1、什么是NoSQL
NoSQL(Not only SQL)是对不同于传统的关系数据库的数据库管理系统的统称,即广义地来说可以把所有不是关系型数据库的数据库统称为NoSQL。
NoSQL 数据库专门构建用于特定的数据模型,并且具有灵活的架构来构建现代应用程序。NoSQL 数据库使用各种数据模型来访问和管理数据。这些类型的数据库专门针对需要大数据量、低延迟和灵活数据模型的应用程序进行了优化,这是通过放宽其他数据库的某些数据一致性限制来实现的。
数十年来,用于应用程序开发的主要数据模型是由关系数据库(如 Oracle、DB2、SQL Server、MySQL 和 PostgreSQL)使用的关系数据模型。直到 21 世纪中后期,才开始大规模采用和使用其他数据模型。为了对这些新类别的数据库和数据模型进行区分和分类,创造了术语“NoSQL”。通常术语“NoSQL”与“非关系”可互换使用。
1.1 NoSQL的常见类型
键值数据库
键值:键值数据库是高度可分区的,并且允许以其他类型的数据库无法实现的规模进行水平扩展。诸如游戏、广告技术和 IoT 等使用案例本身特别适合键值数据模型。Amazon DynamoDB 旨在为任意规模的工作负载提供一致且低于 10 毫秒的延迟。这种一致的性能是为何使用 Snapchat Stories 功能的主要原因,该功能包含移至 DynamoDB 的 Snapchat 的最大存储写入工作负载。
键值数据库是一种非关系数据库,它使用简单的键值方法来存储数据。键值数据库将数据存储为键值对集合,其中键作为唯一标识符。键和值都可以是从简单对象到复杂复合对象的任何内容。键值数据库是高度可分区的,并且允许以其他类型的数据库无法实现的规模进行水平扩展。
内存数据库
内存:游戏和广告技术应用程序具有排行榜、会话存储和实时分析等使用案例,它们需要微秒响应时间并且可能随时出现大规模的流量高峰。
文档数据库
文档:在应用程序代码中,数据通常表示为对象或 JSON 文档,因为对开发人员而言它是高效和直观的数据模型。文档数据库让开发人员可以使用他们在其应用程序代码中使用的相同文档模型格式,更轻松地在数据库中存储和查询数据。文档和文档数据库的灵活、半结构化和层级性质允许它们随应用程序的需求而变化。文档模型可以很好地与目录、用户配置文件和内容管理系统配合使用,其中每个文档都是唯一的,并会随时间而变化。
文档数据库是一种非关系数据库,旨在将数据作为类 JSON 文档存储和查询。文档数据库让开发人员可以使用他们在其应用程序代码中使用的相同文档模型格式,更轻松地在数据库中存储和查询数据。文档和文档数据库的灵活、半结构化和层级性质允许它们随应用程序的需求而变化。文档模型可以很好地与目录、用户配置文件和内容管理系统等使用案例配合使用,其中每个文档都是唯一的,并会随时间而变化。文档数据库支持灵活的索引、强大的临时查询和文档集合分析。
图形数据库
图形:图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。热门图形数据库包括 Neo4j 和 Giraph。图形数据库专门用于存储和导航关系。关系是图形数据库中的一等公民,图形数据库的大部分价值都源自于这些关系。图形数据库使用节点来存储数据实体,并使用边缘来存储实体之间的关系。边缘始终有一个开始节点、结束节点、类型和方向,并且边缘可以描述父子关系、操作、所有权等。一个节点可以拥有的关系的数量和类型没有限制。
图形数据库中的图形可依据具体的边缘类型进行遍历,或者也可对整个图形进行遍历。在图形数据库中,遍历联结或关系非常快,因为节点之间的关系不是在查询时计算的,而是留存在数据库中。在社交网络、推荐引擎和欺诈检测等使用案例中,您需要在数据之间创建关系并快速查询这些关系,此时,图形数据库更具优势。
搜索数据库
搜索:许多应用程序输出日志以帮助开发人员解决问题。搜索引擎数据库是一种非关系数据库,专用于数据内容的搜索。搜索引擎数据库使用索引对数据之间的相似特征进行分类,并增强搜索功能。搜索引擎数据库经过优化,可处理可能是长数据,半结构数据或非结构数据的数据,并且它们通常提供专门的方法,例如全文搜索,复杂的搜索表达式和搜索结果排名。
1.2 关系型数据库和NoSQL

1.3 分布式系统的CAP原理
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Partition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
1.3 NoSQL的BASE原则
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency -- 最终一致性, 也是是 ACID 的最终目的。
BASE模型是传统ACID模型的反面,不同于ACID,BASE强调牺牲高一致性,从而获得可用性,数据允许在一段时间内的不一致,只要保证最终一致就可以了。
2、MongoDB
MongoDB 是由C++语言编写的基于分布式文件存储的开源数据库系统(document database)。MongoDB数据库中的记录称为文档(document),是一种由字段和值(field and value)成对组成的key-value键值型数据结构,格式上和常用的json格式类似,字段的值可以包括其他文档,数组和文档数组。
{
name: "sue",
age: 26,
status: "A",
groups: ["news","sports"]
}使用文档的主要优势在于可以支持许多编程语言的原生数据类型,避免不必要的join操作以及动态的schema模式可以流畅地支持多态类型。
Dynamic schema supports fluent polymorphism。
MongoDB将文档存储到集合(collections)中,集合与关系型数据库中的数据表类似。除了集合之外,MongoDB还支持只读视图(3.4)和按需实例化视图(4.2)。
除了最主要的文档特性外,MongoDB还具有以下特性:
2.1 High Performance
MongoDB提供了高性能的数据持久化存储功能,主要是
- 通过支持嵌入式的数据模型来减少数据库系统的I/O操作
- 索引支持更快的查询,并且可以包括来自嵌入式文档和数组的键
2.2 Rich Query Language
MongoDB提供了丰富的查询语句用于支持CRUD等操作,除了常规的查询语句还支持如
Data Aggregation(数据聚合)、Text Search 、 Geospatial Queries和mapping等操作
- 聚合操作(Data Aggregation)处理数据记录并返回计算结果。聚合操作将来自多个文档的值组合在一起,并且可以对分组的数据执行各种操作以返回单个结果。MongoDB提供了三种执行聚合的方式:聚合管道,map-reduce函数和单一目的聚合方法。
- MongoDB支持使用文本索引和
$text运算符执行字符串内容的文本搜索的查询操作。 - MongoDB还支持地理空间位置的查询操作
2.3 High Availability
MongoDB的复制工具(称为副本集 )提供自动故障转移和数据冗余功能。副本集是一组维护相同数据集的MongoDB服务器,可提供冗余并提高数据可用性.
2.4 Horizontal Scalability
MongoDB的核心功能之一就是提供水平扩展能力。
- 分片将数据分布在一组计算机上。
- 从3.4开始,MongoDB支持基于分片键创建数据区域。在均衡的集群中,MongoDB仅将区域覆盖的读写定向到区域内的那些分片。
2.5 Support for Multiple Storage Engines
MongoDB支持多种存储引擎,如WiredTiger和In-Memory 。此外,MongoDB还提供了存储引擎的API插件供第三方开发者开发存储引擎。
3、Memcached
自由和开放源代码,高性能,分布式内存对象缓存系统,本质上是通用的,但旨在通过减轻数据库负载来加速动态Web应用程序。Memcached是一个内存中的键值存储,用于存储来自数据库调用,API调用或页面渲染结果的任意数据(字符串,对象)。Memcached简单但功能强大。其简单的设计可促进快速部署,易于开发,并解决了大型数据缓存面临的许多问题。它的API适用于大多数流行语言。Memcached对其特点介绍主要有以下几点:
3.1 Simple Key/Value Store
Memcached的服务端并不在乎用户的数据具体是怎么样的,每一个项目/Item(相当于MySQL中的行)是由key、过期时间、标记/flags(可选)和原始数据组成。Memcached并不知道数据的数据结构,因此用户端必须要上传预序列化的数据。
3.2 Logic Half in Client, Half in Server
一个完整的memcached过程实现是需要客户端和服务端共同完成的,也就是说有部分操作在客户端完成而另一部分在服务端完成。客户端负责选择哪一个服务器来进行读写和无法与服务器建立通信连接的时候该如何操作;服务器负责存储和拉取item,同时还负责内存的释放和复用等工作。
3.3 Servers are Disconnected From Each Other
Memcached集群之间的服务器互相并不知道对方的存在,他们不交流、不同步、不广播、不复制,往集群中添加服务器就可以直接增加整个集群的可用内存。当客户端删除或者覆盖了记录该客户端的缓存数据的服务器的时候,缓存就会失效。
3.4 O(1)
所有的命令实现起来都很快并且对加锁十分友好,这为所有用例提供了近乎确定的查询速度。官方表示对于比较慢的机器每次查询都在1ms以下,而高端服务器可以实现每秒百万的吞吐。
Queries on slow machines should run in well under 1ms. High end servers can serve millions of keys per second in throughput.
3.5 Forgetting is a Feature
Memcached默认使用LRU算法和懒惰回收机制。items会在指定的时间后失效,但不是失效后就马上把item从内存中删除,而是当内存不足需要新的内存来建立item时再去查找已经过期的item将其删除并释放内存。当没有过期的item且当内存不足时,Memcached会清除内存中尚未过期但是很久没有被使用的数据来释放内存从而保留那些被频繁访问的数据
3.6 Cache Invalidation
Memcached使用哈希算法,因此客户端不是直接向所有可用主机广播更改,而是根据哈希表的记录直接访问保存有待失效数据的服务器。
4、Redis
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis是一个基于BSD开源协议的,内存中的数据结构存储系统,可以用于数据库、缓存和消息中间件。它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的数据持久化(persistence), 并通过 Redis哨兵(Sentinel)和redis集群的自动分区提供高可用性。
4.1 Redis vs Memcached
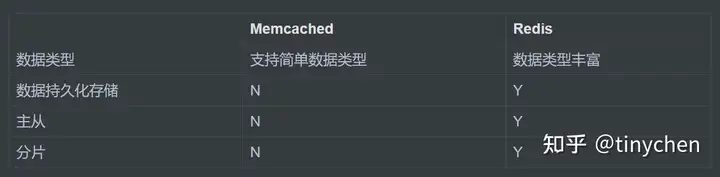
缓存中间件 Memcache 和 Redis 的区别
4.2 Redis的特点
- redis 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高。
- redis 使用单进程单线程模型的(K,V)数据库,将数据存储在内存中,存取均不会受到硬盘 IO 的限制,因此其执行速度极快。
另外单线程也能处理高并发请求,还可以避免频繁上下文切换和锁的竞争,如果想要多核运行也可以启动多个实例。
当然了,单线程也会有它的缺点,也是Redis的噩梦:阻塞。如果执行一个命令过长,那么会造成其他命令的阻塞,对于Redis是十分致命的,所以Redis是面向快速执行场景的数据库。 - 数据结构简单,对数据操作也简单,Redis 不使用表,不会强制用户对各个关系进行关联,不会有复杂的关系限制,其存储结构就是键值对,类似于 HashMap,HashMap 最大的优点就是存取的时间复杂度为 O(1)。
- redis 使用I/O 多路复用模型,属于非阻塞 IO。Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll的read、write、close等都转换成事件,不在网络I/O上浪费过多的时间。实现对多个FD读写的监控,提高性能。