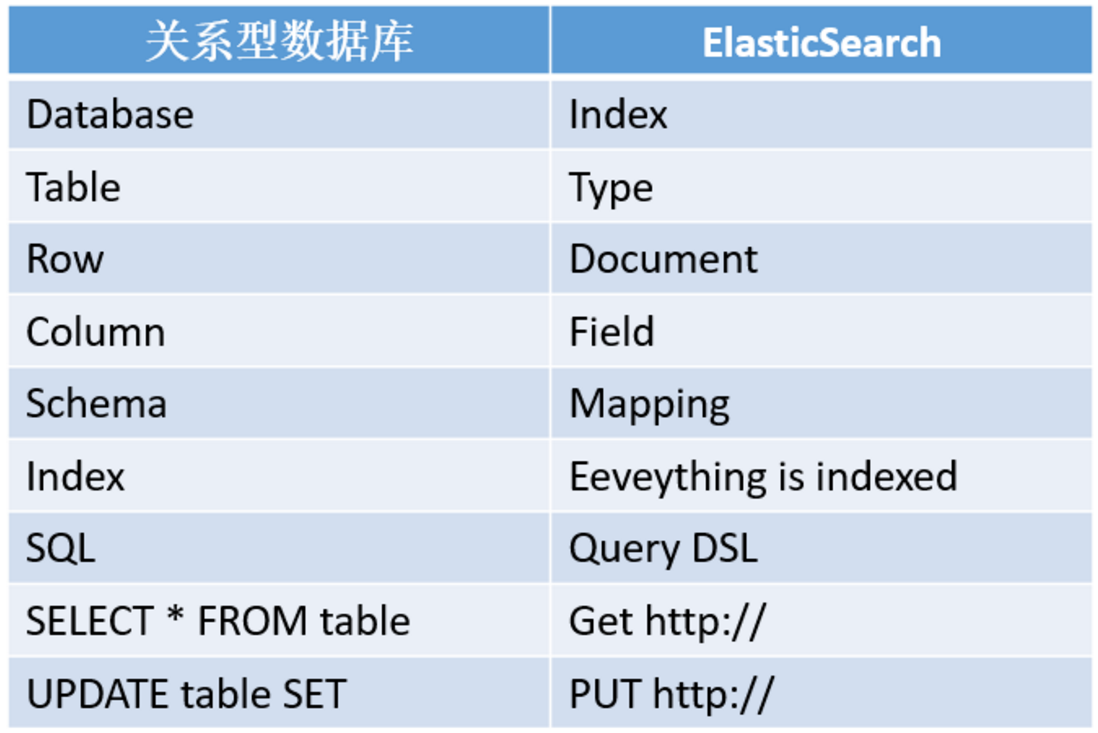
es 与关系型数据库
索引 index
- 索引是 ES 中最大的数据单元,相当于关系型数据库中,
库的概念。 - ES 中没有
表的概念,这是 ES 和数据库的一个区别,在我们建立索引之后,可以直接往索引中写入文档。 - 在
6.0版本之前,ES 中有Type的概念,可以理解成关系型数据库中的表,但是官方说这是一个设计上的失误,所以在6.0版本之后Type 就被废弃了。 - 一个索引由一个名字来标识(必须全部是小写字母的)
- 并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
字段 Field
- 字段在 ES 中可以理解为
JSON数据的键。
{
"name": "BNTang",
"age": 10
}
文档 Document
- 文档在 ES 中相当于传统数据库中的行的概念。
- ES 中的数据都以 JSON 的形式来表示,在 MySQL 中插入一行数据和 ES 中插入一个 JSON 文档是一个意思。
映射 Mapping
- 映射是对文档中每个字段的类型进行定义,每一种数据类型都有对应的使用场景。
- 例如:string 的数据会被作为全文本来处理,这种数据类型适合需要搜索的场景。
- 有些数据类型,你不需要对它进行搜索,相反需要对它做聚合运算,那么
keyword、integer数据类型就更合适。 - 每个文档都有映射,但是在大多数使用场景中,我们并不需要显示的创建映射,因为 ES 中实现了动态映射。
分片 Shards
- 在往索引中不断写入文档, 到了一定数量级,索引文件就会占满整个服务器的磁盘。
- 索引文件变的大,会严重降低搜索的效率。
- 使用分片把单索引文件分成多份存储, 且这些索引的分片可以分部在不同的机器上,假设单台机器磁盘容量
1TB,现在需要存放2TB的索引数据,那就可以把2TB索引分成4份,分别存放到4台机器上每份500G。
集群 cluster
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。
副本 Replicas
- 一个索引可以分成多个分片,分部在不同的机器上。
- 为了解决索引高可用的问题,ES 引入了副本机制。
- 副本指的就是分片的副本,分片的原始数据称为主分片,主分片和副本会放在不同的机器上。
- 这样假设有一个分片丢失了,另外的分片可以作为后备。
- 如果主分片的机器挂掉了,其中一个副本分片就会升级成主分片。
词项 term
- ES 会先把大文本切割成很多个小的词,这些词就是我们所说的词项,它是 ES 搜索的
最小单位,每个查询都是按词项搜索的。
分析器 Analyzers
- ES 中不会把一篇文章直接存入磁盘,在存储时它会先对文本进行分析。
- 分析器的就是用来分析这些文本,中间包括过滤、分词等过程,经过分析处理后再存储到磁盘。
节点 Node & 集群 Cluster
节点就是一个 ElasticSearch 进程,当我们启动一个 ElasticSearch 程序,就启动了一个节点,很多个节点集合在一起就成了集群。
节点也分多种类型,每个节点都有各自的职责:
- 主节点
- 数据节点
- 协调节点
- Ingest 节点
单节点
- 如果集群中只有单个节点,可以把它看成只有单个节点的集群。
- 那这个节点会扮演多个节点的角色,它需要独自完成整个搜索和索引的过程。
- 会默认创建并加入一个叫做
“elasticsearch”的集群。