常见监控软件介绍
Cacti
Cacti 是一套基于 PHP、MySQL、SNMP 及 RRD Tool 开发的监测图形分析工具,Cacti 是使用轮询的方式由主服务器向设备发送数据请求来获取设备上状态数据信息的,如果设备不断增多,这个轮询的过程就非常的耗时,轮询的结果就不能即时的反应设备的状态了。Cacti 监控关注的是对数据的展示,却不关注数据异常后的反馈。如果凌晨 3 点的时候设备的某个数据出现异常,除非监控人员在屏幕前发现这个异常变化,否则是没有任何报警机制能够让我们道出现了异常。
Nagios
Nagios 是一款开源的免费网络监控报警服务,能有效监控 Windows、Linux 和 Unix 的主机状态,交换机、路由器和防火墙等网络设置,打印机、网络投影、网络摄像等设备。在系统或服务状态异常时发出邮件或短信报警第一时间通知运维人员,在状态恢复后发出正常的邮件或短信通知。Nagios 有完善的插件功能,可以方便的根据应用服务扩展功能。Nagios 已经可以支持由数万台服务器或上千台网络设备组成的云技术平台的监控,它可以充分发挥自动化运维技术特点在设备和人力资源减少成本。只是 Nagios 无法将多个相同应用集群的数据集合起来,也不能监控到集群中特殊节点的迁移和恢复。
Ganglia
Ganglia 是 UC Berkeley 发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia 的核心包含 gmond、gmetad 以及一个 Web 前端。主要是用来监控系统性能,如:CPU 、内存、硬盘利用率, I/O 负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体 性能起到重要作用,目前是监控HADOOP 的官方推荐服务。
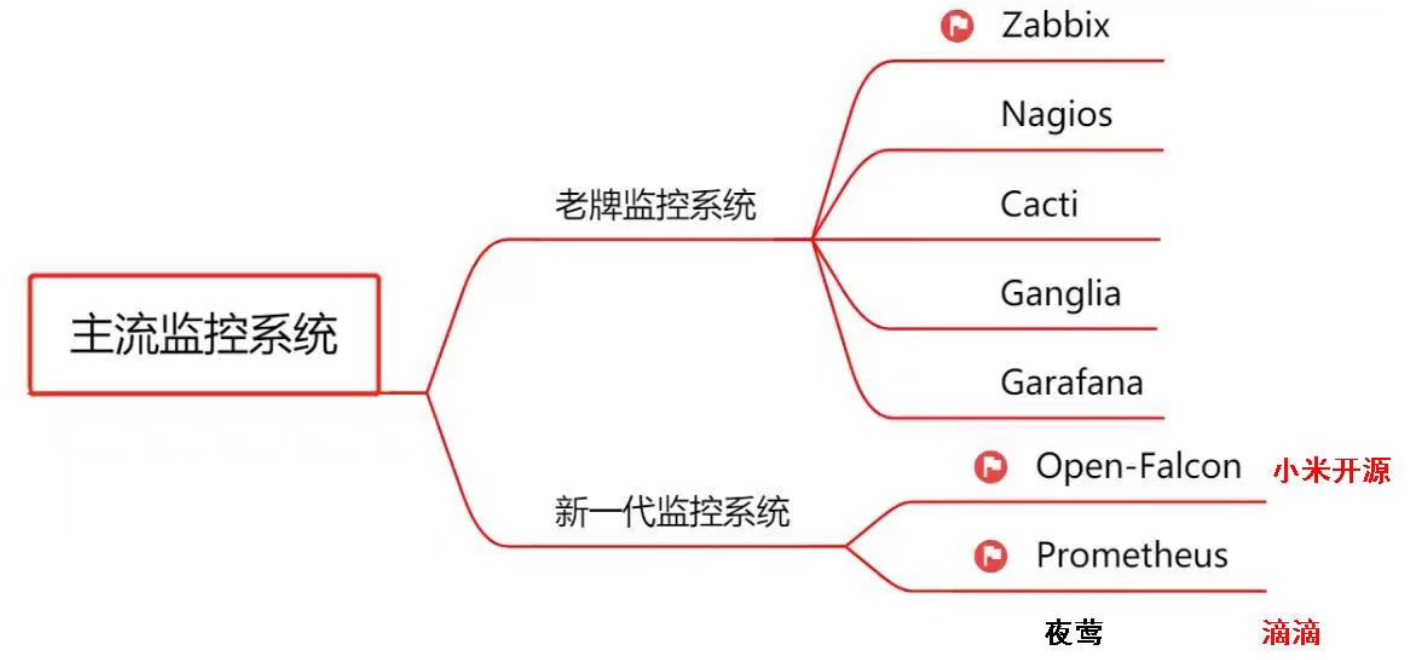
zabbix
zabbix 是一个基于 Web 界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
zabbix 能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题
zabbix 由 2 部分构成,zabbix server 与可选组件 zabbix agent。通过 C/S 模式采集数据,通过 B/S 模式在 Web 端展示和配置
zabbix server 可以通过 zabbix agent,SNMP协议,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行在 Linux 等平台上
zabbix agent 需要安装在被监视的目标服务器上,它主要完成对硬件信息或与操作系统有关的内存,CPU 等信息的收集
为什么选择zabbix呢?先来看下其具有的特点
1,自动发现服务器和网络设备
2,底层自动发现
3,分布式的监控体系和集中式的web管理
4,支持主动监控和被动监控模式
5,支持多种操作系统 Linux, Solaris, HP-UX, AIX, FreeBSD, OpenBSD, OS X
6,高效的agent 支持 Linux, Solaris, HP-UX, AIX, FreeBSD, OpenBSD,OS X, Tru64/OSF1, Windows NT4.0, Windows 2000, Windows 2003, Windows XP, Windows Vista 环境
7,无agent监控等多种监控方法
8,安全的用户认证模式
9,灵活的用户权限设置
10,基于web的管理方法
11,支持自由的自定义事件和邮件发送
12,高水平的业务视图监控资源
13,支持日志审计
zabbix优点
- 开源,无软件成本投入
- Server 对设备性能要求低
- 支持设备多,自带多种监控模板
- 支持分布式集中管理,有自动发现功能,可以实现自动化监控
- 当监控的 item 比较多服务器队列比较大时可以采用主动状态,被监控客户端主动 从server 端去下载需要监控的 item 然后取数据上传到 server 端。 这种方式对服务器的负载比较小。Api 的支持,方便与其他系统结合
zabbix缺点
- 需在被监控主机上安装 agent,所有数据都存在数据库里, 产生的数据据很大,瓶颈主要在数据库
- 项目批量修改不方便
- 系统级别报警设置相对比较多,如果不筛选的话报警邮件会很多;并且自定义的项目报警需要自己设置,过程比较繁琐
- 缺少数据汇总功能,如无法查看一组服务器平均值,需进行二次开发
zabbix的组件及进程
组件
1、Zabbix Server:负责接收agent发送的报告信息的核心组件,所有配置,统计数据及操作数据均由其组织进行;
2、Database Storage:专用于存储所有配置信息,以及由zabbix收集的数据;
3、Web interface:zabbix的GUI接口,通常与Server运行在同一台主机上;
4、Proxy:可选组件,常用于分布监控环境中,代理Server收集部分被监控端的监控数据并统一发往Server端;
5、Agent:部署在被监控主机上,负责收集本地数据并发往Server端或Proxy端;
注:zabbix node也是 zabbix server的一种 。
进程
默认情况下zabbix包含5个程序:zabbix_agentd、zabbix_get、zabbix_proxy、zabbix_sender、zabbix_server,另外一个zabbix_java_gateway是可选,这个需要另外安装。下面来分别介绍下他们各自的作用。
zabbix_agentd
客户端守护进程,此进程收集客户端数据,例如cpu负载、内存、硬盘使用情况等。
zabbix_get
zabbix工具,单独使用的命令,通常在server或者proxy端执行获取远程客户端信息的命令。通常用户排错。例如在server端获取不到客户端的内存数据,我们可以使用zabbix_get获取客户端的内容的方式来做故障排查。
zabbix_sender
zabbix工具,用于发送数据给server或者proxy,通常用于耗时比较长的检查。很多检查非常耗时间,导致zabbix超时。于是我们在脚本执行完毕之后,使用sender主动提交数据。
zabbix_server
zabbix服务端守护进程。zabbix_agentd、zabbix_get、zabbix_sender、zabbix_proxy、zabbix_java_gateway的数据最终都是提交到server
备注:当然不是数据都是主动提交给zabbix_server,也有的是server主动去取数据。
zabbix_proxy
zabbix代理守护进程。功能类似server,唯一不同的是它只是一个中转站,它需要把收集到的数据提交/被提交到server里。
zabbix_java_gateway
zabbix2.0之后引入的一个功能。顾名思义:Java网关,类似agentd,但是只用于Java方面。需要特别注意的是,它只能主动去获取数据,而不能被动获取数据。它的数据最终会给到server或者proxy。
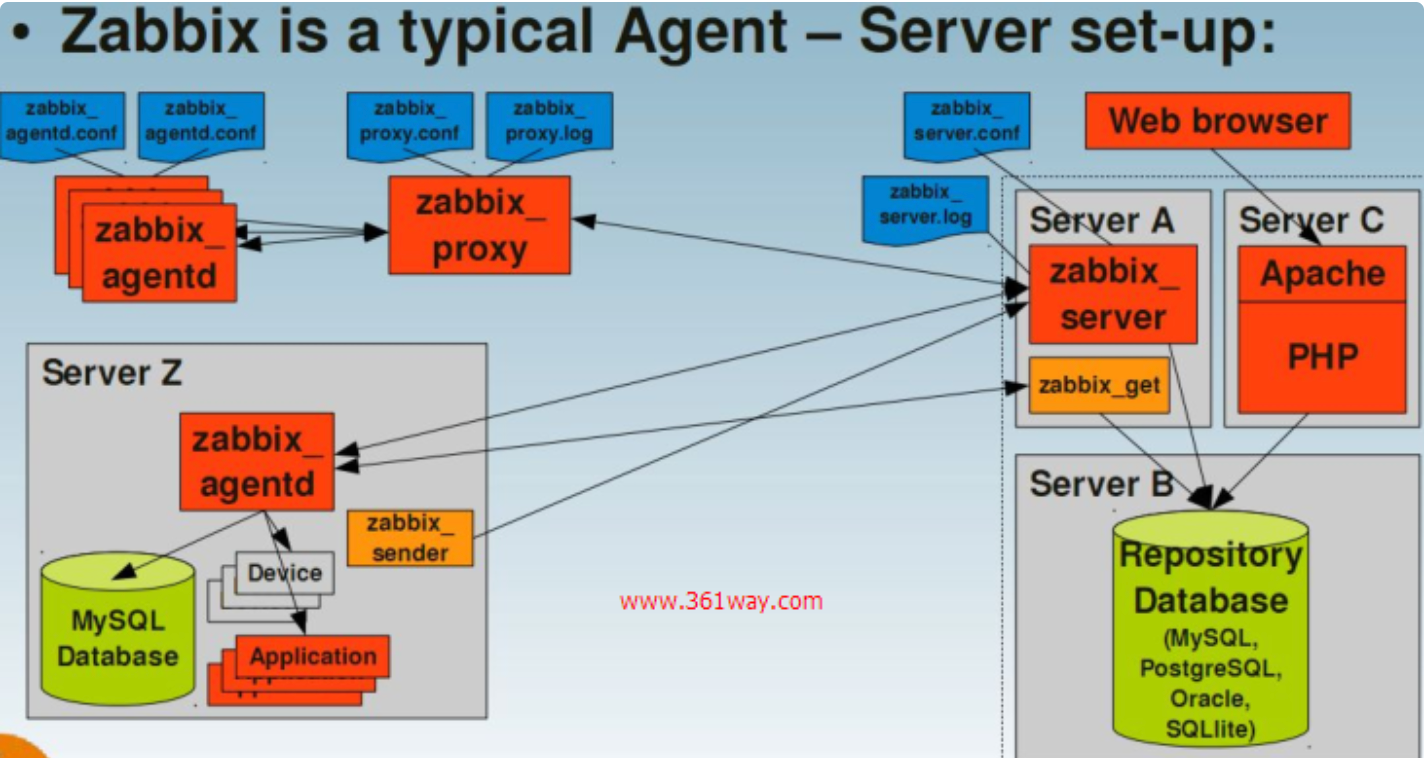
下图是zabbix的逻辑关系图:
zabbix监控环境中相关术语
1、主机(host):要监控的网络设备,可由IP或DNS名称指定;
2、主机组(host group):主机的逻辑容器,可以包含主机和模板,但同一个组织内的主机和模板不能互相链接;主机组通常在给用户或用户组指派监控权限时使用;
3、监控项(item):一个特定监控指标的相关的数据;这些数据来自于被监控对象;item是zabbix进行数据收集的核心,相对某个监控对象,每个item都由"key"标识;
4、触发器(trigger):一个表达式,用于评估某监控对象的特定item内接收到的数据是否在合理范围内,也就是阈值;接收的数据量大于阈值时,触发器状态将从"OK"转变为"Problem",当数据再次恢复到合理范围,又转变为"OK";
5、事件(event):触发一个值得关注的事情,比如触发器状态转变,新的agent或重新上线的agent的自动注册等;
6、动作(action):指对于特定事件事先定义的处理方法,如发送通知,何时执行操作;
7、报警升级(escalation):发送警报或者执行远程命令的自定义方案,如每隔5分钟发送一次警报,共发送5次等;
8、媒介(media):发送通知的手段或者通道,如Email、Jabber或者SMS等;
9、通知(notification):通过选定的媒介向用户发送的有关某事件的信息;
10、远程命令(remote command):预定义的命令,可在被监控主机处于某特定条件下时自动执行;
11、模板(template):用于快速定义被监控主机的预设条目集合,通常包含了item、trigger、graph、screen、application以及low-level discovery rule;模板可以直接链接至某个主机;
12、应用(application):一组item的集合;
13、web场景(web scennario):用于检测web站点可用性的一个活多个HTTP请求;
14、前端(frontend):Zabbix的web接口;
下图是一个zabbix的流程图,其串联了各术语之间的关系

zabbix的监控架构
在实际监控架构中,zabbix根据网络环境、监控规模等 分了三种架构: server-client 、master-node-client、server-proxy-client三种
server-client架构

上图是server-client架构,也是zabbix的最简单的架构,监控机和被监控机之间不经过任何代理 ,直接由zabbix server和zabbix agentd之间进行数据交互。适用于网络比较简单,设备比较少的监控环境
server-proxy-client架构
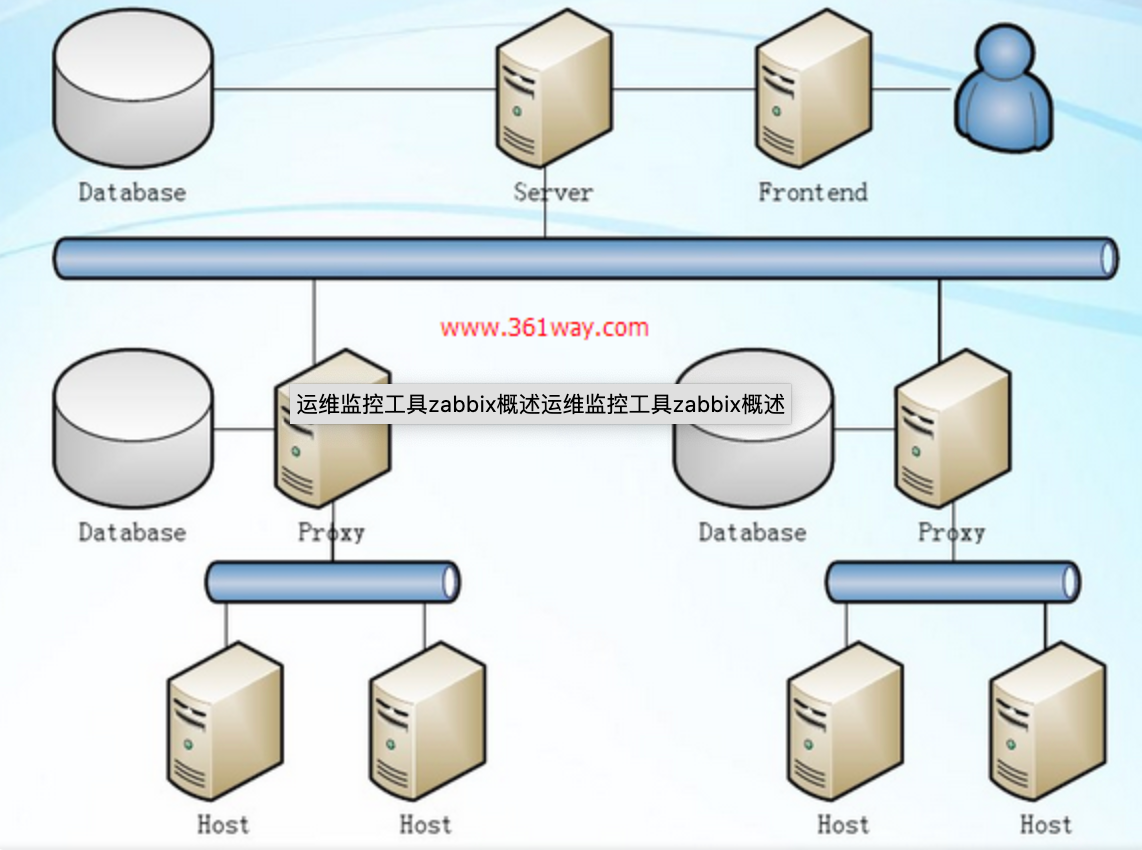
上图是server-proxy-client架构,其中proxy是server、client之间沟通的一个桥梁,proxy本身没有前端,而且其本身并不存放数据,只是将agentd发来的数据暂时存放,而后再提交给server 。该架构经常是和master-node-client架构做比较的架构 ,一般适用于跨机房、跨网络的中型网络架构的监控
master-node-client架构
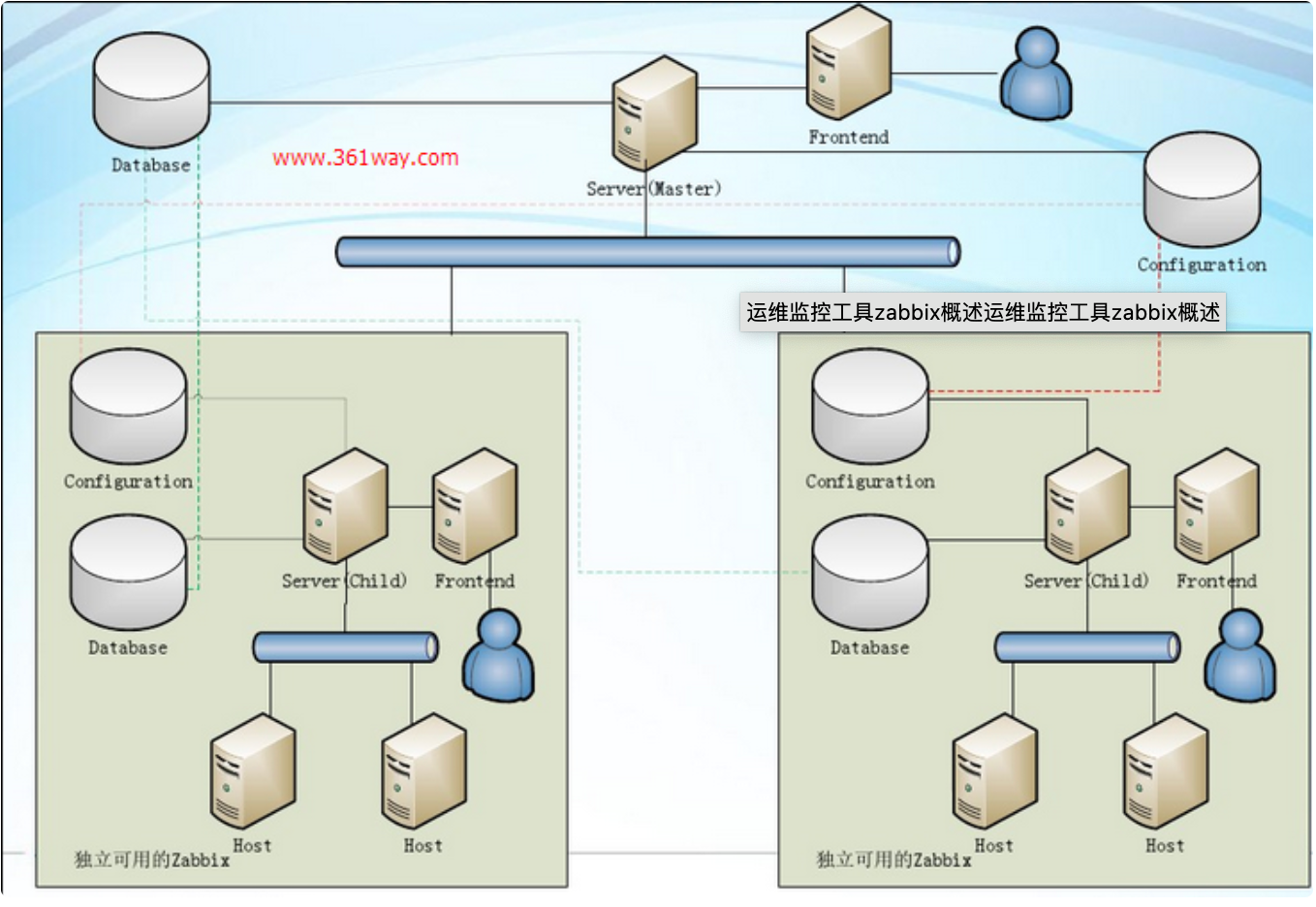
上图是master-node-client架构,该架构是zabbix最复杂的监控架构,适用于跨网络、跨机房、设备较多的大型环境 。每个node同时也是一个server端,node下面可以接proxy,也可以直接接client 。node有自已的配置文件和数据库,其要做的是将配置信息和监控数据向master同步,master的故障或损坏对node其下架构的完整性
zabbix监控方式
被动模式:
被动检测:相对于agent而言;agent, server向agent请求获取配置的各监控项相关的数据,agent接收请求、获取数据并响应给server;
主动模式
主动检测:相对于agent而言;agent(active),agent向server请求与自己相关监控项配置,主动地将server配置的监控项相关的数据发送给server;主动监控能极大节约监控server 的资源。
快速使用
简单监控一个主机
- 添加一个主机
- 添加模板
- 添加应用集
- 添加监控项
- 观察主机是否变绿色
自定义配置监控项
编写客户端监控项配置文件
[root@server2 ~]# cat /etc/zabbix/zabbix_agentd.d/userparameter_nginx.conf
UserParameter=nginx_process_num,ps -ef | grep -c [n]ginx
[root@server2 ~]# systemctl restart zabbix-agent.service
# 复杂的监控项
UserParameter=[*]_process_num,ps -ef | grep -c $1
验证自定义监控项是否生效
[root@server1 ~]# yum install zabbix-get.x86_64 -y
[root@server1 ~]# zabbix_get -s 192.168.80.40 -k nginx_process_num
9
web端添加监控项,加入此键值
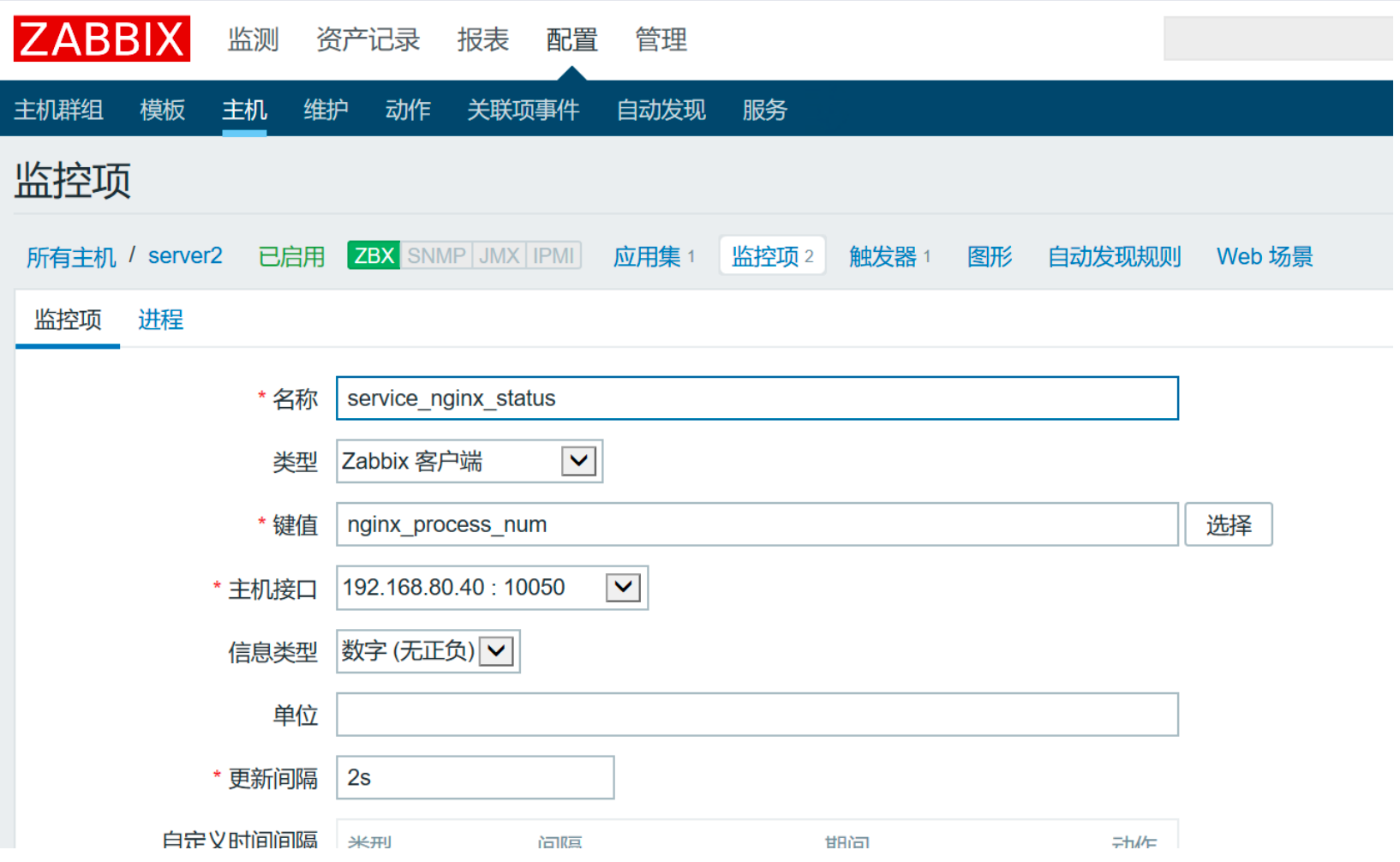
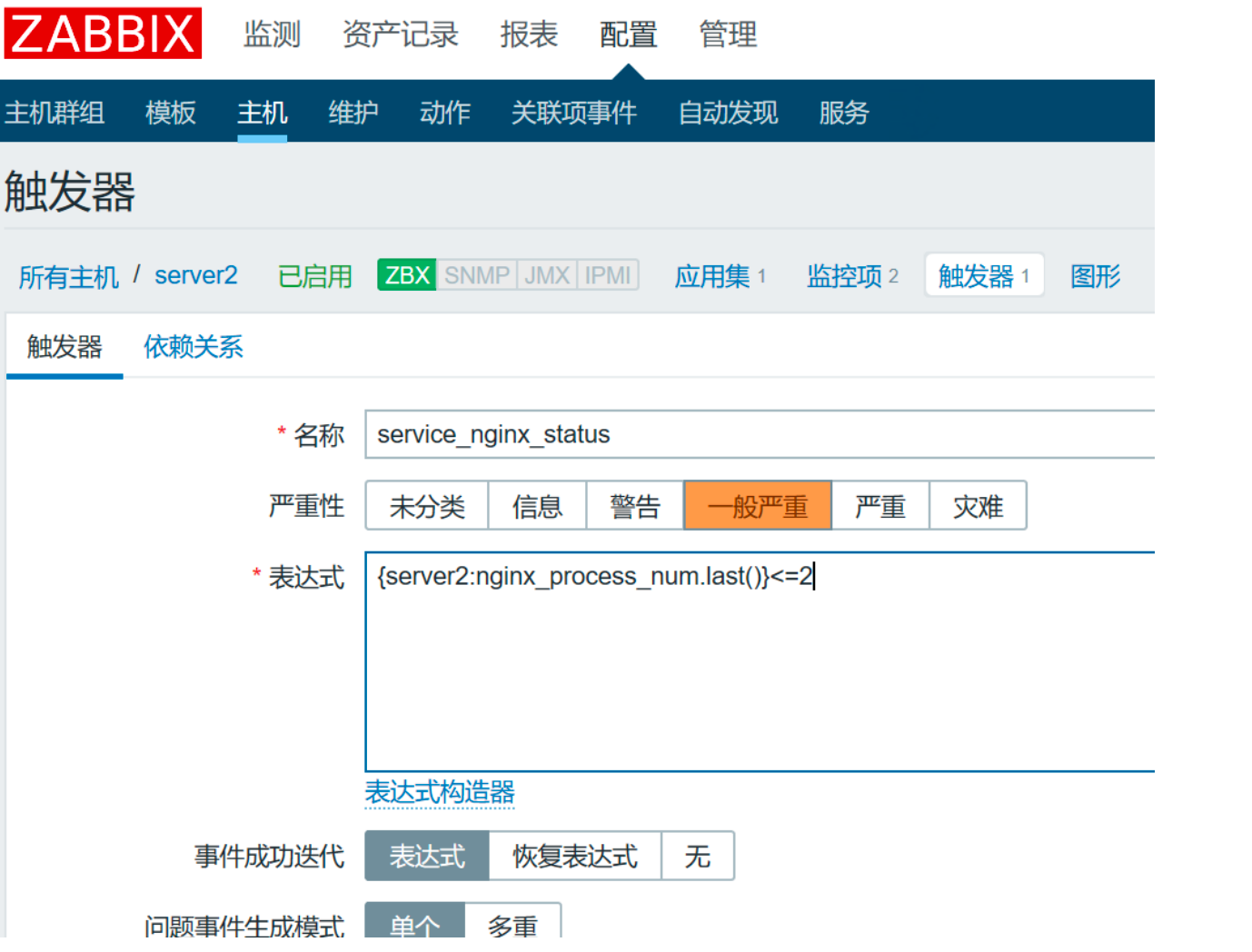
给主机添加触发器
redis相关的自定义监控项
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/redis.conf
UserParameter=Redis.Status,/usr/local/redis/bin/redis-cli -h 127.0.0.1 -p 6379 ping |grep -c PONG
UserParameter=Redis_conn[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "connected_clients" | awk -F':' '{print $2}'
UserParameter=Redis_rss_mem[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "used_memory_rss" | awk -F':' '{print $2}'
UserParameter=Redis_lua_mem[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "used_memory_lua" | awk -F':' '{print $2}'
UserParameter=Redis_cpu_sys[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "used_cpu_sys" | awk -F':' '{print $2}'
UserParameter=Redis_cpu_user[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "used_cpu_user" | awk -F':' '{print $2}'
UserParameter=Redis_cpu_sys_cline[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "used_cpu_sys_children" | awk -F':' '{print $2}'
UserParameter=Redis_cpu_user_cline[*],/usr/local/redis/bin/redis-cli -h $1 - p $2 info | grep -w "used_cpu_user_children" | awk -F':' '{print $2}'
UserParameter=Redis_keys_num[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep -w "$$1" | grep -w "keys" | grep db$3 | awk -F'=' '{print $2}' | awk -F',' '{print $1}'
UserParameter=Redis_loading[*],/usr/local/redis/bin/redis-cli -h $1 -p $2 info | grep loading | awk -F':' '{print $$2}'
Redis.Status --检测Redis运行状态, 返回整数
Redis_conn --检测Redis成功连接数,返回整数
Redis_rss_mem --检测Redis系统分配内存,返回整数
Redis_lua_mem --检测Redis引擎消耗内存,返回整数
Redis_cpu_sys --检测Redis主程序核心CPU消耗率,返回整数
Redis_cpu_user --检测Redis主程序用户CPU消耗率,返回整数
Redis_cpu_sys_cline --检测Redis后台核心CPU消耗率,返回整数
Redis_cpu_user_cline --检测Redis后台用户CPU消耗率,返回整数
Redis_keys_num --检测库键值数,返回整数
Redis_loding --检测Redis持久化文件状态,返回整数
nginx相关的自定义监控项
vim /etc/nginx/conf.d/default.conf
location /
nginx-status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/nginx.conf UserParameter=Nginx.active,/usr/bin/curl -s "http://127.0.0.1:80/nginx- status" | awk '/Active/ {print $NF}'
UserParameter=Nginx.read,/usr/bin/curl -s "http://127.0.0.1:80/nginx-status" | grep 'Reading' | cut -d" " -f2
UserParameter=Nginx.wrie,/usr/bin/curl -s "http://127.0.0.1:80/nginx-status" | grep 'Writing' | cut -d" " -f4
UserParameter=Nginx.wait,/usr/bin/curl -s "http://127.0.0.1:80/nginx-status" | grep 'Waiting' | cut -d" " -f6
UserParameter=Nginx.accepted,/usr/bin/curl -s "http://127.0.0.1:80/nginx- status" | awk '/^[ \t]+[0-9]+[ \t]+[0-9]+[ \t]+[0-9]+/ {print $1}'
UserParameter=Nginx.handled,/usr/bin/curl -s "http://127.0.0.1:80/nginx- status" | awk '/^[ \t]+[0-9]+[ \t]+[0-9]+[ \t]+[0-9]+/ {print $2}'
UserParameter=Nginx.requests,/usr/bin/curl -s "http://127.0.0.1:80/nginx- status" | awk '/^[ \t]+[0-9]+[ \t]+[0-9]+[ \t]+[0-9]+/ {print $3}'
TCP相关的自定义监控
vim /usr/local/zabbix/share/zabbix/alertscripts/tcp_connection.sh
#!/bin/bash
function ESTAB {
/usr/sbin/ss -ant |awk '{++s[$1]} END {for(k in s) print k,s[k]}' | grep 'ESTAB' | awk '{print $2}'
}
function TIMEWAIT {
/usr/sbin/ss -ant | awk '{++s[$1]} END {for(k in s) print k,s[k]}' | grep 'TIME-WAIT' | awk '{print $2}'
}
function LISTEN {
/usr/sbin/ss -ant | awk '{++s[$1]} END {for(k in s) print k,s[k]}' | grep 'LISTEN' | awk '{print $2}' }
$1
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/cattcp.conf
UserParameter=tcp[*],/usr/local/zabbix/share/zabbix/alertscripts/tcp_connect ion.sh $1
tcp[TIMEWAIT] --检测TCP的驻留数,返回整数
tcp[ESTAB] --检测tcp的连接数、返回整数
tcp[LISTEN] --检测TCP的监听数,返回整数
系统监控的自带选项
agent.ping 检测客户端可达性、返回nothing表示不可达。1表示可达
system.cpu.load --检测cpu负载。返回浮点数
system.cpu.util -- 检测cpu使用率。返回浮点数
vfs.dev.read -- 检测硬盘读取数据,返回是sps.ops.bps浮点类型,需要定义1024倍 vfs.dev.write -- 检测硬盘写入数据。返回是sps.ops.bps浮点类型,需要定义1024倍
net.if.out[br0] --检测网卡流速、流出方向,时间间隔为60S
net-if-in[br0] --检测网卡流速,流入方向(单位:字节) 时间间隔60S
proc.num[] 目前系统中的进程总数,时间间隔60s
proc.num[,,run] 目前正在运行的进程总数,时间间隔60S
###处理器信息
通过zabbix_get 获取负载值
合理的控制用户态、系统态、IO等待时间剋保证进程高效率的运行 系统态运行时间较高说明进程进行系统调用的次数比较多,一般的程序如果系统态运行时间占用过高就 需要优化程序,减少系统调用 io等待时间过高则表明硬盘的io性能差,如果是读写文件比较频繁、读写效率要求比较高,可以考虑更 换硬盘,或者使用多磁盘做raid的方案
system.cpu.swtiches --cpu的进程上下文切换,单位sps,表示每秒采样次数,api中参数 history需指定为3
system.cpu.intr --cpu中断数量、api中参数history需指定为3
system.cpu.load[percpu,avg1] --cpu每分钟的负载值,按照核数做平均值(Processor load (1 min average per core)),api中参数history需指定为0
system.cpu.load[percpu,avg5] --cpu每5分钟的负载值,按照核数做平均值(Processor load (5 min average per core)),api中参数history需指定为0
system.cpu.load[percpu,avg15] --cpu每5分钟的负载值,按照核数做平均值(Processor load (15 min average per core)),api中参数history需指定为0