实验13 大数据分析与挖掘建模
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 掌握使用Numpy、Pandas进行数据建模。
- 能够利用模型数据进行相关预测分析。
- 理解数据建模的编程过程。
二、实验要求
通过编程实现使用电信用户数据画像——建立RFM模型对电信电话数据集、短信数据集、上网流量数据集为用户贴标签,然后学习相关预测分析。
三、实验内容
任务1.电信用户画像
一、 实验准备
1.1 需求描述
以客户为中心目标是了解不同客户群体的需求,并向他们提供满足其个性化需求的服务——提供了更多附加值,与此同时也获得高于平均的客户价值。随着电信业产品同质化的趋势越来越明显,企业成功不能再单纯依靠创新产品和产品价格取胜。倾听客户呼声和需求、对不断变化的客户期望迅速作出反应的以客户为中心运营能力——已经成为当今企业能否成功的关键。
市场环境、运营重心和管控模式的转变,要求客户运营更具灵敏性、高效性,以客户洞察为核心的客户经营中心系统实现了“客户-产品”的双向自动匹配,支撑CRM、电子渠道等精准营销策略和客户需求信息的实时信息推送,培养了业务人员客户洞察能力。
基于客户洞察的分析
1、历史趋势分析,分析对应客户数的历史变化情况
2、构成分析,按照品牌、地市、VIP等级等维度,分析对应客户数的构成情况
3、关联分析,分析主体与不同标签之间的关联程度
4、对比分析,分析主体与不同标签之间的对比情况
根据用户的通话记录,短信记录,手机上网记录进行用户画像,建立画像标签跟通话、短信、手机上网的对应关系,结合RFM模型,输出用户画像标签。通过该实验了解数据梳理工作、模型设计工作、数据开发工作的相关内容。基于电信运营商的数据,给每一个客户打标签,标签的范围涉及衣食住行等。
电信运营商有三个典型数据集
1、通话数据
2、短信数据
3、手机上网数据
基于这三个数据集,结合RFM模型,构建用户标签体系,给每个用户打上标签,对用户进行画像,画像后的数据可以用于推荐、精准营销、客群分析等。
本实验为整个大实验的第一个步骤:基于通话数据生成RFM模型数据,输出每个客户在每个标签上的RFM标签值,这是一个中间结果集,用于计算最终的标签。
R:最近一次通话时间与统计月末的距离天数
F:通话次数
M:通话时长
最终数据结果示例如下:
手机号码 标签 R值 F值 M值
138* 旅游 1 0 0
138* 美食 0 1 1
138* 健身 1 1 0
131* 旅游 1 0 1
131* 美食 0 1 0
二、 实验步骤
2.1 导入相关的库,加载数据集
需要导入pandas模块
import pandas as pd
import numpy as np
电信用户数据分为三种类别,分别数电话数据、短信数据、以及APP使用数据,目前导入电话数据,包含电话明细表以及电话标签表
path1 = "dim_call_flag.tsv"
path2 = "ods_user_call_detail_dt_201612.tsv"
data_tele_tag = pd.read_csv(path1,sep='\t',names=["desc_num",'institution','tag'])
data_tele_detail = pd.read_csv(path2,sep='\t',names=["last_date","tele_num","desc_num",'count','duration'])
2.2 数据处理
需要将两种数据进行合并,合并成一个数据表后才能继续操作,代码如下:
data_tele = data_tele_tag.merge(data_tele_detail,left_on="desc_num",right_on='desc_num')
需要计算离月底最近的一次通话,所以需要进行日期的计算,代码如下:
data_tele["last_date"] = pd.to_datetime(data_tele.last_date,format='%Y-%m-%d')
data_tele["last_date_day"] = data_tele.last_date.dt.day
data_tele["diff_date"] = (31 - data_tele["last_date_day"]).astype('int')
2.3 电话数据RFM数据制作
分别计算不同电话、不同标签的最近一次通话、通话总次数以及通话总时长
def make_rfm(x):
def get_format_rfm(xx):
temp_date = xx.nsmallest(1,'diff_date')['diff_date'].iloc[0]
temp_count = xx['count'].sum()
temp_duration = xx["duration"].sum()
tem_series = pd.Series([temp_date,temp_count,temp_duration],index=['last_date','count','duration'])
return tem_series
return x.groupby('tag').apply(get_format_rfm)
data_tele_rfm = data_tele.groupby("tele_num").apply(make_rfm)
data_tele_rfm = data_tele_rfm.reset_index()
此次运行耗时较长,可以直接执行加载数据集的方法,此数据集是上述代码执行的结果
data_tele_rfm = pd.read_csv("tele数据rfm数据表.csv")
电话数据RFM数据归一化,简化模型,直接和各组的各个标签的平均值进行比较,代码如下:
avg_flag_days = data_tele_rfm.groupby("tag")['last_date'].mean()
avg_flag_counts = data_tele_rfm.groupby("tag")['count'].mean()
avg_flag_duration = data_tele_rfm.groupby("tag")['duration'].mean()
#通话日期归一
def rfm_format_days(x):
key = x['tag']
avg_value = avg_flag_days[key]
if x['last_date'] > avg_value:
flag_days = 0
else:
flag_days = 1
x['flag_days'] = flag_days
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_days,axis=1)
#通话次数归一
def rfm_format_counts(x):
key = x['tag']
avg_value = avg_flag_counts[key]
if x['count'] > avg_value:
flag_count = 1
else:
flag_count = 0
x['flag_count'] = flag_count
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_counts,axis=1)
#通话时长归一
def rfm_format_duration(x):
key = x['tag']
avg_value = avg_flag_duration[key]
if x['duration'] > avg_value:
flag_duration = 1
else:
flag_duration = 0
x['flag_duration'] = flag_duration
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_duration,axis=1)
此次运行耗时较长,可以直接执行加载数据集的方法,此数据集是上述代码执行的结果
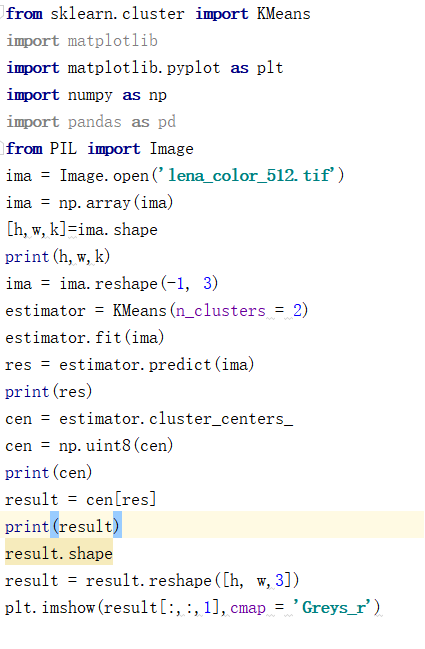
任务2:对一幅打开的彩色图像使用K-means算法对像素进行聚类分析,实现图像分割。
test13.py
import pandas as pd
import numpy as np
# 电信用户数据分为三种类别,分别数电话数据、短信数据、以及APP使用数据,目前导入电话数据,包含电话明细表以及电话标签表
path1 = "dim_call_flag.tsv"
path2 = "ods_user_call_detail_dt_201612.tsv"
data_tele_tag = pd.read_csv(path1, sep='\t', names=["desc_num", 'institution', 'tag'])
data_tele_detail = pd.read_csv(path2, sep='\t', names=["no","last_date", "tele_num", "desc_num", 'count', 'duration'])
# 需要将两种数据进行合并,合并成一个数据表后才能继续操作,代码如下:
data_tele = data_tele_tag.merge(data_tele_detail, left_on="desc_num", right_on='desc_num')
# 需要计算离月底最近的一次通话,所以需要进行日期的计算,代码如下:
data_tele["last_date"] = pd.to_datetime(data_tele.last_date, format='%Y-%m-%d')
data_tele["last_date_day"] = data_tele.last_date.dt.day
data_tele["diff_date"] = (31 - data_tele["last_date_day"]).astype('int')
# 分别计算不同电话、不同标签的最近一次通话、通话总次数以及通话总时长
def make_rfm(x):
def get_format_rfm(xx):
temp_date = xx.nsmallest(1, 'diff_date')['diff_date'].iloc[0]
temp_count = xx['count'].sum()
temp_duration = xx["duration"].sum()
tem_series = pd.Series([temp_date, temp_count, temp_duration], index=['last_date', 'count', 'duration'])
return tem_series
return x.groupby('tag').apply(get_format_rfm)
data_tele_rfm = data_tele.groupby("tele_num").apply(make_rfm)
data_tele_rfm = data_tele_rfm.reset_index()
# 此次运行耗时较长,可以直接执行加载数据集的方法,此数据集是上述代码执行的结果
# data_tele_rfm = pd.read_csv("tele数据rfm数据表.csv")
# 电话数据RFM数据归一化,简化模型,直接和各组的各个标签的平均值进行比较,代码如下:
avg_flag_days = data_tele_rfm.groupby("tag")['last_date'].mean()
avg_flag_counts = data_tele_rfm.groupby("tag")['count'].mean()
avg_flag_duration = data_tele_rfm.groupby("tag")['duration'].mean()
# 通话日期归一
def rfm_format_days(x):
key = x['tag']
avg_value = avg_flag_days[key]
if x['last_date'] > avg_value:
flag_days = 0
else:
flag_days = 1
x['flag_days'] = flag_days
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_days, axis=1)
# 通话次数归一
def rfm_format_counts(x):
key = x['tag']
avg_value = avg_flag_counts[key]
if x['count'] > avg_value:
flag_count = 1
else:
flag_count = 0
x['flag_count'] = flag_count
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_counts, axis=1)
# 通话时长归一
def rfm_format_duration(x):
key = x['tag']
avg_value = avg_flag_duration[key]
if x['duration'] > avg_value:
flag_duration = 1
else:
flag_duration = 0
x['flag_duration'] = flag_duration
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_duration, axis=1)
pd.DataFrame(data_tele_rfm).to_csv('tele数据rfm数据表.csv')
test13_1.py
import pandas as pd
import numpy as np
# 电信用户数据分为三种类别,分别数电话数据、短信数据、以及APP使用数据,目前导入电话数据,包含电话明细表以及电话标签表
path1 = "dim_sms_flag.tsv"
path2 = "ods_user_sms_detail_dt_201612.tsv"
data_tele_tag = pd.read_csv(path1, sep='\t', names=["no","desc_num", 'institution', 'tag'])
data_tele_detail = pd.read_csv(path2, sep='\t', names=["no","last_date", "tele_num", "desc_num", 'count'])
# 需要将两种数据进行合并,合并成一个数据表后才能继续操作,代码如下:
data_tele = data_tele_tag.merge(data_tele_detail, left_on="desc_num", right_on='desc_num')
# 需要计算离月底最近的一次通话,所以需要进行日期的计算,代码如下:
data_tele["last_date"] = pd.to_datetime(data_tele.last_date, format='%Y-%m-%d')
data_tele["last_date_day"] = data_tele.last_date.dt.day
data_tele["diff_date"] = (31 - data_tele["last_date_day"]).astype('int')
# 分别计算不同电话、不同标签的最近一次通话、通话总次数以及通话总时长
def make_rfm(x):
def get_format_rfm(xx):
temp_date = xx.nsmallest(1, 'diff_date')['diff_date'].iloc[0]
temp_count = xx['count'].sum()
# temp_duration = xx["duration"].sum()
tem_series = pd.Series([temp_date, temp_count], index=['last_date', 'count'])
return tem_series
return x.groupby('tag').apply(get_format_rfm)
data_tele_rfm = data_tele.groupby("tele_num").apply(make_rfm)
data_tele_rfm = data_tele_rfm.reset_index()
# 此次运行耗时较长,可以直接执行加载数据集的方法,此数据集是上述代码执行的结果
# data_tele_rfm = pd.read_csv("tele数据rfm数据表.csv")
# 电话数据RFM数据归一化,简化模型,直接和各组的各个标签的平均值进行比较,代码如下:
avg_flag_days = data_tele_rfm.groupby("tag")['last_date'].mean()
avg_flag_counts = data_tele_rfm.groupby("tag")['count'].mean()
# avg_flag_duration = data_tele_rfm.groupby("tag")['duration'].mean()
# 短信日期归一
def rfm_format_days(x):
key = x['tag']
avg_value = avg_flag_days[key]
if x['last_date'] > avg_value:
flag_days = 0
else:
flag_days = 1
x['flag_days'] = flag_days
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_days, axis=1)
# 短信次数归一
def rfm_format_counts(x):
key = x['tag']
avg_value = avg_flag_counts[key]
if x['count'] > avg_value:
flag_count = 1
else:
flag_count = 0
x['flag_count'] = flag_count
return x
data_tele_rfm = data_tele_rfm.apply(rfm_format_counts, axis=1)
pd.DataFrame(data_tele_rfm).to_csv('tele数据rfm数据表2.csv')
test13_2.py
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 读取图像
ima = Image.open('lena_color_512.tif')
ima = np.array(ima)
# 获取图像维度
[h, w, k] = ima.shape
print(h, w, k)
# 将图像数据变形为一维数组
ima_flat = ima.reshape(-1, 3)
# 使用 K-means 算法进行聚类
estimator = KMeans(n_clusters=2)
estimator.fit(ima_flat)
res = estimator.predict(ima_flat)
print(res)
# 获取聚类中心
cen = estimator.cluster_centers_
cen = np.uint8(cen)
print(cen)
# 根据聚类结果和中心值得到分割后的图像
result = cen[res].reshape([h, w, 3])
# 显示原始图像和分割结果
plt.subplot(1, 2, 1)
plt.imshow(ima)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(result)
plt.title('Segmented Result')
plt.show()