
Transformer 模型通常使用标准的 QKV 三件套进行计算,但是部分来自 K 的 token 与来自 Q 的 token 并不相关,如果仍然对这些 token 进行特征聚合计算会影响图像修复的性能。
为了解决这个问题,该论文提出了一种Sparse Transformer网络(DRSformer),它可以自适应地保留最有用的自注意力值以进行特征聚合,从而更好地促进高质量的图像重建。论文框架如下图所示,个人感觉主要创新有两个方面:top-k sparse attention (TKSA) 和 mixed-scale feed-forward network (MSFN)。
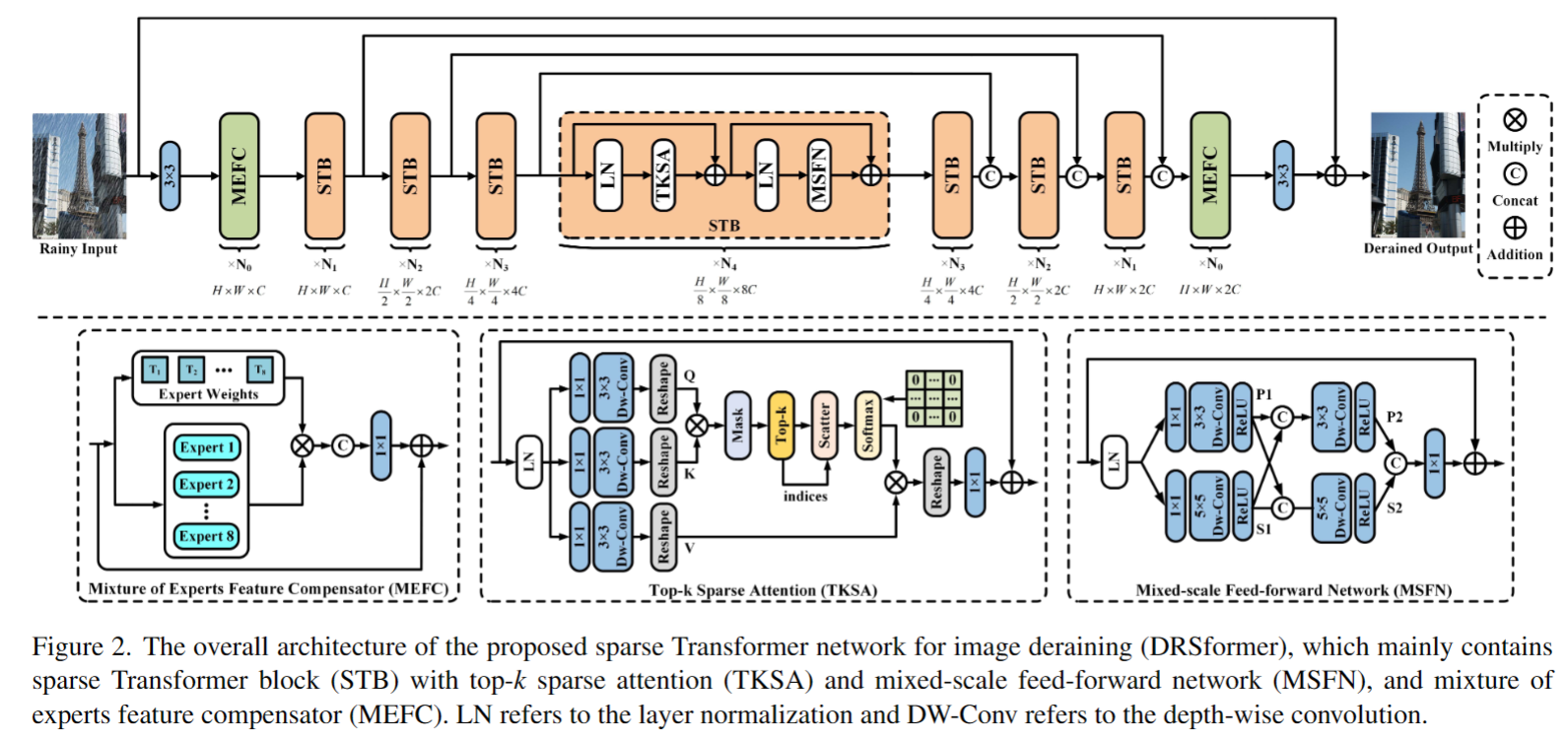
top-k sparse attention (TKSA)
TKSA如下图所示,大体沿用了 Restormer 的思路,不同之处在于作者创建了一个mask,把相对不重要的 token 置0了。这个算法的思路来自于 NeurIPS 21 的论文《Chasing Sparsity in Vision Transformers: An End-to-End Exploration》,原文中说,稀疏训练甚至可以提高ViT的准确性,而不是降低性能。
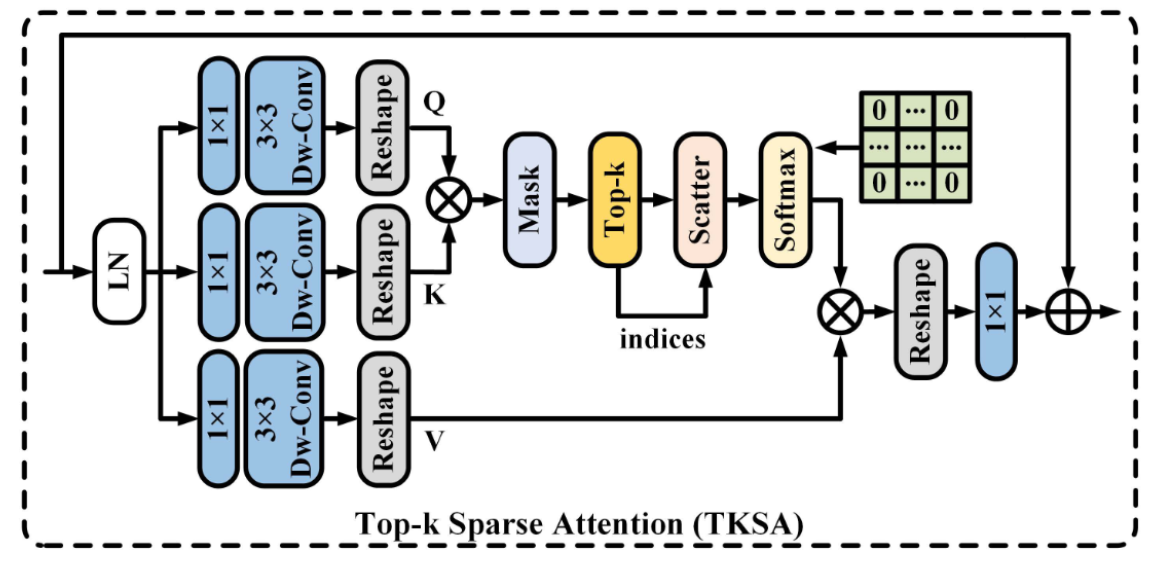
该论文还附一个 pytorch 的伪代码,具体如下。在这个去雨的任务中,通过实验作者保留了[1/2, 4/5] 区间的 token。

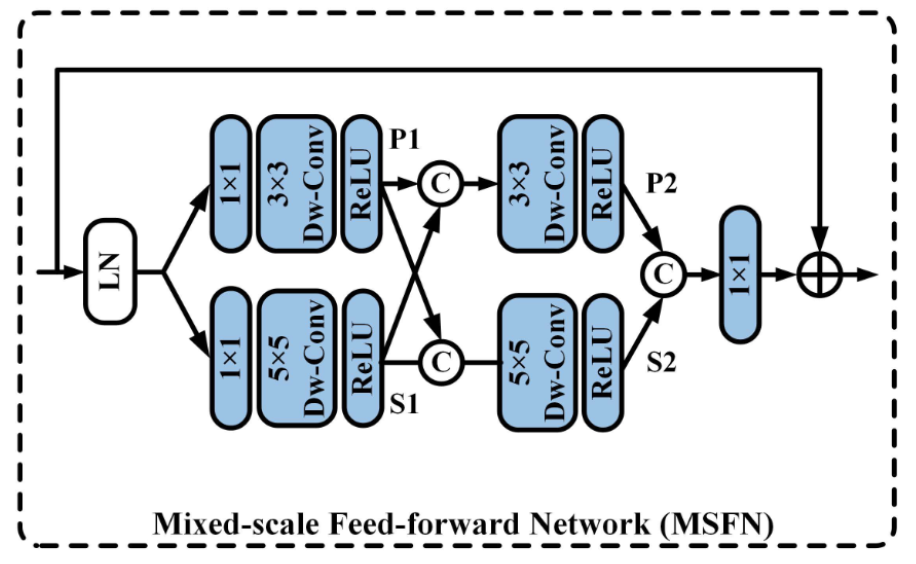
mixed-scale feed-forward network (MSFN)
MSFN的结构如下图所示,与Restormer里不同的地方是,作者使用两个尺度的卷积
实验部分可以参考作者论文,这里不过多介绍。
- Transformer Effective Deraining Learning Networktransformer effective deraining learning transformer spikformer network spiking reinforcement transformer decision learning reinforcement transformer learning trainer convolutional learning network extreme deraining effective effective笔记 effective day effective笔记java