今天分享一篇7月挂在arxiv上的文章,研究的是用生成式网络进行图片压缩。
近十年来,用图片压缩的主流方法是神经网络来做。
17年左右流行用带有量化的autoencoder来做图片压缩,同时训练的指标也是常用的distortion metric,比如MSE,PSNR,MS-SSIM等等。
但是这些方法在低比特率的时候通常有模糊的现象发生,因此从19年开始大家转到了生成式压缩,这个时候指标也变成了原分布与重建分布的差异大小。这个方法在小于0.1bpp(bit-per-pixel)的时候效果很好。但是当时的生成式技术并没有那么可信/faithful,因此后面大家开始用human-aligned的自然语言表述的语义信息来生成图片。
21年开始,text-to-image生成方法流行了起来,而在22年的diffusion model和CLIP算法更是占据了主流。在此基础上,这些压缩器传输量化的embedding来进行图片恢复。这篇文章可以看成这个架构上的扩展。
本文核心
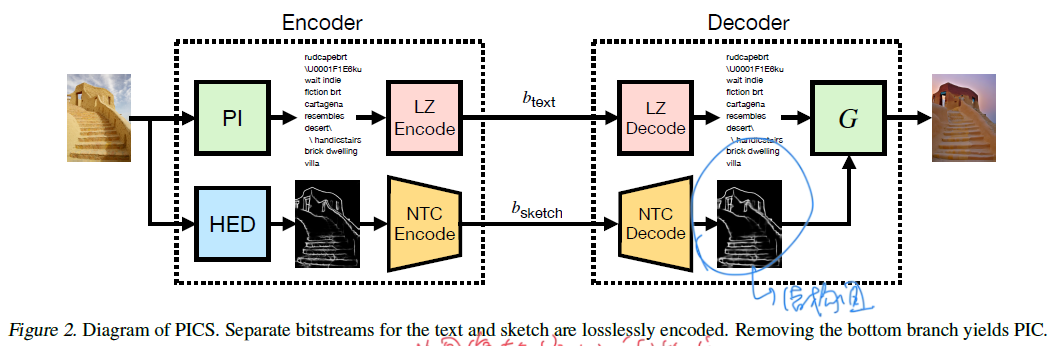
这篇文章的核心创新就是用图片的结构信息来辅助生成压缩后的图像。一般而言的生成式图像,在单独用语言描述时候,只能感觉上像,但是方位等信息通常就丢失了。这个架构其实也是用的比较多的,像杨润雨的一个工作就是用有损压缩来压缩结构信息。这样可以看到在0.013bpp的时候也有比较好的效果。

其他零散要点
- 以人的感官为标准而不是客观指标为标准的压缩方法,是一种可能的发展方向。即对压缩前后,看人的评价是否一致。
- 将图像转换为文字的技术(相当于语义提取)成为prompt inversion,来源于Wen 2023。同样的,从语义相似度角度上来衡量,可以用图片的embedding的结果相似程度来衡量,比如
- 将结构信息和语义信息共同进行生成式图片的基础,可以采用ControlNet来做,来源于Zhang 2023。这是一个基于stable diffusion的文本图像生成结构,能将edge detection map、分割图、深度图等形式的spatial conditioning maps的空间信息提取出来。
Wen, Y., Jain, N., Kirchenbauer, J., Goldblum, M., Geiping, J., and Goldstein, T. Hard prompts made easy: Gradientbased discrete optimization for prompt tuning and discovery. arXiv preprint arXiv:2302.03668, 2023.
Zhang, L. and Agrawala, M. Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023.