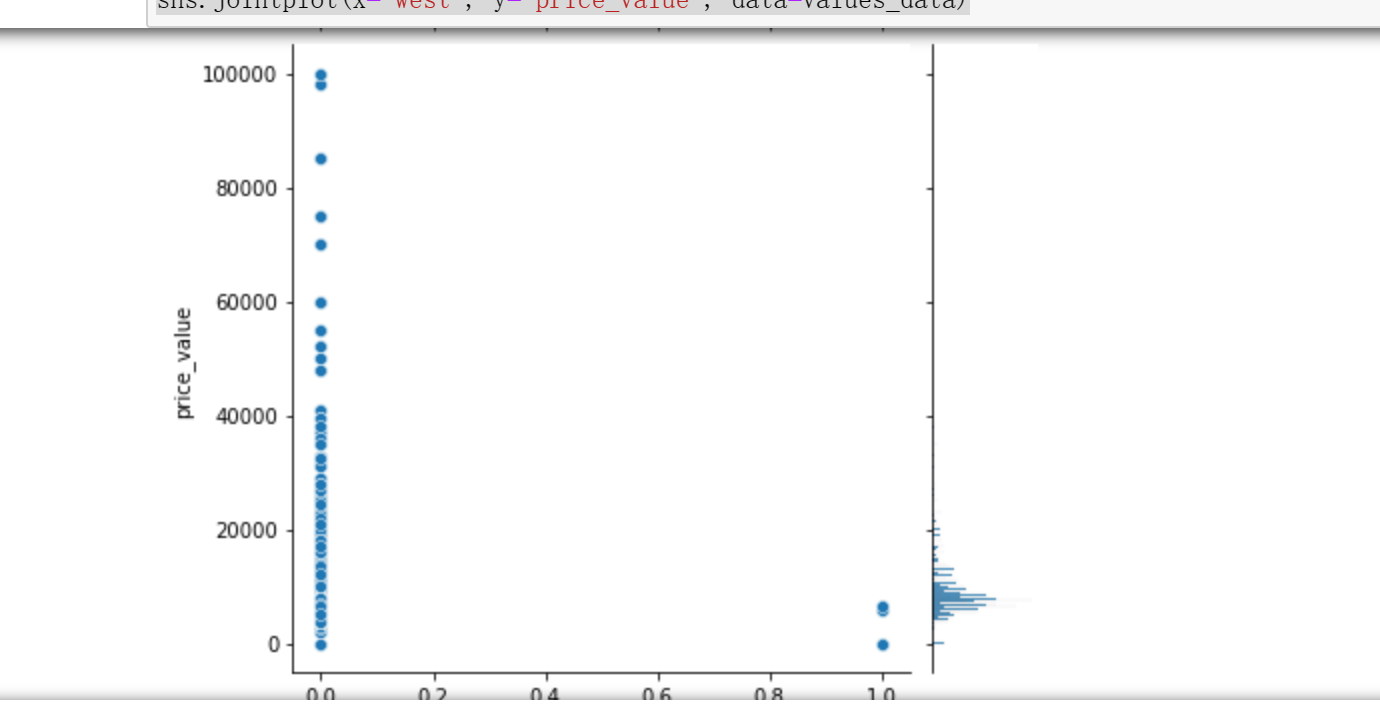
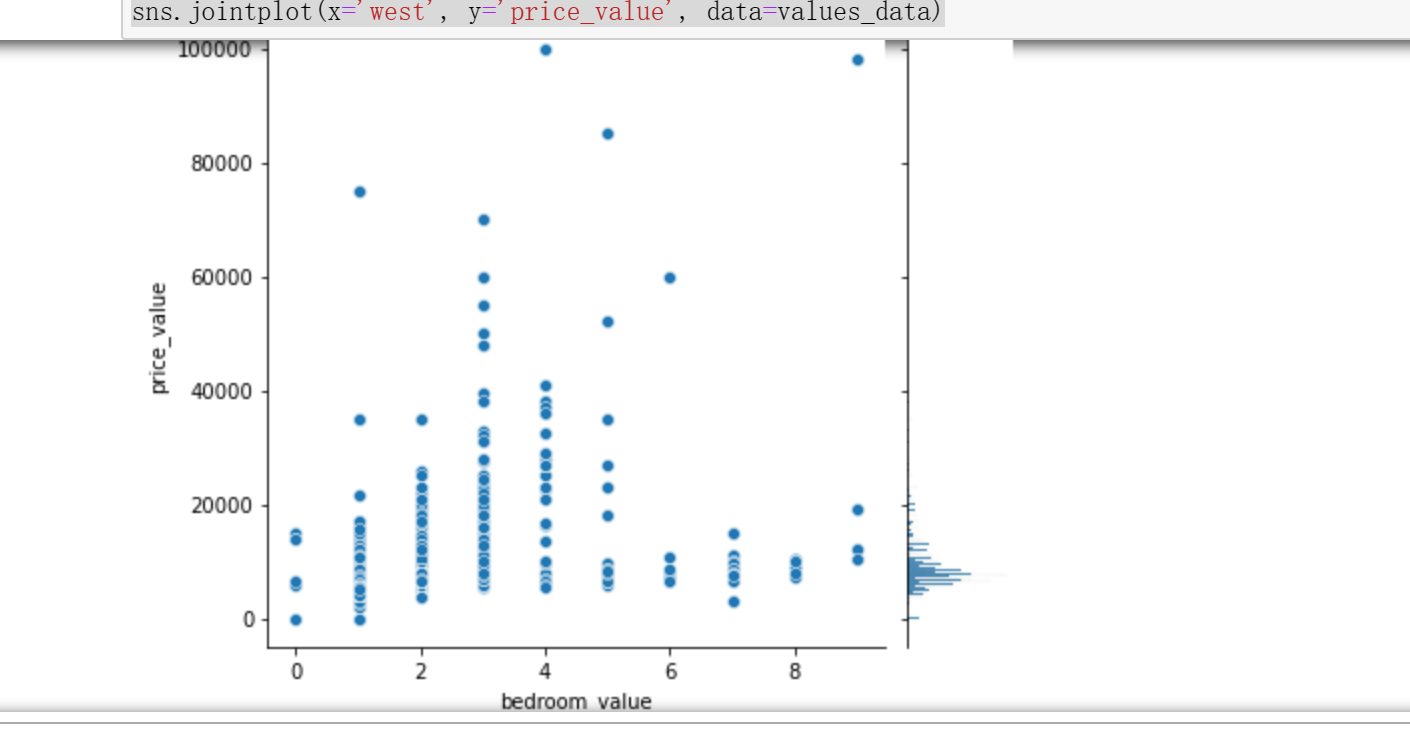
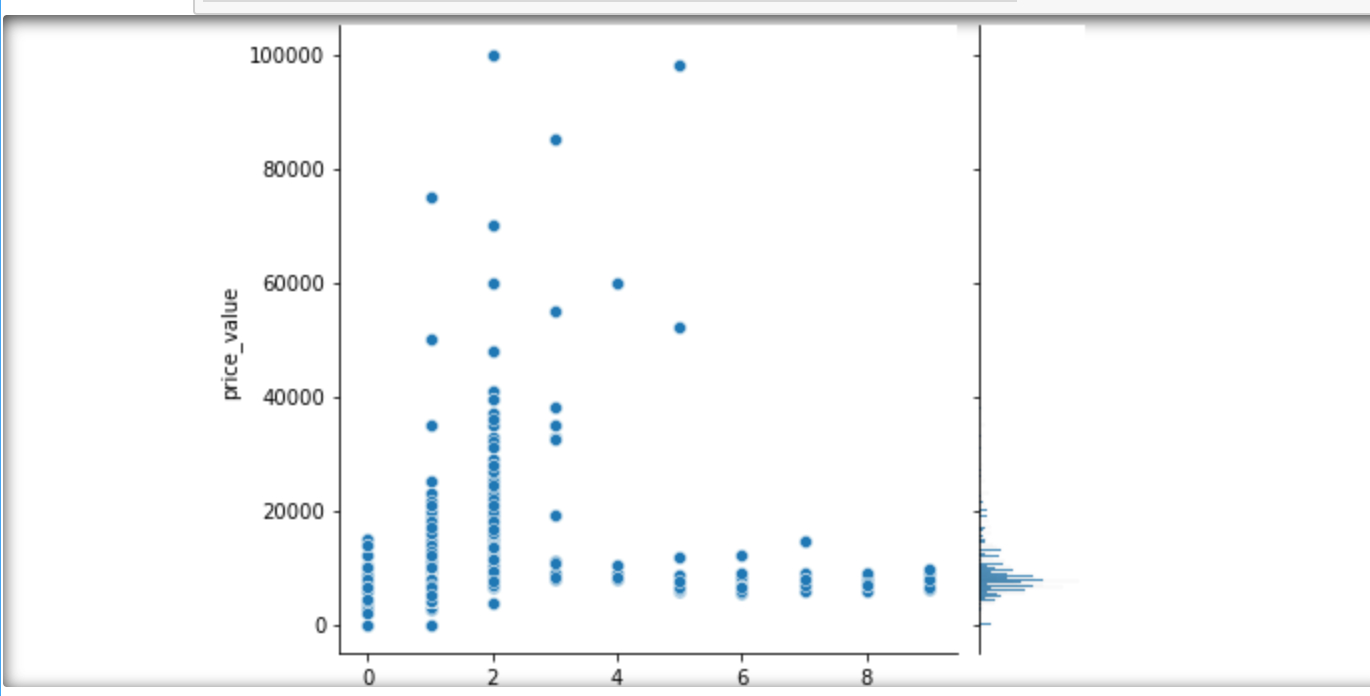
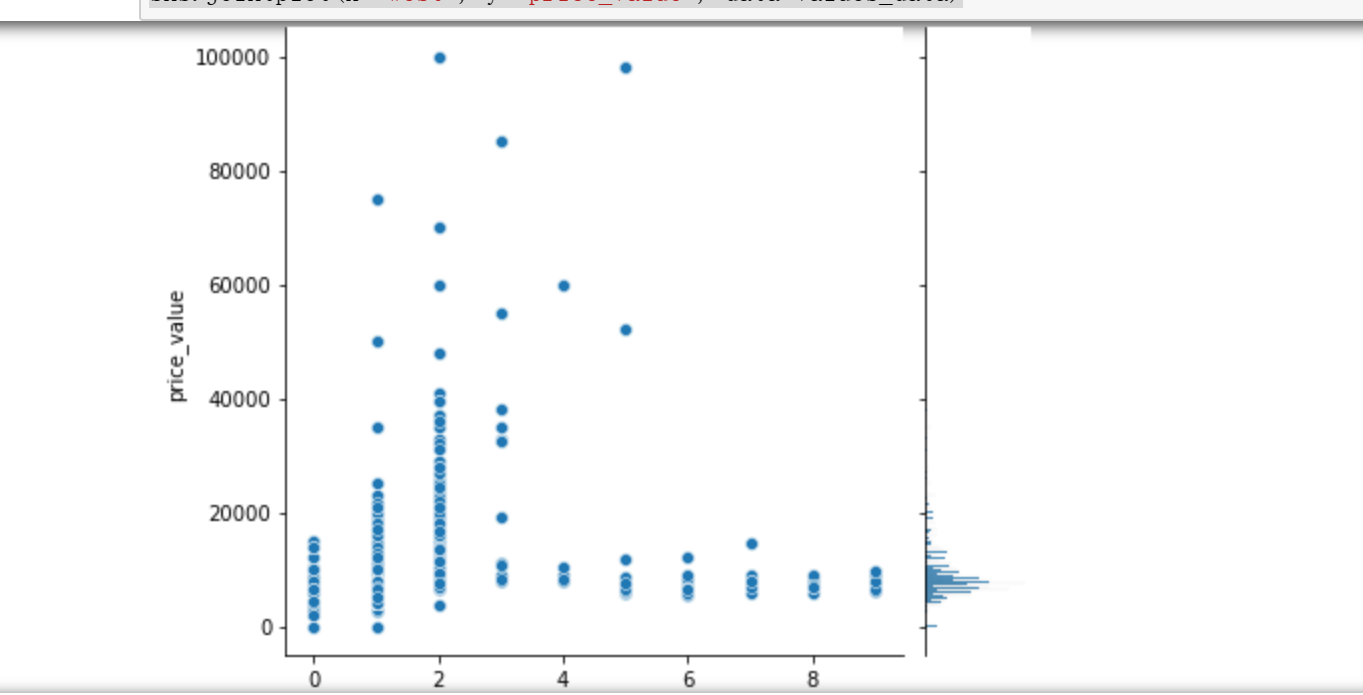
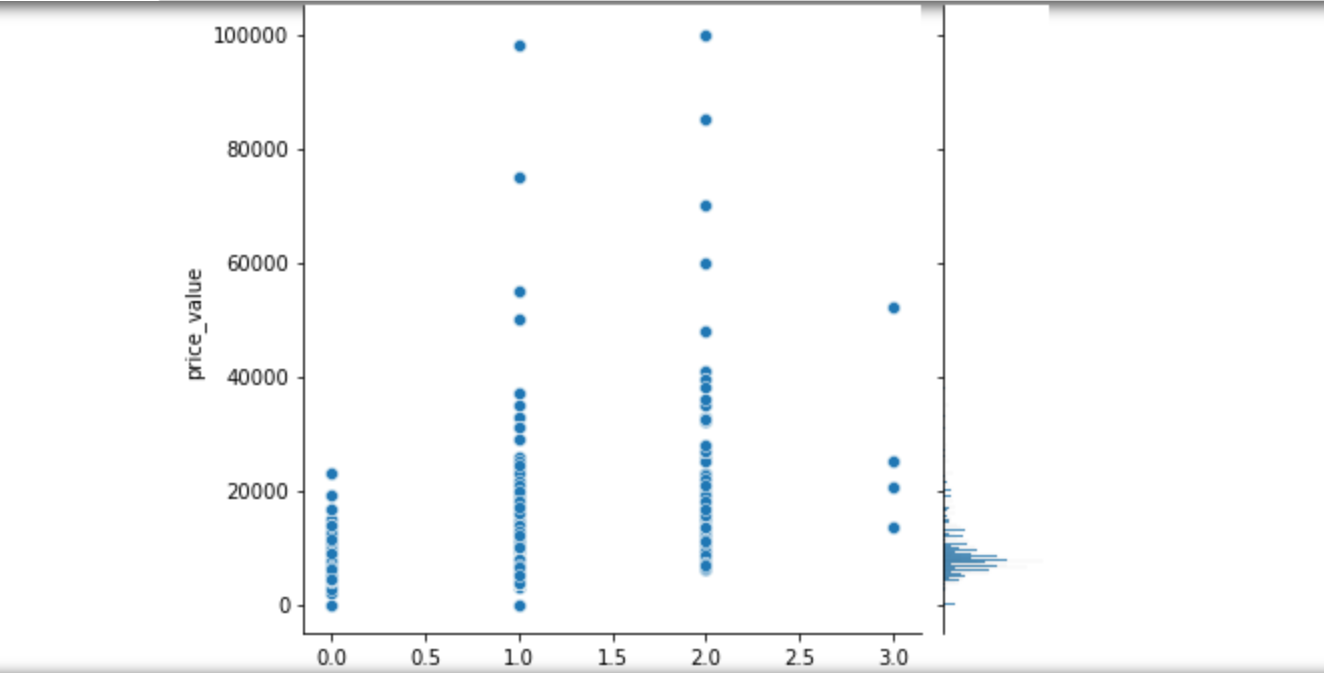
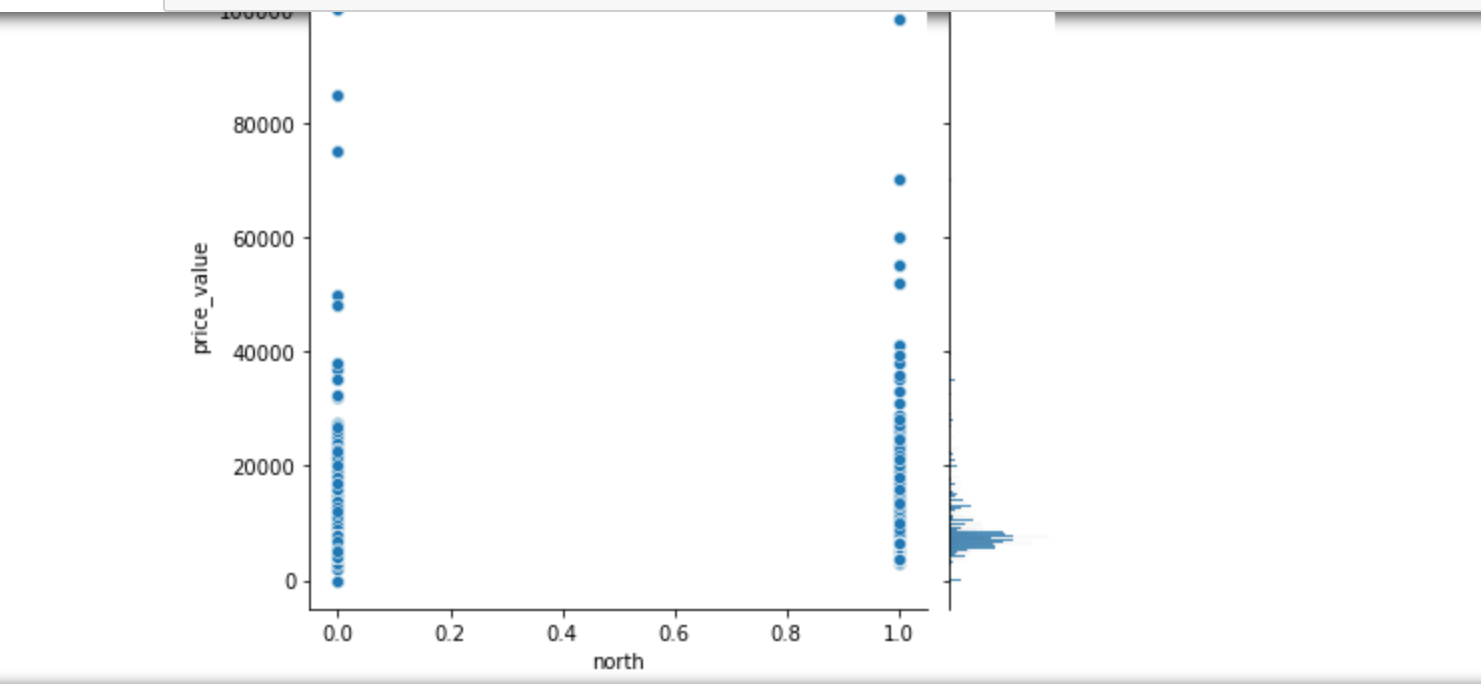
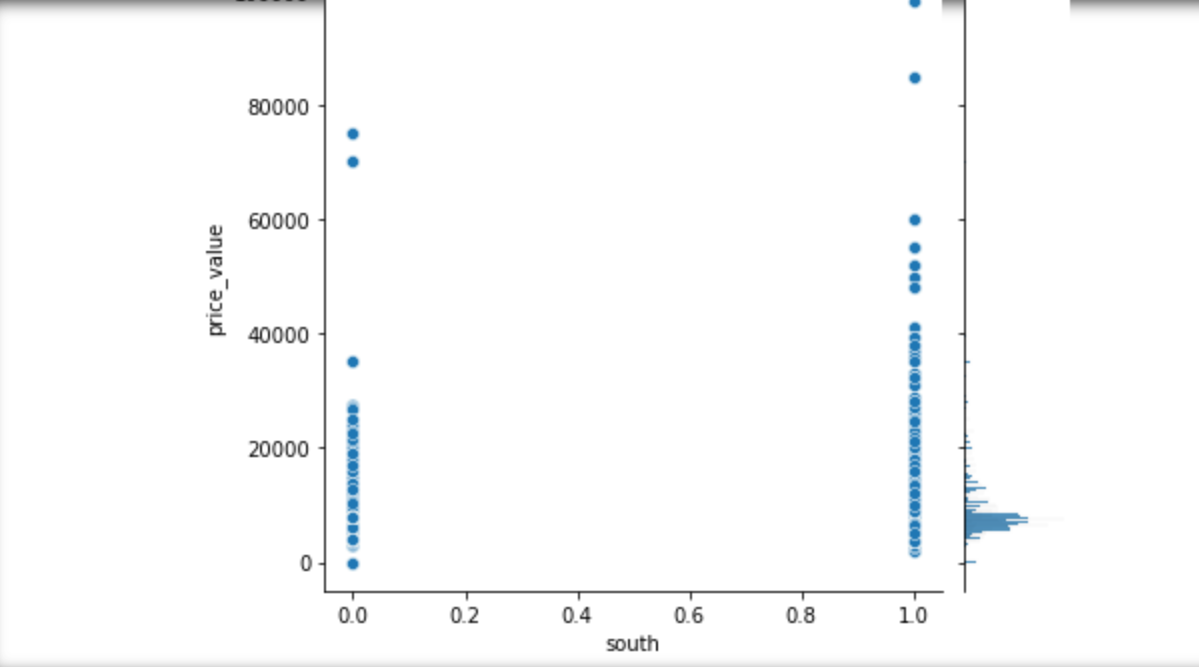
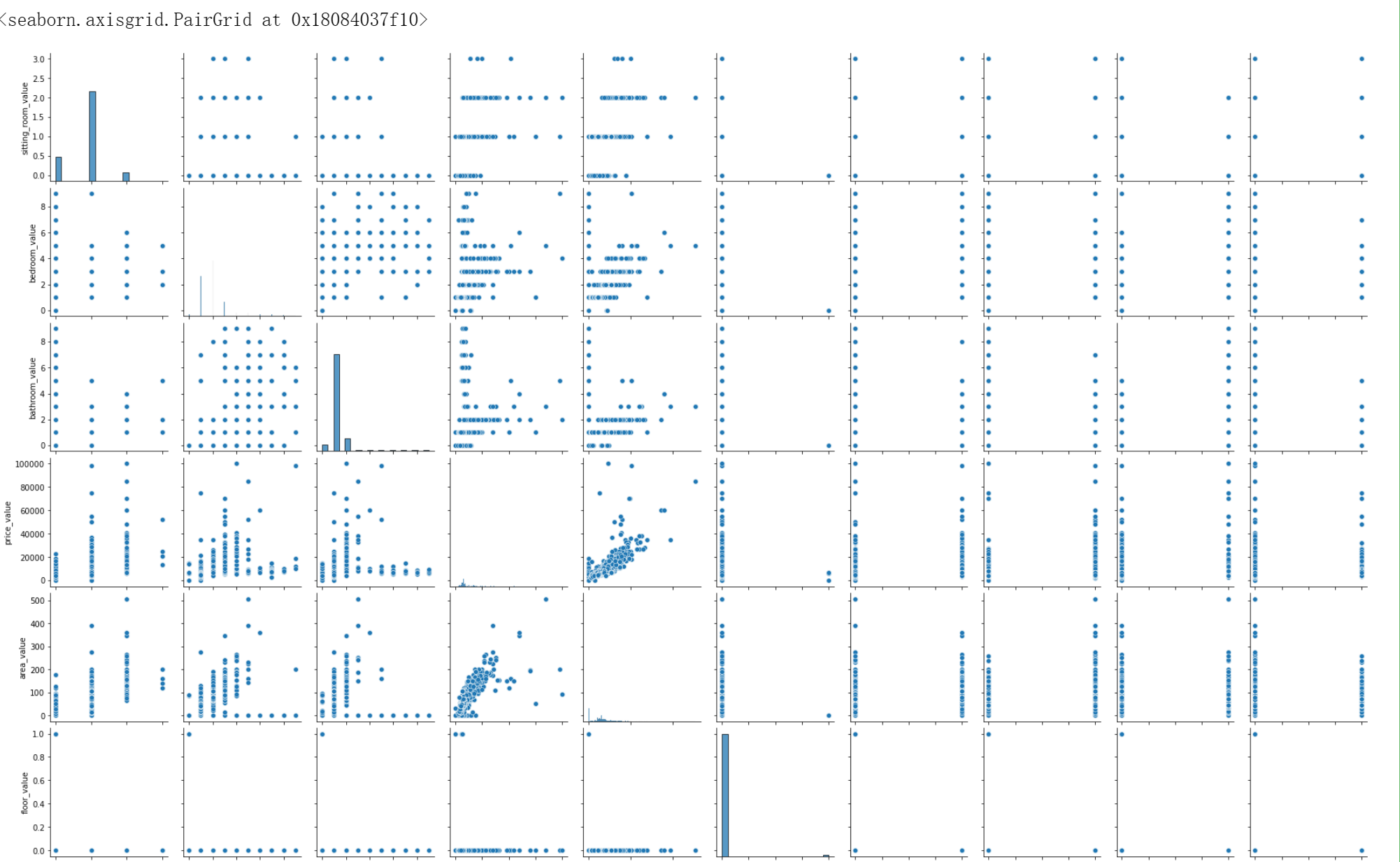
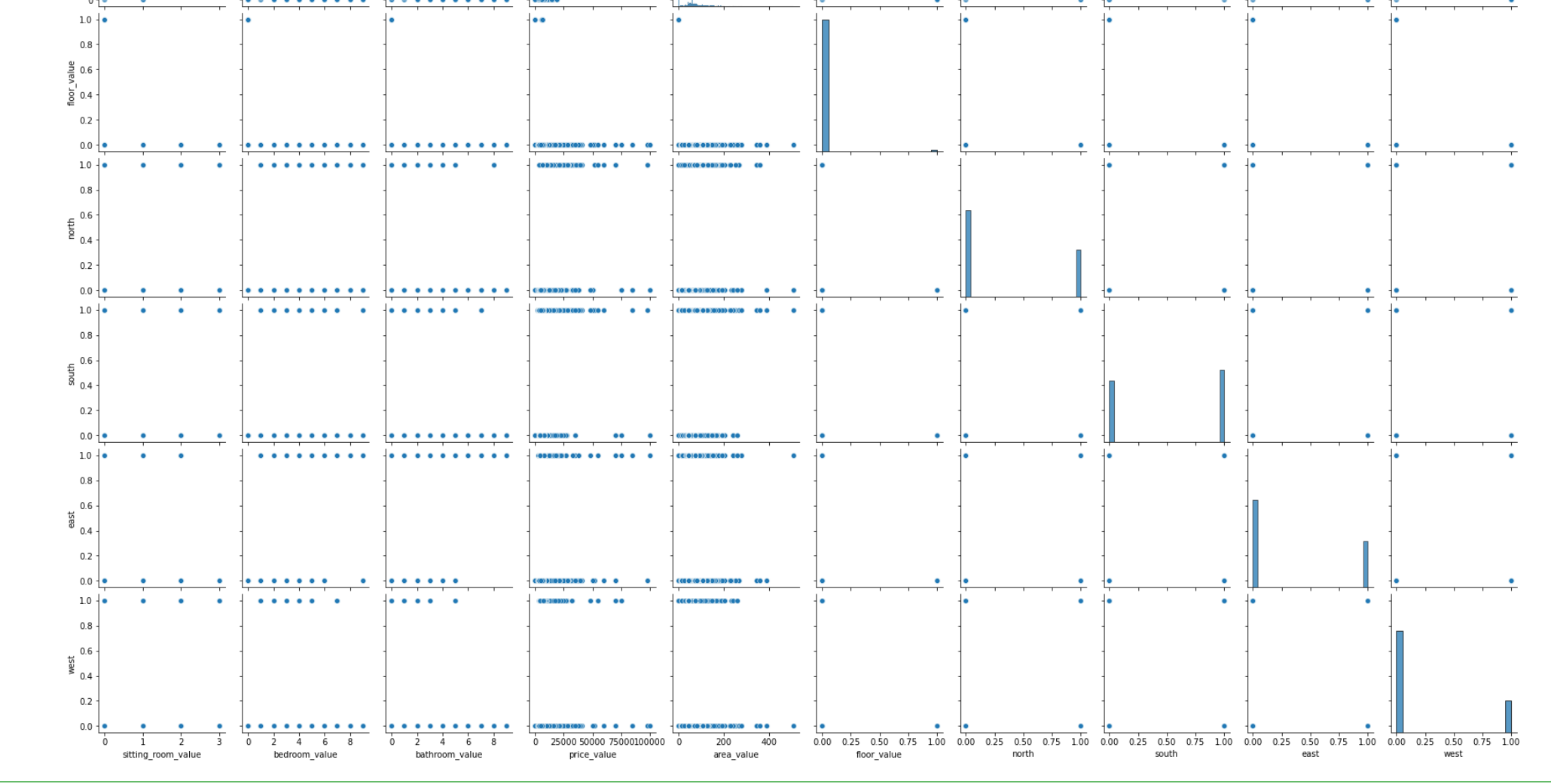
1 # 8.3 分析各因素之间可能存在的关系 2 3 sns.pairplot(values_data)
1 # 步骤9 数据分析:分位数回归 2 3 mod = smf.quantreg('price_value ~ area_value', values_data) 4 res = mod.fit(q=.5) 5 6 quantiles = np.arange(.05, .96, .1) 7 def fit_model(q): 8 res = mod.fit(q=q) 9 return [q, res.params['Intercept'], res.params['area_value']] + \ 10 res.conf_int().loc['area_value'].tolist() 11 12 models = [fit_model(x) for x in quantiles] 13 models = pd.DataFrame(models, columns=['q', 'a', 'b', 'lb', 'ub']) 14 15 ols = smf.ols('price_value ~ area_value', values_data).fit() 16 ols_ci = ols.conf_int().loc['area_value'].tolist() 17 ols = dict(a = ols.params['Intercept'], 18 b = ols.params['area_value'], 19 lb = ols_ci[0], 20 ub = ols_ci[1]) 21 22 print(models) 23 print(ols) 24 25 26 x = np.arange(values_data.area_value.min(), values_data.area_value.max(), 50) 27 get_y = lambda a, b: a + b * x 28 29 fig, ax = plt.subplots(figsize=(8, 6)) 30 31 for i in range(models.shape[0]): 32 y = get_y(models.a[i], models.b[i]) 33 ax.plot(x, y, linestyle='dotted', color='grey') 34 35 y = get_y(ols['a'], ols['b']) 36 37 ax.plot(x, y, color='red', label='OLS') 38 ax.scatter(values_data.area_value, values_data.price_value, alpha=.2) 39 40 legend = ax.legend() 41 ax.set_xlabel('Area', fontsize=16) 42 ax.set_ylabel('Price', fontsize=16);
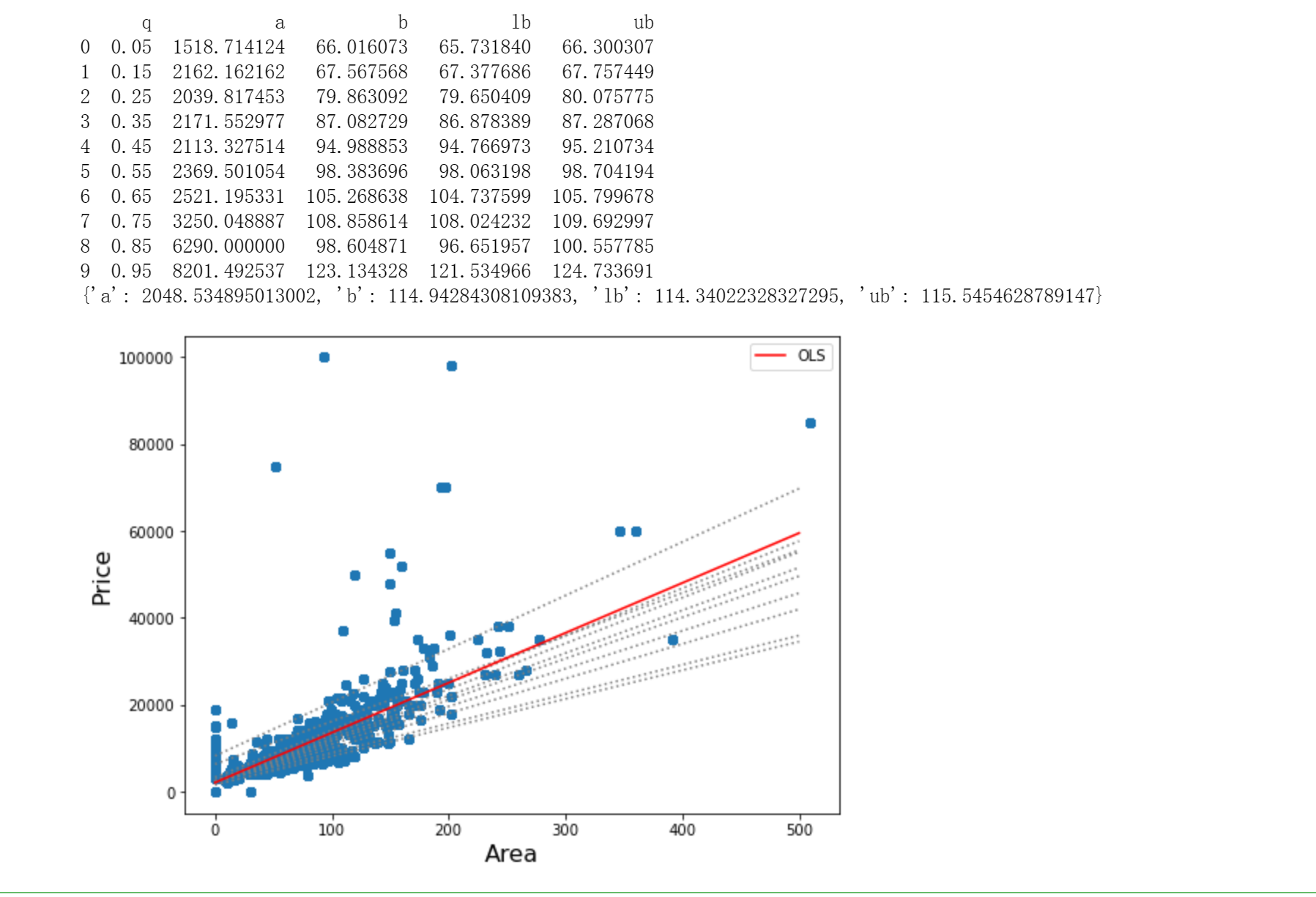
三、在爬虫和可视化是遇到的问题
1 #步骤7 读取已爬取的数据,并对数据进行数字化 2 data = pd.read_csv('./data.csv') 3 4 # 客厅数量 5 data['sitting_room_value'] = data['style'].apply(lambda x: x.split('厅')[0][-1]) 6 data['sitting_room_value'] = data['sitting_room_value'].replace('卫', 0) 7 8 # 卧室浴室数量 9 data['bedroom_value'] = data['style'].apply(lambda x: x[0]) 10 data['bathroom_value'] = data['style'].apply(lambda x: x[-2]) 11 12 # 价格、面积、楼层 13 data['price_value'] = data['price'].apply(lambda x: x[:-3]) 14 data['area_value'] = data['area'].apply(lambda x: x[:-1]) 15 data['floor_value'] = data['floor'].apply(lambda x: x.split('(')[-1][0]) 16 17 # 租房方位朝向 18 def toward(x, key=''): 19 if key in x: 20 return key 21 else: 22 return 0 23 data['north'] = data['toward'].apply(lambda x: toward(x, '北')).replace('北', 1) 24 data['south'] = data['toward'].apply(lambda x: toward(x, '南')).replace('南', 1) 25 data['east'] = data['toward'].apply(lambda x: toward(x, '东')).replace('东', 1) 26 data['west'] = data['toward'].apply(lambda x: toward(x, '西')).replace('西', 1) 27 28 29 30 # 提取全部的数值数据 31 values_data = data[['sitting_room_value', 'bedroom_value', 32 'bathroom_value', 'price_value', 'area_value', 33 'floor_value', 'north', 34 'south', 'east', 'west']].astype(float) 35 36 # 描述性统计 37 values_data.describe()
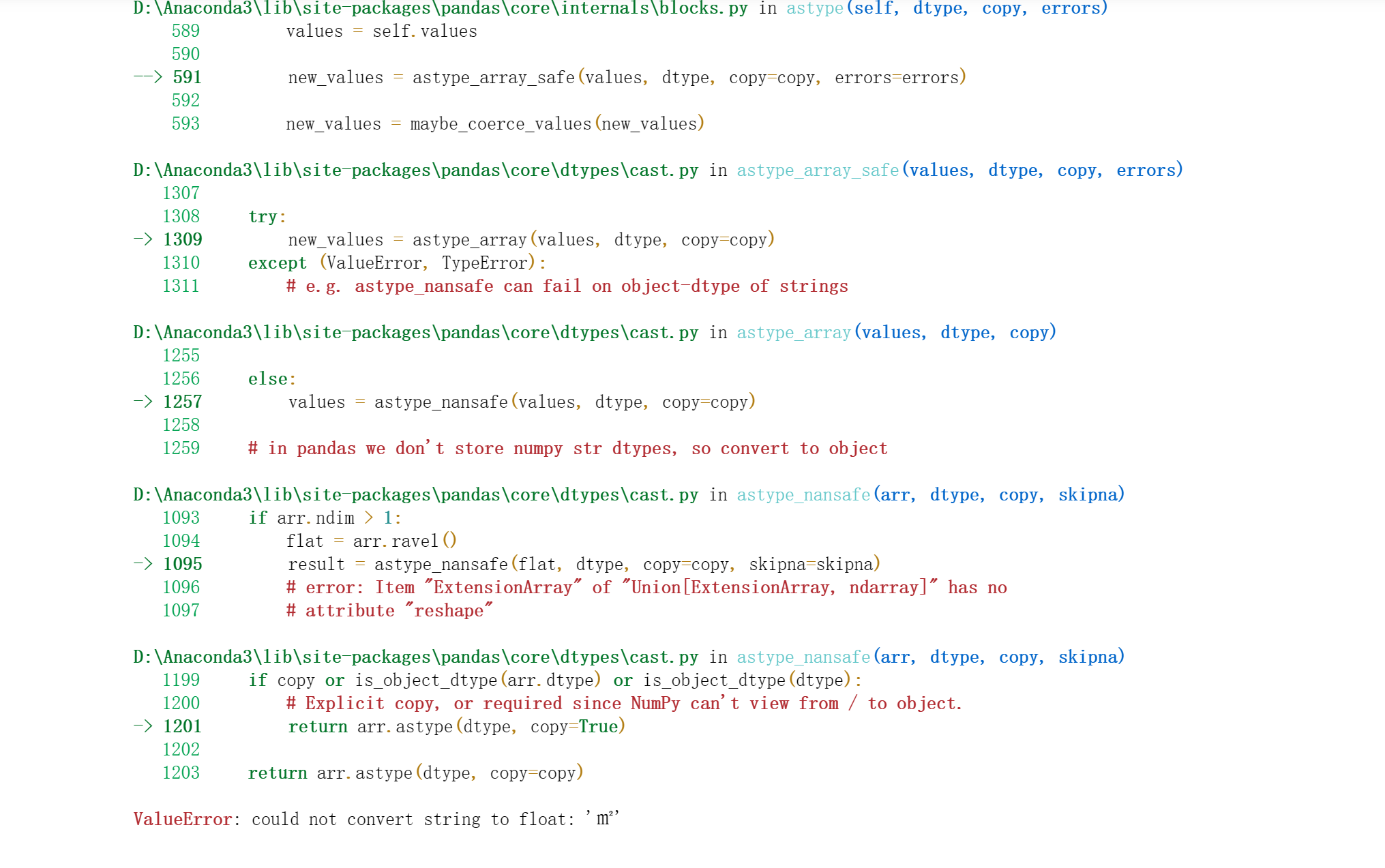
会显示出来could not convert string to float.
网上查询后知道问题所在:pandas导入csv文件后。有部分列是空的,列的类型为object格式,列中单元格存的是string格式;需求是把空的列(object)转化成浮点类型(float)
解决方案:在源代码中加入
1 col = list(data.columns) 2 data[col] = data[col].apply(pd.to_numeric, errors='coerce').fillna(0.0) 3 data = pd.DataFrame(data, dtype='float')
即代码变为上述报告代码,问题解决。