选题方向:2.大数据分析
一、选题背景介绍
新华社北京7月18日电 全国生态环境保护大会17日至18日在北京召开。今后5年是美丽中国建设的重要时期,要深入贯彻新时代中国特色社会主义生态文明思想,坚持以人民为中心,牢固树立和践行绿水青山就是金山银山的理念,把建设美丽中国摆在强国建设、民族复兴的突出位置,推动城乡人居环境明显改善、美丽中国建设取得显著成效,以高品质生态环境支撑高质量发展,加快推进人与自然和谐共生的现代化。
***在党的二十大报告中强调,“立足我国能源资源禀赋,坚持先立后破,有计划分步骤实施碳达峰行动。”“完善能源消耗总量和强度调控,重点控制化石能源消费,逐步转向碳排放总量和强度‘双控’制度。”
在大数据时代,我们可以利用海量的数据信息进行深度分析和挖掘,从而更好地了解自然环境的状况和变化趋势。通过对环境数据的收集、整合和分析,我们可以预测环境问题的发生和发展趋势,为政府和企业提供更加精准的环境管理决策支持。大数据分析还可以促进公众参与和监督。通过公开环境数据和信息,可以增强公众对环境问题的关注和参与度,形成政府、企业和公众共同参与的环境治理格局。
我们应该深入学习领会重要讲话精神,认真贯彻落实生态文明建设的各项决策部署,积极推动大数据技术在生态环境保护领域的应用和发展,为实现人与自然和谐共生的现代化目标贡献力量。
二、选题意义
选择乔木植物作为大数据分析对象与国家碳中和的战略意义密切相关:
1. 碳吸存和减排:乔木植物通过光合作用吸收大量的二氧化碳,并将其固定在植物组织中。将乔木植物作为大数据分析对象,可以帮助我们更好地了解它们在吸收和储存碳方面的能力。这有助于国家实现碳中和目标,减少温室气体排放,应对气候变化。
2. 林业管理和可持续发展:通过对乔木植物的大数据分析,可以了解森林资源的分布、生长情况、病虫害等信息。这有助于制定科学合理的林业管理策略,推动森林的可持续利用和保护。同时,可持续林业发展也可以为国家提供木材、纤维和其他森林产品,促进经济发展。
3. 生态系统恢复和生物多样性保护:乔木植物是生态系统中的重要组成部分,对维护生态平衡和保护生物多样性至关重要。通过对乔木植物进行大数据分析,可以深入了解不同物种的分布、生态特征和相互关系。这有助于科学规划和实施生态系统的恢复计划,保护和恢复受损的生态系统,并维护关键物种的栖息地。
4. 水资源管理:乔木植物在水循环中发挥着重要作用,通过蒸腾作用调节水分蒸发和降水分布。通过对乔木植物的大数据分析,可以了解它们对水资源的利用和影响,帮助科学合理地管理和保护水资源,以应对干旱、水源污染等问题。
5. 环境教育和公众意识:乔木植物是生态系统和环境保护的重要教育资源。通过对乔木植物的大数据分析,可以为公众提供有关森林生态系统、气候变化和生物多样性保护等方面的科学知识。这有助于提高公众对环境保护的认识和意识,促进可持续发展理念的传播和落实。
选择乔木植物作为大数据分析对象可以为国家碳中和的战略提供重要支持。通过深入了解乔木植物的生态特征、碳吸存能力和生态系统服务功能,可以制定科学有效的政策和措施,推动碳减排、可持续林业发展、生态系统保护和环境教育等方面的工作。
三、数据集简介
本数据源包含:Plot、Subplot、Species、Light_ISF、Light_Cat、Core、Soil、Adult、Sterile、Conspecific、Myco、SoilMyco、PlantDate、AMF、EMF、Phenolics、Lignin、NSC、Census、Time、Event、Harvest等24个指标,以及红栎,白栎,枫树,樱桃木四个树种。其中观察树种在不同情况下,哪个树种在哪个环境下生长的好,并解释为什么出现这种情况的原因。
该研究在数据集测量数据采自北半球地中海沿岸地区、黑海沿岸地区、国家(纬度30至40度)进行。夏季炎热干燥,冬季温和多雨,是13种气候类型中唯一一种雨热不同期的气候类型。
夏季在副热带高压控制下,气流下沉,气候炎热干燥少雨,云量稀少,阳光充足。冬季受西风带控制,锋面气旋频繁活动,气候温和,最冷月气温在4-10℃之间,降水量丰沛。
全年降水量300-1000毫米,冬季半年约占60%-70%,夏季半年只有30%-40%,冬季降水量多于夏季。该数据集与4种乔木植物有关,此数据集已预先清理,没有任何问题。我们只需要一个模型来预测谁在相同情况下生存得最多。
数据采集时间在2018年5月15日~2018年5月15日,对于每个数据的每个物种,均采集于北半球地区域1m高度的相同高度。在2018年5月(干旱季节)中,从选定的树种中采集了叶片和根际样品。为了采集叶片样品,我们使用了一个长距离修剪机从树冠上收集了暴露于阳光下的树枝所选物种的顶部。通过对叶片营养成分和根际理化性质、根际微生物量以及根际P组分和根际酸性磷酸酶活性进行了测定。并分析树木枝叶各成分含量(丛枝菌根真菌(AMF)和外生菌根真菌(EMF)、Phenolics酚、Lignin木质素、NSC(非结构碳水化合物))Census(测量数)
数据验证使用中国生物志库(验证该植物是否真实存在,且在中国地区出现频繁,设立同科对照组,对比数据,得出准确的项目结果):
https://species.sciencereading.cn/biology/v/biologicalIndex/122.html
使用数据集:Cleaned_Tree_Dataset.csv
四、大数据前期准备
4.1数据集清洗
对数据进行数据清洗,数据清洗在数据分析和建模过程中起着重要的作用。用来提高数据的质量和准确性,确保数据的可靠性和可用性:
import pandas as pd # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 数据清洗:去除缺失值或异常值 data = data.dropna() # 去除包含缺失值的行 # 其他数据清洗操作... # 获取所有树种的唯一值 species = data['Species'].unique() # 计算每个树种的数据指标平均值 averages = data.groupby(['Species'])[['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']].mean() # 输出数据对比表格 comparison_table = pd.DataFrame(averages.loc[species], columns=['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']) print(comparison_table)
实验结果:

输出各个树种的元素值以达到基本数据集使用演奏求,提高了数据分析和建模的准确性和可靠性,从而支持更可靠的决策和洞察力的发现,并得出总结。
4.2数据集划分
对数据集划分训练集和测试集,做前期数据分析的准备:
import pandas as pd from sklearn.model_selection import train_test_split # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 划分特征和目标变量 X = data.drop('Species', axis=1) # 特征 y = data['Species'] # 目标变量 # 数据集划分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 获取所有树种的唯一值 species = data['Species'].unique() # 计算训练集每个树种的数据指标平均值 train_averages = X_train.groupby(y_train)[['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']].mean() # 输出训练集数据对比表格 train_comparison_table = pd.DataFrame(train_averages.loc[species], columns=['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']) print("训练集数据对比表格:") print(train_comparison_table) # 计算测试集每个树种的数据指标平均值 test_averages = X_test.groupby(y_test)[['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']].mean() # 输出测试集数据对比表格 test_comparison_table = pd.DataFrame(test_averages.loc[species], columns=['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']) print("测试集数据对比表格:") print(test_comparison_table)
实验结果:
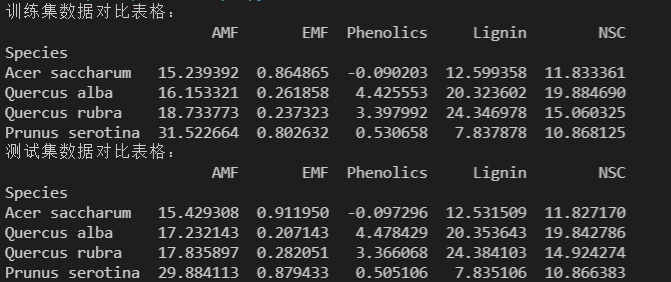
对于数据集有了明确的拆分,输出两个数据集的对比,实现了对后期结果的可验证性和对比性,为接下来的实验分析打下坚实基础。
五、大数据分析实验
5.1数据集各树种分布合理性
观察数据集乔木植物的分布占比,导入数据集,可视化数据绘制饼图,分析数据集中的种类总数占比:
from textwrap import wrap import pandas as pd import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 df = pd.read_csv('Cleaned_Tree_Dataset.csv') # 创建图形 fig = plt.figure() # 计算每种类型的数量 type_counts = df['Species'].value_counts() # 计算总数量 total = type_counts.sum() # 计算占比 percentages = (type_counts / total) * 100 # 绘制饼图 plt.pie(percentages, labels=percentages.index, autopct='%1.1f%%') plt.title('种类总数占比图') plt.show()
实验结果:
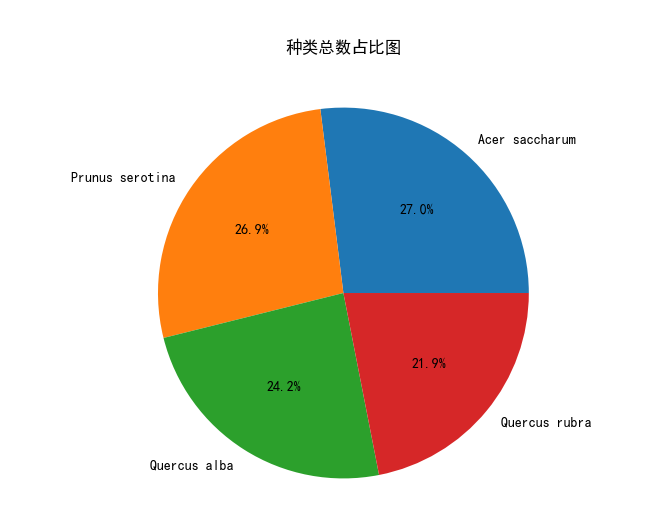
数据图表分析:
- 确定占比的合理性标准:在评估数据集的占比合理性之前,需要明确什么样的占比被认为是合理的。
- 分析占比分布:对数据集中的各个关键指标进行占比分析,以了解它们之间的分布情况。
- 确定占比的合理范围:基于业务或研究需求,确定每个关键指标的占比合理范围。
- 比较和分析:将数据集中的实际占比与确定的合理范围进行比较和分析。
- 数据集的占比关系合理且满足研究需求,我认为该数据集在占比方面是可行的。Quercus alba(白橡)、Quercus rubra(红橡)、Acer saccharum(枫树)和Prunus serotina(樱桃树)确实是四种不同的树种,它们在自然界中广泛分布并具有生态功能。数据集中,展示的四个树种在其占比合理,可以使用该数据集进行继续的讨论研究。
5.2数据集树种多样性证明
观察数据集同种、异种、无菌的分布占比,绘制可视化数据绘制饼图,分析数据集中的种类总数占比:
from textwrap import wrap import pandas as pd import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 df = pd.read_csv('Cleaned_Tree_Dataset.csv') # 创建图形 fig = plt.figure() # 计算每种类型的数量 type_counts = df['Conspecific'].value_counts() # 计算总数量 total = type_counts.sum() # 计算占比 percentages = (type_counts / total) * 100 # 绘制饼图 plt.pie(percentages, labels=percentages.index, autopct='%1.1f%%') plt.title('数据同种的总数占比图') plt.show()
实验结果:
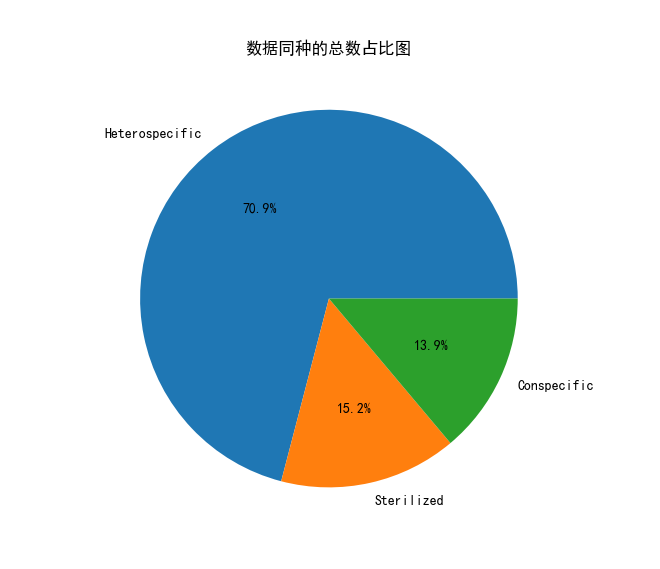
数据分布计算:计算每种数据类型的数量,直观看到计算它们在数据集中的占比。
数据可视化:使用可视化工具来绘制饼图,以显示每种数据类型的分布占比。
数据分析:通过观察饼图,清楚地看到每种数据类型的占比。如果发现我呢提,可以提前根据要求,清洗数据集,脏数据,并根据需要调整数据收集策略或分析方法。
树种的Sterilized、Heterospecific和Conspecific是描述不同植物间杂交方式的术语。在图中,这些数据被表示为饼状图中的百分比。根据饼状图,我们可以得知:
- Sterilized(纯合):占总数的70.9%。
- Heterospecific(杂合):占总数的13.9%。
- Conspecific(同种):占总数的15.2%。
树种的种类繁多。在植物分类学中,我们通常根据一些特定的标准将树种进行分类。按照热量因子,树种可以分为热带树种、亚热带树种、温带树种和寒带亚寒带树种;按照水分因子,树种可以划分为耐旱树种和耐湿树种;光照因子则可以将树种分为阳性树、中性数、阴性树,每类中又可分数级。另外,我们还可以根据树种的枝干特点进行分类,比如乔木,它的树体高大,具有明显主干,高度在10米以上。
在中国,由于地理环境的差异,形成了生物种类繁多、植被类型丰富的情况。湖南省的树木资源就非常丰富,有114科431属1868种及变种。其中松树就是种类非常繁多的一种,不仅分布广泛,而且形态各异。
总的来说,不同的分类方式可以让我们对树种有更深入的了解,同时也反映出生物多样性的特点。
5.3各个树种生长影响因子展示
导入数据集,分类提取四种树种的(Acer saccharum、、Quercus rubra、Quercus alba、Prunus serotina)的,取得各个AMF、EMF、Phenolics、Lignin、NSC数据,分析每一个树种在实验结束后取得各个数据指标的平均值,绘制表格:
import pandas as pd import matplotlib.pyplot as plt # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 指定要提取的树种 species_list = ['Acer saccharum', 'Quercus rubra', 'Quercus alba', 'Prunus serotina'] subset = data[data['Species'].isin(species_list)] # 提取所需的数据列 columns = ['Species', 'AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC'] subset = subset[columns] # 计算每个数据指标的平均值 averages = subset.groupby('Species').mean() # 创建表格 fig, ax = plt.subplots() ax.axis('off') table = ax.table(cellText=averages.values, colLabels=averages.columns, rowLabels=averages.index, loc='center') # 设置表格样式 table.auto_set_font_size(False) table.set_fontsize(12) table.scale(1.2, 1.2) # 显示表格 plt.show()
实验结果:
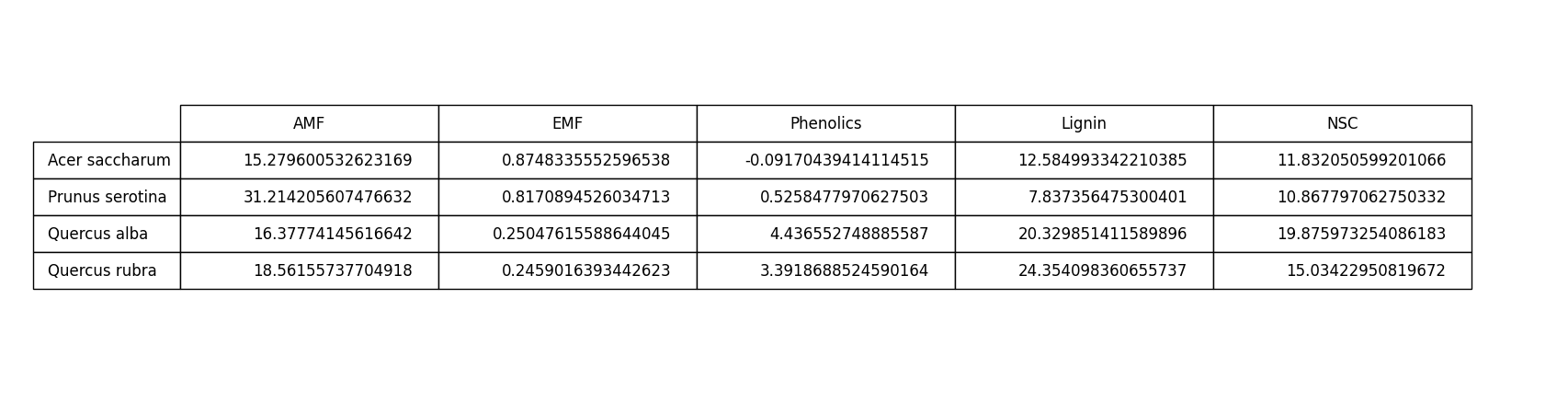
表格是数据展示的一种常用方式,具有以下优点:
- 清晰明了:表格以行和列的形式组织数据,可以直观地展示数据的分布和关系。
- 结构化:表格可以将复杂的数据以结构化的形式呈现,方便阅读和理解。
- 可比性:在表格中,同一类数据可以使用相同的格式和单位展示,使得数据之间的比较变得容易。
- 易于编辑和更新:表格可以轻松地编辑和更新,可以很方便地添加、删除或修改数据。
- 可结合其他工具:表格可以结合各种数据分析工具,进行数据分析和处理。
- 可定制化:可以根据需要定制表格的样式、颜色、字体等,使得数据展示更加美观和易读。
- 可共享:可以将表格分享给其他人,使得数据更加易于共享和使用。
5.4各个树种生长影响因子柱状图展示
分类提取Acer saccharum、、Quercus rubra、Quercus alba、Prunus serotina的,取得各个AMF、EMF、Phenolics、Lignin、NSC数据,分析每一个树种在实验结束后取得各个数据指标的平均值,绘制柱状图,并对比
说明各个树种所需要的微量元素和生长要求是不同的,需要对不同的树种分情况,处理
import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 指定要提取的树种 species_list = ['Acer saccharum', 'Quercus rubra', 'Quercus alba', 'Prunus serotina'] subset = data[data['Species'].isin(species_list)] # 提取所需的数据列 columns = ['Species', 'AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC'] subset = subset[columns] # 计算每个数据指标的平均值 averages = subset.groupby('Species').mean().reset_index() # 绘制柱状图 x = range(len(averages)) bar_width = 0.15 plt.bar(x, averages['AMF'], width=bar_width, label='AMF') plt.bar([i + bar_width for i in x], averages['EMF'], width=bar_width, label='EMF') plt.bar([i + 2 * bar_width for i in x], averages['Phenolics'], width=bar_width, label='Phenolics') plt.bar([i + 3 * bar_width for i in x], averages['Lignin'], width=bar_width, label='Lignin') plt.bar([i + 4 * bar_width for i in x], averages['NSC'], width=bar_width, label='NSC') # 设置图表属性 plt.title('2018年5月-6月各树种数据指标的平均值对比图') plt.xlabel('Species') plt.ylabel('Average Value') plt.xticks([i + 2 * bar_width for i in x], averages['Species']) plt.legend() # 显示图表 plt.show()
实验结果:
每个树种对于生长的所需元素是不一样的,按照四种不同同属的乔木植物讨论。
- Prunus serotina对于AMF(丛枝菌根真菌)的需求是最高的。
- Acer saccharum对于AMF(丛枝菌根真菌)的需求是最高的。
- Quercus rubra对于Lignin(木质素)的需求是最高的。
- Quercus alba对于Lignin(木质素)的需求是最高的。
5.5各个树种土壤影响因子散点图展示
分类提取Soil的Prunus serotina、Quercus rubra、Acer rubrum、Populus grandidentata、Sterile、Acer saccharum、Quercus alba的,取得各个AMF、EMF、Phenolics、Lignin、NSC数据,分析每一个树种在实验结束后取得各个数据指标的平均值,绘制散点图,并对比:
import pandas as pd import matplotlib.pyplot as plt # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 指定要提取的树种和数据指标 species_list = ['Prunus serotina', 'Quercus rubra', 'Acer rubrum', 'Populus grandidentata', 'Sterile', 'Acer saccharum', 'Quercus alba'] indicators = ['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC'] # 提取所需的数据列和指定的树种 columns = ['Species'] + indicators subset = data[data['Species'].isin(species_list)][columns] # 绘制散点图 for indicator in indicators: plt.figure() for species in species_list: species_data = subset[subset['Species'] == species] x = range(len(species_data)) y = species_data[indicator] plt.scatter(x, y, label=species) plt.xlabel('Data Point') plt.ylabel(indicator) plt.title(f'{indicator} Comparison') plt.legend() # 显示图表 plt.show()
实验结果:
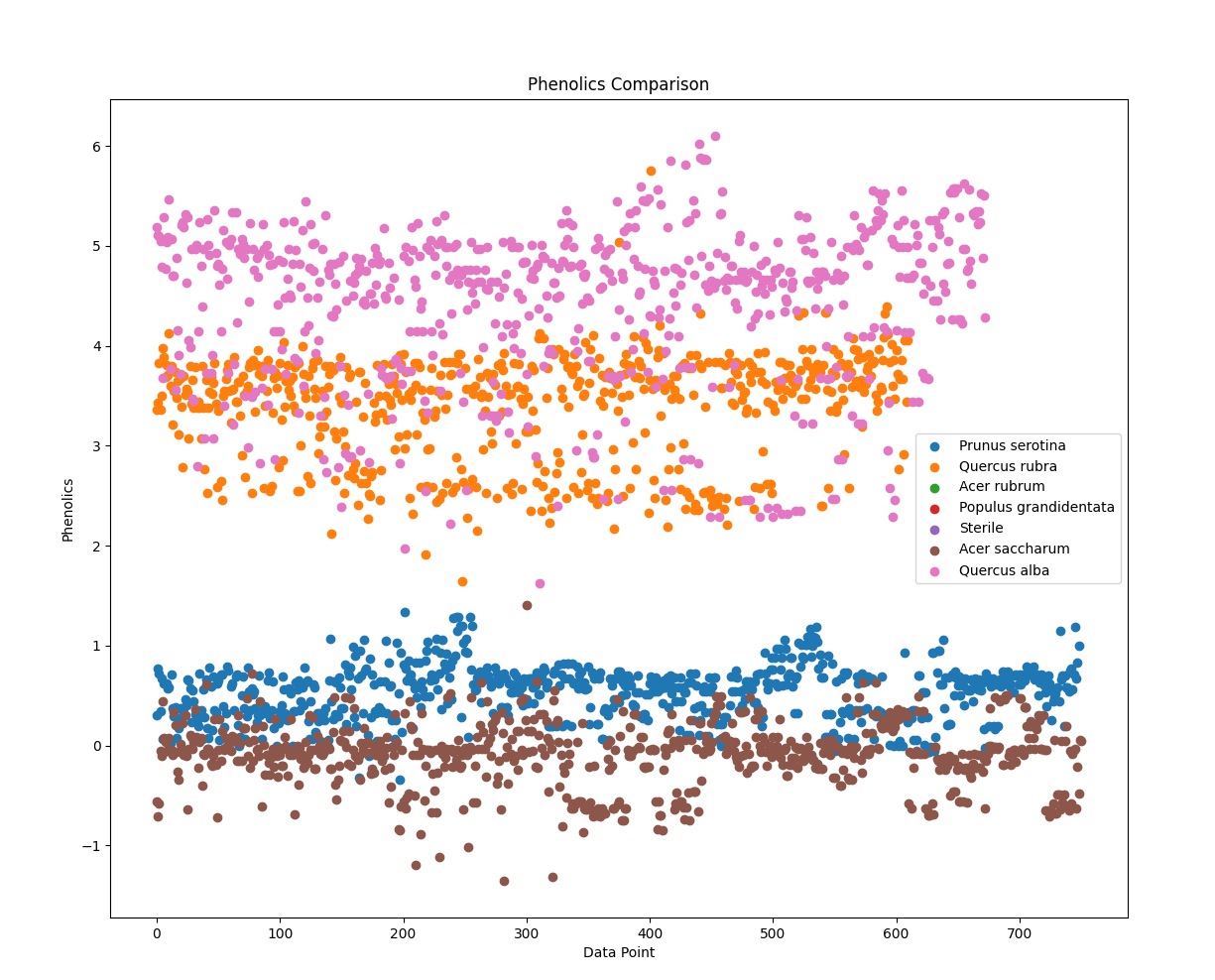
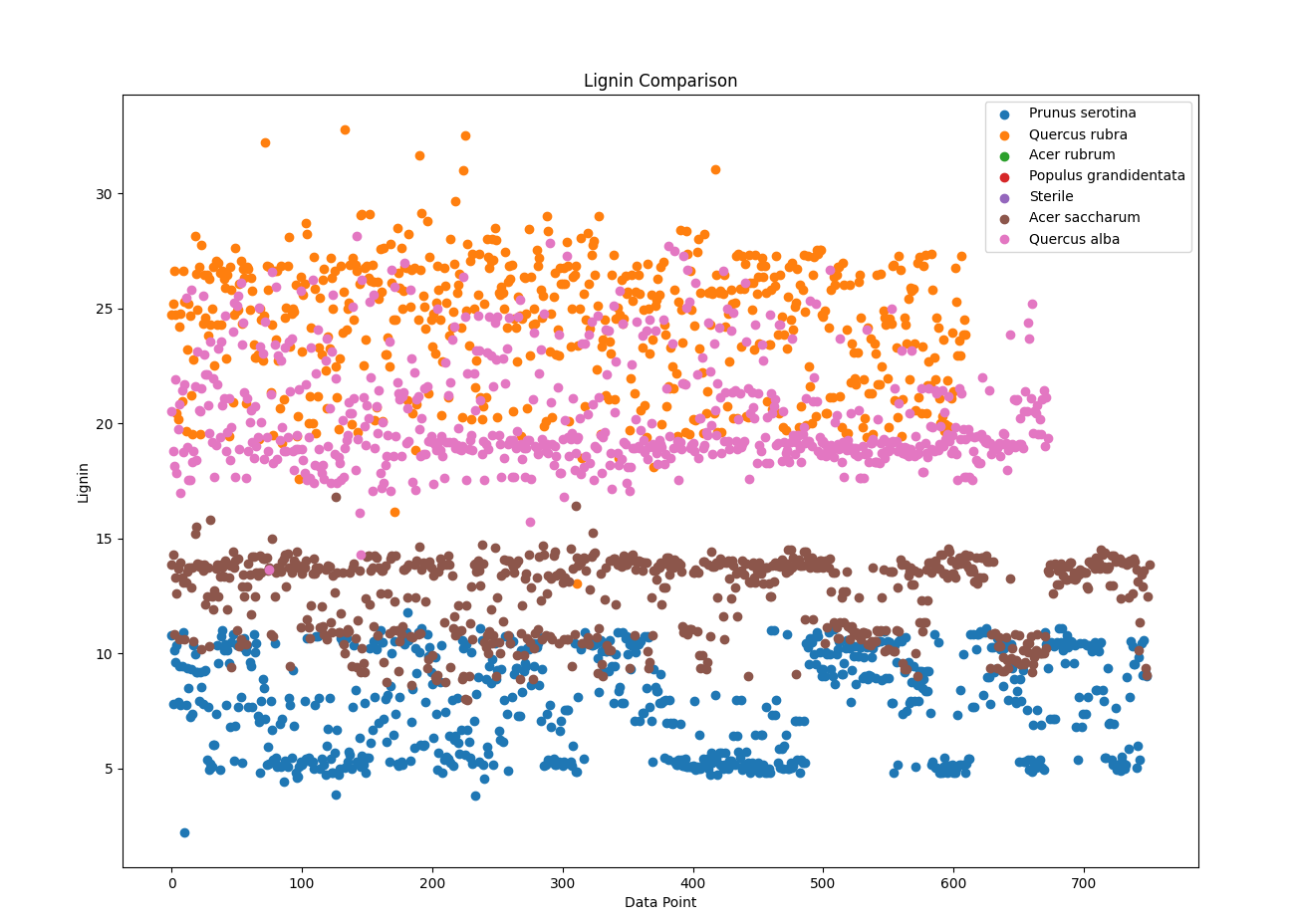
不同树种在散点图上面产生了不同的趋势,能够充分的展现出所属种的特征,基本能够证明,不同的种类生存需要不同的影响元素因子。而在同一科的乔木类,体现了差别迥异的特征,不能够一概而论,每一种的树木都有自己的所需环境,土壤和菌类都有严格要求。
5.6乔木类有无菌,影响因子雷达图展示
土壤有菌和无菌对于树木生长所需的各个元素之间的变化关系平均值:
import pandas as pd import matplotlib.pyplot as plt import numpy as np plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 指定要提取的数据指标和Sterile类型 indicators = ['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC'] sterile_types = ['Non-Sterile', 'Sterile'] # 提取所需的数据列和指定的Sterile类型 columns = ['Species', 'Sterile'] + indicators subset = data[data['Sterile'].isin(sterile_types)][columns] # 计算每个数据指标的平均值 averages = subset.groupby(['Species', 'Sterile']).mean().reset_index() # 创建雷达图 num_indicators = len(indicators) # 计算角度 angles = np.linspace(0, 2 * np.pi, num_indicators, endpoint=False).tolist() angles += angles[:1] # 设置图表属性 plt.figure(figsize=(8, 8)) ax = plt.subplot(111, polar=True) ax.set_xticks(angles[:-1]) ax.set_xticklabels(indicators) ax.set_yticklabels([]) # 绘制雷达图 for sterile_type in sterile_types: species_data = averages[averages['Sterile'] == sterile_type] values = species_data[indicators].values.tolist()[0] values += values[:1] ax.plot(angles, values, label=sterile_type) ax.fill(angles, values, alpha=0.25) # 添加图例 plt.legend() # 显示图表 plt.title('2018年5月-6月各树种在有菌和无菌的数据指标值对比雷达图') plt.show()
实验结果:
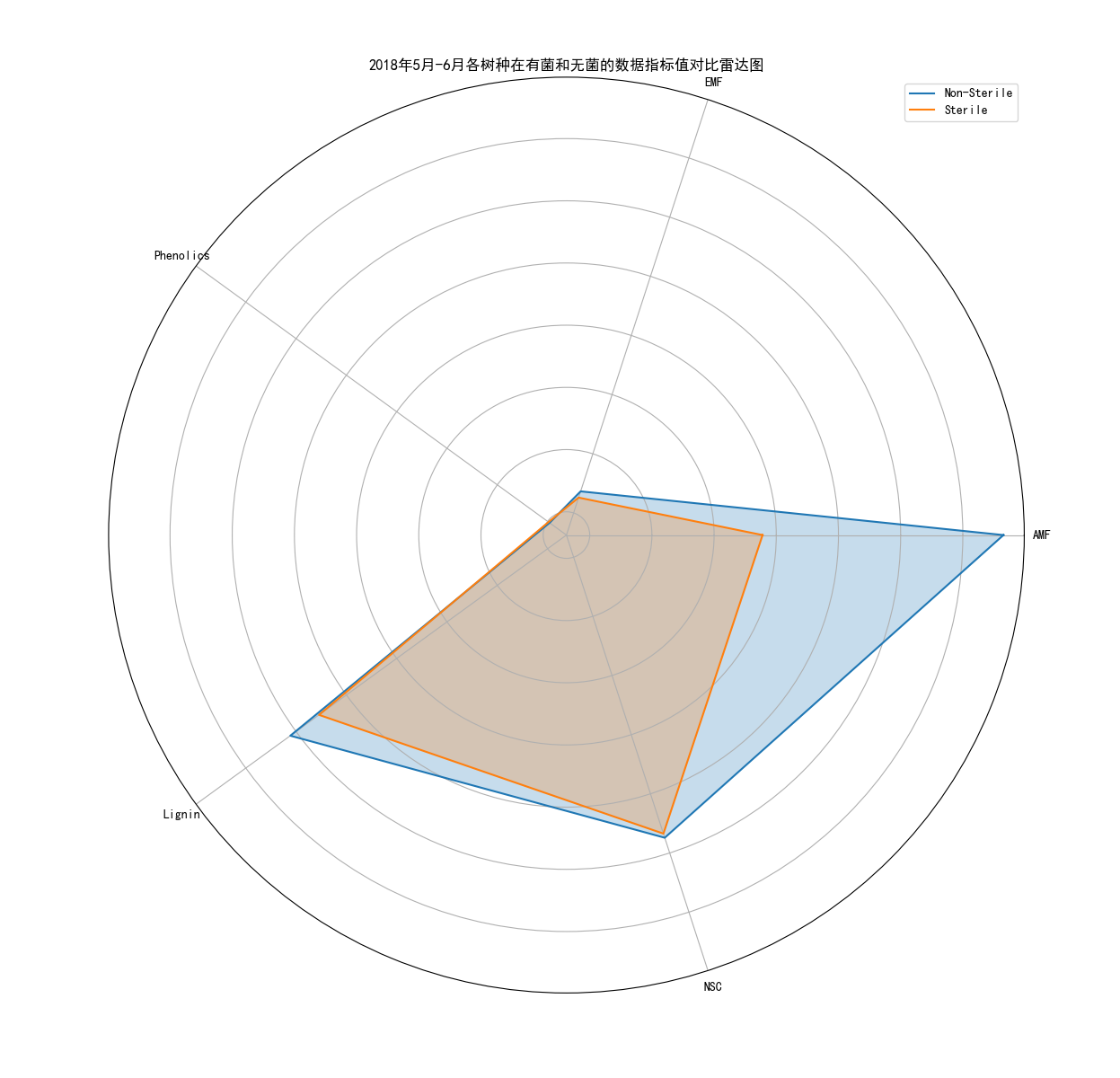
在无菌环境下,通过雷达图表现出树木成长更好,并且生长影响因子,能够更加丰富,吸收更好,有助于树木的生长。
5.7单个树种和土壤环境影响因子数据输出、折线图预测模型
导入数据集,输入树种,输入土壤环境构建预测模型,提取该条件的各个AMF、EMF、Phenolics、Lignin、NSC数据计算平均值,最后打印输出表格,绘制折线图
import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 输入树种和土壤环境 species = input("请输入树种: ") soil = input("请输入土壤环境: ") # 指定要提取的数据指标 indicators = ['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC'] # 提取满足条件的数据 subset = data[(data['Species'] == species) & (data['Soil'] == soil)][indicators] # 计算每个数据指标的平均值 averages = subset.mean() # 打印输出表格 print(f"树种: {species}, 土壤环境: {soil}") print("各个数据指标的平均值:") print(averages) # 绘制折线图 plt.figure(figsize=(10, 6)) for indicator in indicators: plt.plot(subset[indicator], label=indicator) plt.xlabel('样本') plt.ylabel('数值') plt.title(f"{species}在{soil}条件下各个数据指标的折线图") plt.legend() plt.show()
数据输出:

数据折线图:
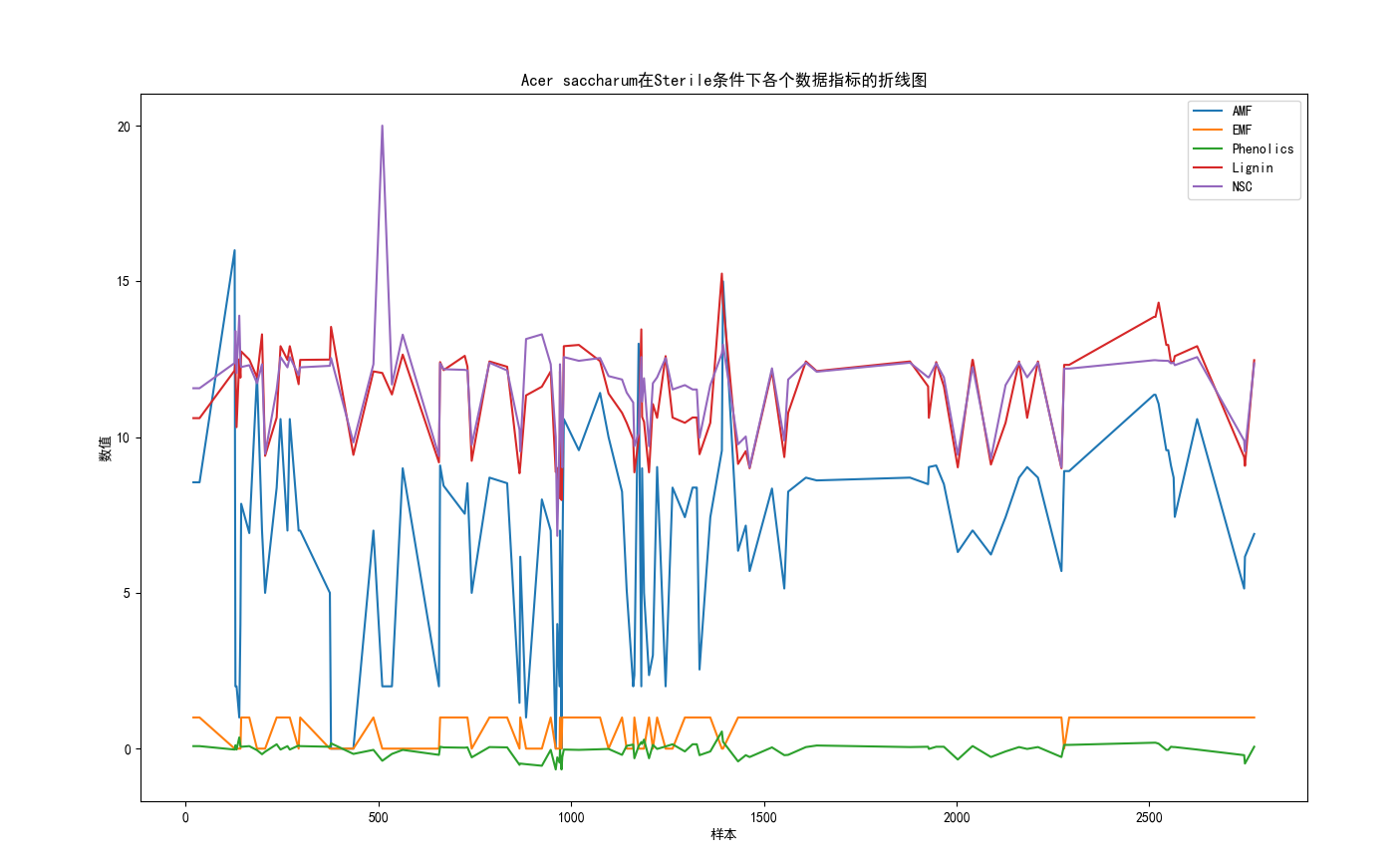
折线图的波动是由于无菌环境下,对于植物生长的影响,大部分数据均处于正常水平,可以得到完整Acer saccharum的树木分析,在Sterile土壤环境下,正常水平。
|
影响因子 |
各个数据指标的平均值: |
|
AMF |
6.949429 |
|
EMF |
0.647619 |
|
Phenolics |
-0.045048 |
|
Lignin |
11.360095 |
|
NSC |
11.683333 |
5.8各个树种土壤影响因子柱状图对比展示
导入数据集,分类提取Sterile的Non-Sterile和Sterile,各个树种的AMF、EMF、Phenolics、Lignin、NSC数据对比,分析每一个树种在实验结束后取得各个数据指标的平均值,输出对比柱状图
import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 导入数据集 data = pd.read_csv('Cleaned_Tree_Dataset.csv') # 分类提取Sterile的Non-Sterile和Sterile数据 sterile_data = data[data['Sterile'] == 'Sterile'] non_sterile_data = data[data['Sterile'] == 'Non-Sterile'] # 获取所有树种的唯一值 species = data['Species'].unique() # 计算每个树种的数据指标平均值 sterile_averages = sterile_data.groupby('Species')[['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']].mean() non_sterile_averages = non_sterile_data.groupby('Species')[['AMF', 'EMF', 'Phenolics', 'Lignin', 'NSC']].mean() # 设置柱状图的宽度和位置 bar_width = 0.35 index = range(len(species)) opacity = 0.8 # 创建图表对象 fig, ax = plt.subplots() # 绘制Sterile数据的柱状图 sterile_bars = ax.bar(index, sterile_averages.loc[species]['AMF'], bar_width, alpha=opacity, color='b', label='Sterile') # 绘制Non-Sterile数据的柱状图 non_sterile_bars = ax.bar([i + bar_width for i in index], non_sterile_averages.loc[species]['AMF'], bar_width, alpha=opacity, color='r', label='Non-Sterile') # 设置图表标题和x轴标签 ax.set_title('不同树种的AMF数据对比') ax.set_xlabel('树种') ax.set_xticks([i + bar_width/2 for i in index]) ax.set_xticklabels(species, rotation=45) # 设置y轴标签 ax.set_ylabel('平均值') # 添加图例 ax.legend() # 显示图表 plt.tight_layout() plt.show() # 生成不同树种的EMF、Phenolics、Lignin、NSC数据对比柱状图 fig, ax = plt.subplots(2, 2, figsize=(10, 8)) # 绘制EMF数据对比柱状图 emf_bars = ax[0, 0].bar(index, sterile_averages.loc[species]['EMF'], bar_width, alpha=opacity, color='b', label='Sterile') ax[0, 0].bar([i + bar_width for i in index], non_sterile_averages.loc[species]['EMF'], bar_width, alpha=opacity, color='r', label='Non-Sterile') ax[0, 0].set_title('EMF数据对比') ax[0, 0].set_xlabel('树种') ax[0, 0].set_ylabel('平均值') ax[0, 0].set_xticks([i + bar_width/2 for i in index]) ax[0, 0].set_xticklabels(species, rotation=45) ax[0, 0].legend() # 绘制Phenolics数据对比柱状图 phenolics_bars = ax[0, 1].bar(index, sterile_averages.loc[species]['Phenolics'], bar_width, alpha=opacity, color='b', label='Sterile') ax[0, 1].bar([i + bar_width for i in index], non_sterile_averages.loc[species]['Phenolics'], bar_width, alpha=opacity, color='r', label='Non-Sterile') ax[0, 1].set_title('Phenolics数据对比') ax[0, 1].set_xlabel('树种') ax[0, 1].set_ylabel('平均值') ax[0, 1].set_xticks([i + bar_width/2 for i in index]) ax[0, 1].set_xticklabels(species, rotation=45) ax[0, 1].legend() # 绘制Lignin数据对比柱状图 lignin_bars = ax[1, 0].bar(index, sterile_averages.loc[species]['Lignin'], bar_width, alpha=opacity, color='b', label='Sterile') ax[1, 0].bar([i + bar_width for i in index], non_sterile_averages.loc[species]['Lignin'], bar_width, alpha=opacity, color='r', label='Non-Sterile') ax[1, 0].set_title('Lignin数据对比') ax[1, 0].set_xlabel('树种') ax[1, 0].set_ylabel('平均值') ax[1, 0].set_xticks([i + bar_width/2 for i in index]) ax[1, 0].set_xticklabels(species, rotation=45) ax[1, 0].legend() # 绘制NSC数据对比柱状图 nsc_bars = ax[1, 1].bar(index, sterile_averages.loc[species]['NSC'], bar_width, alpha=opacity, color='b', label='Sterile') ax[1, 1].bar([i + bar_width for i in index], non_sterile_averages.loc[species]['NSC'], bar_width, alpha=opacity, color='r', label='Non-Sterile') ax[1, 1].set_title('NSC数据对比') ax[1, 1].set_xlabel('树种') ax[1, 1].set_ylabel('平均值') ax[1, 1].set_xticks([i + bar_width/2 for i in index]) ax[1, 1].set_xticklabels(species, rotation=45) ax[1, 1].legend() # 调整子图之间的间距 plt.tight_layout() # 显示图表 plt.show()
实验结果:
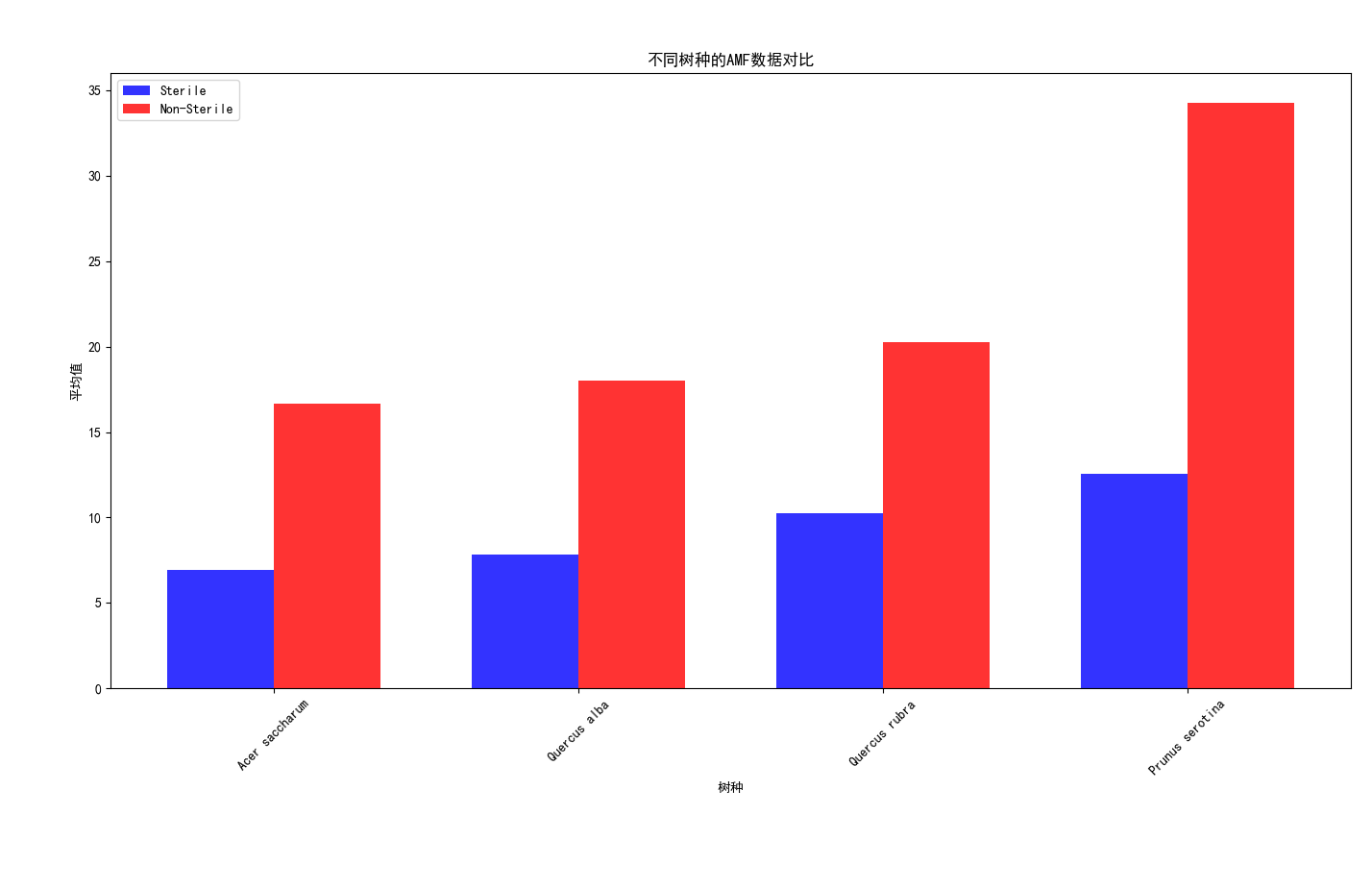
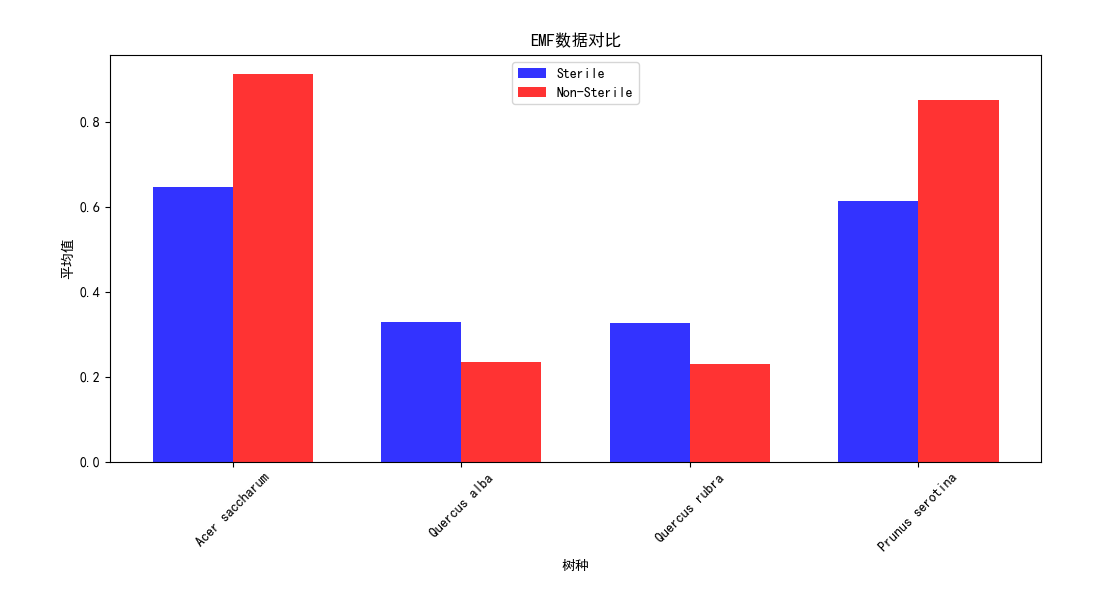
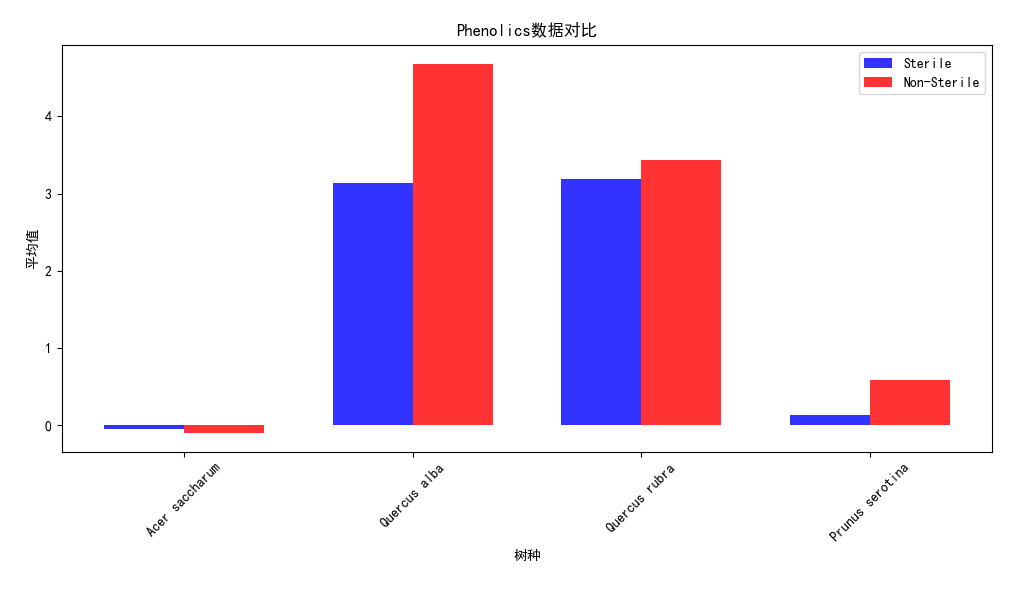
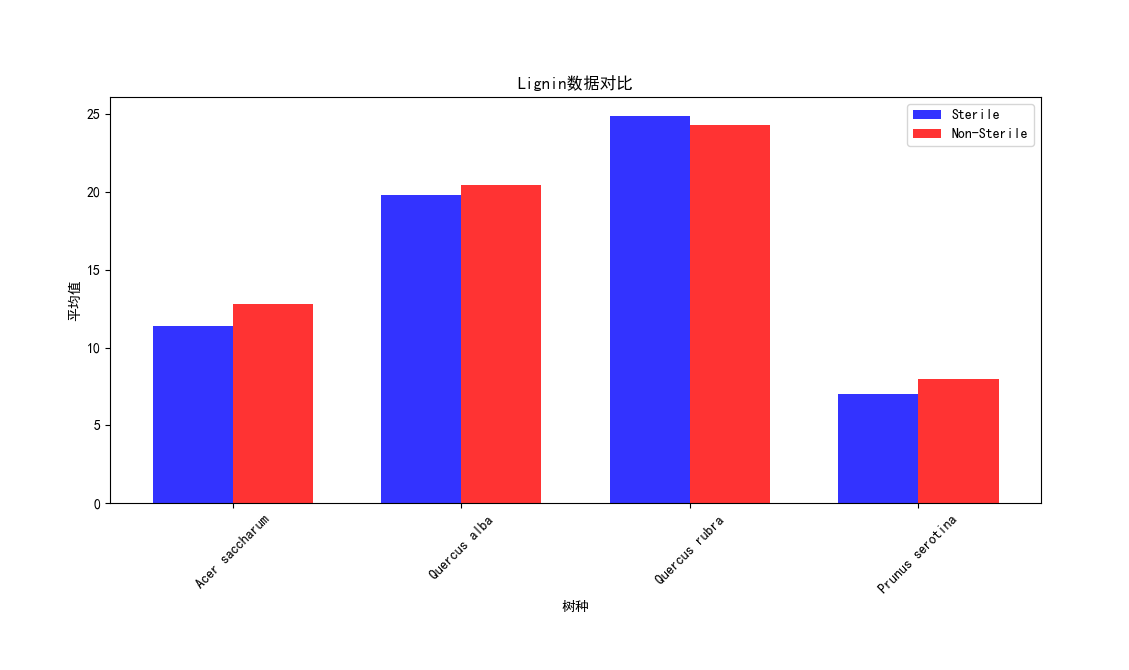
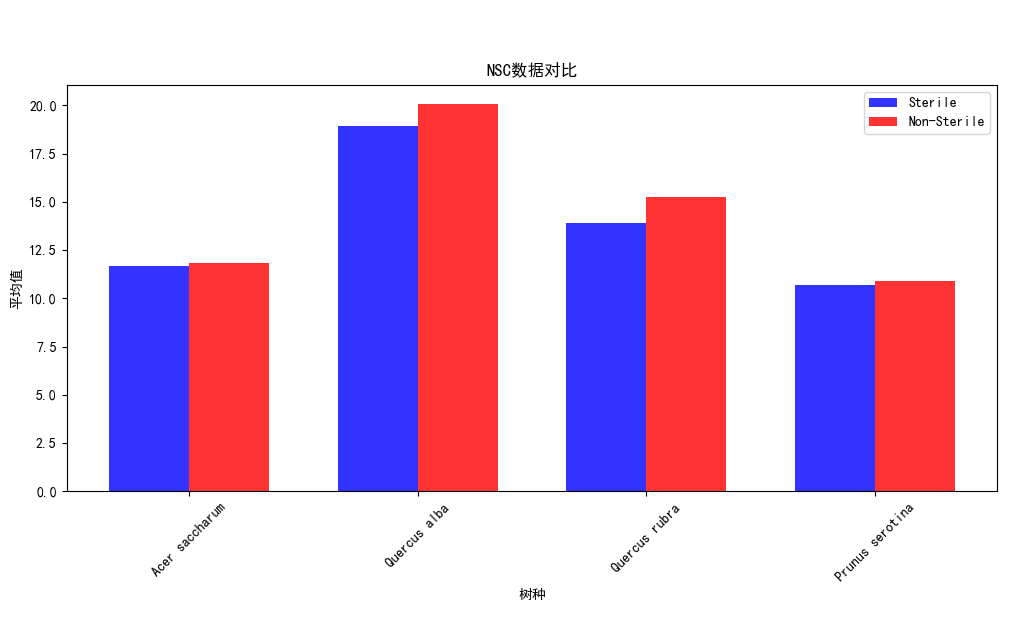
Acer saccharum、、Quercus rubra、Quercus alba、Prunus serotina树种,在有菌和无菌环境下,的数据对比。可以发现先无菌情况下,生存影响化合物数值均有提高,足以证明无菌环境对于植物生存的重要性,对于Lignin木质素、NSC(非结构碳水化合物)这两项数值的增长并不明显,益处不大。
六、大数据分析总结
除了不同演替森林之间的差异外,我发现相同的乔木科,在不同的属种上,所需的生存影响因子元素是不同的。例如植物吸收,微生物动员,酶矿化和土壤氧化还原。吸收植物可能比其他过程更重要,因为植物在生长季节需要大量的磷,因为在此季节它们会快速积累生物量。土壤氧化还原影响铁在湿润热带森林中对磷的吸附能力,并影响磷的吸附和溶解度,造成(丛枝菌根真菌(AMF)和外生菌根真菌(EMF)的数值波动,再加上无菌环境下的无机物丰富,树木所需的生长微生物得到了充分的营养补充,造成数据指标快速增长。
总而言之,我研究土壤、菌类、环境对乔木植物的生存影响数据的预测模型,这可能会增进土壤、菌类、环境对乔木植物的生存影响有了新的认识和亚热带森林巨大生产力和高生物多样性水平的理解。需要进一步的研究来阐明在土壤、菌类、环境对生存影响因子相互作用和各自和协同作用,特别是进行一些可操作的实验以找到更可靠的证据。
在实验中,我对数据集划分:将数据集划分为训练集和测试集,以确保模型在未知数据上的泛化能力。模型优化:根据评估结果对模型进行优化,以提高其性能。局限性分析:分析结果的局限性。有跟深一步的了解和运用。
感谢鄂大伟老师,给我运用Python大数据实践分析报告的机会,如有错误,请老师帮忙批评指正。