每个数据库系统都要确保持久性和可靠性。MongoDB使用journal和检查点来
每个数据库系统都必须确保持久性和可靠性。MongoDB使用Journals和Checkpoints完成WAL(Write-Ahead-Logging)。
从最基本的开始,为什么首先需要WAL?这是为了确保我们的数据在每次写操作之后都是持久的,并且在不影响性能的情况下使其持久化和一致。
就MongoDB而言,它通过结合使用Journals和Checkpoints来实现WAL和数据持久性。让我们来了解一下这两种方法。
1.Journal
在这个过程中,每个写操作都会从内存写入(附加)到一个Journal文件,就是众所周知的事务日志,根据配置按指定间隔写入磁盘。配置选项为journalCommitIntervalMs,默认是100毫秒。
在检查点之间发生崩溃、电源和硬件故障时,可从日志文件恢复丢失的数据,从而确保持久性。
下面是对整个过程的描述:
·对于每次写操作,MongoDB都会将修改写入Journal文件,即事务日志文件,就是上文讨论的MongoDB使用的WAL机制。这发生在每个journalCommitIntervalMs。
·在Wiredtiger缓存中的数据页会被标记为脏页。
以下是使用wt(WiredTiger Binary)工具分析出的journal日志的内容:
$ wt printlog -u -x{ "lsn" : [15,256],"hdr_flags" : "","rec_len" : 256,"mem_len" : 256,"type" : "commit","txnid" : 3836082,"ops": [{ "optype": "row_put","fileid": 14 0xe,"key": "u00e8du001au0015bu00ffu00ffu00dfu00c1","key-hex": "e8641a1562ffffdfc1","value": "gu0000u0000u0000u0002o….,"value-hex": "67000000026f7….."}]},{ "lsn" : [15,512],"hdr_flags" : "","rec_len" : 128,"mem_len" : 128,"type" : "commit","txnid" : 3836083,"ops": [{ "optype": "row_modify","fileid": 6 0x6,"key": "u0081","key-hex": "81","value": "u0001u0000u0000u….","value-hex": "010000000000000008000000000000003e0000000000000008000000000000000100000063151a64"}
2.Checkpoint
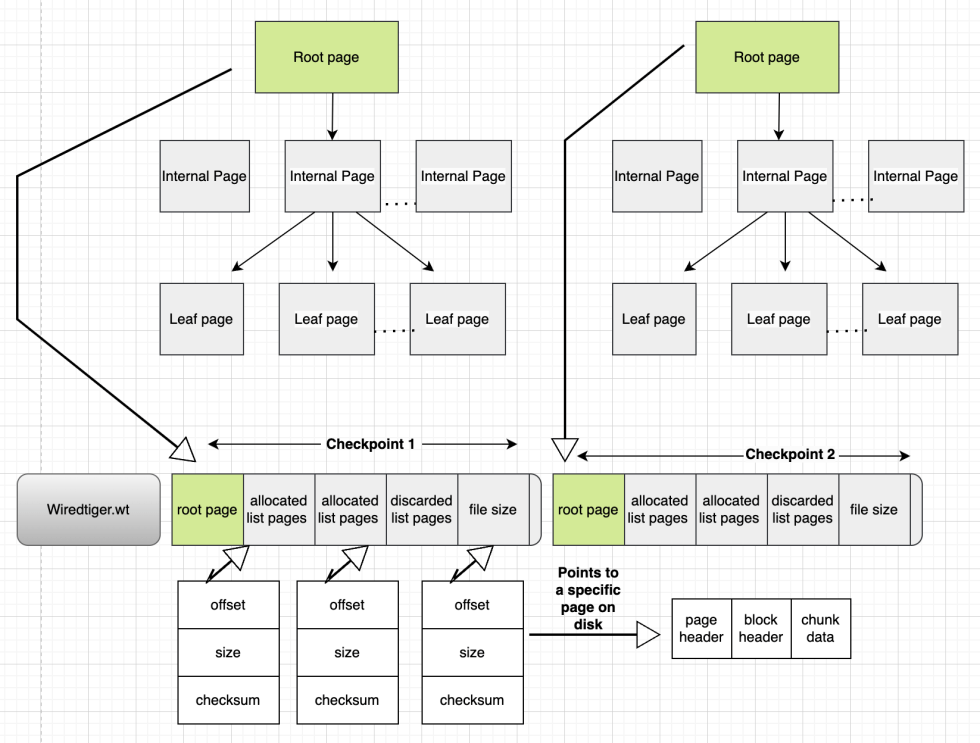
每个检查点包括一个根页,三个指向磁盘上特定位置的列表页,以及磁盘上的文件大小。
在每个检查点间隔(默认60秒),MongoDB会将缓存中被标记为脏的修改页刷新到各自的数据文件中(collection-*.wt和index-*.wt)。
使用"wt"工具,我们可以列出检查点并查看它们所包含的信息。下图所示的是与每个数据文件(集合和索引)相关的检查点信息。这些检查点存储在WiredTiger.wt文件中。
$ wt list -cWiredTigerCheckpoint.33: Sun Mar 26 08:35:59 2022 (size 8 KB)file-size: 8 KB, checkpoint-size: 4 KB offset, size, checksum root : 8192, 4096, 3824871989 (0xe3faea35)alloc: 12288, 4096, 4074814944 (0xf2e0bde0)discard : 0, 0, 0 (0)available : 0, 0, 0 (0)WiredTigerCheckpoint.34: Sun Mar 26 08:35:59 2022 (size 8 KB)file-size: 8 KB, checkpoint-size: 4 KB offset, size, checksum root : 8192, 4096, 997122142 (0x3b6ee05e)alloc: 12288, 4096, 4074814944 (0xf8e0cde0)discard : 0, 0, 0 (0) available : 0, 0, 0 (0)
检查点包含的信息:
·根页:包含根页的大小,在文件中的偏移量,检查和。当创建一个新的检查点,就会创建一个新的根页
·内部页:只是包含了keys。wt引擎通过遍历内部页来找对应的叶子页
·叶子页:包含实际的keys:value值对
·分配的页列表:在最近的检查点之后,wt引擎的块管理器会记录新创建的页和相关信息,比如大小,偏移量,检查和
·丢弃的页列表:检查点完成后,相关的页会被丢弃。但是其相关信息还会被存储
可用的页列表:执行检查点时,wt引擎的块管理器分配的页中,还没有被使用的页。当删除之前的检查点,其对应的可用的页会被合并到最新检查点的可用列表。
·文件大小:检查点完成时候,磁盘上文件系统的大小。
尽管事务日志和检查点这两个过程看起来有点类似,但是他们的目的不同。一方面,日志是在事务日志的追加(append)操作;检查点处理的数据文件,由于其复杂性,开销更大,特别是对磁盘的随机操作。
一般来说,检查点的出发条件是:
·每60秒。
·eviction_dirty_target或eviction_dirty_trigger达到了5%和20%。通常很少遇到,只是发生在写的负载超过了硬件的处理能力。
如果发生了意外崩溃或者硬件故障,会发生什么呢?让我们来看看我们启动mongod的过程。
1.mongod尝试进入崩溃恢复过程,查看Journal日志文件中的内容
{"t":{"$date":"2023-03-27T11:22:48.360+00:00"},"s":"I", "c":"STORAGE", "id":22430, "ctx":"initandlisten","msg":"WiredTiger message","attr":{"message":"[1679916168:360670][9811:0x7f43b45d7bc0], txn-recover: [WT_VERB_RECOVERY_PROGRESS] Recovering log 15 through 16"}}7bc0], txn-recover: [WT_VERB_RECOVERY | WT_VERB_RECOVERY_PROGRESS] Set global recovery timestamp: (1679916159, 1)"}}{"t":{"$date":"2023-03-27T11:22:48.688+00:00"},"s":"I", "c":"STORAGE", "id":22430, "ctx":"initandlisten","msg":"WiredTiger message","attr":{"message":"[1679916168:688481][9811:0x7f43b45d7bc0], txn-recover: [WT_VERB_RECOVERY | WT_VERB_RECOVERY_PROGRESS] Set global oldest timestamp: (1679916154, 1)"}}{"t":{"$date":"2023-03-27T11:22:48.695+00:00"},"s":"I", "c":"STORAGE", "id":22430, "ctx":"initandlisten","msg":"WiredTiger message","attr":{"message":"[1679916168:695497][9811:0x7f43b45d7bc0], WT_SESSION.checkpoint: [WT_VERB_CHECKPOINT_PROGRESS] saving checkpoint snapshot min: 10, snapshot max: 10 snapshot count: 0, oldest timestamp: (1679916154, 1) , meta checkpoint timestamp: (1679916159, 1) base write gen: 11982970"}}{"t":{"$date":"2023-03-27T11:22:48.705+00:00"},"s":"I", "c":"RECOVERY", "id":23987, "ctx":"initandlisten","msg":"WiredTiger recoveryTimestamp","attr":{"recoveryTimestamp":{"$timestamp":{"t":1679916159,"i":1}}}}
2.从数据文件中找出最后一个成功的检查点,根据事务日志恢复未提交的脏数据。对应数据页就会变成脏页。
file:demo/collection/108-2625234990440311433.wtaccess_pattern_hint=none,allocation_size=4KB,app_metadata=(formatVersion=1),assert=(commit_timestamp=none,durable_timestamp=none,read_timestamp=none,write_timestamp=off),block_allocation=best,block_compressor=snappy………checkpoint=(WiredTigerCheckpoint.33=(addr="018081e49e1d91ae9a81e4b44eefcd9b81e4be132c8a808080e30d3fc0e30c4fc0",order=33,time=1679897278,size=819200,newest_start_durable_ts=7215101747935576783,oldest_start_ts=0,......,checkpoint_backup_info=,checkpoint_lsn=(4294967295,2147483647)
3.下一个检查点,会将脏页刷新到磁盘。不需要的juournal日志条目将在检查点执行后进行相应清理。