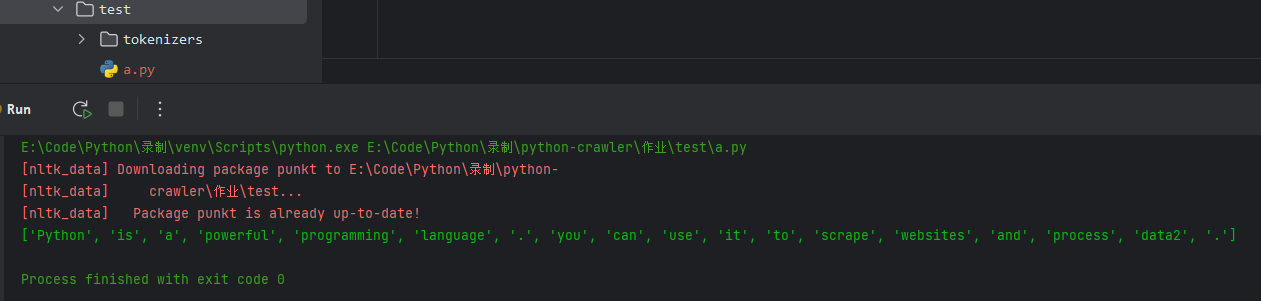
# 使用 NLTK 进行文本处理
import nltk
from nltk.tokenize import word_tokenize
path = r"E:\Code\Python\录制\python-crawler\作业\test"
nltk.data.path.append(path) # 添加你想要的文件夹路径
# 确保资源文件下载到指定文件夹
nltk.download('punkt', download_dir=path)
text = "Python is a powerful programming language. you can use it to scrape websites and process data2."
tokens = word_tokenize(text)
print(tokens)