2 命名的艺术
本章包括
- 命名
- 命名空间
"计算机科学中只有两件难事:缓存失效和命名。"这句话出自菲尔-卡尔顿(Phil Karlton)之口,他是网景公司(Netscape)的程序员。
2.1 命名
命名是你和Python共享某物身份的一种方式。通常,这意味着您要唯一地标识一个事物,使其与程序中所有其他被命名的事物区分开来。例如,美国的社会安全号是给人们的,这样他们就可以在美国的使用环境中唯一地识别自己。这串唯一的号码可以帮助人们就业、纳税、购买保险,以及从事其他各种需要全国唯一标识符的活动。
这是否意味着社会保障号是唯一事物的好名字?其实不然。除非你能进入使用该号码的系统,否则它是完全不透明的。它没有传递任何关于所标识事物的信息。
让我们把唯一名称的概念提升到另一个层次。有一种标准化的标识符被称为通用唯一标识符(UUID)。UUID是一串字符,就所有实际目的而言,在全世界都是唯一的。UUID示例如下
f566d4a9-6c93-4ee6-b3b3-3a1ffa95d2ae
您可以使用Python内置的UUID模块,根据UUID值创建有效的变量名:
>>> import uuid
>>> f"v_{uuid.uuid4().hex}"
'v_02f9c8953e2d4fb8ba83b65f1237f82f'
您可以用这种方法创建变量名,以便唯一标识应用程序中的所有内容。这些变量名在整个应用程序中和已知世界中都是唯一的。
以这种方式命名变量也是一种完全不可用的命名约定。变量名完全没有传递任何关于所标识事物的信息。这样的变量名输入起来也非常长,不可能记住,使用起来也不方便。
2.1.1 命名事物
创建有用的变量名需要花费精力,但作为开发人员,这是值得的。随着时间的推移,你会发现变量名很难更改。这是因为随着应用程序的开发和使用,对现有变量的依赖性会增加。选择好的变量名可以避免在使用过程中更改变量名。
变量名的长度也与编写代码的工作量有关。编程确实涉及到大量的键入,这意味着意义和简短之间的平衡非常重要。
你突然发现,整个语言都是你寻找命名单词和短语的地方。您的目标是找到既能附加元信息,又足够简短,不会妨碍编写或阅读一行程序代码的词语。这就限制了你在命名时可以或应该做的事情。就像画家在有限的调色板上创作一样,你可以选择沮丧,也可以在这种限制下发挥想象力,创作出具有艺术性和创造力的作品。
你要编写的许多程序都会包括对事物集合的循环、计数和相加。下面是一个二维表格的迭代代码示例:
t = [[12, 11, 4], [3, 22, 105], [0, 47, 31]]
for i, r in enumerate(t):
for j, it in enumerate(r):
process_item(i, j, it)
这段代码功能完善。t 变量由一个 Python 列表组成,代表一个二维表格。process_item() 函数需要知道项目--it 变量--在表中的行和列位置,才能正确处理它。变量 t、i、j、r 和 it 完全可以使用,但却没有告诉读者它们的意图。
修改后:
table = [[12, 11, 4], [3, 22, 105], [0, 47, 31]]
for row_index, row in enumerate(table):
for column_index, item in enumerate(row):
process_item(row_index, column_index, item)
开发过程中的另一个常见操作是计数和创建总数。下面是一些简单的示例:
total_employees = len(employees)
total_parttime_employees = len([
employee for employee in employees if employee.part_time
])
total_managers = sum([
employee for employee in employees if employee.manager
])
在前面的示例中,我们可以看到几个非常好的命名规则。employees 这个名字赋予了变量意义。复数 employees的使用表明这是可迭代的集合。它还表明该集合内部有一个或多个代表雇员的事物。列表理解中的变量employee表明它是雇员集合中的单个项目。
变量total_employees、total_parttime_employees和total_ managers的名称中使用了total,说明了它们所指的是什么。每一个变量都是一个总计数。每个变量名的第二部分表示被计算的事物。
除了数值计算,你还经常会遇到一些已经有名字的事物,比如公司、社区或小组中的人。当你收集用户输入或通过名字搜索某人时,有一个有用的变量名会让你更容易想到代码中要表示的事物:
full_name = "John George Smith"
根据您编写代码的目的,这可能是一个完全可以接受的变量名,用来表示姓名。通常情况下,在处理人名时,您需要更细化的变量名,并希望用部分变量名来表示人名:
first_name = "John"
middle_name = "George"
last_name = "Smith"
这些变量名也能很好地发挥作用,而且与full_name一样,这些变量名赋予了变量所代表的含义。下面是另一种变体
fname = "John"
mname = "George"
lname = "Smith"
这个版本采用了变量命名的惯例。这样的约定意味着你选择了一种模式来创建人的变量名。使用约定意味着读者必须知道并理解所使用的约定。上例中的折衷方法是减少键入,但变量名的含义仍然清晰。此外,由于变量名以单行编辑字体垂直排列,因此视觉效果可能更好。
采用约定是在变量命名限制条件下提高工作效率的一种技巧。如果速记命名约定在视觉上对你更有吸引力,那么在可视化解析代码时,你就能识别模式并找出错别字。
建立约定俗成的习惯有助于减轻开发人员的认知负担。你可以更多地考虑要解决的问题,而不是考虑如何命名。
2.1.2 命名实验
你可能不记得了,早期的个人电脑只有很小的硬盘驱动器。早期的操作系统也没有目录或子目录的概念;硬盘上的所有文件都存在于一个全局目录中。此外,文件名仅限于8个字符、点(.)和 3 个字符的扩展名,扩展名通常用来表示文件包含的内容。
正因为如此,人们发明了奇异而复杂的文件命名约定,以保持唯一性并防止文件名冲突。这些命名约定是以牺牲有逻辑意义的文件名为代价的。例如1995年10月创建的简历文件可能是这样的
res1095.doc
解决这个问题的办法是在操作系统中增加对命名子目录的支持,并取消文件名字符长度限制。现在,每个人都对此非常熟悉,因为你可以创建几乎无限深的目录和子目录结构。
下面是一个要求你满足的规范:你工作的会计部门要求所有费用报告的文件名都必须相同:expense.xlsx。你需要创建一个目录结构,让所有expenses.xlsx文件都能存在,并且不会相互碰撞或覆盖,以保存和跟踪这些费用文件。
约束条件是要求所有支出报告文件都有一个固定的文件名。隐含的限制条件是,无论你设计什么样的目录结构,都必须适用于你的工作所产生的尽可能多的费用报告。创建子目录的功能就是帮助你解决这个问题并将费用报告文件分开的工具。
任何解决方案都取决于你在工作中创建了多少份开支报告。如果你的工作是初级软件开发人员,你可能一年只出差几次。在这种情况下,你只需提供粗粒度的支出.xlsx文件,就可以将其分开。这种简单的结构将所有支出报告集中在一个名为expenses的根目录下。每份费用报告都存在于一个目录中,该目录以创建费用报告的完整日期命名。使用YYYY-MM-DD的日期格式会使目录在许多操作系统上显示时按有用的时间顺序排序。
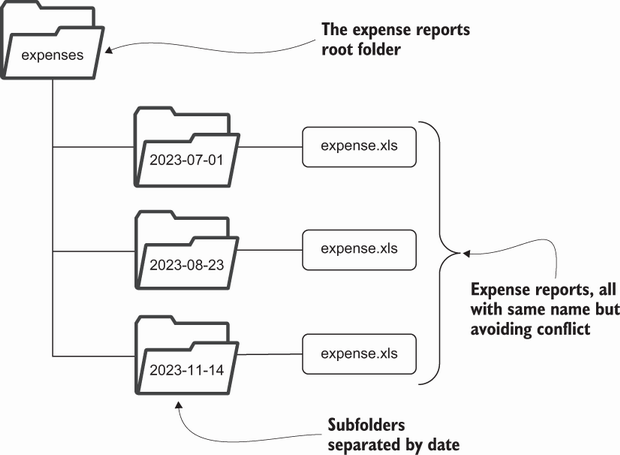
但是,如果你是一名销售工程师,你很可能经常出差,可能每天要会见多个客户。这就改变了你处理约束的方式,要求你的目录结构支持更多的粒度,以便将所有expenses.xlsx文件分开。对于销售工程师来说,一个可行的解决方案是使用年、月、日和客户名称值作为子目录。这样,即使每天拜访多个客户,也能保持expenses.xlsx文件的独立性。这样就形成了一种惯例,即特定expenses.xlsx文件路径的每一部分都有意义和价值。
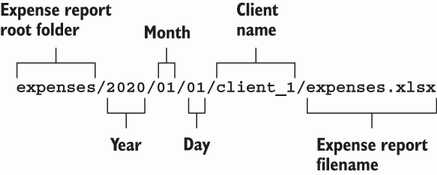
从前面的实验中我们可能看不出什么,但我们创建的变量名是有意义和约定俗成的。请看特定支出报告的目录路径。你创建了命名空间,每个命名空间都缩小了所包含内容的范围。从左到右阅读路径,你会发现路径的每一段都由 / 字符分隔,在前一段的上下文中创建了一个新的、范围更小的命名空间。
假设你是会计师,规定了费用报告的文件命名规则。作为会计,你必须保存员工提交的所有费用报告。你将受到与生成费用报告的员工相同的限制,但要保持所有员工的费用报告彼此不同并相互分离,这就增加了复杂性。

创建一个目录结构来处理增加的复杂性,可以包括更高级别的部门和员工抽象。创建一个提供这种粒度的目录结构来跟踪和保存所有员工费用报告是可行的。考虑到如何创建该结构,会计部门显然应该重新考虑文件命名要求和限制,并设计一个更好的系统。
2.2 命名空间
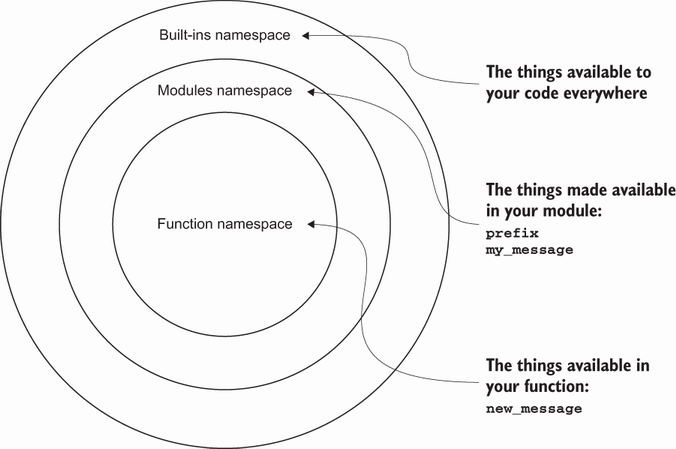
Python编程语言提供了创建名称空间的能力。在处理命名变量的约束、赋予它们意义、保持它们相对较短并避免冲突时,命名空间为您提供了很大的能力和控制。可以通过在命名空间放置变量名来实现这一点。在开始创建自己的命名空间之前,让我们先看看该语言提供的名称空间。
2.2.1内置级
当Python开始运行应用程序时,它会创建一个builtins命名空间,其中builtins是Python中最外层的命名空间,包含您可以随时访问的所有函数。例如,print()和open()函数存在于内置命名空间中。
你可以通过在Python交互提示符下输入以下命令来查看内置命名空间中的内容:
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EncodingWarning', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'aiter', 'all', 'anext', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
该命令在__builtins__对象上运行dir (directory)。
在使用内置命名空间时,完全有可能用您自己的命名空间覆盖名称空间中的对象。例如,你可以这样定义一个函数:
def open(...):
# run some code here
这个函数遮蔽了已经在内置命名空间中定义的open()函数。你可以通过创建如下的函数来处理这个问题:
def my_own_open(...):
# run some code here
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.2.2模块级别
将程序代码分解为包含逻辑分组功能的多个文件是一种有用的惯例。这样做有以下好处:
- 将相似的功能放在一起
- 防止程序文件变得太长
- 创建命名空间
utility.py:
def add(a, b):
return f"{a} {b}"
main.py
import utility
def add(a, b):
return a + b
print(add(12, 12))
print(utility.add(12, 12))
utility.py文件将两个add()函数定义分开。在main.py文件中,import utility语句告诉Python将utility.py文件中的所有对象拉到utility的新名称空间中。
在导入文件时使用from
通过利用文件系统目录结构,您可以创建名称空间层次结构。就像前面的目录结构命名实验一样,这为您提供了更多的工具来为您创建的层次结构创建意义和范围。
在main.py文件所在的文件夹中创建utilities的新目录。将utility.py文件移动到utilities目录,并将其重命名为strings.py。
在创建包含功能的目录层次结构时,需要记住的一件事是需要创建一个__init__.py文件。该文件必须存在于每个目录中,以让Python知道该目录包含功能或它的路径。当__init__.py文件存在于目录中时,该目录就是Python包。
通常__init__.py文件是空的,但它不必是空的。只要包含该文件的路径是import语句的一部分,该文件中的任何代码都将执行。
在此基础上,在实用程序目录中创建一个空的__init__.py文件。完成后,像这样修改main.py文件:
from utilities import strings
def add(a, b):
return a + b
print(add(12, 12))
print(strings.add(12, 12))
如果您使用过任何Python的标准模块,如sys,您可能会注意到这些标准模块不存在于您的程序的工作目录中,例如您之前创建的strings.py模块。Python通过路径列表搜索你想要导入的模块,首先是工作目录。
>>> import sys
>>> sys.path
['', 'D:\\anaconda\\python310.zip', 'D:\\anaconda\\DLLs', 'D:\\anaconda\\lib', 'D:\\anaconda', 'C:\\Users\\徐荣中\\AppData\\Roaming\\Python\\Python310\\site-packages', 'D:\\anaconda\\lib\\site-packages', 'D:\\anaconda\\lib\\site-packages\\win32', 'D:\\anaconda\\lib\\site-packages\\win32\\lib', 'D:\\anaconda\\lib\\site-packages\\Pythonwin']
列表中的第一个元素是一个空字符串。Python将在当前工作目录中查找模块。这就是它找到utilities包和该包中string模块的方式。
这也意味着,如果你创建了一个模块,并将其命名为Python系统模块,Python将首先找到你的包并使用它,而忽略系统包。在命名包和模块时,请记住这一点。
在我们的简短示例中,import sys语句导致Python搜索前面提到的路径列表。因为工作目录中不存在sys模块,所以它会在其他路径中查找标准模块。
路径列表在使用pip命令安装包或模块时使用。pip命令将在列表中的一个路径中安装包。如前所述,建议使用Python虚拟环境来防止pip安装到您的计算机系统的Python版本中。