Transformer由谷歌团队在论文《Attention is All You Need》提出,是基于attention机制的模型,最大的特点就是全部的主体结构均为attention。
以下部分图片来自论文,部分图片来自李宏毅老师的transformer课程
课程链接:强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili
2023-12-12
transformer模型结构:

(1) Encoder(编码器)
如图4,红色部分为编码器部分,可以看出是由Multi-Head Attention,Add & Norm, Feed Forward, Add & Norm组成的。
1.1 Add & Norm
Add & Norm层由Add和Norm两个主体构成。其中,Add是指残差连接的部分,Norm是指Layer Norlization的部分。其计算公式如下:
(2). Decoder(解码器)
如图右半部分所示,为Decoder部分,结构上与Encoder类似,但是存在以下差别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个出现值的概率。
1、Self-attention:


自注意力机制中有三个重要的输入矩阵:查询矩阵Q(query)、键矩阵K(key)和值矩阵V(value)。这三个矩阵都是由输入序列经过不同的线性变换得到的。
a1,a2,a3,a4分别是有关输入的4个vector,以a1为例,a1 * Wq1 = q1(其中的Wq1也是一个矩阵,不过此矩阵是通过训练模型得到的参数,同理,k1,k2,k3,k4,v1,v2,v3,v4也是通过与矩阵Wk1,WK2,WV1,WV2...相乘得到)。
然后以q2为例,q2分别与k1,k2,k3,k4做dot-product(也是矩阵相乘)得到a2-1,a2-2,a2-3,a2-4
a2-1,a2-2,a2-3,a2-4分别与v1,v2,v3,v4矩阵相乘,再相加得到b2 (公式见图片右上角)
※ 自注意力机制的计算过程包括三个步骤:
- 计算注意力权重:计算每个位置与其他位置之间的注意力权重,即每个位置对其他位置的重要性。
- 计算加权和:将每个位置向量与注意力权重相乘,然后将它们相加,得到加权和向量。
- 线性变换:对加权和向量进行线性变换,得到最终的输出向量。



2、Multi-head self-attention 多头自注意力
transformer的attention是基于多头机制的self-attention构成的,将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。



与上面同理,只不过此处以两头为例,q1只与Ki1,kj1做dot-product得到ai1, aj1; ai1, aj1再与vi1,vj1做矩阵乘法,结果相加得到bi1
3、transformer's Encoder&Decoder


此处值得注意的是用到了残差模块residual,layer Norm,

第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置
在完成了编码阶段后,我们开始解码阶段。解码阶段的每个时间步都输出一个元素。
接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入加上位置编码,来指示每个词的位置。
Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于编码器栈的输出。
4、Decoder中的Masked self-attention

mask self-attention中“mask"代表了掩盖的意思,ai不再受右边的ai+n的影响,因为在生成的过程中,ai左边的已经生成了,而右边的并没有生成,无法对此处的ai产生影响。
5. Input
Transformer的输入主要由单词embedding和位置embedding组成Transformer的embedding
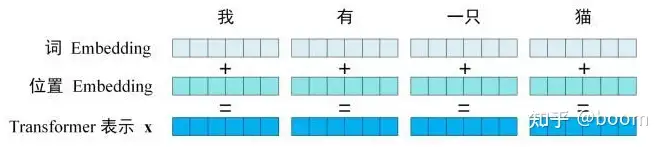
5.1单词embedding
单词embedding可以由多种方式获取,初始化+训练或者通过work2vec、glove等算法与训练得到。
5.2位置embedding
transformer最大的改变是彻底放弃了RNN结构,使用了self-attention作为核心的结构,self-attention利用的是全局信息,而没有使用位置信息,而这部分信息对NLP来说非常重要。所以,self-attention加入了位置embedding来弥补这部分的缺失。

Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。最后选择最高概率所对应的单词,作为这个时间步的输出.