作业①
1、码云链接:实验一码云链接
2、实验要求及内容
实验要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
▪输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
实验内容:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
from sqlalchemy import create_engine
import pandas as pd
opt = Options()
opt.add_experimental_option("detach",True)
# 沪深京
websites = ["https://quote.eastmoney.com/center/gridlist.html#hs_a_board","https://quote.eastmoney.com/center/gridlist.html#sh_a_board","https://quote.eastmoney.com/center/gridlist.html#sz_a_board"]
# 下一页
def next_page():
botton = web.find_element(By.XPATH,"//a[@class='next paginate_button']")
botton.click()
time.sleep(0.5)
def get_data(page):
global stock
for p in range(page):
# 爬取所需要的数据
trs = web.find_elements(By.XPATH,"//body//tr")
# print(trs)
for r in range(1,len(trs)):
tr = trs[r]
line = []
data = tr.text.split()
# print(data)
line += [data[1],data[2],data[6],data[7],data[8],data[9],data[10],data[11],data[12],data[13],data[14],data[15]]
stock.append(line)
next_page()
# 学号最后一位
page = 7
stock = []
# 依次访问沪深京股票页面并将其爬取下来
for website in websites:
web = Chrome(options=opt)
web.get(website)
get_data(page)
# 存取到名为stock_exercise4的表中
df = pd.DataFrame(data=stock,columns=['代码','名称','最新价','涨跌幅','涨跌额','成交量','成交额','振幅','最高','最低','今收','昨收'])
engine = create_engine("mysql+mysqlconnector://root:@127.0.0.1:3306/selenium")
df.to_sql('stock_exercise4',engine,if_exists="replace")
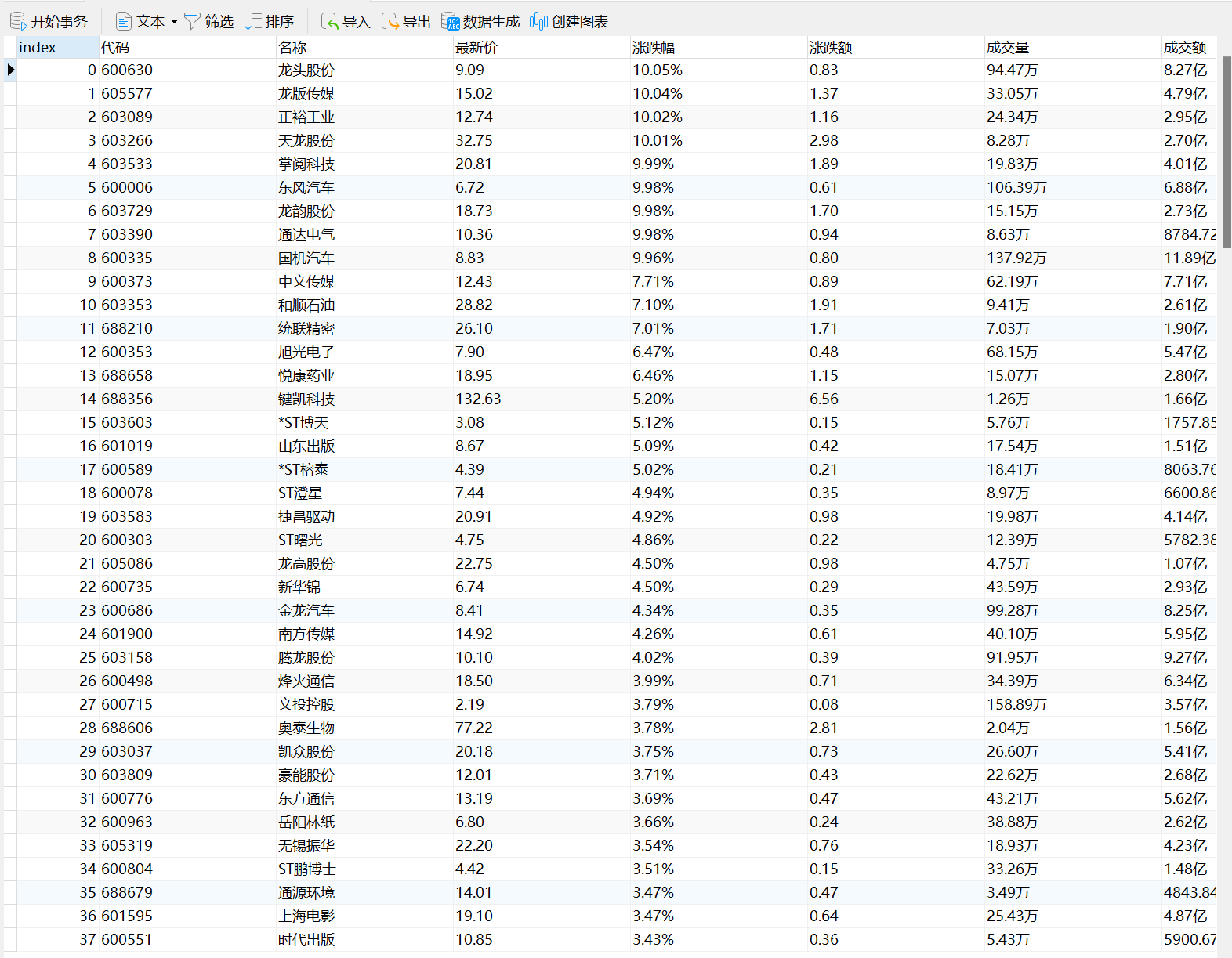
实验结果
通过navicat进行数据可视化
3、心得体会
与scrapy对比,selenium不需要进行抓包处理,可以模拟网站访问相对应的网页,提供了丰富的页面元素捕获方式,上手比较容易,通过本次实验也对selenium有了进一步的了解。
作业②
1、码云链接实验二码云链接
2、实验要求及内容
实验要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 输出信息:MYSQL 数据库存储和输出格式
实验内容
from selenium.webdriver import Chrome
import pandas as pd
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.chrome.options import Options
from sqlalchemy import create_engine
opt = Options()
opt.add_experimental_option("detach",True)
web = Chrome(options = opt)
web.get('https://www.icourse163.org/')
# 登录
log_in = web.find_element(By.XPATH,'//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
log_in.click()
# time.sleep(100000)
# 跳转到iframe中
web.switch_to.default_content()
web.switch_to.frame(web.find_element(By.XPATH,"/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe"))
# 登录自己的账号
user = web.find_element(By.XPATH,"//html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input")
user.clear()
user.send_keys("13506915655")
time.sleep(1)
password = web.find_element(By.XPATH,"//html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]")
password.clear()
password.send_keys("Chs123456.")
time.sleep(1)
sign_in = web.find_element(By.ID,'submitBtn')
sign_in.click()
web.switch_to.default_content()
# into 高等数学
time.sleep(15)
input_search = web.find_element(By.XPATH,"/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input")
input_search.send_keys("高等数学")
search = web.find_element(By.XPATH,"/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span")
search.click()
# 下一页
def next_page():
next_botton = web.find_element(By.CLASS_NAME,'th-bk-main-gh')
next_botton.click()
# 数据获取
def get_data():
courses = web.find_elements(By.XPATH,"//div[@class='cnt f-pr']")
global datas
for course in courses:
data = []
name = course.find_element(By.XPATH,".//span[@class=' u-course-name f-thide']").text
# print(name)
college = course.find_element(By.XPATH,".//a[@class='t21 f-fc9']").text
teacher = course.find_element(By.XPATH,".//a[@class='f-fc9']").text
team = course.find_elements(By.XPATH,".//a[@class='f-fc9']")
team_number = ''
for number in team:
team_number = team_number + str(number.text) + ','
partitioners = course.find_element(By.XPATH,".//span[@class='hot']").text
date = course.find_element(By.XPATH,".//span[@class='txt']").text
introduce = course.find_element(By.XPATH,".//span[@class='p5 brief f-ib f-f0 f-cb']").text
data += [name,college,teacher,team_number,partitioners,date,introduce]
# print(data)
datas.append(data)
datas = []
page_number = 7 # 学号最后一位
# for i in range(page_number):
time.sleep(3)
get_data()
df = pd.DataFrame(data=datas,columns=['ccourse','ccollege','cteacher','cteam','ccount','cprocess','cbrief'])
engine = create_engine("mysql+mysqlconnector://root:@127.0.0.1:3306/selenium")
df.to_sql("mooc_exercise4",engine,if_exists="replace")
3、心得体会
在实践过程中,一直无法捕获登录页面。然后发现想要进行登录时页面出现了iframe,因此需要通过switch_to.frame跳转到小窗口,一开始通过BY.TAG_NAME来进行捕获iframe但是一直无法正确捕获,被迫使用XPATH才成功登录进慕课平台。通过本次实验收获最大的就是窗口的转换以及元素获取的步骤。
作业③
1、实验要求及内容
实验要求
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
实验内容
• 环境搭建:
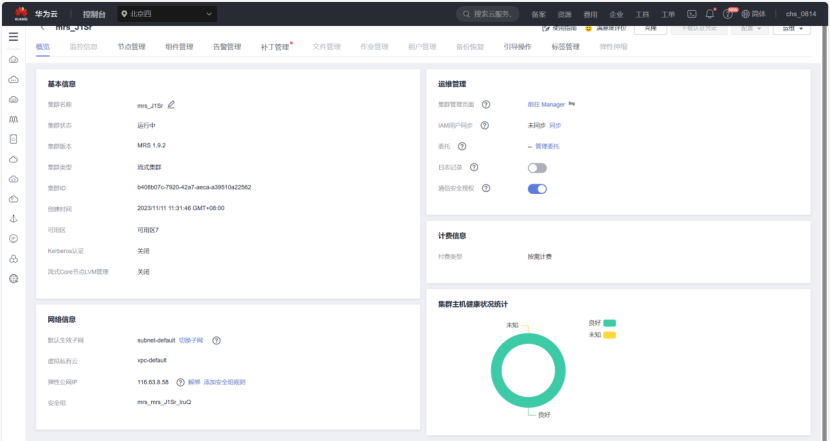
·任务一:开通 MapReduce 服务
配置好集群
登录admin
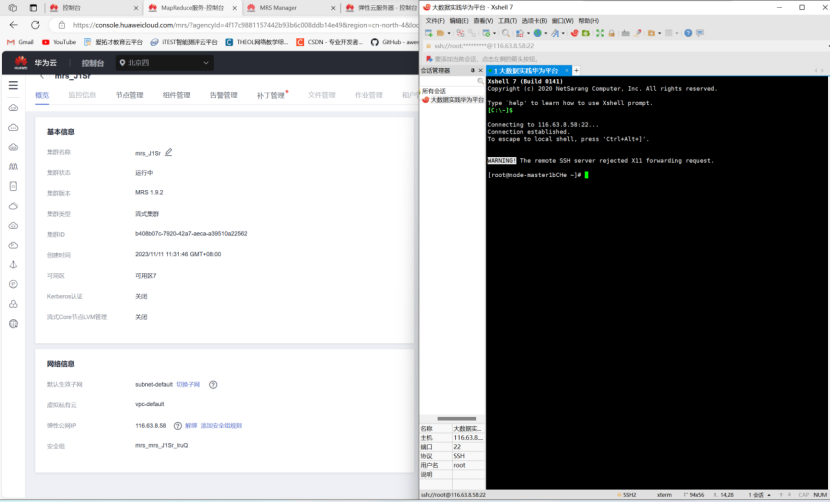
通过xshell进行连接公网ip
• 实时分析开发实战:
·任务一:Python 脚本生成测试数据
通过用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/
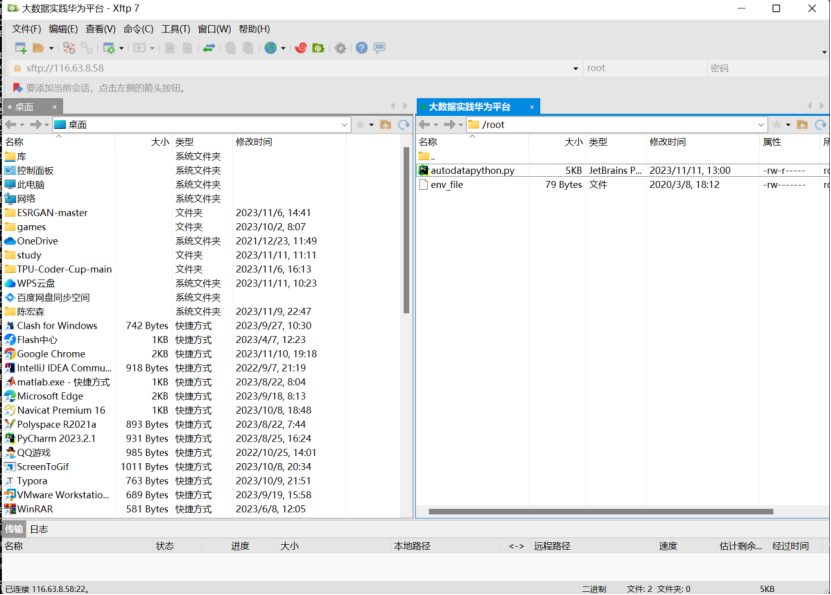
执行python文件,获取其100条数据
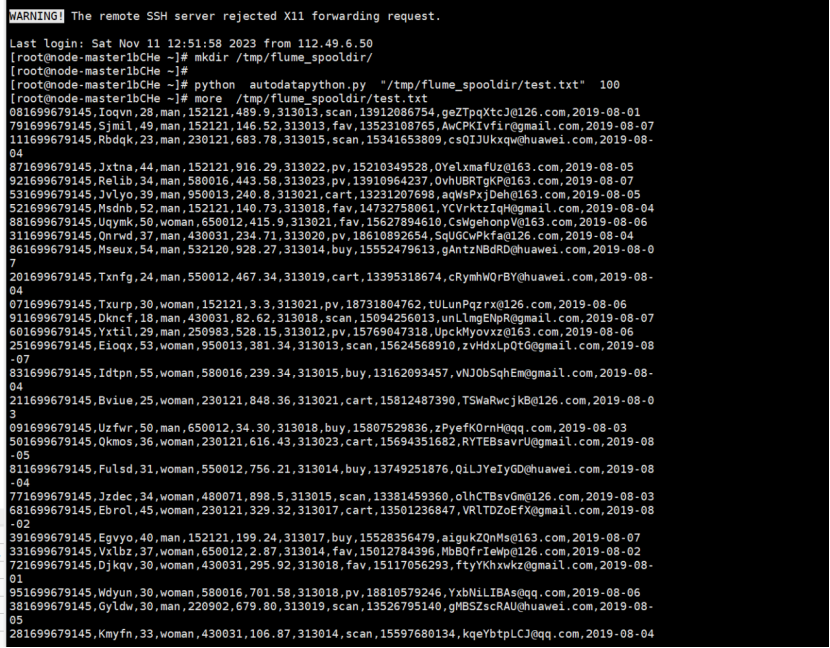
·任务二:配置 Kafka
查找自己Zookeeper的IP
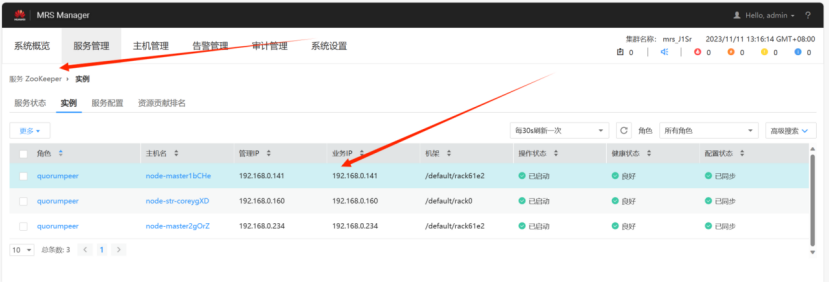
①执行source语句配置环境变量使其生效
②如下图在kafka中创建topic并查看topic信息

·任务三: 安装 Flume 客户端
进入MRS Manager集群管理界面,打开服务管理,点击flume,进入Flume服务,下载Flume客户端
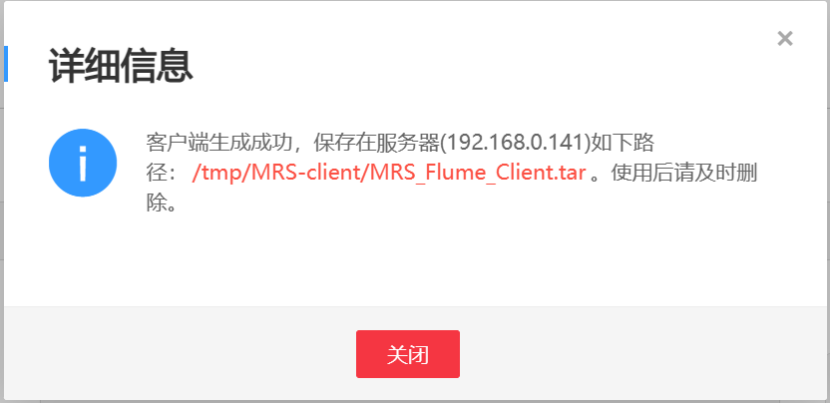
解压压缩包获取校验文件与客户端配置包并校验文件包


解压“MRS_Flume_ClientConfig.tar”文件!
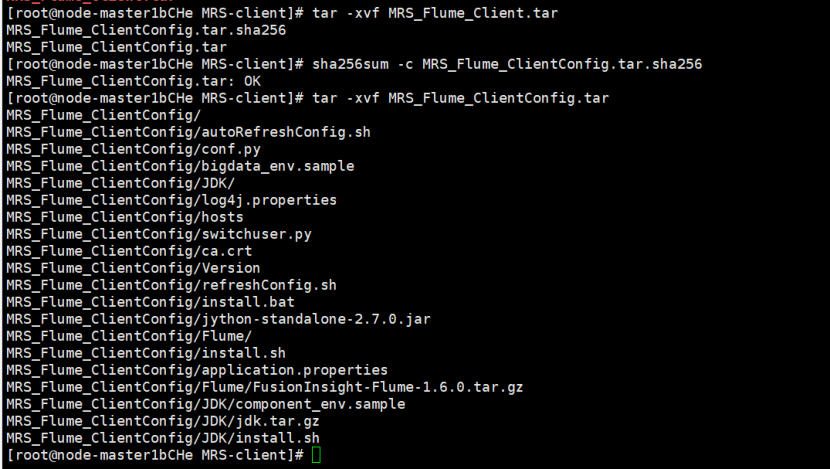
安装Flume环境变量并解压Flume客户端
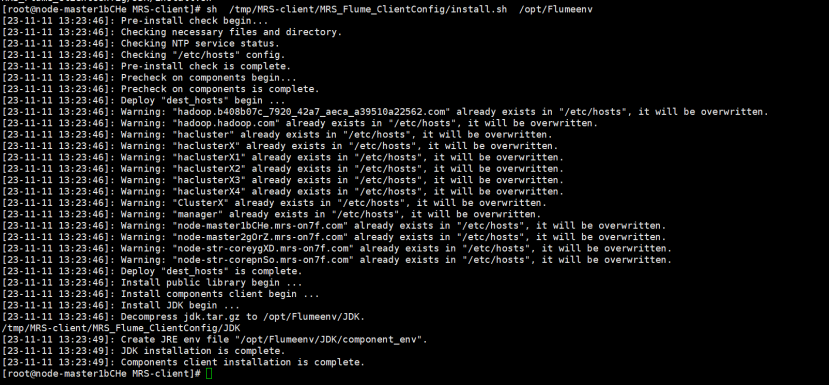
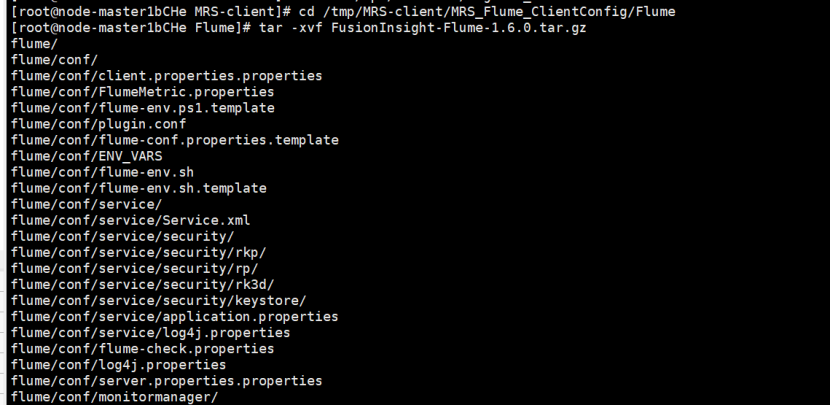
安装Flume客户端

重启Flume服务

·任务四:配置 Flume 采集数据
通过xftp7将本地的properties.properties文件上传至服务器
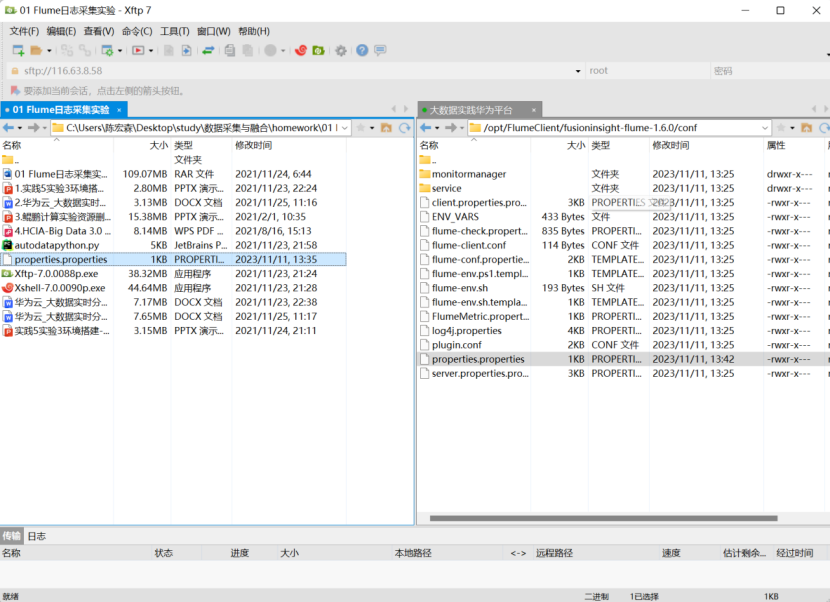
查看broker的ip

登录Master节点,source环境变量后,执行一下命令

在新开一个Xshell 7窗口,执行Python命令,再生成一份数据,查看Kafka中是否有数据产生
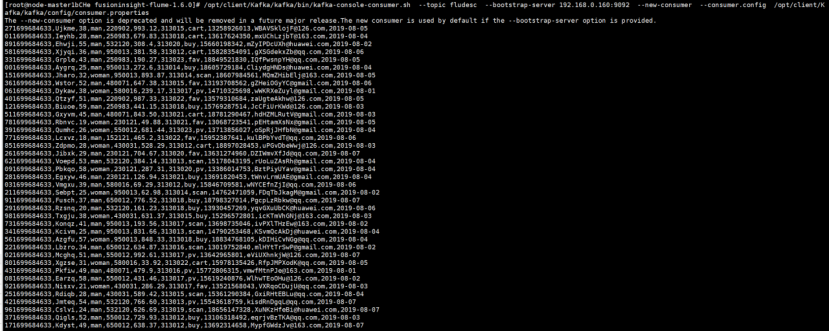
2、心得体会
本次实验实在华为云平台上进行Flume搭建,学习了如何搭建Flume以及如何进行数据采集,虽然对其不是很了解,但是通过本次实验领悟到了其功能的强大之处。