原文:Mastering OpenCV 4 with Python
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
第 2 部分:OpenCV 中的图像处理
在本书的第二部分中,您将更深入地了解 OpenCV 库。 更具体地说,您将看到计算机视觉项目中所需的大多数常见图像处理技术。 此外,您还将看到如何创建和理解直方图,直方图是用于更好地理解图像内容的强大工具。 此外,您将在计算机视觉应用中看到所需的主要阈值处理技术,这是图像分割的关键部分。 此外,您还将看到如何处理轮廓,轮廓用于形状分析以及对象检测和识别。 最后,您将学习如何构建第一个增强现实应用。
本节将介绍以下章节:
- 第 5 章,“图像处理技术”
- 第 6 章,“直方图的构建”
- 第 7 章,“阈值处理技术”
- 第 8 章,“轮廓检测,过滤和绘制”
- 第 9 章,“增强现实”
五、图像处理技术
图像处理技术是计算机视觉项目的核心。 它们可以看作是有用的关键工具,可用于完成各种任务。 换句话说,图像处理技术就像构造块,在处理图像时应牢记。 因此,如果要使用计算机视觉项目,则需要对图像处理有基本的了解。
在本章中,您将学习所需的大多数常见图像处理技术。 这些将由本书的后三章介绍的其他图像处理技术(直方图,阈值技术,轮廓检测和滤波)进行补充。
本章将讨论以下主题:
- 拆分和合并通道
- 图像的几何变换-平移,旋转,缩放,仿射变换,透视变换和裁剪
- 使用图像进行算术运算—按位运算(AND,OR,XOR 和 NOT)和掩码
- 平滑和锐化技术
- 形态操作
- 色彩空间
- 颜色图
技术要求
本章的技术要求如下:
- Python 和 OpenCV
- 特定于 Python 的 IDE
- NumPy 和 Matplotlib 包
- 一个 Git 客户端
有关如何安装这些要求的更多详细信息,请参见第 1 章,“设置 OpenCV”。 《精通 Python OpenCV 4》的 GitHub 存储库,其中包含从第一章到最后一章学习本书所需的所有支持项目文件,可以在以下网址访问。
在 OpenCV 中拆分和合并通道
有时,您必须使用多通道图像上的特定通道。 为此,您必须将多通道图像拆分为几个单通道图像。 此外,一旦处理完成,您可能想从不同的单通道图像创建一个多通道图像。 为了同时分割和合并通道,可以分别使用cv2.split()和cv2.merge()函数。 cv2.split()函数将源多通道图像分割为几个单通道图像。 cv2.merge()函数将几个单通道图像合并为一个多通道图像。
在下一个示例splitting_and_merging.py中,您将学习如何使用上述两个函数。 使用cv2.split()函数,如果要从已加载的 BGR 图像中获取三个通道,则应使用以下代码:
(b, g, r) = cv2.split(image)
使用cv2.merge()函数,如果要从其三个通道再次构建 BGR 图像,则应使用以下代码:
image_copy = cv2.merge((b, g, r))
您应该记住cv2.split()是一项耗时的操作,因此仅在绝对必要时才应使用它。 否则,您可以使用 NumPy 函数处理特定的通道。 例如,如果要获取图像的蓝色通道,可以执行以下操作:
b = image[:, :, 0]
另外,您可以消除(设置为0)多通道图像的某些通道。 生成的图像将具有相同数量的通道,但在相应通道中具有0值; 例如,如果要消除 BGR 图像的蓝色通道,可以使用以下代码:
image_without_blue = image.copy()
image_without_blue[:, :, 0] = 0
如果执行splitting_and_merging.py脚本,则会看到以下屏幕截图:
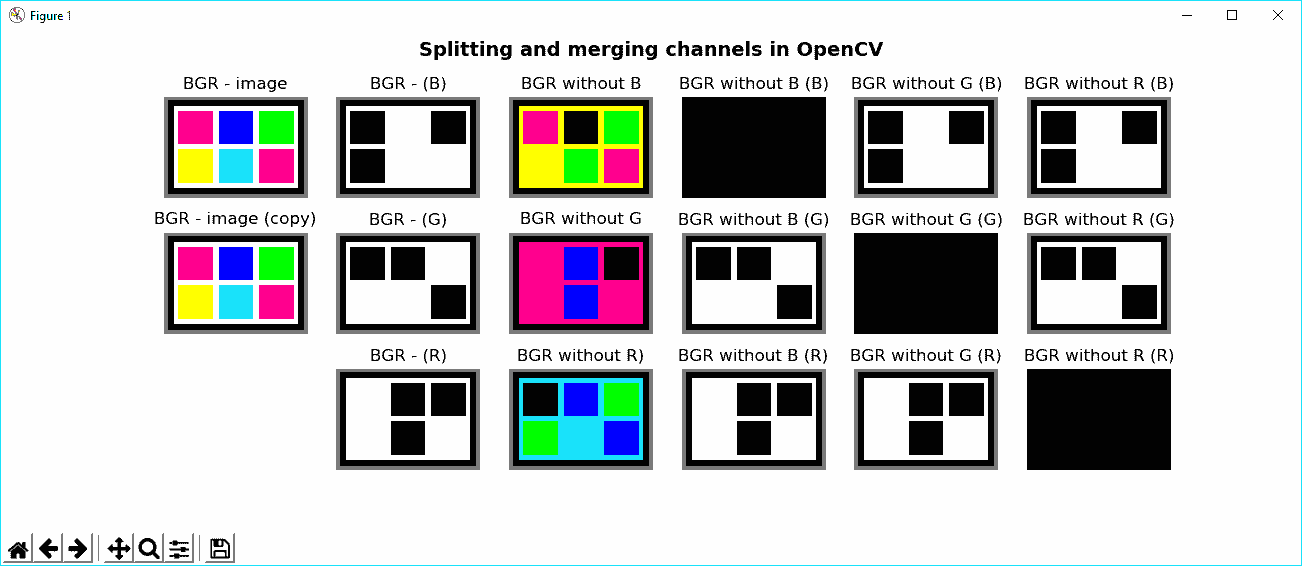
为了理解此屏幕截图,您应该记住 RGB 颜色空间的累加属性。 例如,使用不带 B 的 BGR 子图,您可以看到它大部分是黄色的。 这是因为绿色和红色值产生黄色。 您可以看到的另一个关键特征是与我们设置为0的特定通道相对应的黑色子图。
图像的几何变换
在本节的第一部分中,将介绍图像的主要几何变换。 我们将看一些缩放,平移,旋转,仿射变换,透视变换和图像裁剪的示例。 执行这些几何变换的两个关键函数是cv2.warpAffine()和cv2.warpPerspective()。 cv2.warpAffine()函数通过使用以下2 x 3的M变换矩阵来变换源图像:

cv2.warpPerspective()函数使用以下3 x 3转换矩阵对源图像进行转换:
在接下来的小节中,我们将学习最常见的几何变换技术,当我们查看geometric_image_transformations.py脚本时,将学习更多有关几何变换的技术。
缩放图像
缩放图像时,可以调用特定大小的cv2.resize(),并且缩放因子(fx和fy)将根据提供的大小进行计算,如以下代码所示:
resized_image = cv2.resize(image, (width * 2, height * 2), interpolation=cv2.INTER_LINEAR)
另一方面,您可以同时提供fx和fy值。 例如,如果要将图像缩小2倍,则可以使用以下代码:
dst_image = cv2.resize(image, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
如果要放大图像,最好的方法是使用cv2.INTER_CUBIC插值方法(一种费时的插值方法)或cv2.INTER_LINEAR。 如果要缩小图像,通常的方法是使用cv2.INTER_LINEAR。
OpenCV 提供的五种插值方法是cv2.INTER_NEAREST(最近邻插值),cv2.INTER_LINEAR(双线性插值),cv2.INTER_AREA(使用像素面积关系重采样),cv2.INTER_CUBIC(双曲线插值)和cv2.INTER_LANCZOS4(正弦形) 插值)。
平移图像
为了转换对象,您需要使用带有浮点值的 NumPy 数组来创建2 x 3转换矩阵,以提供x和y方向(以像素为单位),如以下代码所示:
M = np.float32([[1, 0, x], [0, 1, y]])
这给出了以下M转换矩阵:
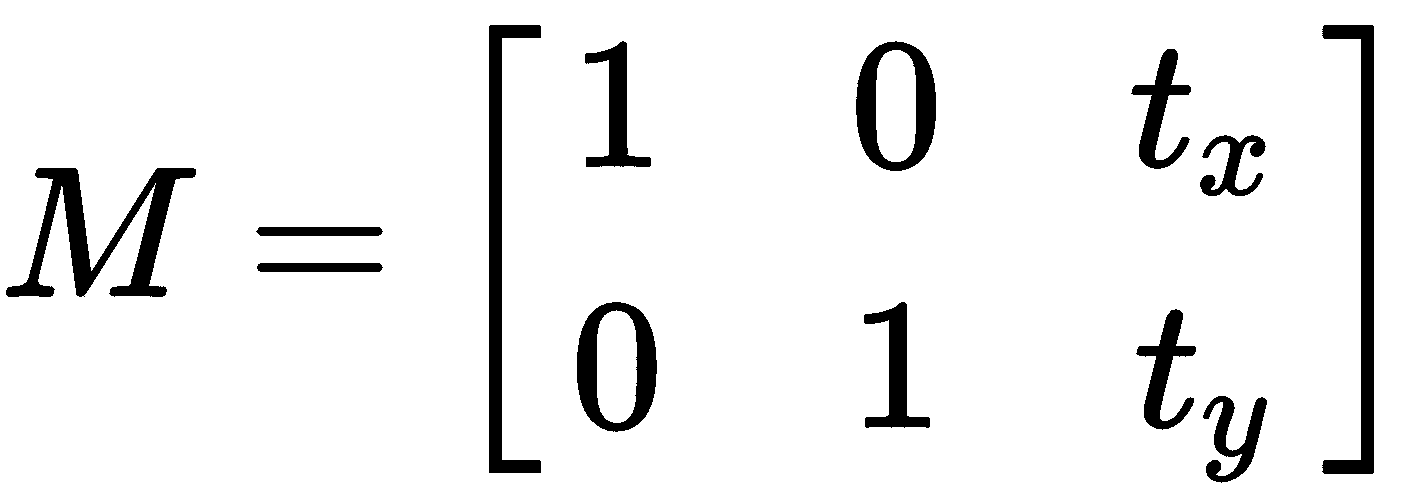
创建此矩阵后,将调用cv2.warpAffine()函数,如以下代码所示:
dst_image = cv2.warpAffine(image, M, (width, height))
cv2.warpAffine()函数使用提供的M矩阵变换源图像。 第三个(width, height)参数确定输出图像的大小。
请记住,image.shape返回(width, height)。
例如,如果要转换x方向为200像素,y方向为30像素的图像,请使用以下内容:
height, width = image.shape[:2]
M = np.float32([[1, 0, 200], [0, 1, 30]])
dst_image = cv2.warpAffine(image, M, (width, height))
请注意,转换也可以是负数,如以下代码所示:
M = np.float32([[1, 0, -200], [0, 1, -30]])
dst_image = cv2.warpAffine(image, M, (width, height))
旋转图像
为了旋转图像,我们利用cv.getRotationMatrix2D()函数来构建2 x 3变换矩阵。 该矩阵以所需角度(以度为单位)旋转图像,其中正值表示逆时针旋转。 旋转center和scale因子也都可以调整。 在我们的示例中使用这些元素,将计算以下转换矩阵:

该表达式具有以下值:

下面的示例构建M变换矩阵,以1的比例因子(不缩放)相对于图像中心旋转180度。 然后,将此M矩阵应用于图像,如下所示:
height, width = image.shape[:2]
M = cv2.getRotationMatrix2D((width / 2.0, height / 2.0), 180, 1)
dst_image = cv2.warpAffine(image, M, (width, height))
图像的仿射变换
在仿射变换中,我们首先使用cv2.getAffineTransform()函数来构建2 x 3变换矩阵,该矩阵将从输入图像和变换图像中的相应坐标获得。 最后,将该M矩阵传递给cv2.warpAffine(),如下所示:
pts_1 = np.float32([[135, 45], [385, 45], [135, 230]])
pts_2 = np.float32([[135, 45], [385, 45], [150, 230]])
M = cv2.getAffineTransform(pts_1, pts_2)
dst_image = cv2.warpAffine(image_points, M, (width, height))
仿射变换是保留点,直线和平面的变换。 另外,在此变换之后,平行线将保持平行。 但是,仿射变换不能同时保留点之间的距离和角度。
图像的透视变换
为了校正透视图(也称为透视变换),您将需要使用cv2.getPerspectiveTransform()函数创建变换矩阵,其中构造了3 x 3矩阵。 此函数需要四对点(源图像和输出图像中的四边形的坐标),并从这些点计算透视变换矩阵。 然后,将M矩阵传递到cv2.warpPerspective(),在其中通过应用具有指定大小的指定矩阵来变换源图像,如以下代码所示:
pts_1 = np.float32([[450, 65], [517, 65], [431, 164], [552, 164]])
pts_2 = np.float32([[0, 0], [300, 0], [0, 300], [300, 300]])
M = cv2.getPerspectiveTransform(pts_1, pts_2)
dst_image = cv2.warpPerspective(image, M, (300, 300))
裁剪图像
要裁剪图像,我们将使用 NumPy 切片,如以下代码所示:
dst_image = image[80:200, 230:330]
如前所述,这些几何变换的代码对应于geometric_image_transformations.py脚本。
过滤图像
在本节中,我们将解决如何通过应用几个过滤器和定制核来模糊和锐化图像。 此外,我们将研究一些常见的核,这些核可用于执行其他图像处理功能。
应用任意核
OpenCV 提供cv2.filter2D()函数,以便将任意核应用于图像,从而将图像与提供的核进行卷积。 为了了解此函数的工作原理,我们应该先构建核,稍后再使用。 在这种情况下,将使用5 x 5核,如以下代码所示:
kernel_averaging_5_5 = np.array([[0.04, 0.04, 0.04, 0.04, 0.04], [0.04, 0.04, 0.04, 0.04, 0.04], [0.04, 0.04, 0.04, 0.04, 0.04],[0.04, 0.04, 0.04, 0.04, 0.04], [0.04, 0.04, 0.04, 0.04, 0.04]])
这对应于5 x 5平均核。 另外,您还可以像这样创建核:
kernel_averaging_5_5 = np.ones((5, 5), np.float32) / 25
然后,通过应用上述函数,将核应用于源图像,如以下代码所示:
smooth_image_f2D = cv2.filter2D(image, -1, kernel_averaging_5_5)
现在我们已经看到了将任意核应用于图像的方法。 在前面的示例中,创建了一个平均核来平滑图像。 还有其他无需创建核即可执行图像平滑的方法(也称为图像模糊)。 相反,可以将其他一些参数提供给相应的 OpenCV 函数。 在smoothing_techniques.py脚本中,您可以看到此先前示例和下一小节的完整代码。
平滑图像
如前所述,在smoothing_techniques.py脚本中,您将看到其他常用的滤波技术来执行平滑操作。 平滑技术通常用于减少噪声,此外,这些技术还可应用于减少低分辨率图像中的像素化效果。 这些技术评论如下。
您可以在以下屏幕截图中看到此脚本的输出:

在前面的屏幕截图中,您可以看到在图像处理中应用通用核的效果。
均值过滤
您可以同时使用cv2.blur()和cv2.boxFilter()通过将图像与核进行卷积来执行平均,在cv2.boxFilter()情况下,该核可以不规范化。 它们仅获取核区域下所有像素的平均值,然后用该平均值替换中心元素。 您可以控制核大小和锚定核(默认为(-1,-1),这意味着锚定位于核中心)。 当cv2.boxFilter()的normalize参数(默认为True)等于True时,两个函数执行相同的操作。 这样,两个函数都使用核对图像进行平滑处理,如以下表达式所示:
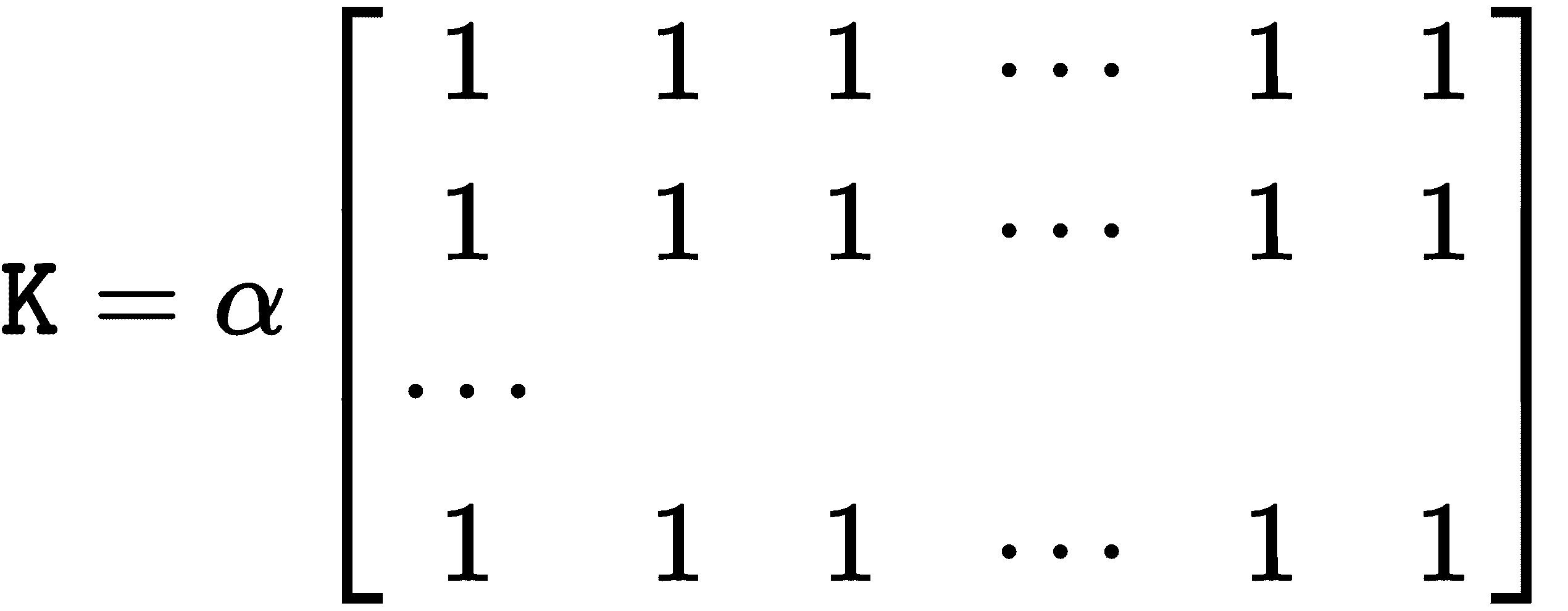
对于cv2.boxFilter()函数:
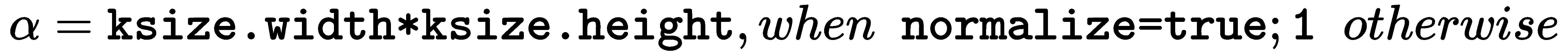
对于cv2.blur()函数:

换句话说,cv2.blur()始终使用标准化的框式过滤器,如以下代码所示:
smooth_image_b = cv2.blur(image, (10, 10))
smooth_image_bfi = cv2.boxFilter(image, -1, (10, 10), normalize=True)
在前面的代码中,两行代码是等效的。
高斯过滤
OpenCV 提供cv2.GaussianBlur()函数,该函数使用高斯核模糊图像。 可以使用以下参数控制该核:ksize(核大小),sigmaX(x-高斯核方向的标准差)和sigmaY(y-高斯核的方向)。 为了知道已经应用了哪个核,可以使用cv2.getGaussianKernel()函数。
例如,在下面的代码行中,cv2.GaussianBlur()使用大小为(9, 9)的高斯核模糊图像:
smooth_image_gb = cv2.GaussianBlur(image, (9, 9), 0)
中值过滤
OpenCV 提供cv2.medianBlur()函数,该函数使用中值核模糊图像,如以下代码所示:
smooth_image_mb = cv2.medianBlur(image, 9)
可以应用此过滤器来减少图像的椒盐噪声。
双边过滤
可以将cv2.bilateralFilter()函数应用于输入图像,以便应用双边过滤器。 此函数可用于减少噪声,同时保持边缘清晰,如以下代码所示:
smooth_image_bf = cv2.bilateralFilter(image, 5, 10, 10)
应当注意,所有先前的过滤器都倾向于使包括边缘在内的所有图像平滑。
锐化图像
与最后一个函数结合使用,您可以尝试一些选项以锐化图像的边缘。 一种简单的方法是执行所谓的锐化遮罩,其中从原始图像中减去图像的锐化或平滑版本。 在以下示例中,首先应用了高斯平滑过滤器,然后从原始图像中减去了所得图像:
smoothed = cv2.GaussianBlur(img, (9, 9), 10)
unsharped = cv2.addWeighted(img, 1.5, smoothed, -0.5, 0)
另一种选择是使用特定的核锐化边缘,然后应用cv2.filter2D()函数。 在sharpening_techniques.py脚本中,有一些定义的核可用于此目的。 以下屏幕快照显示了此脚本的输出:

在前面的屏幕截图中,您可以看到应用不同的锐化核的效果,可以在sharpening_techniques.py脚本中看到。
图像处理中的常见核
我们已经看到核对生成的图像有很大的影响。 在filter_2D_kernels.py脚本中,有一些定义的通用核可用于不同目的-边缘检测,平滑,锐化或压花等。 提醒一下,为了应用特定的核,应使用cv2.filter2D()函数。 以下屏幕快照显示了此脚本的输出:

您可以使用cv2.filter2D()函数查看应用不同核的效果,该函数可用于应用特定核。
创建卡通化图像
如前所述,可以使用cv2.bilateralFilter()来减少噪声,同时保留尖锐的边缘。 但是,此过滤器可以在滤波后的图像中同时产生强度平稳(阶梯效应)和假边缘(梯度反转)。 尽管可以在过滤后的图像中考虑到这一点(对处理这些伪像的双边过滤器进行了一些改进),但是创建卡通化图像可能非常酷。 完整的代码可以在cartoonizing.py中看到,但是在本节中,我们将进行简要描述。
将图像卡通化的过程非常简单,可以在cartonize_image()函数中执行。 首先,基于图像的边缘构造图像的草图(请参见sketch_image()函数)。 还有其他边缘检测器可以使用,但是在这种情况下,使用拉普拉斯算子。 在调用cv2.Laplacian()函数之前,我们通过cv2.medianBlur()中值过滤器对图像进行平滑处理来降低噪声。 一旦获得边缘,则通过应用cv2.threshold()对所得图像进行阈值处理。 我们将在下一章中介绍阈值技术,但是在本示例中,此函数从给定的灰度图像中为我们提供了一个与sketch_image()函数的输出相对应的二进制图像。 您可以使用阈值(在这种情况下固定为70)进行操作,以查看该值如何控制结果图像中出现的黑色像素(对应于检测到的边缘)数量。 如果此值较小(例如10),则会出现许多黑色边框像素。 如果该值较大(例如200),则几乎不会输出黑色边框像素。 为了获得卡通效果,我们将cv2.bilateralFilter()函数称为具有较大值的函数(例如cv2.bilateralFilter(img, 10, 250, 250))。 最后一步是使用草图图像作为遮罩,使用cv2.bitwise_and()将草图图像和双边过滤器的输出放在一起,以便将这些值设置为输出。 如果需要,输出也可以转换为灰度。 注意cv2.bitwise_and()函数是按位操作,我们将在下一部分中看到。
为了完整起见,OpenCV 提供了类似的功能,并且也在此脚本中进行了测试。 它可以使用以下过滤器工作:
cv2.pencilSketch():此过滤器生成铅笔素描线图(类似于我们的sketch_image()函数)。cv2.stylization():此过滤器可用于产生各种非真实感效果。 在这种情况下,我们应用cv2.stylization()以获得卡通效果(类似于我们的cartonize_image()函数)。
以下屏幕快照显示了与cartoonizing.py脚本对应的输出:
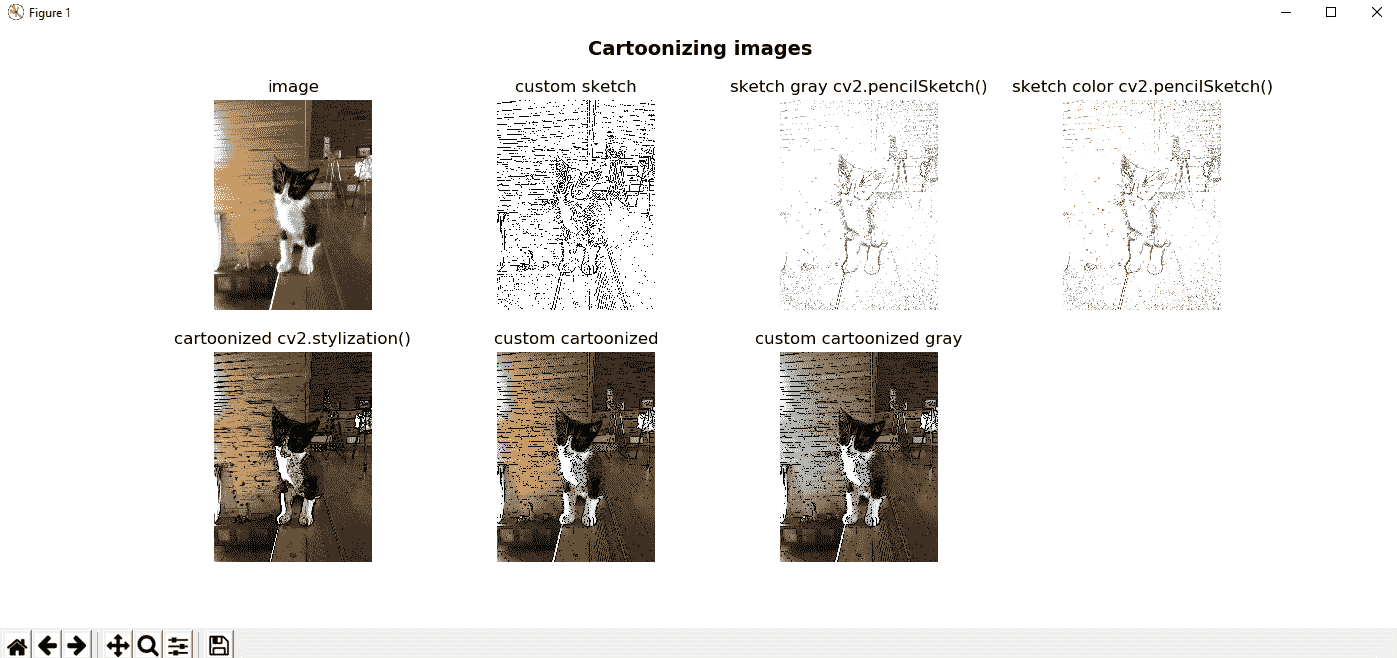
如您所见,cartonize_image()函数还可以输出调用cv2.cvtColor()的灰度图像,以将图像从 BGR 转换为灰度。
图像算术
在本节中,我们将学习一些可以在图像上执行的常见算术运算,例如按位运算,加法和减法。 与这些操作有关,要考虑的一个关键点是饱和算法的概念,以下小节对此进行了说明。
饱和算法
饱和算术是一种算术运算,其中通过限制运算可以采用的最大值和最小值将运算限制在固定范围内。 例如,对图像的某些操作(例如,色彩空间转换,插值技术等)可能会产生超出可用范围的值。 为了解决这个问题,使用了饱和算法。
例如,要存储r(这可能是对 8 位图像(值范围从0到255的值)执行特定操作的结果),请应用以下公式:

可以在以下saturation_arithmetic.py脚本中看到此概念:
x = np.uint8([250])
y = np.uint8([50])
# 250+50 = 300 => 255:
result_opencv = cv2.add(x, y)
print("cv2.add(x:'{}' , y:'{}') = '{}'".format(x, y, result_opencv))
# 250+50 = 300 % 256 = 44
result_numpy = x + y
print("x:'{}' + y:'{}' = '{}'".format(x, y, result_numpy))
在 OpenCV 中,对值进行裁剪以确保它们永远不会超出[0, 255]范围。 这称为饱和操作。 在 NumPy 中,值被包裹起来。 这也称为取模操作。
图像加减
可以分别通过cv2.add()和cv2.subtract()函数执行图像加和减。 这些函数对两个数组的每个元素进行求和/减法。 这些函数还可以用于对数组和标量求和/相减。 例如,如果要向图像的所有像素添加60,我们首先必须使用以下代码构建要添加到原始图像的图像:
M = np.ones(image.shape, dtype="uint8") * 60
然后,我们使用以下代码执行添加:
added_image = cv2.add(image, M)
另一种可能性是创建标量并将其添加到原始图像。 例如,如果要将110添加到图像的所有像素,则首先必须使用以下代码构建标量:
scalar = np.ones((1, 3), dtype="float") * 110
然后,我们使用以下代码执行加法:
added_image_2 = cv2.add(image, scalar)
在减法的情况下,过程相同,但是我们调用了cv2.subtract()函数。 可以在arithmetic.py中看到此脚本的完整代码。 在以下屏幕截图中可以看到此脚本的输出:

在前面的屏幕截图中,您可以清楚地看到添加和减去预定义值的效果(以两种不同的方式计算,但显示的结果相同)。 当我们添加一个值时,图像将更亮,而当我们减去一个值时,图像将更暗。
图像融合
图像融合也是图像添加,但是对图像赋予不同的权重,给人以透明感。 为此,将使用cv2.addWeighted()函数。 此函数通常用于从Sobel运算符获取输出。
Sobel运算符用于边缘检测,在其中创建强调边缘的图像。 Sobel运算符使用两个3×3核,它们与原始图像卷积在一起,以便计算导数的近似值,同时捕获水平和垂直变化,如以下代码所示:
# Gradient x is calculated:
# the depth of the output is set to CV_16S to avoid overflow
# CV_16S = one channel of 2-byte signed integers (16-bit signed integers)
gradient_x = cv2.Sobel(gray_image, cv2.CV_16S, 1, 0, 3)
gradient_y = cv2.Sobel(gray_image, cv2.CV_16S, 0, 1, 3)
因此,在计算出水平和垂直变化之后,可以使用上述函数将它们混合成图像,如下所示:
# Conversion to an unsigned 8-bit type:
abs_gradient_x = cv2.convertScaleAbs(gradient_x)
abs_gradient_y = cv2.convertScaleAbs(gradient_y)
# Combine the two images using the same weight:
sobel_image = cv2.addWeighted(abs_gradient_x, 0.5, abs_gradient_y, 0.5, 0)
可以在arithmetic_sobel.py脚本中看到。 在以下屏幕截图中可以看到此脚本的输出:

在前面的屏幕截图中,显示了Sobel运算符的输出,包括水平和垂直更改。
按位运算
可以使用按位运算符在位级别执行某些操作,这些操作可用于操纵值以进行比较和计算。 这些按位运算很简单,并且计算很快。 这意味着它们是处理图像时的有用工具。
按位运算包括AND,OR,NOT和XOR。
- 按位与:
bitwise_and = cv2.bitwise_and(img_1, img_2) - 按位或:
bitwise_xor = cv2.bitwise_xor(img_1, img_2) - 按位异或:
bitwise_xor = cv2.bitwise_xor(img_1, img_2) - 按位非:
bitwise_not_1 = cv2.bitwise_not(img_1)
为了解释这些操作的工作方式,请在以下屏幕截图中查看bitwise_operations.py脚本的输出:

为了进一步处理按位运算,您可以查看下面的bitwise_operations_images.py脚本,其中加载了两个图像并执行了一些按位运算(AND 和 OR)。 应当注意,图像应具有相同的形状:
# Load the original image (250x250):
image = cv2.imread('lenna_250.png')
# Load the binary image (but as a GBR color image - with 3 channels) (250x250):
binary_image = cv2.imread('opencv_binary_logo_250.png')
# Bitwise AND
bitwise_and = cv2.bitwise_and(image, binary_image)
# Bitwise OR
bitwise_or = cv2.bitwise_or(image, binary_image)
在以下屏幕截图中可以看到输出:

在上一个屏幕截图中,您可以在执行按位运算(AND,OR)时看到生成的图像。
形态变换
形态变换是通常在二进制图像上并且基于图像形状执行的操作。 确切的操作由核结构元素确定,该元素决定了操作的性质。 膨胀和侵蚀是形态转换领域中的两个基本运算符。 另外,打开和关闭是两个重要的操作,它们是从上述两个操作(膨胀和腐蚀)派生而来的。 最后,还有其他三个基于这些先前操作之间的差异的操作。
所有这些形态转换将在以下小节中介绍,morphological_operations.py脚本显示了将这些转换应用于某些测试图像时的输出。 关键点也将被注解。
膨胀操作
对二值图像进行膨胀操作的主要效果是逐渐扩展前景对象的边界区域。 这意味着在这些区域内的孔缩小时,前景对象的区域将变大。 以下代码显示了操作的详细信息:
dilation = cv2.dilate(image, kernel, iterations=1)
侵蚀操作
对二进制图像进行腐蚀操作的主要效果是逐渐侵蚀掉前景对象的边界区域。 这意味着前景对象的区域将变小,并且这些区域内的孔洞将变大。 您可以在以下代码中查看此操作的详细信息:
erosion = cv2.erode(image, kernel, iterations=1)
打开操作
对于两个操作,打开操作都执行侵蚀,然后使用相同的结构元素(或核)进行膨胀。 这样,可以施加腐蚀来消除一小组不希望的像素(例如,盐和胡椒噪声)。
侵蚀将不加选择地影响图像的所有区域。 通过在腐蚀之后执行膨胀操作,我们将减少其中一些影响。 您可以在以下代码中查看此操作的详细信息:
opening = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
关闭操作
与其相反,关闭操作可以从腐蚀和膨胀运算中得出。 在这种情况下,操作会先进行扩张,然后进行腐蚀。 膨胀操作通常用于填充图像中的小孔。 但是,膨胀操作也会使不希望出现的像素的较小组变大。 通过在膨胀后对图像进行腐蚀操作,可以减少这种影响。 您可以在以下代码中查看此操作的详细信息:
closing = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernel)
形态梯度操作
形态学梯度运算定义为输入图像的膨胀和腐蚀之间的差:
morph_gradient = cv2.morphologyEx(image, cv2.MORPH_GRADIENT, kernel)
高帽操作
高帽操作定义为输入图像和图像打开之间的差异。 您可以在以下代码中查看此操作的详细信息:
top_hat = cv2.morphologyEx(image, cv2.MORPH_TOPHAT, kernel)
黑帽操作
黑帽操作定义为输入图像和输入图像关闭之间的差异。 您可以在以下代码中查看此操作的详细信息:
black_hat = cv2.morphologyEx(image, cv2.MORPH_BLACKHAT, kernel)
结构元素
与结构元素一起,OpenCV 提供了cv2.getStructuringElement()函数。
此函数输出所需的核(类型为uint8的 NumPy 数组)。 应该向该函数传递两个参数-核的形状和大小。 OpenCV 提供以下三种形状:
- 矩形核:
cv2.MORPH_RECT - 椭圆核:
cv2.MORPH_ELLIPSE - 十字形核:
cv2.MORPH_CROSS
将形态学变换应用于图像
在morphological_operations.py脚本中,我们使用不同的核大小和形状,形态转换和图像。 我们将在本节中描述此脚本的一些关键点。
首先,build_kernel()函数根据核类型和大小返回用于形态转换的特定核。 其次,morphological_operations词典包含所有已实现的形态学运算。 如果我们打印字典,输出将如下所示:
index: '0', key: 'erode', value: '<function erode at 0x0C1F8228>'
index: '1', key: 'dilate', value: '<function dilate at 0x0C1F8390>'
index: '2', key: 'closing', value: '<function closing at 0x0C1F83D8>'
index: '3', key: 'opening', value: '<function opening at 0x0C1F8420>'
index: '4', key: 'gradient', value: '<function morphological_gradient at 0x0C1F8468>'
index: '5', key: 'closing|opening', value: '<function closing_and_opening at 0x0C1F8348>'
index: '6', key: 'opening|closing', value: '<function opening_and_closing at 0x0C1F84B0>'
换句话说,字典的键标识要使用的形态操作,并且值是使用相应键时要调用的函数。 例如,如果要调用erode操作,则必须执行以下操作:
result = morphological_operations['erode'](image, kernel_type, kernel_size)
在前面的代码image,kernel_type和kernel_size是erode函数的参数(实际上,它们是字典中所有函数的参数)。
apply_morphological_operation()函数将字典中定义的所有形态运算应用于图像数组。 最后,调用show_images()函数,在其中绘制数组中包含的所有图像。 具体的实现细节可以在morphological_operations.py脚本的源代码中找到,该脚本包含大量注释。
该脚本绘制了四个图形,其中测试了不同的核类型和大小。 例如,在以下屏幕截图中,当使用(3, 3)的核大小和矩形核(cv2.MORPH_RECT)时,您可以看到输出:

如您在前面的屏幕快照中所见,在对图像进行预处理时,形态学运算是一种有用的技术,因为您可以消除一些噪声,这些噪声会干扰图像的正确处理。 另外,形态学操作也可以用于处理图像结构中的缺陷。
色彩空间
在本节中,将介绍流行的色彩空间的基础知识。 这些颜色空间是-RGB,CIELab,HSL 和 HSV 以及 YCbCr。
OpenCV 提供了 150 多种颜色空间转换方法来执行用户所需的转换。 在以下示例中,从加载到 RGB(OpenCV 中的 BGR)的图像到其他颜色空间(例如,HSV,HLS 或 YCbCr)执行转换。
显示色彩空间
RGB 颜色空间是加法颜色空间,其中特定颜色由红色,绿色和蓝色值表示。 人类视觉的工作方式相似,因此此色彩空间是显示计算机图形的合适方式。
CIELAB 颜色空间(也称为 CIELab 或简称为 LAB)代表一种特定的颜色,作为三个数值,其中L表示亮度,a代表绿色-红色分量,b代表蓝黄色分量。 在某些图像处理算法中也使用此色彩空间。
色相,饱和度,亮度(HSL)和色相,饱和度,值(HSV)是两个色彩空间,其中只有一个通道 (H)用于描述颜色,使其非常直观地指定颜色。 在这些颜色模型中,当应用图像处理技术时,亮度分量的分离具有一些优势。
YCbCr 是在视频和数字摄影系统中使用的一系列色彩空间,以色度分量(Y)和两个色度分量/色度(Cb 和 Cr)表示颜色。 基于从 YCbCr 图像派生的颜色模型,此颜色空间在图像分割中非常受欢迎。
在color_spaces.py脚本中,图像被加载到 BGR 颜色空间中并转换为上述颜色空间。 在此脚本中,关键函数是cv2.cvtColor(),它可以将一种颜色空间的输入图像转换为另一种颜色空间。
在与 RGB 颜色空间之间进行转换的情况下,应明确指定通道的顺序(BGR 或 RGB)。 例如:
image = cv2.imread('color_spaces.png')
该图像被加载到 BGR 颜色空间中。 因此,如果我们要将其转换为 HSV 颜色空间,则必须执行以下操作:
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
注意,我们使用了cv2.COLOR_BGR2HSV而不是cv2.COLOR_RGB2HSV。
该脚本的完整代码可以在color_space.py中看到。 在以下屏幕截图中可以看到输出:

如前面的屏幕快照所示,BGR 图像被转换为HSV,HLS,YCrCb 和 Lab 颜色空间。 还显示了每个颜色空间的所有组件(通道)。
不同颜色空间中的皮肤分割
前述色彩空间可用于不同的图像处理任务和技术。 例如,skin_segmentation.py脚本实现了不同的算法,以在不同的颜色空间(YCrCb,HSV 和 RGB)中执行皮肤分割工作。 该脚本还加载了一些测试图像,以查看这些算法如何工作。
该脚本中的关键函数是cv2.cvtColor()(我们已经提到过)和cv2.inRange(),它检查一个数组中包含的元素是否位于其他两个数组的元素之间(下边界数组和上边界数组) )。
因此,我们使用cv2.inRange()函数分割与皮肤对应的颜色。 如您所见,为这两个数组(上下边界)定义的值在分割算法的表现中起着至关重要的作用。 以此方式,已经进行了广泛的调查以正确设置它们。 在此示例中,这些值是从以下研究论文中获得的:
RGB-H-CbCr Skin Color Model for Human Face Detection by Nusirwan Anwar, Abdul Rahman, K. C. Wei, and John See
Skin segmentation algorithm based on the YCrCb color space by Shruti D Patravali, Jyoti Waykule, and Apurva Katre
Face Segmentation Using Skin-Color Map in Videophone Applications by D. Chai and K.N. Ngan
skin_detectors词典已构建为将所有皮肤分割算法应用于测试图像。 如果我们打印它,输出将如下所示:
index: '0', key: 'ycrcb', value: '<function skin_detector_ycrcb at 0x07B8C030>'
index: '1', key: 'hsv', value: '<function skin_detector_hsv at 0x07B8C0C0>'
index: '2', key: 'hsv_2', value: '<function skin_detector_hsv_2 at 0x07B8C108>'
index: '3', key: 'bgr', value: '<function skin_detector_bgr at 0x07B8C1E0>'
您可以看到定义了四个皮肤检测器。 为了调用皮肤分割检测器(例如skin_detector_ycrcb),必须执行以下操作:
detected_skin = skin_detectors['ycrcb'](image)
脚本的输出可以在以下屏幕截图中看到:

您可以通过使用多个测试图像来查看应用不同的皮肤分割算法的效果,以了解这些算法在不同条件下的工作方式。
颜色图
在许多计算机视觉应用中,算法的输出是灰度图像。 但是,人眼不善于观察灰度图像的变化。 当意识到彩色图像的变化时,它们更加敏感,因此一种常见的方法是将灰度图像转换(重新着色)为伪彩色等效图像。
OpenCV 中的颜色图
为了执行此转换,OpenCV 具有多个颜色图以增强可视化。 cv2.applyColorMap()函数在给定图像上应用颜色图。 color_map_example.py脚本加载灰度图像并应用cv2.COLORMAP_HSV色彩映射,如以下代码所示:
img_COLORMAP_HSV = cv2.applyColorMap(gray_img, cv2.COLORMAP_HSV)
最后,我们将所有颜色图应用于同一灰度图像,并在同一图中绘制它们。 可以在color_map_all.py脚本中看到。 OpenCV 定义的颜色图如下所示:
COLORMAP_AUTUMN = 0COLORMAP_BONE = 1COLORMAP_JET = 2COLORMAP_WINTER = 3COLORMAP_RAINBOW = 4COLORMAP_OCEAN = 5COLORMAP_SUMMER = 6COLORMAP_SPRING = 7COLORMAP_COOL = 8COLORMAP_HSV = 9COLORMAP_HOT = 11COLORMAP_PINK = 10COLORMAP_PARULA = 12
color_map_all.py脚本将所有这些颜色映射应用于灰度图像。 在以下屏幕截图中可以看到此脚本的输出:
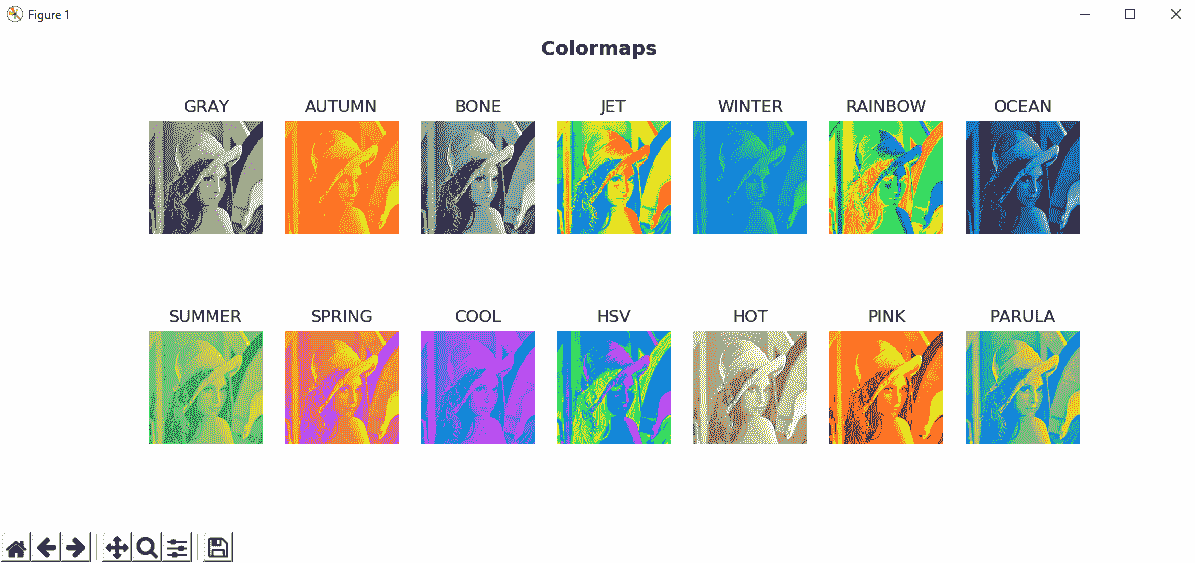
在上一个屏幕截图中,您可以看到将所有预定义的颜色图应用于灰度图像以增强可视化效果的效果。
自定义颜色图
您还可以将自定义颜色映射应用于图像。 此功能可以通过几种方式实现。
第一种方法是定义一个将0到255灰度值映射到 256 种颜色的颜色图。 这可以通过创建大小为256 x 1的 8 位彩色图像来完成,以存储所有创建的颜色。 之后,您可以通过查找表将图像的灰度强度映射为定义的颜色。 为此,您可以执行以下操作之一:
- 利用
cv2.LUT()函数 - 将图像的灰度强度映射为定义的颜色,以便可以使用
cv2.applyColorMap()
一个关键点是在创建大小为256 x 1的 8 位彩色图像时存储所创建的颜色。 如果要使用cv2.LUT(),则应按以下方式创建图像:
lut = np.zeros((256, 3), dtype=np.uint8)
如果要使用cv2.cv2.applyColorMap(),则应如下所示:
lut = np.zeros((256, 1, 3), dtype=np.uint8)
完整的代码可以在color_map_custom_values.py中看到。 在以下屏幕截图中可以看到此脚本的输出:

定义颜色图的第二种方法是只提供一些关键色,然后内插这些值,以便获得所有必要的颜色来建立查找表。 color_map_custom_key_colors.py脚本显示了如何实现此目的。
build_lut()函数基于这些关键色构建查找表。 基于五个色点,此函数调用np.linespace()以获取在该间隔内计算出的所有 64 种均匀分布的颜色,每种颜色由两个色点定义。 为了更好地理解这一点,请看以下屏幕截图:
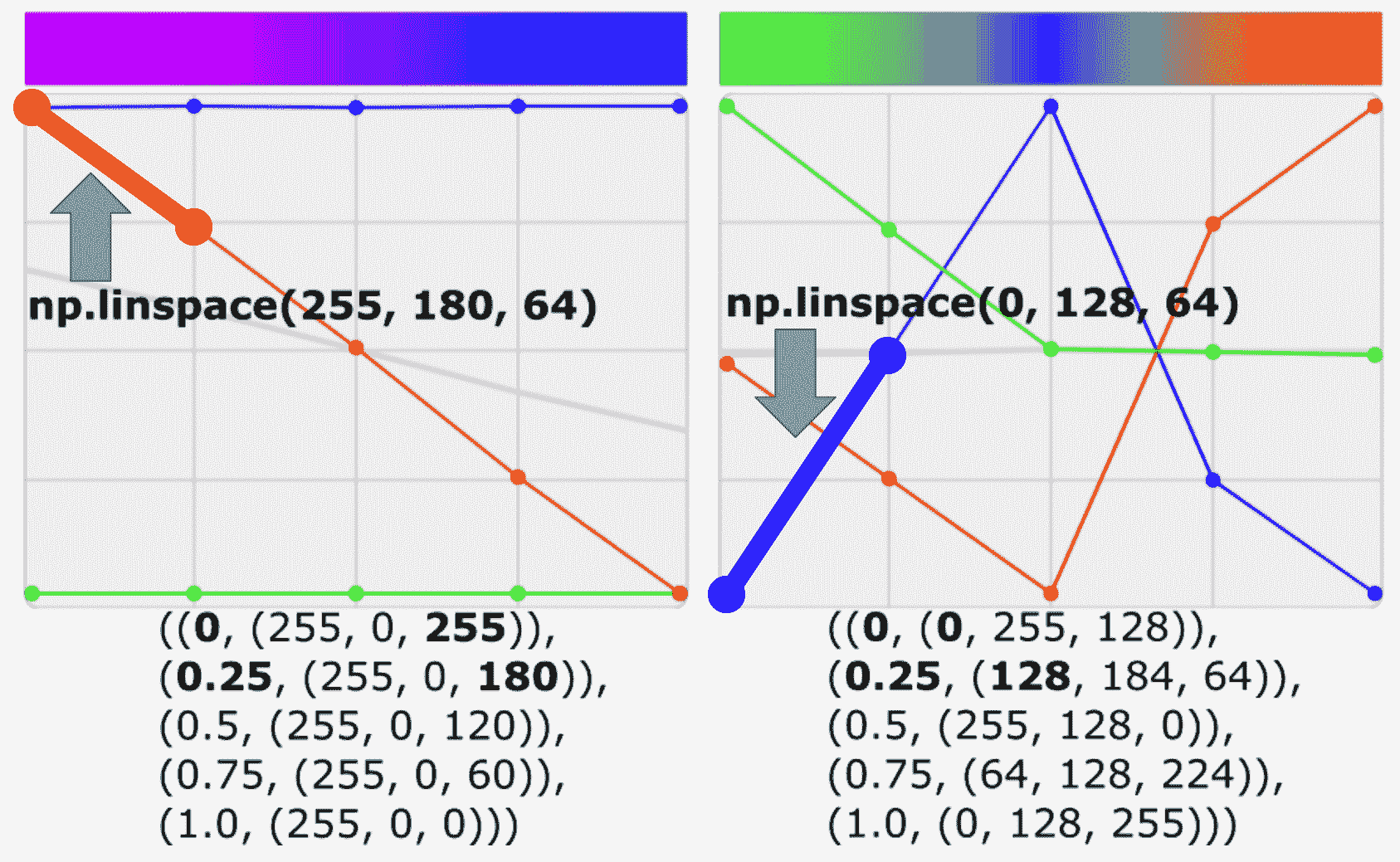
在此屏幕截图中,您可以查看例如如何计算两个线段的所有64等距颜色(请参见绿色和蓝色突出显示的线段)。
最后,为了构建以下五个关键色点((0, (0, 255, 128)),(0.25, (128, 184, 64)),(0.5, (255, 128, 0)),(0.75, (64, 128, 224))和(1.0, (0, 128, 255)))的查找表,对np.linespace()进行了以下调用:
blue : np.linspace('0', '128', '64' - '0' = '64')
green : np.linspace('255', '184', '64' - '0' = '64')
red : np.linspace('128', '64', '64' - '0' = '64')
blue : np.linspace('128', '255', '128' - '64' = '64')
green : np.linspace('184', '128', '128' - '64' = '64')
red : np.linspace('64', '0', '128' - '64' = '64')
blue : np.linspace('255', '64', '192' - '128' = '64')
green : np.linspace('128', '128', '192' - '128' = '64')
red : np.linspace('0', '224', '192' - '128' = '64')
blue : np.linspace('64', '0', '256' - '192' = '64')
green : np.linspace('128', '128', '256' - '192' = '64')
red : np.linspace('224', '255', '256' - '192' = '64')
下一个屏幕截图中可以看到color_map_custom_key_colors.py脚本的输出:
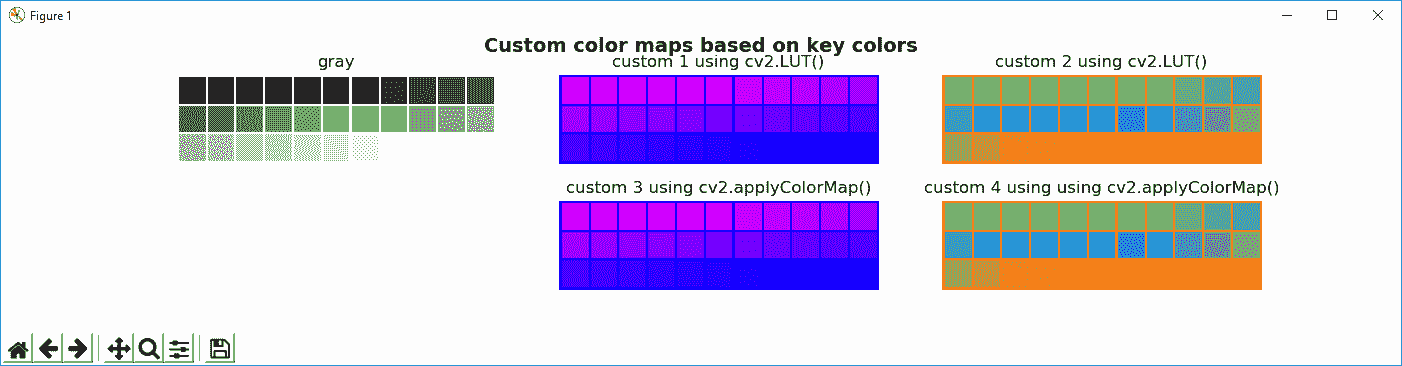
在上一个屏幕截图中,您可以看到将两个自定义颜色图应用于灰度图像的效果。
显示自定义颜色图的图例
最后,一种有趣的功能是在显示自定义颜色图时提供图例。 这可以通过color_map_custom_legend.py脚本来实现。
为了构建图例图像,build_lut_image()函数执行此功能。 我们首先调用build_lut()函数以获得查询表。 然后,我们调用np.repeat(),以便多次复制此查找表(此操作重复height次)。 请注意,查询表的形状为(256, 3)。 我们希望输出图像的形状为height,256 和 3,因此可以将np.repeat()与np.newaxis()结合使用,如下所示:
image = np.repeat(lut[np.newaxis, ...], height, axis=0)
在以下屏幕截图中可以看到此脚本的输出:

在前面的屏幕截图中,您可以看到将两个自定义颜色图应用于灰度图像并显示每个颜色图的图例的效果。
总结
在本章中,我们回顾了计算机视觉项目中所需的大多数常见图像处理技术。 在接下来的三章中(第 6 章,“构造和构建直方图”,第 7 章,“阈值处理技术”,和第 8 章,“轮廓检测,滤波和绘图”),将对最常见的图像处理技术进行回顾。
在第 6 章,“构造和构建直方图”中,您将学习如何创建和理解直方图,这是一种强大的技术,可用于更好地理解图像内容。
问题
- 哪个函数可将多通道分割成几个单通道图像?
- 哪个函数可以将几个单通道图像合并为一个多通道图像?
- 在
x方向上平移图像 150 像素,在y方向上平移图像 300。 - 以
1的比例因子将名为img的图像相对于图像中心旋转30度。 - 构建
5 x 5平均核,然后使用cv2.filter2D()将其应用于图像。 - 将
40添加到灰度图像中的所有像素。 - 将
COLORMAP_JET颜色图应用于灰度图像。
进一步阅读
以下参考将帮助您更深入地了解 OpenCV 中的图像处理技术:
六、构造和建立直方图
直方图是一种强大的技术,可用于更好地理解图像内容。 例如,许多摄像机实时显示正在捕获的场景的直方图,以便调整摄像机采集的某些参数(例如,曝光时间,亮度或对比度),目的是捕获合适的图像并帮助检测图像获取问题。
在本章中,您将看到如何创建和理解直方图。
本章将讨论有关直方图的主要概念,并将涵盖以下主题:
- 直方图的理论介绍
- 灰度直方图
- 颜色直方图
- 直方图的自定义可视化
- 比较 OpenCV,NumPy 和 Matplotlib 直方图
- 直方图均衡
- 自适应直方图均衡
- 比较 CLAHE 和直方图均衡
- 直方图比较
技术要求
技术要求如下:
- Python 和 OpenCV
- 特定于 Python 的 IDE
- NumPy 和 Matplotlib 包
- Git 客户端
有关如何安装这些要求的更多详细信息,请参见第 1 章,“设置 OpenCV”。 可以通过以下 URL 访问《精通 Python OpenCV 4》的 GitHub 存储库,其中包含从本书第一章到最后一章的所有必要的支持项目文件。
直方图的理论介绍
图像直方图是一种直方图,可反映图像的色调分布,并绘制每个色调值的像素数。 每个色调值的像素数也称为频率。 因此,强度值在[0, K-1]范围内的灰度图像的直方图将准确包含K条目。 例如,在 8 位灰度图像的情况下,K = 256(2^8 = 256),因此,强度值在[0, 255]的范围内。 直方图的每个条目定义如下:

例如, h(80)为强度为 80 的像素数。
在下一个屏幕截图中,您可以看到图像(左)具有7不同的灰度级。 灰度等级为:30,60,90,120,150,180和210。 直方图(右)显示每个色调值出现在图像中的次数(频率)。 在这种情况下,由于每个区域的大小为50 x 50像素(2,500 像素),因此上述灰度值的频率将为 2,500,否则为0:
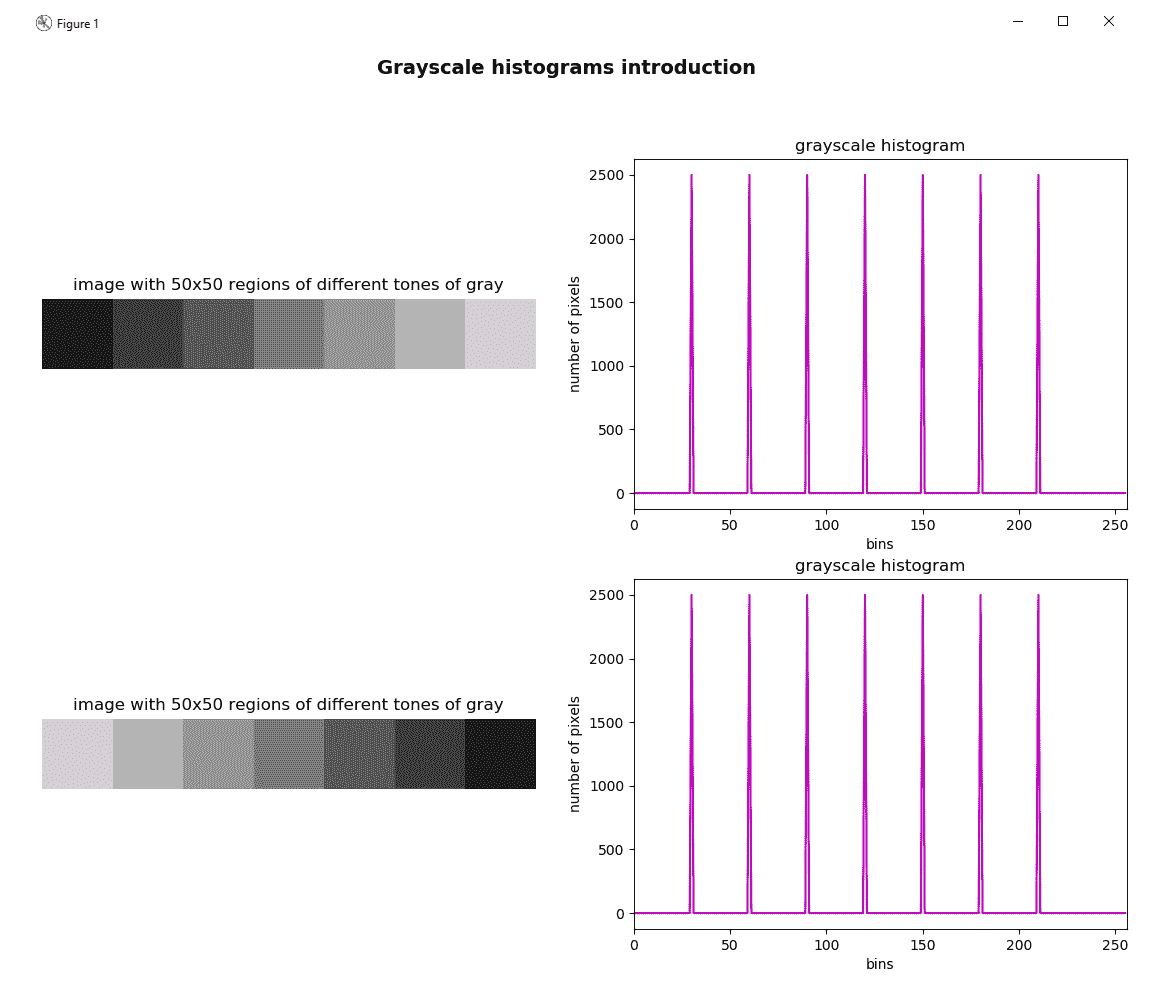
请注意,直方图仅显示统计信息,而不显示像素的位置。 这就是两个图像的直方图完全相同的原因。
histogram_introduction.py脚本如前所示绘制图形。 在此脚本中,build_sample_image()函数使用 NumPy 操作构建第一张图像(上),build_sample_image_2()函数构建第二张图像(下)。 接下来提供build_sample_image()的代码:
def build_sample_image():
"""Builds a sample image with 50x50 regions of different tones of gray"""
# Define the different tones. In this case: 60, 90, 120, ..., 210
# The end of interval (240) is not included
tones = np.arange(start=60, stop=240, step=30)
# Initialize result withe the first 50x50 region with 30-intensity level
result = np.ones((50, 50, 3), dtype="uint8") * 30
# Build the image concatenating horizontally the regions:
for tone in tones:
img = np.ones((50, 50, 3), dtype="uint8") * tone
result = np.concatenate((result, img), axis=1)
return result
在这里,请注意build_sample_image2()的代码:
def build_sample_image_2():
"""Builds a sample image with 50x50 regions of different tones of gray
flipping the output of build_sample_image()
"""
# Flip the image in the left/right direction:
img = np.fliplr(build_sample_image())
return img
下面简要描述了用于构建这些图像(np.ones(),np.arange(),np.concatenate()和np.fliplr())的 NumPy 操作:
np.ones():返回给定形状和类型的数组,并填充1的值。 在这种情况下,形状为(50, 50, 3)和dtype="uint8"。np.arange():考虑到提供的步骤,返回给定间隔内的均匀间隔的值。 不包括间隔的结尾(在这种情况下为240)。np.concatenate():沿着现有轴连接一系列数组; 在这种情况下,axis=1可以水平连接图像。np.fliplr():沿左右方向翻转数组。
下一节将介绍计算和显示直方图的功能。
直方图术语
在深入了解直方图以及如何通过使用与直方图相关的 OpenCV(以及 NumPy 和 Matplotlib)功能构建和可视化直方图之前,我们需要了解一些与直方图有关的术语:
bins:上一个屏幕截图中的直方图显示了每个色调值的像素数(频率),范围从0到255。 这些256值的每个在直方图术语中称为箱子。 可以根据需要选择bins的数量。 常用值为8,16,32,64,128和256。 OpenCV 使用histSize来引用bins。range:这是我们要测量的强度值的范围。 通常,它是[0,255],对应于所有色调值(0对应于黑色,255对应于白色)。
灰度直方图
OpenCV 提供cv2.calcHist()函数以便计算一个或多个数组的直方图。 因此,该函数可以应用于单通道图像(例如灰度图像)和多通道图像(例如 BGR 图像)。
在本节中,我们将看到如何计算灰度图像的直方图。 该函数的签名如下:
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
为此,适用以下条件:
images:它表示作为列表提供的uint8或float32类型的源图像(例如[gray_img])。channels:它代表我们计算其列表的直方图的通道索引(例如,对于灰度图像,[0];对于多通道图像,[0],[1],[2]分别计算第一,第二或第三通道的直方图)。mask:它代表一个遮罩图像,用于计算由遮罩定义的图像特定区域的直方图。 如果此参数等于None,则将在没有遮罩的情况下计算直方图,并且将使用完整图像。histSize:表示作为列表提供的bins的数量(例如[256])。ranges:它表示我们要测量的强度值的范围(例如[0,256])。
没有遮罩的灰度直方图
因此,用于计算完整灰度图像(不带遮罩)的直方图的代码如下:
image = cv2.imread('lenna.png')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
hist = cv2.calcHist([gray_image], [0], None, [256], [0, 256])
在这种情况下,hist是一个(256, 1)数组。 数组的每个值(仓)对应于具有相应色调值的像素数(频率)。
要使用 Matplotlib 绘制直方图,可以使用plt.plot(),提供直方图和颜色以显示直方图(例如color='m')。 支持以下颜色缩写-'b'-蓝色,'g'-绿色,‘r’-红色,'c'-青色,'m'-品红色,'y'-黄色,'k'-黑色和 'w'-白色。 该示例的完整代码可以在grayscale_histogram.py脚本中看到。
我们在引言中评论了直方图可用于揭示或检测图像采集问题。 以下示例将向您展示如何检测图像亮度问题。 灰度图像的亮度可以定义为以下公式给出的图像所有像素的平均强度:
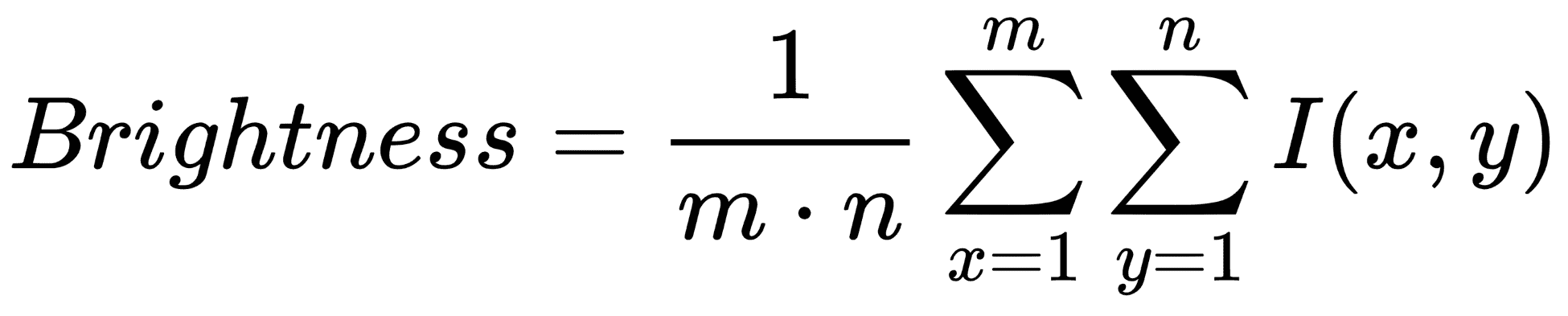
在此,I(x, y)是图像特定像素的色调值。
因此,如果图像的平均色调较高(例如220),则意味着图像的大多数像素将非常接近白色。 相反,如果图像上的平均色调较低(例如30),则意味着图像的大多数像素将非常接近黑色。
在上述脚本grayscale_histogram.py中,我们将看到如何更改图像的亮度以及直方图如何更改。
在此脚本中(为了介绍如何计算灰度图像的直方图并进行显示)已经引入了该脚本,我们还对加载灰度图像进行了一些基本数学运算。 具体来说,我们已经执行了图像加法和减法运算,以便向图像的每个像素的灰度级强度中添加特定的量或从中减去特定的量。 这可以通过cv2.add()和cv2.subtract()函数执行。
在第 5 章,“图像处理技术”中,我们介绍了如何对图像执行算术运算。 因此,如果您对此有任何疑问,可以阅读上一章。
这样,可以改变图像的平均亮度水平。 可以在下一个屏幕截图中看到,与脚本的输出相对应:

在此特定情况下,我们在原始图像的每个像素中添加/减去了35,然后计算了所得图像的直方图:
# Add 35 to every pixel on the grayscale image (the result will look lighter) and calculate histogram
M = np.ones(gray_image.shape, dtype="uint8") * 35
added_image = cv2.add(gray_image, M)
hist_added_image = cv2.calcHist([added_image], [0], None, [256], [0, 256])
# Subtract 35 from every pixel (the result will look darker) and calculate histogram
subtracted_image = cv2.subtract(gray_image, M)
hist_subtracted_image = cv2.calcHist([subtracted_image], [0], None, [256], [0, 256])
如您所见,中央灰度图像对应于将35添加到原始图像的每个像素的图像,从而使图像更亮。 在此图像中,在没有强度在[0-35]范围内的像素的意义上,直方图似乎向右移动。 相反,右侧的灰度图像与从原始图像的每个像素中减去35的图像相对应,从而产生较暗的图像。 在没有强度在[220-255]范围内的像素的意义上,直方图似乎向左移动。
带遮罩的灰度直方图
要了解如何应用遮罩,请参见grayscale_histogram_mask.py脚本,其中会创建一个遮罩,并使用先前创建的遮罩来计算直方图。 为了创建遮罩,以下行是必需的:
mask = np.zeros(gray_image.shape[:2], np.uint8)
mask[30:190, 30:190] = 255
因此,遮罩由尺寸与加载的图像相同的黑色图像组成,而白色的图像对应于我们要计算直方图的区域。
然后,通过创建的掩码调用cv2.calcHist()函数:
hist_mask = cv2.calcHist([gray_image], [0], mask, [256], [0, 256])
在以下屏幕截图中可以看到此脚本的输出:
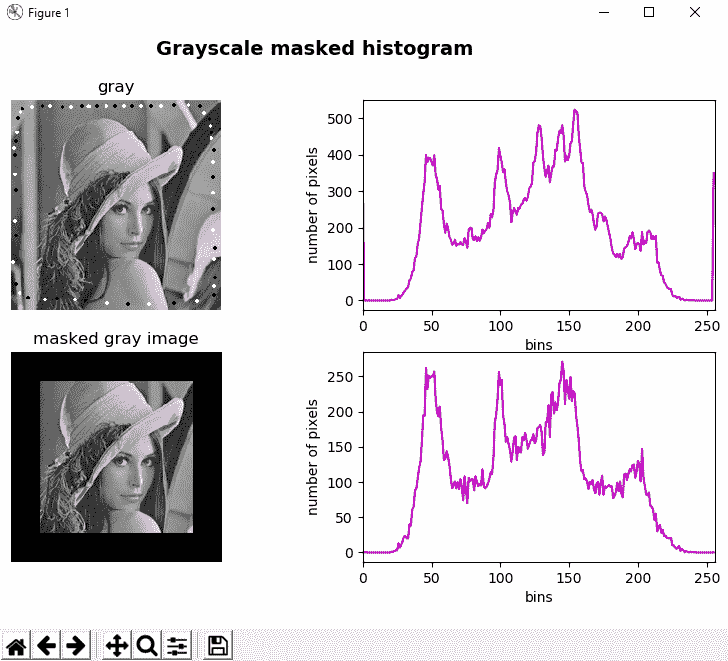
如您所见,我们已经修改了图像,以分别添加一些具有0和255灰度强度的黑色和白色小圆圈(换句话说,黑色和白色圆圈)。 这可以在第一个直方图中看到,它在bins = 0和255中有两个选择。 但是,这些选择不会出现在遮罩图像的最终直方图中,因为在计算直方图时并未考虑它们,因为已应用了遮罩。
颜色直方图
在本节中,我们将看到如何计算颜色直方图。 执行此功能的脚本为color_histogram.py。 在多通道图像(例如,BGR 图像)的情况下,计算颜色直方图的过程包括计算每个通道中的直方图。 在这种情况下,我们创建了一个从三通道图像计算直方图的函数:
def hist_color_img(img):
"""Calculates the histogram from a three-channel image"""
histr = []
histr.append(cv2.calcHist([img], [0], None, [256], [0, 256]))
histr.append(cv2.calcHist([img], [1], None, [256], [0, 256]))
histr.append(cv2.calcHist([img], [2], None, [256], [0, 256]))
return histr
应当注意,我们可能已经创建了for循环或类似的方法,以便三次调用cv2.calcHist()函数。 但是,为简单起见,我们执行了三个调用,分别明确指示了不同的通道。 在这种情况下,当我们加载 BGR 图片时,调用如下:
- 计算蓝色通道的直方图:
cv2.calcHist([img], [0], None, [256], [0, 256]) - 计算绿色通道的直方图:
cv2.calcHist([img], [1], None, [256], [0, 256]) - 计算红色通道的直方图:
cv2.calcHist([img], [1], None, [256], [0, 256])
因此,为了计算图像的颜色直方图,请注意以下几点:
image = cv2.imread('lenna.png')
hist_color = hist_color_img(image)
在此脚本中,我们还使用了cv2.add()和cv2.subtract()来修改加载的 BGR 图像的亮度,并观察直方图的变化。 在这种情况下,15已添加/减去到原始 BGR 图像的每个像素。 在与color_histogram.py脚本输出相对应的下一个屏幕截图中可以看到:
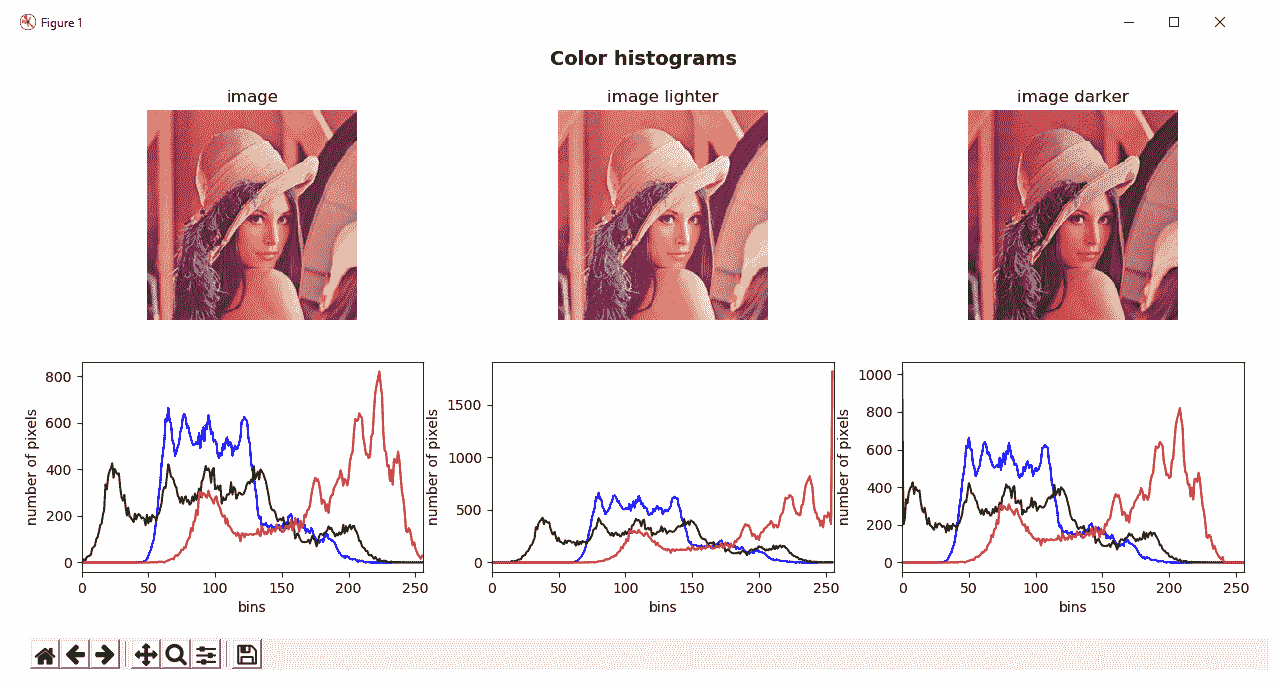
直方图的自定义可视化
为了可视化直方图,我们使用了plt.plot()函数。 如果我们只想使用 OpenCV 功能来可视化直方图,则没有 OpenCV 函数可以绘制直方图。 在这种情况下,我们必须利用 OpenCV 原语(例如cv2.polylines()和cv2.rectangle()等)来创建一些(基本)绘制直方图的函数。 在histogram_custom_visualization.py脚本中,我们创建了plot_hist()函数,该函数执行此功能。 此函数创建 BGR 彩色图像,并在其中绘制直方图。 该函数的代码如下:
def plot_hist(hist_items, color):
"""Plots the histogram of a image"""
# For visualization purposes we add some offset:
offset_down = 10
offset_up = 10
# This will be used for creating the points to visualize (x-coordinates):
x_values = np.arange(256).reshape(256, 1)
canvas = np.ones((300, 256, 3), dtype="uint8") * 255
for hist_item, col in zip(hist_items, color):
# Normalize in the range for proper visualization:
cv2.normalize(hist_item, hist_item, 0 + offset_down, 300 - offset_up, cv2.NORM_MINMAX)
# Round the normalized values of the histogram:
around = np.around(hist_item)
# Cast the values to int:
hist = np.int32(around)
# Create the points using the histogram and the x-coordinates:
pts = np.column_stack((x_values, hist))
# Draw the points:
cv2.polylines(canvas, [pts], False, col, 2)
# Draw a rectangle:
cv2.rectangle(canvas, (0, 0), (255, 298), (0, 0, 0), 1)
# Flip the image in the up/down direction:
res = np.flipud(canvas)
return res
此函数接收直方图,并为直方图的每个元素建立(x, y)点,pts点,其中y值表示x元素的频率。 直方图的这些点pts是使用cv2.polylines()函数绘制的,我们已经在第 4 章,“在 OpenCV 中构造基本形状”。 此函数基于pts数组绘制多边形曲线。 最后,由于y值上下颠倒,因此图像垂直翻转。 在下一个屏幕截图中,我们可以使用plt.plot()和我们的自定义函数比较可视化效果:

比较 OpenCV,NumPy 和 Matplotlib 直方图
我们已经看到 OpenCV 提供了cv2.calcHist()函数来计算直方图。 此外,NumPy 和 Matplotlib 为创建直方图提供了类似的函数。 在comparing_opencv_numpy_mpl_hist.py脚本中,我们出于性能目的比较这些函数。 从这个意义上讲,我们将看到如何使用 OpenCV,NumPy 和 Matplotlib 创建直方图,然后测量每个图形的执行时间并将结果绘制在图中。
为了测量执行时间,我们使用timeit.default_timer,因为它会自动在您的平台和 Python 版本上提供最佳时钟。 这样,我们将其导入脚本的开头:
from timeit import default_timer as timer
这里总结了我们使用计时器的方式:
start = timer()
# ...
end = timer()
execution_time = start - end
应当考虑到default_timer()测量可能会受到同一台计算机上同时运行的其他程序的影响。 因此,执行准确计时的最佳方法是重复几次并花费最佳时间。
为了计算直方图,我们将使用以下函数:
cv2.calcHist()由 OpenCV 提供np.histogram()由 NumPy 提供- Matplotlib 提供的
plt.hist()
因此,用于计算上述每个函数执行的代码如下:
start = timer()
# Calculate the histogram calling cv2.calcHist()
hist = cv2.calcHist([gray_image], [0], None, [256], [0, 256])
end = timer()
exec_time_calc_hist = (end - start) * 1000
start = timer()
# Calculate the histogram calling np.histogram():
hist_np, bins_np = np.histogram(gray_image.ravel(), 256, [0, 256])
end = timer()
exec_time_np_hist = (end - start) * 1000
start = timer()
# Calculate the histogram calling plt.hist():
(n, bins, patches) = plt.hist(gray_image.ravel(), 256, [0, 256])
end = timer()
exec_time_plt_hist = (end - start) * 1000
我们将值乘以得到毫秒(而不是秒)。 在以下屏幕截图中可以看到comparing_opencv_numpy_mpl_hist.py脚本的输出:

可以看出,cv2.calcHist()比np.histogram()和plt.hist()都快。 因此,出于性能目的,您可以使用 OpenCV 函数。
直方图均衡
在本节中,我们将看到如何使用 OpenCV 函数cv2.equalizeHist()执行直方图均衡,以及如何将其应用于灰度图像和彩色图像。 cv2.equalizeHist()函数可标准化亮度,并增加图像的对比度。 因此,在应用此函数后会修改图像的直方图。 在接下来的小节中,我们将探索原始直方图和修改后的直方图,以查看其变化方式。
灰度直方图均衡
使用cv2.equalizeHist()函数以均衡给定灰度图像的对比度非常容易:
image = cv2.imread('lenna.png')
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray_image_eq = cv2.equalizeHist(gray_image)
在grayscale_histogram_equalization.py脚本中,我们将直方图均衡化应用于三个图像。 第一个是原始灰度图像。 第二个是原始图像,但是在我们已经向图像的每个像素添加35的意义上进行了修改。 第三个是原始图像,但是在我们已经从图像的每个像素中减去35的意义上进行了修改。 我们还计算了直方图均衡之前和之后的直方图。 最后,绘制所有这些图像。 在以下屏幕截图中可以看到此脚本的输出:
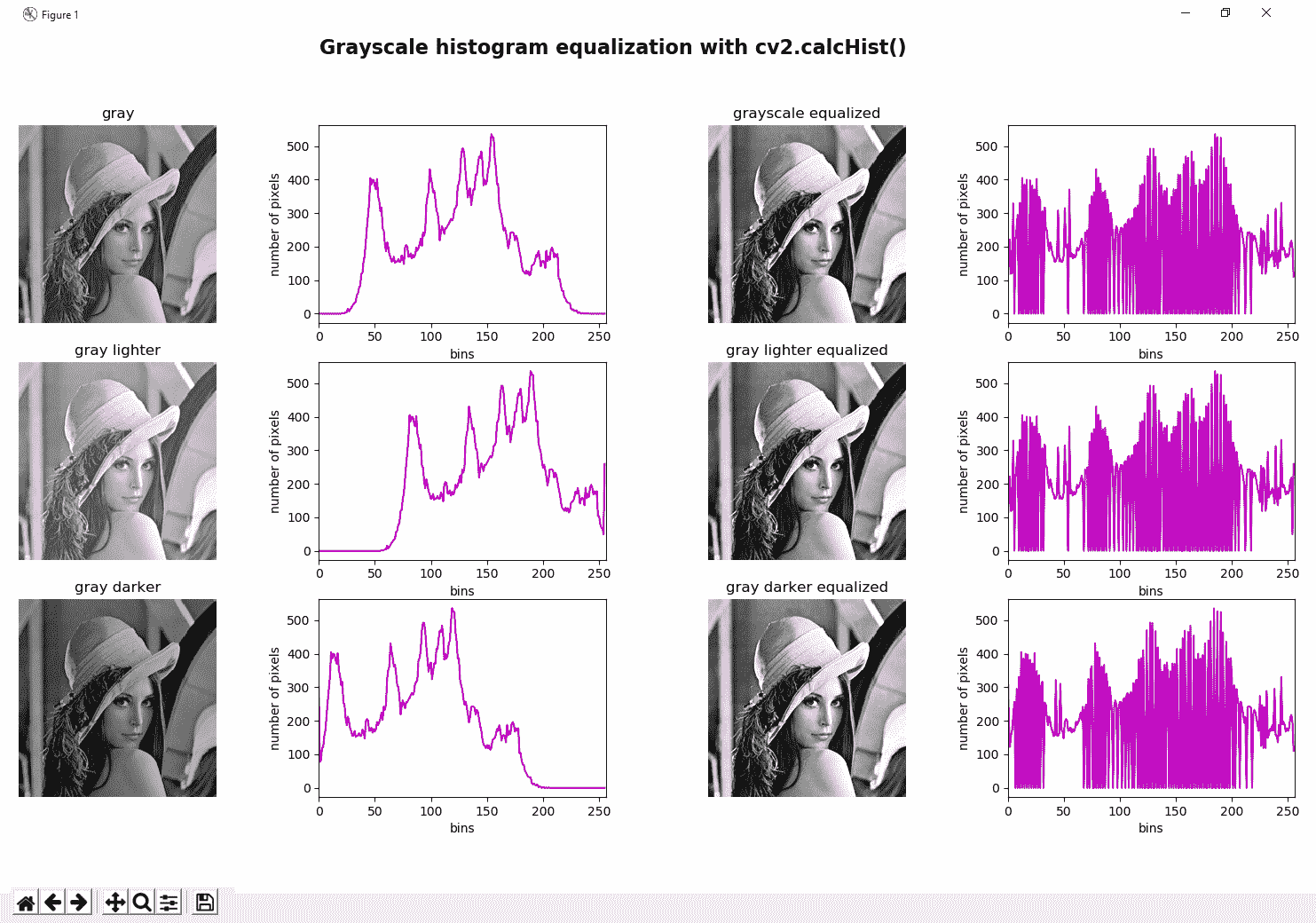
在上一个屏幕截图中,我们可以看到三个均衡图像确实非常相似,并且这一事实也可以反映在均衡直方图中,其中所有三个图像也非常相似。 这是因为直方图均衡化趋向于标准化图像的亮度(并增加对比度)。
颜色直方图均衡
按照相同的方法,我们可以在彩色图像中执行直方图均衡化。 我们必须说这不是彩色图像中直方图均衡的最佳方法,我们将看到如何正确执行它。 因此,此第一个(以及不正确的)版本将直方图均衡化应用于 BGR 图像的每个通道。 在以下代码中可以看到这种方法:
def equalize_hist_color(img):
"""Equalize the image splitting the image applying cv2.equalizeHist() to each channel and merging the results"""
channels = cv2.split(img)
eq_channels = []
for ch in channels:
eq_channels.append(cv2.equalizeHist(ch))
eq_image = cv2.merge(eq_channels)
return eq_image
我们创建了equalize_hist_color()函数,该函数通过使用cv2.split()分割 BGR 图像并将cv2.equalizeHist()函数应用于每个通道。 最后,我们使用cv2.merge()合并所有结果通道。 我们已将此函数应用于三个不同的图像。 第一个是原始的 BGR 图片。 第二个是原始图像,但在某种意义上进行了修改,即我们已经向图像的每个像素添加了15。 第三个是原始图像,但在某种意义上进行了修改,即我们已经从图像的每个像素中减去了15。 我们还计算了直方图均衡之前和之后的直方图。
最后,绘制所有这些图像。 在以下屏幕截图中可以看到color_histogram_equalization.py脚本的输出:

我们评论说,均衡三个通道不是一个好方法,因为色调会发生巨大变化。 这是由于 BGR 颜色空间的累加特性。 由于我们分别更改三个通道的亮度和对比度,因此在合并均衡的通道时,这可能导致图像中出现新的阴影。 在上一个屏幕截图中可以看到此问题。
更好的方法是将 BGR 图像转换为包含亮度/强度通道(Yuv,Lab,HSV 和 HSL)的色彩空间。 然后,我们仅在亮度通道上应用直方图均衡化,最后执行逆变换,也就是说,我们合并通道并将它们转换回 BGR 颜色空间。
在color_histogram_equalization_hsv.py脚本中可以看到这种方法,其中equalize_hist_color_hsv()函数将执行以下功能:
def equalize_hist_color_hsv(img):
"""Equalize the image splitting the image after HSV conversion and applying cv2.equalizeHist()
to the V channel, merging the channels and convert back to the BGR color space
"""
H, S, V = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
eq_V = cv2.equalizeHist(V)
eq_image = cv2.cvtColor(cv2.merge([H, S, eq_V]), cv2.COLOR_HSV2BGR)
return eq_image
在以下屏幕截图中可以看到输出:
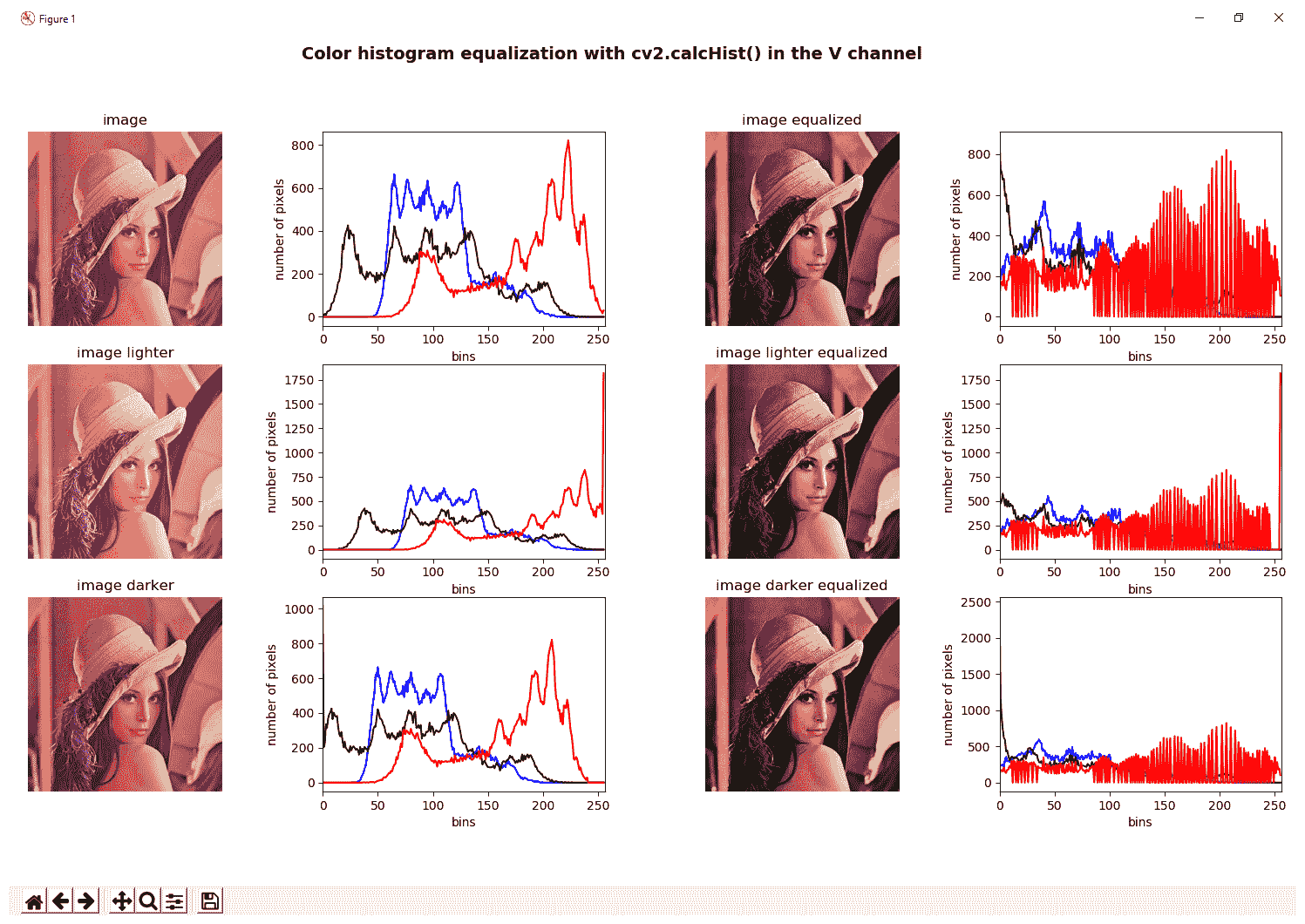
可以看出,仅对 HSV 图像的 V 通道进行均衡后获得的结果要比对 BGR 图像的所有通道进行均衡好得多。 正如我们所评论的,这种方法对于包含亮度/强度通道(Yuv,Lab,HSV 和 HSL)的色彩空间也是有效的。 这将在下一部分中看到。
对比度受限的自适应直方图均衡
在本节中,我们将了解如何应用对比度受限的自适应直方图均衡(CLAHE)来均衡图像,这是自适应直方图均衡的一种形式 (AHE),其中对比度放大受到限制。 图像的相对均匀区域中的噪声被 AHE 过度放大,而 CLAHE 通过限制对比度放大来解决此问题。 该算法可用于改善图像的对比度。 该算法通过创建原始图像的多个直方图来工作,并使用所有这些直方图重新分配图像的亮度。
在clahe_histogram_equalization.py脚本中,我们将 CLAHE 应用于灰度和彩色图像。 应用 CLAHE 时,有两个参数需要调整。 第一个是clipLimit,它设置对比度限制的阈值。 默认值为40。 第二个是tileGridSize,它设置行和列中瓦片的数量。 当应用 CLAHE 时,图像被分成称为瓦片的小块(默认为8 x 8)以执行其计算。
要将 CLAHE 应用于灰度图像,我们必须执行以下操作:
clahe = cv2.createCLAHE(clipLimit=2.0)
gray_image_clahe = clahe.apply(gray_image)
此外,我们还可以将 CLAHE 应用于彩色图像,这与上一节中介绍的彩色图像对比度均衡方法非常相似,其中仅均衡 HSV 图像的亮度通道后的结果要比均衡所有通道的结果好得多。 BGR 图片。
在本节中,我们将创建四个函数,以通过仅在不同颜色空间的亮度通道上使用 CLAHE 来均衡彩色图像:
def equalize_clahe_color_hsv(img):
"""Equalize the image splitting after conversion to HSV and applying CLAHE
to the V channel and merging the channels and convert back to BGR
"""
cla = cv2.createCLAHE(clipLimit=4.0)
H, S, V = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
eq_V = cla.apply(V)
eq_image = cv2.cvtColor(cv2.merge([H, S, eq_V]), cv2.COLOR_HSV2BGR)
return eq_image
def equalize_clahe_color_lab(img):
"""Equalize the image splitting after conversion to LAB and applying CLAHE
to the L channel and merging the channels and convert back to BGR
"""
cla = cv2.createCLAHE(clipLimit=4.0)
L, a, b = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2Lab))
eq_L = cla.apply(L)
eq_image = cv2.cvtColor(cv2.merge([eq_L, a, b]), cv2.COLOR_Lab2BGR)
return eq_image
def equalize_clahe_color_yuv(img):
"""Equalize the image splitting after conversion to YUV and applying CLAHE
to the Y channel and merging the channels and convert back to BGR
"""
cla = cv2.createCLAHE(clipLimit=4.0)
Y, U, V = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2YUV))
eq_Y = cla.apply(Y)
eq_image = cv2.cvtColor(cv2.merge([eq_Y, U, V]), cv2.COLOR_YUV2BGR)
return eq_image
def equalize_clahe_color(img):
"""Equalize the image splitting the image applying CLAHE to each channel and merging the results"""
cla = cv2.createCLAHE(clipLimit=4.0)
channels = cv2.split(img)
eq_channels = []
for ch in channels:
eq_channels.append(cla.apply(ch))
eq_image = cv2.merge(eq_channels)
return eq_image
下一个屏幕截图中可以看到此脚本的输出,在将所有这些函数应用于测试图像后,我们在其中比较了结果:

在上一个屏幕截图中,我们可以通过更改clipLimit参数在测试图像上应用 CLAHE 后看到结果。 此外,在不同颜色空间(LAB,HSV 和 YUV)的亮度通道上应用 CLAHE 之后,我们可以看到不同的结果。 最后,我们会看到在 BGR 图像的三个通道上应用 CLAHE 的错误方法。
比较 CLAHE 和直方图均衡
为了完整起见,在comparing_hist_equalization_clahe.py脚本中,您可以看到 CLAHE 和直方图均衡化(cv2.equalizeHist())如何在同一图像上工作,同时可视化结果图像和结果直方图。
在以下屏幕截图中可以看到:

可以肯定地说,与在许多情况下应用直方图均衡化相比,CLAHE 提供了更好的结果和性能。 从这个意义上讲,CLAHE 通常在许多计算机视觉应用(例如,面部处理等)中用作第一步。
直方图比较
OpenCV 提供的与直方图相关的一种有趣函数是cv2.compareHist()函数,该函数可用于获取一个数值参数,该数值参数表示两个直方图相互匹配的程度。 从这个意义上讲,由于直方图反映了图像中像素值的强度分布,因此该函数可用于比较图像。 如前所述,直方图仅显示统计信息,而不显示像素的位置。 因此,图像比较的常用方法是将图像划分为一定数量的区域(通常具有相同的大小),计算每个区域的直方图,最后将所有直方图连接起来以创建图像的特征表示 。 在此示例中,为简单起见,我们不会将图像划分为一定数量的区域,因此将仅使用一个区域(完整图像)。
cv2.compareHist()函数的签名如下:
cv2.compareHist(H1, H2, method)
这里,H1和H2是要比较的直方图,method建立了比较方法。
OpenCV 提供了四种不同的度量标准(方法)来计算匹配项:
cv2.HISTCMP_CORREL:此度量标准计算两个直方图之间的相关性。 此指标返回[-1, 1]范围内的值,其中1表示完美匹配,而-1完全不匹配。cv2.HISTCMP_CHISQR:此度量标准计算两个直方图之间的卡方距离。 此指标返回[0, unbounded]范围内的值,其中0表示完美匹配,而不匹配则不受限制。cv2.HISTCMP_INTERSECT:此度量标准计算两个直方图之间的交集。 如果直方图已归一化,则此度量标准将返回[0,1]范围内的值,其中1表示完美匹配,而0则完全不匹配。cv2.HISTCMP_BHATTACHARYYA:此度量标准计算两个直方图之间的 Bhattacharyya 距离。 此指标返回[0,1]范围内的值,其中0是完美匹配,而1完全不匹配。
在compare_histograms.py脚本中,我们首先加载四个图像,然后使用先前注释的所有度量标准来计算所有这些图像与测试图像之间的相似度。
我们使用的四个图像如下:
gray_image.png:此图像对应于灰度图像。gray_added_image.png:此图像对应于原始图像,但在某种意义上进行了修改,即我们已经向图像的每个像素添加了35。gray_subtracted_image.png:此图像对应于原始图像,但在某种意义上进行了修改,因为我们已经对图像的每个像素减去了35。gray_blurred.png:此图像对应于原始图像,但已使用模糊过滤器(cv2.blur(gray_image, (10, 10))进行了修改。
测试(或查询)图像也是gray_image.png。 在下一个屏幕截图中可以看到该示例的输出:

如您所见,由于img 1是同一张图片,因此可提供最佳结果(在所有度量标准中均完美匹配)。 此外,img 2还提供了非常好的表现指标。 这是有道理的,因为img 2是查询图像的平滑版本。 最后,img 3和img 4的表现指标不佳,因为直方图已移动。
总结
在本章中,已经回顾了与直方图有关的所有主要概念。 从这个意义上讲,我们已经了解了直方图的含义以及如何使用 OpenCV,NumPy 和 Matplotlib 函数计算直方图。 此外,我们已经看到了灰度直方图和颜色直方图之间的差异,展示了如何计算和显示这两种类型。 直方图均衡也是处理直方图时的重要因素,我们已经了解了如何对灰度图像和彩色图像执行直方图均衡。 最后,直方图比较对于执行图像比较也可能非常有帮助。 我们已经看到 OpenCV 提供的四个度量来度量两个直方图之间的相似性。
与下一章相关,将介绍与计算机视觉应用中作为图像分割的关键部分所需内容相关的主要阈值处理技术(简单阈值处理,自适应阈值处理和大津的阈值处理等)。
问题
- 什么是图像直方图?
- 使用
64箱计算灰度图像的直方图。 - 将
50添加到灰度图像上的每个像素(结果看起来更亮)并计算直方图。 - 计算没有遮罩的 BGR 图像的红色通道直方图。
- OpenCV,NumPy 和 Matplotlib 提供哪些函数来计算直方图?
- 修改
grayscale_histogram.py脚本以计算这三个图像(gray_image,added_image和subtracted_image)的亮度。 将脚本重命名为grayscale_histogram_brightness.py。 - 修改
comparing_hist_equalization_clahe.py脚本以显示cv2.equalizeHist()和 CLAHE 的执行时间。 将其重命名为comparing_hist_equalization_clahe_time.py。
进一步阅读
此处列出的参考将帮助您更深入地研究 OpenCV 中的图像处理技术:
七、分割技术
图像分割是许多计算机视觉应用中的关键过程。 它通常用于将图像划分为不同的区域,理想情况下,这些区域对应于从背景提取的现实世界对象。 因此,图像分割是图像识别和内容分析的重要步骤。 图像阈值化是一种简单但有效的图像分割方法,其中,根据像素的强度值对像素进行分割,因此,可以将其用于将图像分割为前景和背景。
在本章中,您将学习阈值技术在计算机视觉项目中的重要性。 我们将审查 OpenCV(以及 Scikit-image 图像处理库)提供的主要阈值技术,这些技术将在计算机视觉应用中用作图像分割的关键部分。
本章的主要部分如下:
- 阈值技术简介
- 简单阈值技术
- 自适应阈值技术
- 大津阈值算法
- 三角阈值算法
- 彩色图像的阈值
- 使用 scikit-image 的阈值算法
技术要求
技术要求如下:
- Python 和 OpenCV。
- 特定于 Python 的 IDE。
- NumPy 和 Matplotlib 包。
- scikit-image 图像处理库(对于本章的最后部分是可选的。请参阅 scikit-image 阈值算法以了解如何为基于 Conda 的发行版安装它)。 请参阅以下说明,以便使用
pip进行安装。 - 还需要 SciPy 库(对于本章的最后部分是可选的)。 请参阅以下说明,以便使用
pip进行安装。 - 一个 Git 客户端。
有关如何安装这些要求的更多详细信息,请参见第 1 章,“设置 OpenCV”。 可通过 github 访问《精通 Python OpenCV4》的 GitHub 存储库,其中包含从本书第一章到最后一章的所有必要的支持项目文件。。
安装 scikit-image
要安装 scikit-image,请使用以下命令:
$ pip install scikit-image
或者,您也可以为基于 Conda 的发行版安装 scikit-image,如使用该库的特定部分所述。
要检查安装是否正确执行,只需打开 Python shell 并尝试按以下方式导入scikit-image库:
python
import skimage
安装 SciPy
要安装 SciPy,请使用以下命令:
$ pip install scipy
要检查安装是否正确执行,只需打开 Python shell 并尝试按以下方式导入scipy库:
python
import scipy
请记住,推荐的方法是在虚拟环境中安装包。 请参阅第 1 章,“设置 OpenCV”,以了解如何创建和管理虚拟环境。
阈值技术简介
阈值是一种简单而有效的方法,可将图像划分为前景和背景。 图像分割的目的是将图像的表示形式修改为更易于处理的另一种表示形式。 例如,图像分割通常用于根据对象的某些属性(例如颜色,边缘或直方图)从背景中提取对象。 如果像素强度小于某个预定义常数(阈值),则最简单的阈值化方法将源图像中的每个像素替换为黑色像素;如果像素强度大于阈值,则将像素替换为白色像素。
OpenCV 提供cv2.threshold()函数以对图像进行阈值处理。 我们将在本章接下来的小节中详细介绍该函数。
在thresholding_introduction.py脚本中,我们将cv2.threshold()函数与一些预定义的阈值一起应用-0,50,100,150,200和250,以便查看对于不同的阈值图像如何变化。
例如,要使用thresh = 50的阈值对图像进行阈值处理,代码如下:
ret1, thresh1 = cv2.threshold(gray_image, 50, 255, cv2.THRESH_BINARY)
在此,thresh1是阈值图像,是黑白图像。 强度小于50的像素将为黑色,强度大于50的像素将为白色。
在下面的代码中可以看到另一个示例,其中thresh5对应于阈值图像:
ret5, thresh5 = cv2.threshold(gray_image, 200, 255, cv2.THRESH_BINARY)
在这种情况下,强度小于200的像素将为黑色,强度大于200的像素将为白色。
在以下屏幕截图中可以看到上述脚本的输出:

在此屏幕截图中,您可以看到源图像,它是一个示例图像,其中一些大小相同的区域填充了不同的灰色调。 更具体地,这些灰色色调是0,50,100,150,200和250。 build_sample_image()函数按以下方式构建此样本图像:
def build_sample_image():
"""Builds a sample image with 50x50 regions of different tones of gray"""
# Define the different tones.
# The end of interval is not included
tones = np.arange(start=50, stop=300, step=50)
# print(tones)
# Initialize result with the first 50x50 region with 0-intensity level
result = np.zeros((50, 50, 3), dtype="uint8")
# Build the image concatenating horizontally the regions:
for tone in tones:
img = np.ones((50, 50, 3), dtype="uint8") * tone
result = np.concatenate((result, img), axis=1)
return result
简要描述了用于构建此示例图像的 NumPy 操作(np.ones(),np.zeros(),np.arange(),np.concatenate()和np.fliplr()):
np.ones():这将返回给定形状和类型的数组,并填充为 1; 在这种情况下,形状为(50, 50, 3)和dtype="uint8"。np.zeros():这将返回给定形状和类型的数组,并用零填充; 在这种情况下,形状为(50, 50, 3)和dtype="uint8"。np.arange():考虑到提供的步骤,它会在给定的间隔内返回均匀间隔的值。 不包括间隔的末尾(在这种情况下为300)。np.concatenate():这将沿着现有轴(在本例中为axis=1)连接一系列数组,以水平连接图像。
构建样本图像后,下一步是使用不同的阈值对其进行阈值处理。 在这种情况下,阈值是0,50,100,150,200和250。
您将看到阈值与样本图像中不同的灰度色调相同。 用不同的阈值对样本图像进行阈值处理的代码如下:
ret1, thresh1 = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY)
ret2, thresh2 = cv2.threshold(gray_image, 50, 255, cv2.THRESH_BINARY)
ret3, thresh3 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_BINARY)
ret4, thresh4 = cv2.threshold(gray_image, 150, 255, cv2.THRESH_BINARY)
ret5, thresh5 = cv2.threshold(gray_image, 200, 255, cv2.THRESH_BINARY)
ret6, thresh6 = cv2.threshold(gray_image, 250, 255, cv2.THRESH_BINARY)
您可以根据阈值和样本图像的不同灰度色调,看到阈值化后的黑白图像如何变化。
在对图像进行阈值处理后,共同的输出是黑白图像。 在前面的章节中,屏幕截图的背景也是白色的。 在本章中,为了进行适当的可视化,我们已使用fig.patch.set_facecolor('silver')将屏幕快照的背景更改为silver颜色。
简单阈值
为了执行简单的阈值处理,OpenCV 提供了cv2.threshold()函数,该函数在上一节中进行了简要介绍。 此方法的签名如下:
cv2.threshold(src, thresh, maxval, type, dst=None) -> retval, dst
cv2.threshold()函数将固定级别的阈值应用于src输入数组(多通道,8 位或 32 位浮点)。 固定级别由thresh参数调整,该参数设置阈值。 type参数设置阈值类型,这将在下一个小节中进一步说明。
不同的类型如下:
cv2.THRESH_BINARYcv2.THRESH_BINARY_INVcv2.THRESH_TRUNCcv2.THRESH_TOZEROcv2.THRESH_TOZERO_INVcv2.THRESH_OTSUcv2.THRESH_TRIANGLE
此外,maxval参数设置最大值,仅与cv2.THRESH_BINARY和cv2.THRESH_BINARY_INV阈值类型一起使用。 最后,仅在cv2.THRESH_OTSU和cv2.THRESH_TRIANGLE阈值类型中,输入图像应为单通道。
在本节中,我们将检查所有可能的配置以了解所有这些参数。
阈值类型
阈值操作的类型根据其公式描述。 考虑到src是源(原始)图像,而dst对应于阈值化后的目标(结果)图像。 从这个意义上讲,src(x, y)对应于源图像像素(x, y)的强度,而dst(x, y)将对应于目标图像的像素(x, y)的强度。
这是cv2.THRESH_BINARY的公式:

因此,如果像素src(x, y)的强度高于thresh,则将新像素强度设置为maxval参数。 否则,将像素设置为0。
这是cv2.THRESH_BINARY_INV的公式:
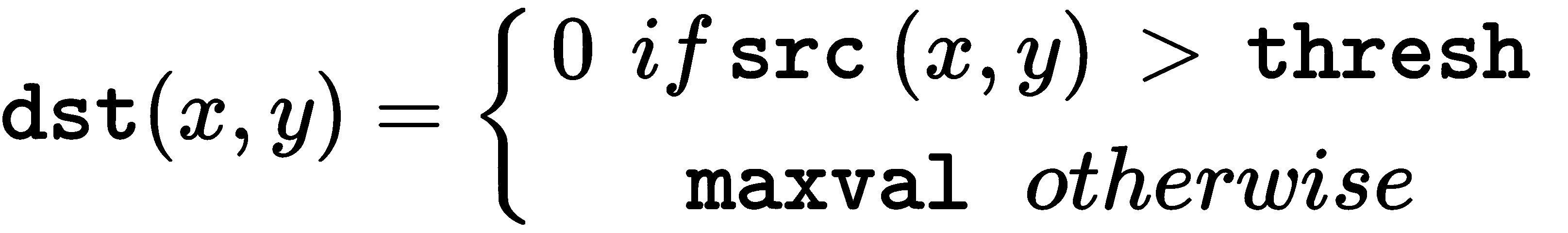
因此,如果像素src(x, y)的强度高于thresh,则新像素强度设置为0。 否则,将其设置为maxval。
这是cv2.THRESH_TRUNC的公式:
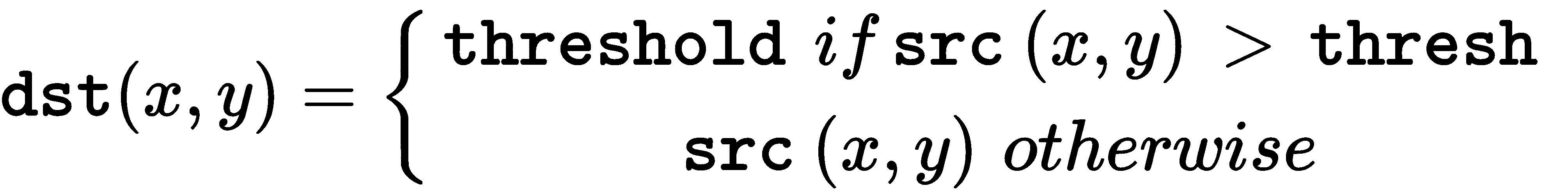
因此,如果像素src(x, y)的强度高于thresh,则新像素强度设置为threshold。 否则,将其设置为src(x, y)。
这是cv2.THRESH_TOZERO的公式:
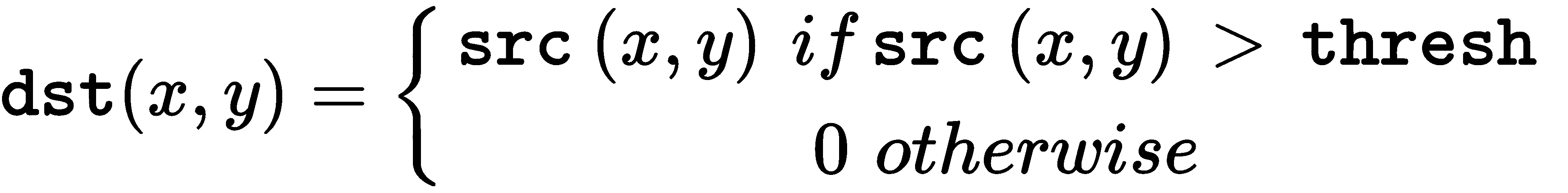
因此,如果像素src(x, y)的强度高于thresh,则新像素值将设置为src(x, y)。 否则,将其设置为0。
这是cv2.THRESH_TOZERO_INV的公式:

因此,如果像素src(x, y)的强度大于thresh,则新像素值将设置为0。 否则,将其设置为src(x, y)。
另外,可以将特殊的cv2.THRESH_OTSU和cv2.THRESH_TRIANGLE值与先前引入的值之一cv2.THRESH_BINARY,cv2.THRESH_BINARY_INV,cv2.THRESH_TRUNC,cv2.THRESH_TOZERO和cv2.THRESH_TOZERO_INV组合在一起。 在这些情况下(cv2.THRESH_OTSU和cv2.THRESH_TRIANGLE),阈值运算(仅对 8 位图像实现)将计算最佳阈值,而不是指定的thresh值。 应当注意,阈值操作返回计算出的最佳阈值。
thresholding_simple_types.py脚本可帮助您了解上述类型。 我们使用上一节中介绍的相同样本图像,并对所有先前类型使用固定阈值(thresh = 100)执行阈值操作。
执行此操作的关键代码如下:
ret1, thresh1 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_BINARY)
ret2, thresh2 = cv2.threshold(gray_image, 100, 220, cv2.THRESH_BINARY)
ret3, thresh3 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_BINARY_INV)
ret4, thresh4 = cv2.threshold(gray_image, 100, 220, cv2.THRESH_BINARY_INV)
ret5, thresh5 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_TRUNC)
ret6, thresh6 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_TOZERO)
ret7, thresh7 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_TOZERO_INV)
如前所述,maxval参数将最大值设置为仅与cv2.THRESH_BINARY和cv2.THRESH_BINARY_INV阈值类型一起使用。 在此示例中,我们为cv2.THRESH_BINARY和cv2.THRESH_BINARY_INV类型将maxval的值设置为255和220,以查看阈值图像在两种情况下如何变化。 下一个屏幕截图中可以看到此脚本的输出:

在上一个屏幕截图中,您既可以看到原始灰度图像,也可以看到所执行的七个阈值操作的结果。 此外,您可以看到maxval参数的效果,该参数仅与cv2.THRESH_BINARY和cv2.THRESH_BINARY_INV阈值类型一起使用。 更具体地说,例如,参见第一和第二阈值运算结果之间的差异(结果图像中的白色与灰色之间的差异),以及第三和第四阈值运算结果之间的差异(结果图像中的白色与灰色之间的差异)。
应用于真实图像的简单阈值
在前面的示例中,我们将简单的阈值操作应用于定制图像,以查看不同参数的工作方式。 在本节中,我们将cv2.threshold()应用于实际图像。 thresholding_example.py脚本执行此操作。 我们对cv2.threshold()函数应用了不同的阈值,如下所示– 60,70,80,90,100,110,120,130:
ret1, thresh1 = cv2.threshold(gray_image, 60, 255, cv2.THRESH_BINARY)
ret2, thresh2 = cv2.threshold(gray_image, 70, 255, cv2.THRESH_BINARY)
ret3, thresh3 = cv2.threshold(gray_image, 80, 255, cv2.THRESH_BINARY)
ret4, thresh4 = cv2.threshold(gray_image, 90, 255, cv2.THRESH_BINARY)
ret5, thresh5 = cv2.threshold(gray_image, 100, 255, cv2.THRESH_BINARY)
ret6, thresh6 = cv2.threshold(gray_image, 110, 255, cv2.THRESH_BINARY)
ret7, thresh7 = cv2.threshold(gray_image, 120, 255, cv2.THRESH_BINARY)
ret8, thresh8 = cv2.threshold(gray_image, 130, 255, cv2.THRESH_BINARY)
最后,我们显示阈值图像,如下所示:
show_img_with_matplotlib(cv2.cvtColor(thresh1, cv2.COLOR_GRAY2BGR), "threshold = 60", 2)
show_img_with_matplotlib(cv2.cvtColor(thresh2, cv2.COLOR_GRAY2BGR), "threshold = 70", 3)
show_img_with_matplotlib(cv2.cvtColor(thresh3, cv2.COLOR_GRAY2BGR), "threshold = 80", 4)
show_img_with_matplotlib(cv2.cvtColor(thresh4, cv2.COLOR_GRAY2BGR), "threshold = 90", 5)
show_img_with_matplotlib(cv2.cvtColor(thresh5, cv2.COLOR_GRAY2BGR), "threshold = 100", 6)
show_img_with_matplotlib(cv2.cvtColor(thresh6, cv2.COLOR_GRAY2BGR), "threshold = 110", 7)
show_img_with_matplotlib(cv2.cvtColor(thresh7, cv2.COLOR_GRAY2BGR), "threshold = 120", 8)
show_img_with_matplotlib(cv2.cvtColor(thresh8, cv2.COLOR_GRAY2BGR), "threshold = 130", 9)
在以下屏幕截图中可以看到此脚本的输出:

如您所见,在使用cv2.threshold()阈值图像时,阈值起着至关重要的作用。 假设您的图像处理算法尝试识别网格内的数字。 如果阈值较低(例如threshold = 60),则阈值图像中会缺少一些数字。 另一方面,如果阈值高(例如threshold = 120),则黑色像素会遮挡一些数字。 因此,为整个图像建立全局阈值是非常困难的。 此外,如果图像受不同的照明条件影响,则几乎不可能完成此任务。 这就是为什么其他阈值算法可以应用于图像阈值的原因。 在下一节中,将介绍自适应阈值算法。
最后,您可以在代码段中看到我们已经创建了几个具有固定阈值的阈值图像(一张一张)。 可以通过创建一个包含阈值的数组(使用np.arange())并在创建的数组上进行迭代以针对该数组的每个值调用cv.threshold()来进行优化。 请参阅“问题”部分,因为建议将此优化作为练习。
自适应阈值
在上一节中,我们已使用全局阈值应用了cv2.threshold()。 如我们所见,由于图像不同区域的照明条件不同,因此获得的结果不是很好。 在这些情况下,您可以尝试自适应阈值化。 在 OpenCV 中,自适应阈值通过cv2.adapativeThreshold()函数执行。 此方法的签名如下:
adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst]) -> dst
此函数将自适应阈值应用于src数组(8 位单通道图像)。 maxValue参数设置dst图像中满足条件的像素的值。 adaptiveMethod参数设置自适应阈值算法以使用:
cv2.ADAPTIVE_THRESH_MEAN_C:T(x, y)阈值计算为(x, y)的blockSize x blockSize邻域平均值减去C参数cv2.ADAPTIVE_THRESH_GAUSSIAN_C:将T(x, y)阈值计算为(x, y)的blockSize x blockSize邻域的加权总和减去C参数
blockSize参数设置用于计算像素阈值的邻域的大小,并且可以采用3, 5, 7,...等值。
C参数只是从均值或加权均值中减去的常数(取决于adaptiveMethod参数设置的自适应方法)。 通常,此值为正,但可以为零或负。 最后,thresholdType 参数设置cv2.THRESH_BINARY或cv2.THRESH_BINARY_INV阈值类型。
根据以下公式,其中T(x, y)是为每个像素计算的阈值,thresholding_adaptive.py脚本使用cv2.ADAPTIVE_THRESH_MEAN_C和cv2.ADAPTIVE_THRESH_GAUSSIAN_C方法将自适应阈值应用于测试图像:
- 这是
cv2.THRESH_BINARY的公式:
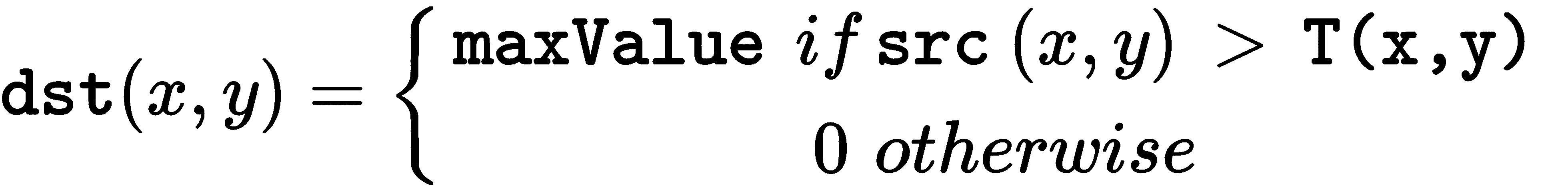
- 这是
cv2.THRESH_BINARY_INV的公式:

在以下屏幕截图中可以看到此脚本的输出:
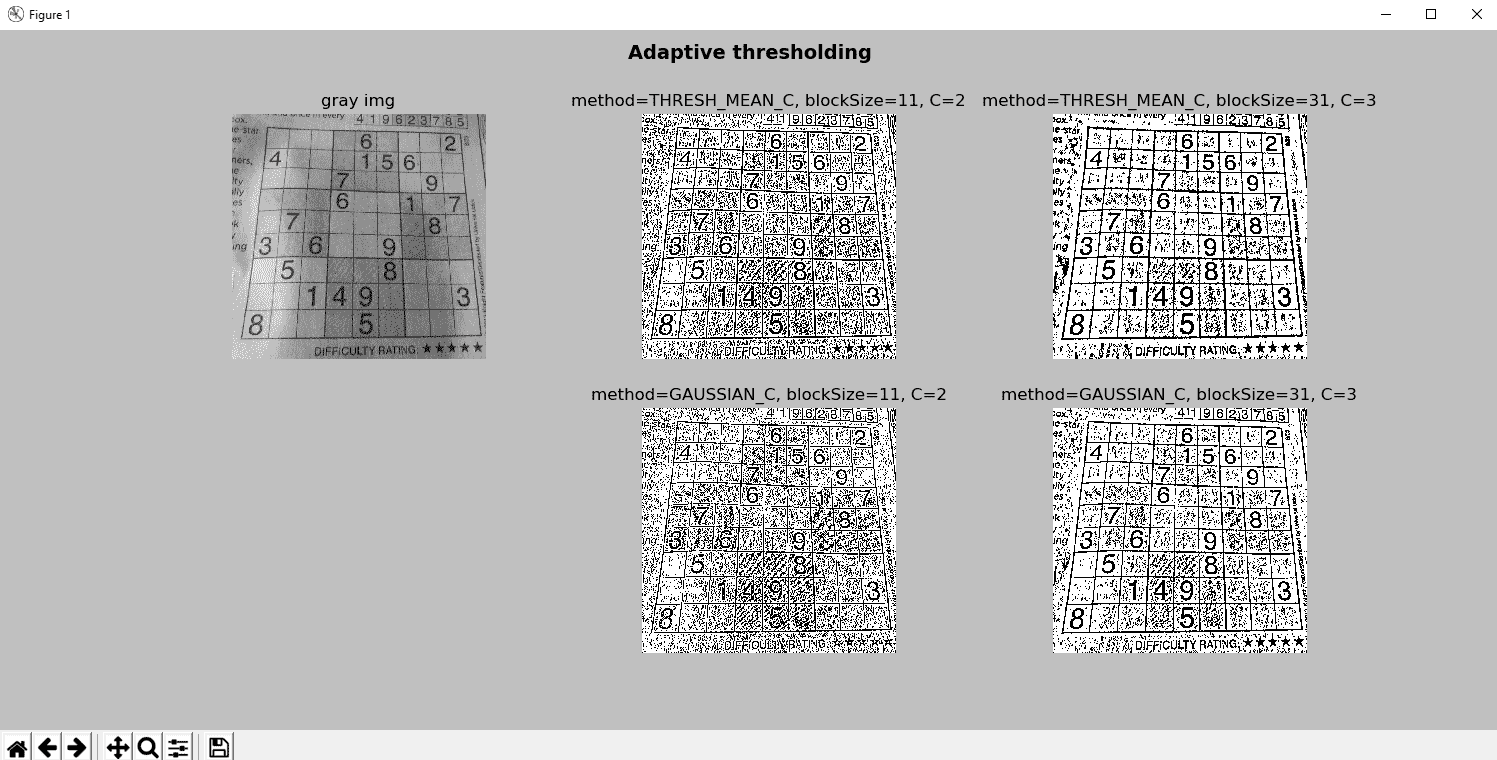
在上一个屏幕截图中,您可以在应用具有不同参数的cv2.adaptiveThreshold()之后看到输出。 如前所述,如果您的任务是识别数字,则自适应阈值处理可以为您提供更好的阈值图像。 但是,您也可以看到,图像中出现了很多噪点。 为了对其进行处理,可以应用一些平滑操作(请参阅第 5 章,“图像处理技术”)。
在这种情况下,我们可以应用双边过滤器,因为它在去除噪声的同时保持尖锐边缘非常有用。 为了应用双边过滤器,OpenCV 提供了cv2.bilateralFilter()函数。 因此,我们可以在对图像进行阈值处理之前应用该函数,如下所示:
gray_image = cv2.bilateralFilter(gray_image, 15, 25, 25)
此示例的代码可以在thresholding_adaptive_filter_noise.py脚本中看到。 在以下屏幕截图中可以看到输出:

您会看到,应用平滑过滤器是处理噪声的好方法。 在这种情况下,应用双边过滤器是因为我们要保持边缘清晰。
大津阈值算法
正如我们在前面的部分中看到的那样,简单的阈值算法应用了任意全局阈值。 在这种情况下,我们需要做的是尝试使用不同的阈值,并查看阈值图像,以查看结果是否满足我们的需求。 但是,这种方法可能非常繁琐。
一种解决方案是使用 OpenCV 通过cv2.adapativeThreshold()函数提供的自适应阈值。 在 OpenCV 中应用自适应阈值设置时,无需设置阈值,这是一件好事。
但是,应正确建立两个参数:blockSize参数和C参数。 另一种方法是使用大津的二值化算法,这在处理双峰图像时是一种很好的方法。 双峰图像可以通过其包含两个峰的直方图来表征。大津的算法通过最大化两类像素之间的方差来自动计算将两个峰分开的最佳阈值。 等效地,最佳阈值使组内差异最小化。大津的二值化算法是一种统计方法,因为它依赖于从直方图得出的统计信息(例如,均值,方差或熵)。 为了计算 OpenCV 中大津的二值化,我们使用cv2.threshold()函数,如下所示:
ret, th = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
在这种情况下,由于大津的二值化算法会计算最佳阈值,因此无需设置阈值,这就是thresh = 0的原因。 cv2.THRESH_OTSU标志指示将应用大津算法。 另外,在这种情况下,此标志与cv2.THRESH_BINARY组合。 实际上,它可以与cv2.THRESH_BINARY,cv2.THRESH_BINARY_INV,cv2.THRESH_TRUNC,cv2.THRESH_TOZERO和cv2.THRESH_TOZERO_INV组合。 此函数返回阈值图像th和阈值ret。
在thresholding_otsu.py脚本中,我们已将此算法应用于样本图像。 在以下屏幕截图中可以看到输出。 我们修改了show_hist_with_matplotlib_gray()函数,添加了一个额外的参数,该参数对应于大津算法计算出的最佳阈值。 为了绘制此阈值,我们绘制一条线,以t阈值建立x坐标,如下所示:
plt.axvline(x=t, color='m', linestyle='--')
在以下屏幕截图中可以看到thresholding_otsu.py脚本的输出:

在上一个屏幕截图中,我们可以看到图像没有噪点,带有白色背景和非常清晰的绿叶。 但是,噪声会影响阈值算法,因此我们应该对其进行适当处理。 例如,在上一节中,我们执行双边滤波,以滤除一些噪声并保留边缘。 在下一个示例中,我们将向叶图像添加一些噪声,以查看阈值算法如何受到影响。 可以在thresholding_otsu_filter_noise.py脚本中看到。 在此脚本中,我们在应用高斯过滤器之前和之后应用大津的二值化算法,以查看阈值图像如何急剧变化。
在以下屏幕截图中可以看到:
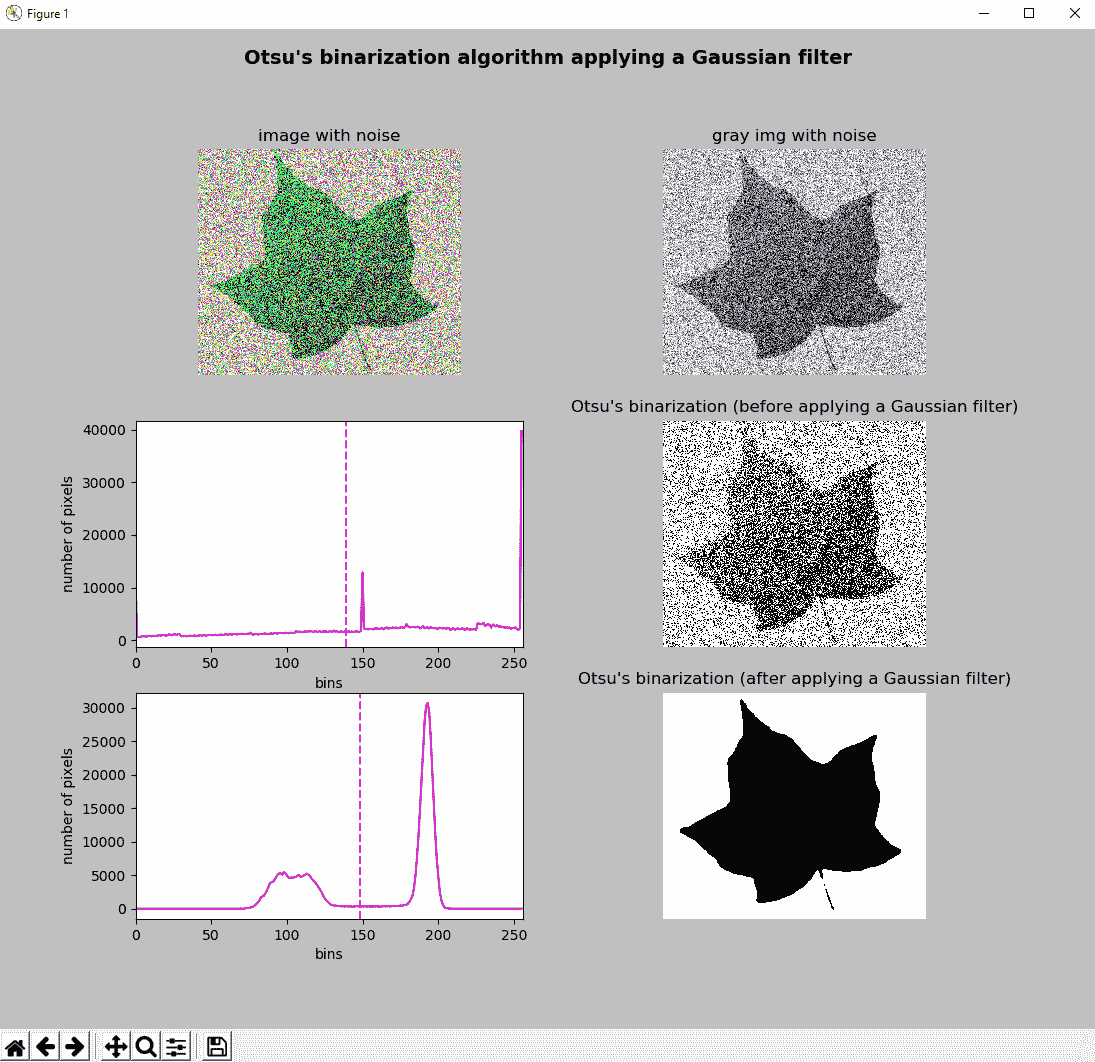
如我们所见,如果不应用平滑过滤器(在这种情况下为高斯过滤器),则阈值图像也会充满噪声。 但是,应用高斯过滤器是正确过滤噪声的好方法。 此外,滤波后的图像是双峰的。 这个事实可以在对应于滤波图像的直方图中看到。 在这种情况下,大津的二值化算法可以正确分割叶子。
三角二值化算法
另一种自动阈值算法是三角算法,该算法被认为是基于形状的方法,因为它可以分析直方图的结构(或形状)(例如,尝试查找谷值,峰值和其他形状直方图特征)。 该算法分三步工作。 第一步,在灰度轴上的直方图最大值b_max与灰度轴上的最小值b_min之间计算一条线 。 在第二步中,对于b[b_min - b_max]的所有值,计算直线(在第一步中计算出)到直方图的距离。 最后,在第三步中,将直方图和直线之间的距离最大的级别选择为阈值。
在 OpenCV 中使用三角二值化算法的方式与大津的算法非常相似。 实际上,仅应适当更改一个标志。 在大津市二值化的情况下,设置了cv2.THRESH_OTSU标志。 对于三角二值化算法,标记为cv2.THRESH_TRIANGLE,如下所示:
ret1, th1 = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_TRIANGLE)
在下一个屏幕截图中,您可以看到将三角二值化算法应用于噪声图像(与上一节中大津的二值化示例中使用的图像相同)的输出。 该示例的完整代码可以在thresholding_triangle_filter_noise.py脚本中看到:
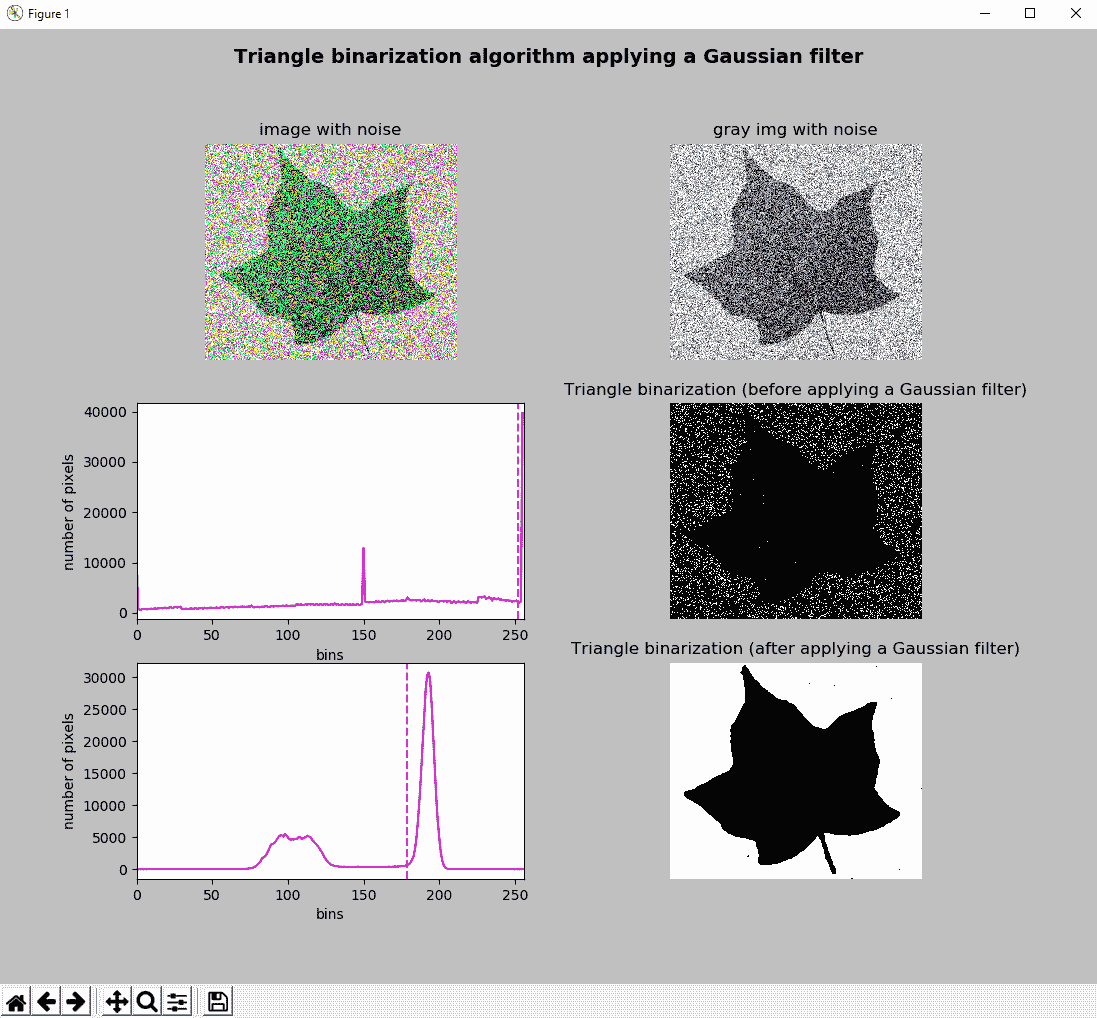
您会看到,应用高斯过滤器是过滤噪声的好方法。 这样,三角二值化算法可以正确地分割叶子。
彩色图像的阈值
cv2.threshold()函数也可以应用于多通道图像。 可以在thresholding_bgr.py脚本中看到。 在这种情况下,cv2.threshold()函数在 BGR 图像的每个通道中应用阈值操作。 这产生与在每个通道中应用此函数并合并阈值通道相同的结果:
ret1, thresh1 = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY)
因此,上一行代码产生与执行以下操作相同的结果:
(b, g, r) = cv2.split(image)
ret2, thresh2 = cv2.threshold(b, 150, 255, cv2.THRESH_BINARY)
ret3, thresh3 = cv2.threshold(g, 150, 255, cv2.THRESH_BINARY)
ret4, thresh4 = cv2.threshold(r, 150, 255, cv2.THRESH_BINARY)
bgr_thresh = cv2.merge((thresh2, thresh3, thresh4))
结果可以在以下屏幕截图中看到:

尽管您可以在多通道图像(例如 BGR 图像)上执行cv2.threshold(),但是此操作可能会产生奇怪的结果。 例如,在结果图像中,由于每个通道只能采用两个值(在这种情况下为0和255),因此最终图像仅具有2^3个可能的颜色 。 在下一个屏幕截图中,我们还将这个颜色阈值应用于另一个测试图像:

如前面的屏幕快照所示,输出图像仅具有2^3个可能的颜色。 因此,在 BGR 图像中执行阈值操作时,应考虑到这一点。
使用 scikit-image 的阈值算法
正如我们在第 1 章,“设置 OpenCV”中提到的那样,还有其他包可用于科学计算,数据科学,机器学习,深度学习和计算机视觉。 与计算机视觉有关,scikit-image 是图像处理算法的集合。 scikit-image 操纵的图像是 NumPy 数组。
在本节中,我们将结合阈值技术使用 Scikit-image 功能。 因此,如果要复制此处获得的结果,则第一步是安装它。 请参阅这里,以便在您的操作系统上正确安装 scikit-image。 在这里,我们将使用 Conda 来安装它,Conda 是一个开源包管理系统(也是环境管理系统)。 请参阅第 1 章,“设置 OpenCV”,以了解如何安装 Anaconda/Miniconda 发行版和 Conda。 要为基于 Conda 的发行版(Anaconda,Miniconda)安装 scikit-image,请执行以下代码:
conda install -c conda-forge scikit-image
使用 scikit-image 介绍阈值
为了测试 Scikit-image,我们将使用大津的二值化算法对测试图像进行阈值处理。 为了尝试此方法,第一步是导入所需的包。 在这种情况下,与 scikit-image 关联如下:
from skimage.filters import threshold_otsu
from skimage import img_as_ubyte
将大津的二值化算法与 scikit-image 结合使用的关键代码如下:
thresh = threshold_otsu(gray_image)
binary = gray_image > thresh
binary = img_as_ubyte(binary)
threshold_otsu(gray_image)函数基于大津的二值化算法返回阈值。 然后,使用该值构造二进制图像(dtype= bool),应将其转换为 8 位无符号整数格式(dtype= uint8)以进行适当的可视化。 img_as_ubyte()函数用于此目的。 该示例的完整代码可以在thresholding_scikit_image_otsu.py脚本中看到。
在以下屏幕截图中可以看到输出:

现在,我们将尝试使用 scikit-image 进行一些阈值处理。
尝试使用 scikit-image 更多的阈值技术
我们将对比较大津,三角形,Niblack 和 Sauvola 的阈值处理技术的测试图像进行阈值处理。大津和三角形是全局阈值技术,而 Niblack 和 Sauvola 是局部阈值技术。 当背景不均匀时,局部阈值技术被认为是更好的方法。 有关 Niblack 和 Sauvola 阈值算法的更多信息,请分别参见《数字图像处理简介》(1986)和《自适应文档图像二值化》(2000)。 该示例的完整代码可以在thresholding_scikit_image_techniques.py脚本中看到。 为了尝试这些方法,第一步是导入所需的包。 在这种情况下,与 scikit-image 关联如下:
from skimage.filters import (threshold_otsu, threshold_triangle, threshold_niblack, threshold_sauvola)
from skimage import img_as_ubyte
为了对 scikit-image 执行阈值化操作,我们调用每种阈值化方法(threshold_otsu(),threshold_niblack(),threshold_sauvola()和threshold_triangle()):
# Trying Otsu's scikit-image algorithm:
thresh_otsu = threshold_otsu(gray_image)
binary_otsu = gray_image > thresh_otsu
binary_otsu = img_as_ubyte(binary_otsu)
# Trying Niblack's scikit-image algorithm:
thresh_niblack = threshold_niblack(gray_image, window_size=25, k=0.8)
binary_niblack = gray_image > thresh_niblack
binary_niblack = img_as_ubyte(binary_niblack)
# Trying Sauvola's scikit-image algorithm:
thresh_sauvola = threshold_sauvola(gray_image, window_size=25)
binary_sauvola = gray_image > thresh_sauvola
binary_sauvola = img_as_ubyte(binary_sauvola)
# Trying triangle scikit-image algorithm:
thresh_triangle = threshold_triangle(gray_image)
binary_triangle = gray_image > thresh_triangle
binary_triangle = img_as_ubyte(binary_triangle)
输出可以在下一个屏幕截图中看到:

如您所见,当背景不均匀时,局部阈值方法可以提供更好的结果。 实际上,这些方法可以应用于文本识别。 最后,scikit-image 附带了更多可以尝试的阈值处理技术。 如有必要,请查阅 API 文档,以查看位于这个页面的所有可用方法。
总结
在本章中,我们回顾了可用于对图像进行阈值处理的主要阈值处理技术。 门限技术可用于许多计算机视觉任务(例如,文本识别和图像分割等)。 简单和自适应阈值处理技术都已被审查。 此外,我们已经了解了如何应用大津的二值化算法和三角形算法来自动选择全局阈值以对图像进行阈值处理。 最后,我们看到了如何使用 scikit-image 使用不同的阈值技术。 从这个意义上说,两种全局阈值技术(大津和三角算法)和两种局部阈值技术(Niblack 和 Sauvola 算法)已应用于测试图像。
在第 8 章,“轮廓检测,滤波和图形”中,我们将看到如何处理轮廓,轮廓对于形状分析以及对象检测和识别非常有用。
问题
- 使用具有阈值
100的cv2.threshold()和cv2.THRESH_BINARY阈值类型应用阈值操作。 - 使用
cv2.adapativeThreshold(),cv2.ADAPTIVE_THRESH_MEAN_C,C=2和blockSize=9应用自适应阈值运算。 - 使用
cv2.THRESH_BINARY阈值类型应用大津的阈值。 - 使用
cv2.THRESH_BINARY阈值类型应用三角形阈值。 - 使用 scikit-image 应用大津的阈值。
- 使用 scikit-image 应用三角形阈值。
- 使用 scikit-image 应用 Niblack 的阈值。
- 使用 scikit-image 和
25的窗口大小应用 Sauvola 的阈值。 - 修改
thresholding_example.py脚本以使用np.arange(),目的是定义要应用于cv2.threshold()函数的阈值。 然后,使用定义的阈值调用cv2.threshold()函数,并将所有阈值图像存储在数组中。 最后,显示每个调用show_img_with_matplotlib()的数组中的所有图像。 将脚本重命名为thresholding_example_arange.py。
进一步阅读
以下参考资料将帮助您深入研究阈值处理和其他图像处理技术:
八、轮廓检测,过滤和绘图
轮廓可以定义为定义图像中对象边界的点序列。 因此,轮廓线传达有关对象边界的关键信息,并对有关对象形状的主要信息进行编码。 该信息用作图像描述符(例如 SIFT,傅立叶描述符或形状上下文等)的基础,并且可用于形状分析以及对象检测和识别。
在本章中,您将看到如何处理轮廓,轮廓用于形状分析以及对象检测和识别。
在本章中,与轮廓相关的关键点将在以下主题中解决:
- 轮廓介绍
- 压缩轮廓
- 图像的矩
- 与轮廓有关的更多函数
- 过滤轮廓
- 识别轮廓
- 匹配轮廓
技术要求
技术要求如下:
- Python 和 OpenCV
- 特定于 Python 的 IDE
- NumPy 和 Matplotlib 包
- Git 客户端
有关如何安装这些要求的更多详细信息,请参见第 1 章,“设置 OpenCV”。 “精通 Python OpenCV 4”的 GitHub 存储库,其中包含所有支持的项目文件,这是从第一章到最后一章学习本书所必需的,可以在下一个 URL 中访问。
轮廓介绍
轮廓可以看作是一条曲线,它沿着特定形状的边界连接所有点。 当它们定义形状的边界时,对这些点的分析可以揭示用于形状分析以及对象检测和识别的关键信息。 OpenCV 提供了许多功能来正确检测和处理轮廓。 但是,在深入探讨这些功能之前,我们将了解样本轮廓的结构。 例如,以下函数模拟检测假设图像中的轮廓:
def get_one_contour():
"""Returns a 'fixed' contour"""
cnts = [np.array(
[[[600, 320]], [[563, 460]], [[460, 562]], [[320, 600]], [[180, 563]], [[78, 460]], [[40, 320]], [[77, 180]], [[179, 78]], [[319, 40]], [[459, 77]], [[562, 179]]], dtype=np.int32)]
return cnts
如您所见,轮廓是由np.int32类型的许多点组成的数组(整数在[-2147483648, 2147483647]范围内)。 现在,我们可以调用此函数来获取轮廓数组。 在这种情况下,此数组只有一个detected轮廓:
contours = get_one_contour()
print("'detected' contours: '{}' ".format(len(contours)))
print("contour shape: '{}'".format(contours[0].shape))
此时,我们可以应用 OpenCV 提供的所有功能来播放轮廓。 请注意,定义get_one_contour()函数很有趣,因为它为您提供了一种简单的方法来准备使用轮廓,以便调试和测试与轮廓相关的其他功能。 在许多情况下,实际图像中检测到的轮廓具有数百个点,因此很难调试代码。 因此,请随时使用此函数。
为了完成对轮廓的介绍,OpenCV 提供了cv2.drawContours(),它可以在图像中绘制轮廓轮廓。 因此,我们可以调用该函数来查看轮廓。 此外,我们还对draw_contour_points()函数进行了编码,该函数在图像中绘制轮廓点。 同样,我们已经使用np.squeeze()函数来摆脱一维数组,例如使用[1,2,3]而不是[[[1,2,3]]]。 例如,如果打印上一个函数中定义的轮廓,则将得到以下内容:
[[[600 320]]
[[563 460]]
[[460 562]]
[[320 600]]
[[180 563]]
[[ 78 460]]
[[ 40 320]]
[[ 77 180]]
[[179 78]]
[[319 40]]
[[459 77]]
[[562 179]]]
执行以下代码行之后:
squeeze = np.squeeze(cnt)
如果打印squeeze,将得到以下输出:
[[600 320]
[563 460]
[460 562]
[320 600]
[180 563]
[ 78 460]
[ 40 320]
[ 77 180]
[179 78]
[319 40]
[459 77]
[562 179]]
此时,我们可以遍历此数组的所有点。
因此,draw_contour_points()函数的代码如下:
def draw_contour_points(img, cnts, color):
"""Draw all points from a list of contours"""
for cnt in cnts:
squeeze = np.squeeze(cnt)
for p in squeeze:
p = array_to_tuple(p)
cv2.circle(img, p, 10, color, -1)
return img
另一个考虑因素是,在先前的函数中,我们使用了array_to_tuple()函数,该函数将数组转换为元组:
def array_to_tuple(arr):
"""Converts array to tuple"""
return tuple(arr.reshape(1, -1)[0])
这样,轮廓的第一个点[600 320]转换为(600, 320),可以在cv2.circle()内部将其用作中心。 可以在contours_introduction.py中看到有关轮廓的先前介绍的完整代码。 下一个屏幕截图中可以看到此脚本的输出:

为了完成对轮廓的介绍,我们还编写了脚本contours_introduction_2.py。 在这里,我们已经编码了函数build_sample_image()和build_sample_image_2()。 这些函数在图像中绘制基本形状,其目的是提供一些可预测(或预定义)的形状。
这两个函数与上一个脚本中定义的get_one_contour()函数具有相同的目的,即,它们有助于我们理解与轮廓有关的关键概念。 build_sample_image()函数的代码如下:
def build_sample_image():
"""Builds a sample image with basic shapes"""
# Create a 500x500 gray image (70 intensity) with a rectangle and a circle inside:
img = np.ones((500, 500, 3), dtype="uint8") * 70
cv2.rectangle(img, (100, 100), (300, 300), (255, 0, 255), -1)
cv2.circle(img, (400, 400), 100, (255, 255, 0), -1)
return img
如您所见,此函数绘制两个填充的形状(一个矩形和一个圆形)。 因此,此函数创建具有两个(外部)轮廓的图像。 build_sample_image_2()函数的代码如下:
def build_sample_image_2():
"""Builds a sample image with basic shapes"""
# Create a 500x500 gray image (70 intensity) with a rectangle and a circle inside (with internal contours):
img = np.ones((500, 500, 3), dtype="uint8") * 70
cv2.rectangle(img, (100, 100), (300, 300), (255, 0, 255), -1)
cv2.rectangle(img, (150, 150), (250, 250), (70, 70, 70), -1)
cv2.circle(img, (400, 400), 100, (255, 255, 0), -1)
cv2.circle(img, (400, 400), 50, (70, 70, 70), -1)
此函数绘制两个填充的矩形(一个在另一个内部)和两个填充的圆(一个在另一个内部)。 此函数创建具有两个外部轮廓和两个内部轮廓的图像。
在contours_introduction_2.py中,在将图像加载之后,我们将其转换为灰度并设置了阈值以获得二进制图像。 此二进制图像稍后将用于使用cv2.findContours()函数查找轮廓。 如前所述,创建的图像仅具有圆形和正方形。 因此,调用cv2.findContours()将找到所有这些创建的轮廓。 cv2.findContours()方法的签名如下:
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset]]]) -> image, contours, hierarchy
OpenCV 提供cv2.findContours(),可用于检测二进制图像(例如,阈值运算后生成的图像)中的轮廓。 该函数实现了中通过边界进行数字化二进制图像的拓扑结构分析中定义的算法。 应当注意,在 OpenCV 3.2 之前,源图像将已被修改,并且自 OpenCV 3.2 起,在调用此函数后将不再修改源图像。 源图像被视为二进制图像,其中非零像素被视为 1。 该函数返回检测到的轮廓,每个轮廓包含所有检索到的定义边界的点。
检索到的轮廓可以以不同的模式输出-cv2.RETR_EXTERNAL(仅在轮廓外部输出),cv2.RETR_LIST(不带任何层次关系输出所有轮廓)和cv2.RETR_TREE(通过建立层次关系输出所有轮廓) 。 输出向量hierarchy包含有关此层次关系的信息,为每个检测到的轮廓提供一个条目。 对于每个第i个轮廓contours[i],hierarchy[i][j]和j在[0,3]范围内的轮廓包含以下内容:
hierarchy[i][0]:同一层级上的下一个轮廓的索引hierarchy[i][1]:在相同层次级别上的先前轮廓的索引hierarchy[i][2]:第一个子轮廓的索引hierarchy[i][3]:父轮廓的索引
hierarchy[i][j]中的负值表示没有下一个轮廓j=0,没有上一个轮廓j=1,没有子轮廓j=2或没有父轮廓j=3。 最后,method参数设置检索与每个检测到的轮廓有关的点时使用的近似方法。 下一部分将进一步说明此参数。
如果执行contours_introduction_2.py脚本,则可以看到以下屏幕:

在此屏幕截图中,通过调用cv2.findContours()来计算外部(cv2.RETR_EXTERNAL)和外部和内部(cv2.RETR_LIST)。
压缩轮廓
检测到的轮廓可以压缩以减少点数。 从这个意义上讲,OpenCV 提供了几种减少点数的方法。 可以使用参数method进行设置。 另外,可以通过将标志设置为cv2.CHAIN_APPROX_NONE(所有边界点都存储在其中)来禁用此压缩; 因此,不执行压缩。
cv2.CHAIN_APPROX_SIMPLE方法可用于压缩检测到的轮廓,因为它压缩轮廓的水平,垂直和对角线部分,仅保留端点。 例如,如果我们使用cv2.CHAIN_APPROX_SIMPLE压缩矩形的轮廓,则它将仅由四个点组成。
最后,OpenCV 提供了另外两个基于 Teh-Chin 算法的轮廓压缩标志,这是一种非参数方法。 该算法的第一步是根据每个点的局部属性确定其支持区域(ROS)。
接下来,该算法计算每个点的相对重要性的度量。 最后,通过非极大值抑制过程来检测优势点。 他们使用三种不同的有效度量,分别对应于离散曲率度量的不同精确度:
- 余弦度量
- K 曲率度量
- 一种曲率度量(
2的k = 1)
因此,结合离散曲率量度,OpenCV 提供了两个标记-cv2.CHAIN_APPROX_TC89_L1和cv2.CHAIN_APPROX_TC89_KCOS。 有关此算法的更详细说明,请参见出版物《关于检测数字曲线上的优势点》(1989)。 只是为了澄清起见,_CT89_对该名称的作者(Teh 和 Chin)的首字母以及出版年份(1989)进行了编码。
在contours_approximation_method.py中,用于method参数的上述四个标记(cv2.CHAIN_APPROX_NONE,cv2.CHAIN_APPROX_SIMPLE,cv2.CHAIN_APPROX_TC89_L1和cv2.CHAIN_APPROX_TC89_KCOS)用于编码图像中的两个检测到的轮廓。 下一个屏幕截图中可以看到此脚本的输出:

可以看出,定义轮廓的点以白色显示,显示了四种方法(cv2.CHAIN_APPROX_NONE,cv2.CHAIN_APPROX_SIMPLE,cv2.CHAIN_APPROX_TC89_L1和cv2.CHAIN_APPROX_TC89_KCOS)如何压缩两个提供形状的检测轮廓。
图像的矩
在数学中,矩可以看作是函数形状的特定定量度量。 图像矩可以看作是图像像素强度的加权平均值,或者是此类矩的函数,可以对某些有趣的属性进行编码。 从这个意义上讲,图像矩可用于描述检测到的轮廓的某些属性(例如,对象的质心或对象的面积等)。
cv2.moments()可用于计算直到向量形状或栅格化形状的三阶的所有矩。
此方法的签名如下:
retval = cv.moments(array[, binaryImage])
因此,为了计算检测到的轮廓(例如,第一个检测到的轮廓)的矩,请执行以下操作:
M = cv2.moments(contours[0])
如果我们打印M,则会得到以下信息:
{'m00': 235283.0, 'm10': 75282991.16666666, 'm01': 75279680.83333333, 'm20': 28496148988.333332, 'm11': 24089788592.25, 'm02': 28492341886.0, 'm30': 11939291123446.25, 'm21': 9118893653727.8, 'm12': 9117775940692.967, 'm03': 11936167227424.852, 'mu20': 4408013598.184406, 'mu11': 2712402.277420044, 'mu02': 4406324849.628765, 'mu30': 595042037.7265625, 'mu21': -292162222.4824219, 'mu12': -592577546.1586914, 'mu03': 294852334.5449219, 'nu20': 0.07962727021646843, 'nu11': 4.8997396280458296e-05, 'nu02': 0.07959676431294238, 'nu30': 2.2160077537124397e-05, 'nu21': -1.0880470778779139e-05, 'nu12': -2.2068296922023203e-05, 'nu03': 1.0980653771087236e-05}
如您所见,存在三种不同类型的矩(m[ji], mu[ji], nu[ji])。
如下计算空间矩m[ji]:
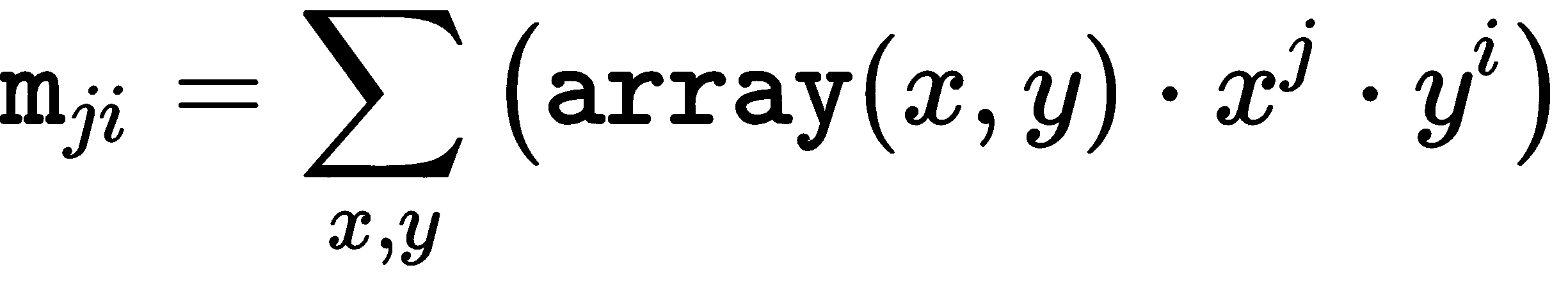
中心矩mu[ji]的计算如下:

在此适用以下条件:

前面的等式对应于质心。
根据定义,中心矩对于翻译而言是不变的。 因此,中心矩适合描述物体的形式。 然而,空间和中心矩的缺点是它们依赖于物体的大小。 它们不是尺度不变的。
归一化中心矩nu[ji]的计算如下:

归一化的中心矩从定义上来说是平移和尺度不变的。
接下来的矩值计算如下:
mu[00] = m[00], nu[00] = 1, nu[10] = mu[10] = mu[01] = mu[10] = 0
因此,这些矩不被存储。
通常根据矩的顺序对矩进行分类,矩的阶数是基于矩m[ji]的索引j, i的总和(j + i)来计算的。
在接下来的小节中,将提供有关图像矩的更多信息。 更具体地,将基于矩来计算一些物体特征(例如,中心,偏心率或轮廓的面积等)。 此外,还将看到胡矩不变式。 最后,还介绍了 Zernike 矩。
一些基于矩的对象特征
如前所述,矩是根据轮廓计算的特征,允许对对象进行几何重构。 尽管没有直接可理解的几何含义,但是可以基于矩来计算一些有趣的几何属性和参数。
在contours_analysis.py中,我们将首先计算检测到的轮廓的矩,然后,将计算一些物体特征:
M = cv2.moments(contours[0])
print("Contour area: '{}'".format(cv2.contourArea(contours[0])))
print("Contour area: '{}'".format(M['m00']))
如您所见,矩m00给出轮廓的面积,该面积等于函数cv2.contourArea()。 为了计算轮廓的质心,必须执行以下操作:
print("center X : '{}'".format(round(M['m10'] / M['m00'])))
print("center Y : '{}'".format(round(M['m01'] / M['m00'])))
圆度 κ是轮廓接近完美圆轮廓的量度。 轮廓的圆度可以根据以下公式计算:

P是轮廓的周长,A是相应的面积。 在正圆的情况下,结果为1; 获得的值越高,则圆形越小。
可以使用roundness()函数来计算:
def roundness(contour, moments):
"""Calculates the roundness of a contour"""
length = cv2.arcLength(contour, True)
k = (length * length) / (moments['m00'] * 4 * np.pi)
return k
偏心率(也称为伸长率)是轮廓可以伸长的量度。 偏心率ε可以直接根据对象的半长轴和半短轴a和b得出,其公式如下:
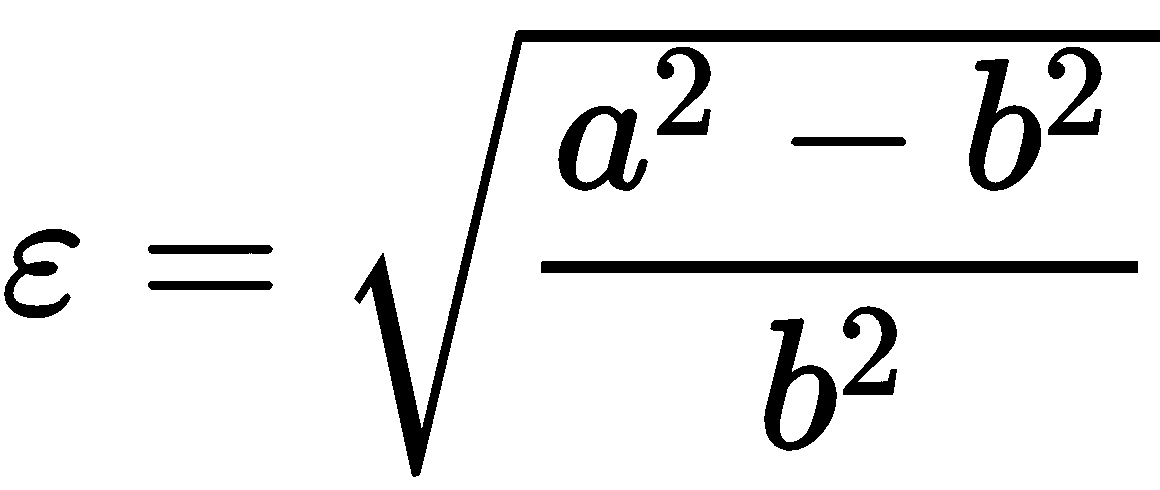
因此,一种计算轮廓的偏心率的方法是计算适合轮廓的椭圆,然后从所计算的椭圆中导出a和b。 最后,根据上式计算ε。
下一个代码执行此操作:
def eccentricity_from_ellipse(contour):
"""Calculates the eccentricity fitting an ellipse from a contour"""
(x, y), (MA, ma), angle = cv2.fitEllipse(contour)
a = ma / 2
b = MA / 2
ecc = np.sqrt(a ** 2 - b ** 2) / a
return ecc
另一种方法是通过下一个公式使用轮廓矩来计算偏心率:

这可以通过eccentricity_from_moments()执行:
def eccentricity_from_moments(moments):
"""Calculates the eccentricity from the moments of the contour"""
a1 = (moments['mu20'] + moments['mu02']) / 2
a2 = np.sqrt(4 * moments['mu11'] ** 2 + (moments['mu20'] - moments['mu02']) ** 2) / 2
ecc = np.sqrt(1 - (a1 - a2) / (a1 + a2))
return ecc
为了完成可用于描述轮廓的特征,可以计算其他属性。 例如,可以基于最小边界矩形的尺寸(使用cv2.boundingRect()计算)轻松计算出宽高比。 长宽比是轮廓的边界矩形的宽度与高度之比:
def aspect_ratio(contour):
"""Returns the aspect ratio of the contour based on the dimensions of the bounding rect"""
x, y, w, h = cv2.boundingRect(contour)
res = float(w) / h
return res
如前所述,所有这些属性都是在contours_analysis.py脚本中计算的。 下一个屏幕截图中可以看到此脚本的输出:

在上一个屏幕截图中,通过打印脚本中计算出的所有属性来显示轮廓分析。
在前面的示例中,仅使用直到第二阶的矩来计算简单的对象特征。 为了更精确地描述复杂的对象,应使用高阶矩或更复杂的矩(例如 Zernike,Legendre)。 从这个意义上说,对象越复杂,应该计算出矩的阶次越高,以最小化从矩重构对象的误差。 有关更多信息,请参见《通过矩的简单图像分析》。
为了完成本节,还对脚本contours_ellipses.py进行了编码。 在此脚本中,我们首先构建要使用的图像。 在这种情况下,图像中会绘制不同的椭圆。 这是通过build_image_ellipses()执行的。 在这种情况下,使用 OpenCV 函数cv2.ellipse()绘制了六个椭圆。 之后,在阈值图像中检测绘制的椭圆的轮廓,并计算一些特征。 更具体地,计算圆度和偏心度。 在结果图像中,仅显示了偏心率。
在下一个屏幕截图中,可以看到此脚本的输出。 如您所见,偏心率值绘制在每个轮廓的质心的中心。 此功能通过函数get_position_to_draw()执行:
def get_position_to_draw(text, point, font_face, font_scale, thickness):
"""Gives the coordinates to draw centered"""
text_size = cv2.getTextSize(text, font_face, font_scale, thickness)[0]
text_x = point[0] - text_size[0] / 2
text_y = point[1] + text_size[1] / 2
return round(text_x), round(text_y)
此函数返回x,y坐标以绘制point为中心的位置text,并绘制text的特定特征,这些特征对于计算[ text size-字体由参数font_face设置,字体比例由参数font_scale设置,粗细由参数thickness设置。
下一个屏幕截图中可以看到此脚本的输出:

可以看出,显示了使用上述函数eccentricity_from_moments()计算的偏心率。 应该注意的是,我们已经使用两个提供的公式计算了偏心率,获得了非常相似的结果。
胡矩不变量
胡矩不变量相对于平移,缩放和旋转是不变的,并且所有矩(第七个矩除外)对于反射都是不变的。 在第七种情况下,符号已通过反射进行了更改,从而使其能够区分图像。 OpenCV 提供cv2.HuMoments()来计算七个胡矩不变量。
此方法的签名如下:
cv2.HuMoments(m[, hu]) → hu
在此,m对应于使用cv2.moments()计算的矩。 输出hu对应于七个胡矩不变量。
七个胡矩不变量定义如下:
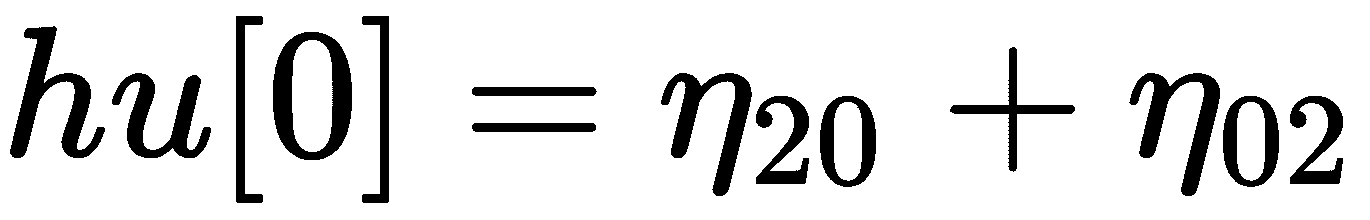





η[ji]代表nu[ji]。
在contours_hu_moments.py脚本中,计算了七个胡矩不变量。 如前所述,我们必须首先使用cv2.moments()计算矩。 为了计算矩,该参数可以既是向量形状又是图像。 此外,如果binaryImage参数为true(仅用于图像),则输入图像中的所有非零像素将被视为 1。 在此脚本中,我们同时使用向量形状和图像来计算弯矩。 最后,利用计算出的矩,我们将计算出胡矩不变性。
接下来说明键码。 我们首先加载图像,将其转换为灰度,然后应用cv2.threshold()获得二进制图像:
# Load the image and convert it to grayscale:
image = cv2.imread("shape_features.png")
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply cv2.threshold() to get a binary image
ret, thresh = cv2.threshold(gray_image, 70, 255, cv2.THRESH_BINARY)
在这一点上,我们通过使用阈值图像来计算矩。 之后,计算质心,最后计算出胡矩不变量:
# Compute moments:
M = cv2.moments(thresh, True)
print("moments: '{}'".format(M))
# Calculate the centroid of the contour based on moments:
x, y = centroid(M)
# Compute Hu moments:
HuM = cv2.HuMoments(M)
print("Hu moments: '{}'".format(HuM))
现在,我们重复该过程,但是在这种情况下,将传递轮廓而不是二进制图像。 因此,我们首先计算二进制图像中轮廓的坐标:
# Find contours
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# Compute moments:
M2 = cv2.moments(contours[0])
print("moments: '{}'".format(M2))
# Calculate the centroid of the contour based on moments:
x2, y2 = centroid(M2)
# Compute Hu moments:
HuM2 = cv2.HuMoments(M2)
print("Hu moments: '{}'".format(HuM2))
最后,质心显示如下:
print("('x','y'): ('{}','{}')".format(x, y))
print("('x2','y2'): ('{}','{}')".format(x2, y2))
如您所见,计算出的矩,胡矩不变性和质心非常相似,但并不相同。 例如,获得的质心如下:
('x','y'): ('613','271')
('x2','y2'): ('613','270')
如您所见,y坐标相差一个像素。 这样做的原因是光栅分辨率有限。 为轮廓估计的矩与为相同栅格化轮廓计算的矩略有不同。 在下一个屏幕截图中可以看到此脚本的输出,其中显示了两个质心,以突出显示y坐标中的这一小差异:

在contours_hu_moments_properties.py中,我们加载了三个图像。 第一个是原始的。 第二个与原件相对应,但旋转了 180 度。 第三个对应于原件的垂直反射。 这可以在脚本的输出中看到。 此外,我们打印从上述三个图像得出的计算得出的胡矩不变量。
该脚本的第一步是使用cv2.imread()加载图像,并使用cv2.cvtColor()将其转换为灰度。 第二步是应用cv2.threshold()获得二进制图像。 最后,使用cv2.HuMoments()计算胡矩:
# Load the images (cv2.imread()) and convert them to grayscale (cv2.cvtColor()):
image_1 = cv2.imread("shape_features.png")
image_2 = cv2.imread("shape_features_rotation.png")
image_3 = cv2.imread("shape_features_reflection.png")
gray_image_1 = cv2.cvtColor(image_1, cv2.COLOR_BGR2GRAY)
gray_image_2 = cv2.cvtColor(image_2, cv2.COLOR_BGR2GRAY)
gray_image_3 = cv2.cvtColor(image_3, cv2.COLOR_BGR2GRAY)
# Apply cv2.threshold() to get a binary image:
ret_1, thresh_1 = cv2.threshold(gray_image_1, 70, 255, cv2.THRESH_BINARY)
ret_2, thresh_2 = cv2.threshold(gray_image_2, 70, 255, cv2.THRESH_BINARY)
ret_2, thresh_3 = cv2.threshold(gray_image_3, 70, 255, cv2.THRESH_BINARY)
# Compute Hu moments cv2.HuMoments():
HuM_1 = cv2.HuMoments(cv2.moments(thresh_1, True)).flatten()
HuM_2 = cv2.HuMoments(cv2.moments(thresh_2, True)).flatten()
HuM_3 = cv2.HuMoments(cv2.moments(thresh_3, True)).flatten()
# Show calculated Hu moments for the three images:
print("Hu moments (original): '{}'".format(HuM_1))
print("Hu moments (rotation): '{}'".format(HuM_2))
print("Hu moments (reflection): '{}'".format(HuM_3))
# Plot the images:
show_img_with_matplotlib(image_1, "original", 1)
show_img_with_matplotlib(image_2, "rotation", 2)
show_img_with_matplotlib(image_3, "reflection", 3)
# Show the Figure:
plt.show()
计算出的色相矩不变性如下:
Hu moments (original): '[ 1.92801772e-01 1.01173781e-02 5.70258405e-05 1.96536742e-06 2.46949980e-12 -1.88337981e-07 2.06595472e-11]'
Hu moments (rotation): '[ 1.92801772e-01 1.01173781e-02 5.70258405e-05 1.96536742e-06 2.46949980e-12 -1.88337981e-07 2.06595472e-11]'
Hu moments (reflection): '[ 1.92801772e-01 1.01173781e-02 5.70258405e-05 1.96536742e-06 2.46949980e-12 -1.88337981e-07 -2.06595472e-11]'
您可以看到,除了第七种情况外,三种情况下计算出的胡矩不变性都相同。 在之前显示的输出中,此差异以粗体突出显示。 如您所见,符号已更改。
以下屏幕截图显示了用于计算胡矩不变性的三个图像:

Zernike 矩
自从引入胡矩以来,矩就已用于图像处理以及对象分类和识别。 从该出版物开始,已经开发了与矩有关的更强大的矩技术。
一个典型的例子是 Zernike 矩。 蒂格基于正交 Zernike 多项式的基础集提出了 Zernike 矩。 OpenCV 不提供计算 Zernike 矩的函数。 但是,其他 Python 包也可以用于此目的。
从这个意义上讲,mahotas包提供了zernike_moments()函数,该函数可用于计算 Zernike 矩。 zernike_moments()的签名如下:
mahotas.features.zernike_moments(im, radius, degree=8, cm={center_of_mass(im)})
此函数计算以cm为中心(如果不使用cm则为图像质心)的radius圆上的 Zernike 矩。 使用的最大程度由degree设置(默认为8)。
例如,如果使用默认值,则可以如下计算 Zernike 矩:
moments = mahotas.features.zernike_moments(image, 21)
在这种情况下,使用21的半径。 Zernike 矩特征向量具有 25 维。
与轮廓有关的更多函数
到目前为止,我们已经看到了一些来自图像矩的轮廓属性(例如,质心,面积,圆度或偏心距等)。 此外,OpenCV 提供了一些与轮廓有关的有趣功能,这些功能也可以用于进一步描述轮廓。
在contours_functionality.py中,我们主要使用五个与轮廓相关的 OpenCV 函数和一个计算给定轮廓的极值的函数。
在描述每个函数的计算结果之前,最好先显示此脚本的输出,因为生成的图像可以帮助我们理解上述每个函数:

cv2.boundingRect()返回包含轮廓的所有点的最小边界矩形:
x, y, w, h = cv2.boundingRect(contours[0])
cv2.minAreaRect()返回包含轮廓的所有点的最小旋转(如果需要)的矩形:
rotated_rect = cv2.minAreaRect(contours[0])
为了提取旋转矩形的四个点,可以使用cv2.boxPoints()函数,该函数返回旋转矩形的四个顶点:
box = cv2.boxPoints(rotated_rect)
cv2.minEnclosingCircle()返回包含轮廓的所有点的最小圆(它返回中心和半径):
(x, y), radius = cv2.minEnclosingCircle(contours[0])
cv2.fitEllipse()返回符合(具有最小的最小平方误差)轮廓的所有点的椭圆:
ellipse = cv2.fitEllipse(contours[0])
cv2.approxPolyDP()根据给定的精度返回给定轮廓的轮廓近似值。 此函数使用 Douglas-Peucker 算法。
epsilon参数确定精度,确定原始曲线与其近似之间的最大距离。 因此,所得轮廓是与给定轮廓相似的抽取轮廓,其点更少:
approx = cv2.approxPolyDP(contours[0], epsilon, True)
extreme_points()计算定义给定轮廓的四个极限点:
def extreme_points(contour):
"""Returns extreme points of the contour"""
index_min_x = contour[:, :, 0].argmin()
index_min_y = contour[:, :, 1].argmin()
index_max_x = contour[:, :, 0].argmax()
index_max_y = contour[:, :, 1].argmax()
extreme_left = tuple(contour[index_min_x][0])
extreme_right = tuple(contour[index_max_x][0])
extreme_top = tuple(contour[index_min_y][0])
extreme_bottom = tuple(contour[index_max_y][0])
return extreme_left, extreme_right, extreme_top, extreme_bottom
np.argmin()返回沿轴的最小值的索引。 在多次出现最小值的情况下,返回与第一次出现相对应的索引。 np.argmax()返回最大值的索引。 一旦计算出索引(例如index),我们将获得数组的相应组件(例如contour[index]-[[ 40 320]]),然后访问第一个组件(例如contour[index][0]-[ 40 320])。 最后,我们将其转换为元组(例如tuple(contour[index][0])-(40,320))。
如您所见,您可以以更紧凑的方式执行这些计算:
index_min_x = contour[:, :, 0].argmin()
extreme_left = tuple(contour[index_min_x][0])
该代码可以重写如下:
extreme_left = tuple(contour[contour[:, :, 0].argmin()][0])
过滤轮廓
在前面的部分中,我们已经看到了如何计算检测到的轮廓的大小。 可以根据图像矩或使用 OpenCV 函数cv2.contourArea()计算检测到的轮廓的大小。 在此示例中,我们将基于每个轮廓的计算大小对检测到的轮廓进行排序。
因此,sort_contours_size()函数是关键:
def sort_contours_size(cnts):
""" Sort contours based on the size"""
cnts_sizes = [cv2.contourArea(contour) for contour in cnts]
(cnts_sizes, cnts) = zip(*sorted(zip(cnts_sizes, cnts)))
return cnts_sizes, cnts
在解释该代码的功能之前,我们将介绍一些关键点。 *运算符可以与zip()结合使用以解压缩列表:
coordinate = ['x', 'y', 'z']
value = [5, 4, 3]
result = zip(coordinate, value)
print(list(result))
c, v = zip(*zip(coordinate, value))
print('c =', c)
print('v =', v)
输出如下:
[('x', 5), ('y', 4), ('z', 3)]
c = ('x', 'y', 'z')
v = (5, 4, 3)
让我们合并sorted函数:
coordinate = ['x', 'y', 'z']
value = [5, 4, 3]
print(sorted(zip(value, coordinate)))
c, v = zip(*sorted(zip(value, coordinate)))
print('c =', c)
print('v =', v)
输出如下:
[(3, 'z'), (4, 'y'), (5, 'x')]
c = (3, 4, 5)
v = ('z', 'y', 'x')
因此,sort_contours_size()函数根据尺寸对轮廓进行分类。 同样,脚本在轮廓的中心输出序号。 contours_sort_size.py的输出可以在下一个屏幕截图中看到:

如您所见,在屏幕截图的上部显示了原始图像,而在屏幕截图的下部显示了原始图像,以在每个轮廓的中心包括序号。
识别轮廓
我们先前已经介绍了cv2.approxPolyDP(),使用道格拉斯-皮克算法(Douglas-Peucker algorithm)可以用较少的点将一个轮廓与另一个轮廓近似。 此函数的关键参数是epsilon,它设置近似精度。 在contours_shape_recognition.py中,我们将使用cv2.approxPolyDP()来基于抽取的轮廓中检测到的顶点数量(例如三角形,正方形,矩形,五边形或六边形等)识别轮廓。 cv2.approxPolyDP()的输出)。 为了减少给定轮廓的点数,我们首先计算轮廓的周长。 基于周长,将建立epsilon参数。 这样,抽取的轮廓就不会缩放。 ε参数的计算如下:
epsilon = 0.03 * perimeter
常数0.03经过多次测试后建立。 例如,如果该常数较大(例如0.1),则ε参数也将较大,因此近似精度将降低。
这导致轮廓具有更少的点,并且获得了丢失的顶点。 因此,轮廓识别不正确,因为它基于检测到的顶点数。 另一方面,如果该常数较小(例如0.001),则ε参数也将较小,因此近似精度将增加,从而导致具有更多点的近似轮廓。 在这种情况下,轮廓的识别也被错误地执行,因为获得了错误的顶点。
下一个屏幕截图中可以看到contours_shape_recognition.py脚本的输出:
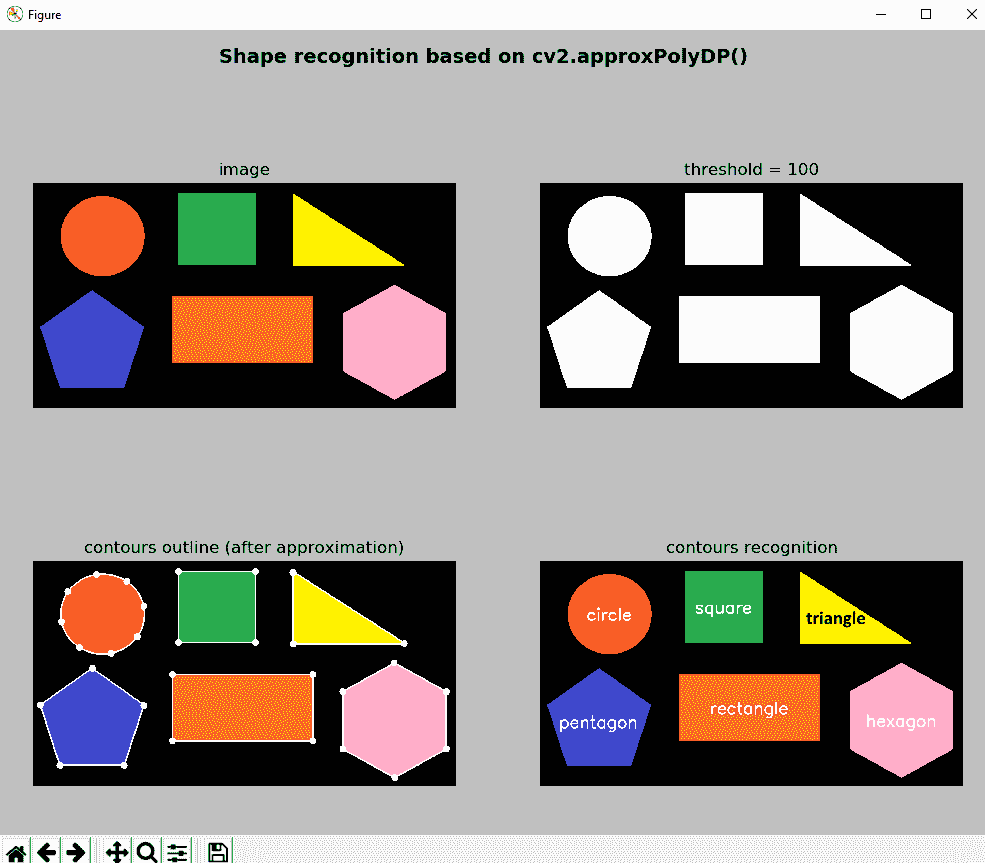
在上一个屏幕截图中,显示了关键步骤(阈值,轮廓近似和轮廓识别)。
匹配轮廓
胡矩不变量可用于对象匹配和识别。 在本节中,我们将了解如何基于胡矩不变性来匹配轮廓。 OpenCV 提供cv2.matchShapes(),可以使用三种比较方法来比较两个轮廓。 所有这些方法都使用胡矩不变式。 三种实现的方法是cv2.CONTOURS_MATCH_I1,cv2.CONTOURS_MATCH_I2和cv2.CONTOURS_MATCH_I3。
如果A表示第一个对象,B表示第二个对象,则以下条件适用:

 分别是
分别是A和B的胡矩。
最后,请参阅以下内容:
cv2.CONTOURS_MATCH_I1:
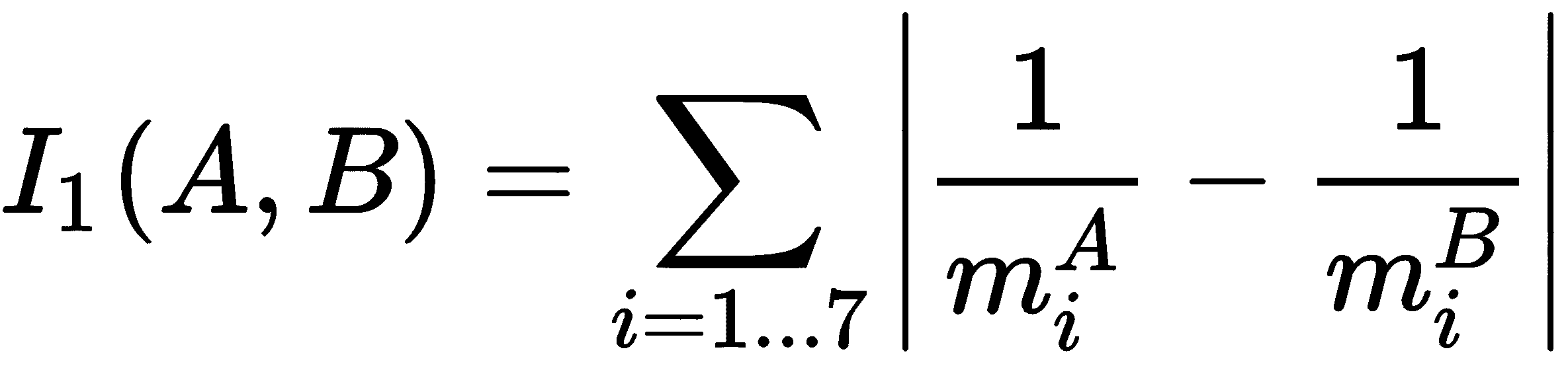
cv2.CONTOURS_MATCH_I2:
cv2.CONTOURS_MATCH_I3:

在contours_matching.py中,我们利用cv2.matchShapes()将几个轮廓与一个完美的圆轮廓匹配。
首先,我们使用 OpenCV 函数cv2.circle()在图像中绘制一个完美的圆。 这将是参考图像。 为了构建此图像,调用build_circle_image()。 然后,我们加载图像match_shapes.png,其中绘制了许多不同的形状。 一旦准备好两个图像,下一步就是在上述两个图像的每一个中找到轮廓:
- 使用
cv2.cvtColor()将其转换为灰度 - 使用
cv2.threshold()将其二值化 - 使用
cv2.findContours()查找轮廓
此时,我们准备将从match_shapes.png提取的所有轮廓与从使用build_circle_image()函数构建的图像中提取的轮廓进行比较:
for contour in contours:
# Compute the moment of contour:
M = cv2.moments(contour)
# The center or centroid can be calculated as follows:
cX = int(M['m10'] / M['m00'])
cY = int(M['m01'] / M['m00'])
# We match each contour against the circle contour using the three matching modes:
ret_1 = cv2.matchShapes(contours_circle[0], contour, cv2.CONTOURS_MATCH_I1, 0.0)
ret_2 = cv2.matchShapes(contours_circle[0], contour, cv2.CONTOURS_MATCH_I2, 0.0)
ret_3 = cv2.matchShapes(contours_circle[0], contour, cv2.CONTOURS_MATCH_I3, 0.0)
# Get the positions to draw:
(x_1, y_1) = get_position_to_draw(str(round(ret_1, 3)), (cX, cY), cv2.FONT_HERSHEY_SIMPLEX, 1.2, 3)
(x_2, y_2) = get_position_to_draw(str(round(ret_2, 3)), (cX, cY), cv2.FONT_HERSHEY_SIMPLEX, 1.2, 3)
(x_3, y_3) = get_position_to_draw(str(round(ret_3, 3)), (cX, cY), cv2.FONT_HERSHEY_SIMPLEX, 1.2, 3)
# Write the obtainted scores in the result images:
cv2.putText(result_1, str(round(ret_1, 3)), (x_1, y_1), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (255, 0, 0), 3)
cv2.putText(result_2, str(round(ret_2, 3)), (x_2, y_2), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 3)
cv2.putText(result_3, str(round(ret_3, 3)), (x_3, y_3), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3)
在以下屏幕截图中可以看到contours_matching.py脚本的输出:

可以看出,图像result_1使用匹配模式cv2.CONTOURS_MATCH_I1显示匹配分数,图像result_2使用匹配模式cv2.CONTOURS_MATCH_I2显示匹配分数,最后result_3使用匹配模式result_3显示匹配分数result_1 cv2.CONTOURS_MATCH_I3。
总结
在本章中,我们回顾了 OpenCV 提供的与轮廓相关的主要功能。 此外,在比较和描述轮廓时,我们还编写了一些有用的函数。 此外,我们还提供了一些有趣的功能,这些功能在调试代码时很有用。 从这个意义上讲,提供了用于创建缩小轮廓和创建具有简单形状的图像的函数。 在本章中,我们完成了与图像处理技术有关的四章-第 5 章,“图像处理技术”,回顾了图像处理的关键点; 第 6 章,“构造和构建直方图”,介绍了直方图; 第 7 章,“阈值技术”涵盖了阈值技术; 最后,在本章中,我们解释了如何处理轮廓。
在下一章中,我们将提供对增强现实的介绍,这是当前最热门的趋势之一,可以定义为增强的现实版本,通过叠加计算机生成的元素可以增强对现实世界的看法。
问题
- 如果要检测二进制图像中的轮廓,应该使用什么函数?
- OpenCV 提供哪些四个标志来压缩轮廓?
- OpenCV 提供什么函数来计算图像矩?
- 什么矩提供轮廓的大小?
- OpenCV 提供什么函数来计算七个胡矩不变量?
- 如果要获得给定轮廓的轮廓近似值,应该使用什么函数?
- 如本章所述,可以以更紧凑的方式覆盖
contour_functionality.py脚本中定义的extreme_points()函数。 因此,请相应地覆盖它。 - 如果要使用胡矩不变量作为特征来匹配轮廓,应该使用什么函数?
进一步阅读
以下参考资料将帮助您更深入地研究轮廓和其他图像处理技术:
九、增强现实
增强现实是目前最热门的趋势之一。 增强现实的概念可以定义为现实的改进版本,其中通过叠加的计算机生成元素(例如,图像,视频或 3D 模型等)增强对现实世界的看法。 为了覆盖和集成数字信息(增强现实),可以使用不同类型的技术,主要是基于位置的方法和基于识别的方法。
在本章中,我们将介绍与增强现实相关的主要概念,还将对一些有趣的应用进行编码,以了解该技术的潜力。 在本章中,您将学习如何构建第一个增强现实应用。 在本章的最后,您将掌握使用 OpenCV 创建增强现实应用的知识。
本章的主要部分如下:
- 增强现实简介
- 基于无标记的增强现实
- 基于标记的增强现实
- 基于 Snapchat 的增强现实
- QR 码检测
技术要求
技术要求在这里列出:
- Python 和 OpenCV
- 特定于 Python 的 IDE
- NumPy 和 Matplotlib 包
- Git 客户端
有关如何安装这些要求的更多详细信息,请参见第 1 章,“设置 OpenCV”。
《精通 Python OpenCV 4》的 GitHub 存储库,包含从第一章到最后一章的所有本书所需的支持项目文件,可以在下一个 URL 中访问。
增强现实简介
基于位置和基于识别的增强现实是增强现实的两种主要类型。 两种类型都尝试得出用户正在寻找的位置。 该信息是增强现实过程中的关键,并且依赖于正确计算相机姿态估计。 为了完成此任务,以下简要描述了两种类型:
- 基于位置的增强现实依赖于通过从多个传感器中读取数据来检测用户的位置和方向,这些传感器在智能手机设备中非常常见(例如 GPS,数字罗盘和加速度计),以得出正在搜索的用户的位置。 此信息用于在屏幕上叠加计算机生成的元素。
- 另一方面,基于识别的增强现实使用图像处理技术来推导用户正在看的地方。 从图像获得照相机姿势需要找到环境中的已知点与其对应的照相机投影之间的对应关系。 为了找到这些对应关系,可以在文献中找到两种主要方法:
- 基于标记的姿势估计:此方法依赖于使用平面标记(基于方形标记的标记已经获得普及,尤其是在增强现实领域),从四个角计算相机姿势。 使用正方形标记的一个主要缺点是与相机姿态的计算有关,这取决于对标记的四个角的精确确定。 在阻塞的情况下,该任务可能非常困难。 但是,一些基于标记检测的方法也可以很好地处理遮挡。 ArUco 就是这种情况。
- 基于无标记的姿势估计:当无法使用标记来准备场景以导出姿势估计时,可以将图像中自然存在的对象用于姿势估计。 一旦计算出一组
n个 2D 点及其对应的 3D 坐标,就可以通过求解透视 N 点(PnP)问题。 由于这些方法依赖于点匹配技术,因此很少会排除输入数据的异常值。 这就是为什么可以在姿态估计过程中使用针对异常值的强大技术(例如 RANSAC)的原因。
在下一个屏幕截图中,结合图像处理技术显示了上述两种方法(基于标记的和基于无标记的增强现实):
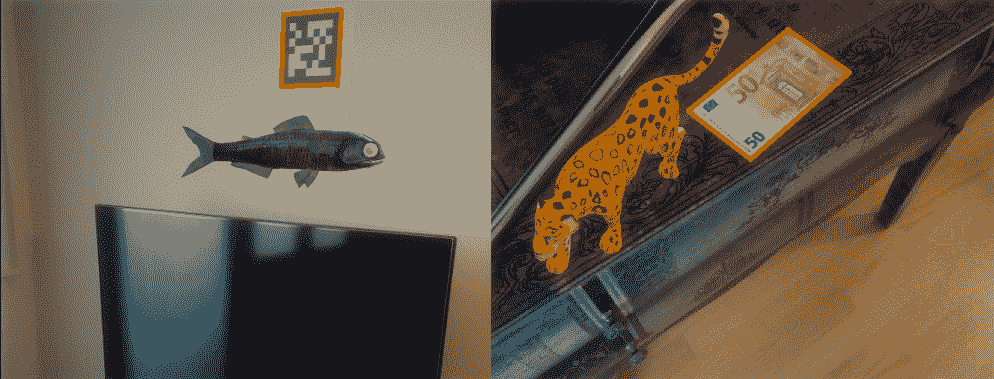
在前面的屏幕快照的左侧,您可以看到一个基于标记的方法的示例,该标记用于从四个角计算摄像机的姿势。 此外,在右侧,您可以看到基于无标记方法的示例,其中 50 欧元的钞票用于计算相机姿态。 以下各节将说明这两种方法。
基于无标记的增强现实
如前所述,可以从图像中得出相机姿态估计值,以找到环境中已知点与其相机投影之间的对应关系。 在本节中,我们将看到如何从图像中提取特征以导出相机姿势。 基于这些特征及其匹配,我们将看到如何最终得出相机姿态估计,然后将其用于覆盖和整合数字信息。
特征检测
可以将特征描述为图像中的一个小块,这对于图像缩放,旋转和照明是不变的(尽可能多)。 这样,可以从具有不同视角的同一场景的不同图像中检测到同一特征。 因此,一个好的特征应该是:
- 可重复且精确(应从同一对象的不同图像中提取相同特征)
- 区别于图像(具有不同结构的图像将不具有此特征)
OpenCV 提供了许多算法和技术来检测图像中的特征。 其中包括:
- 哈里斯角点检测
- Shi-Tomasi 角点检测
- 尺度不变特征变换(SIFT)
- 加速鲁棒特征(SURF)
- 来自加速段测试的特征(FAST)
- 二进制鲁棒独立基本特征(BRIEF)
- 定向的 FAST 和旋转的 BRIEF(ORB)
在feature_detection.py脚本中,我们将使用 ORB 进行图像中的特征检测和描述。 该算法来自 OpenCV Labs,在出版物《ORB:SIFT 或 SURF 的有效替代品》(2011)中进行了描述。 ORB 基本上是 FAST 关键点检测器和 BRIEF 描述符的组合,并进行了关键修改以增强表现。 第一步是检测keypoints。
ORB 使用修改后的FAST-9(带有radius = 9像素的圆圈,并存储检测到的keypoints的方向)来检测keypoints(默认情况下为500)。 一旦检测到keypoints,下一步就是计算描述符,以获得与每个检测到的关键点相关的信息。 ORB 使用修改的BRIEF-32描述符获取每个检测到的关键点的描述。 例如,检测到的keypoints的描述符如下所示:
[103 4 111 192 86 239 107 66 141 117 255 138 81 92 62 101 123 148 91 62 3 177 61 205 31 12 129 68 165 203 116 116]
因此,第一点是创建 ORB 检测器:
orb = cv2.ORB_create()
下一步是检测已加载图像中的keypoints:
keypoints = orb.detect(image, None)
一旦检测到keypoints,下一步就是计算检测到的keypoints的描述符:
keypoints, descriptors = orb.compute(image, keypoints)
注意,您还可以执行orb.detectAndCompute(image, None)来检测keypoints并计算检测到的keypoints的描述符。 最后,我们可以使用cv2.drawKeypoints()函数绘制检测到的keypoints:
image_keypoints = cv2.drawKeypoints(image, keypoints, None, color=(255, 0, 255), flags=0)
下一个屏幕截图中可以看到此脚本的输出:

可以看出,右边的结果显示了 ORB 关键点检测器已检测到的 ORB 检测关键点。
特征匹配
在下一个示例中,我们将看到如何匹配检测到的特征。 OpenCV 提供了两个匹配器,如下所示:
- 暴力(BF)匹配器:此匹配器采用为第一个集合中每个检测到的特征计算的每个描述符,以及第二组中的所有其他描述符,并对其进行匹配。 最后,它返回距离最近的匹配项。
- 近似最近邻的快速库(FLANN)匹配器:对于大型数据集,此匹配器比 BF 匹配器工作更快。 它包含用于最近邻搜索的优化算法。
在feature_matching.py脚本中,我们将使用 BF 匹配器来查看如何匹配检测到的特征。 因此,第一步是要检测keypoints并计算描述符:
orb = cv2.ORB_create()
keypoints_1, descriptors_1 = orb.detectAndCompute(image_query, None)
keypoints_2, descriptors_2 = orb.detectAndCompute(image_scene, None)
下一步是使用cv2.BFMatcher()创建 BF 匹配器对象:
bf_matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
第一个参数normType将距离测量默认设置为使用cv2.NORM_L2。 在使用 ORB 描述符(或其他基于二进制的描述符,例如 Brief 或 BRISK)的情况下,要使用的距离度量为cv2.NORM_HAMMING。 可以将第二个参数crossCheck(默认情况下为False)设置为True,以便在匹配过程中仅返回一致的对(两组中的两个特征应相互匹配)。 创建完成后,下一步就是使用BFMatcher.match()方法匹配检测到的描述符:
bf_matches = bf_matcher.match(descriptors_1, descriptors_2)
descriptors_1和descriptors_2是应该预先计算的描述符; 这样,我们可以在两张图像中获得最佳匹配。 此时,我们可以按距离的升序对匹配项进行排序:
bf_matches = sorted(bf_matches, key=lambda x: x.distance)
最后,我们可以使用cv2.drawMatches()函数绘制匹配项。 在这种情况下,仅显示前20个匹配项(出于可见性考虑):
result = cv2.drawMatches(image_query, keypoints_1, image_scene, keypoints_2, bf_matches[:20], None, matchColor=(255, 255, 0), singlePointColor=(255, 0, 255), flags=0)
cv2.drawMatches()函数水平连接两个图像,并从显示匹配的第一张图像到第二张图像绘制线条。
下一个屏幕截图中可以看到feature_matching.py脚本的输出:

如您在上一个屏幕截图中所见,绘制了两个图像(image_query,image_scene)之间的匹配。
用于查找对象的特征匹配和单应性计算
为了完成本节,我们将看到查找对象的最后一步。 一旦特征匹配,下一步就是使用cv2.findHomography()函数在两个图像中匹配的keypoints的位置之间找到透视变换。
OpenCV 提供了几种计算单应性矩阵的方法-RANSAC,最低中位数(LMEDS)和 PROSAC(RHO)。 在此示例中,我们使用RANSAC,如下所示:
M, mask = cv2.findHomography(pts_src, pts_dst, cv2.RANSAC, 5.0)
这里,pts_src是源图像中匹配的关键点的位置,pts_dst是查询图像中匹配的keypoints的位置。
第四个参数ransacReprojThreshold设置最大重投影误差,以将一个点对视为一个惯常值。 在这种情况下,如果重投影误差大于5.0,则将相应的点对视为异常值。 此函数计算并返回由keypoints位置定义的源平面和目标平面之间的透视变换矩阵M。
最后,基于透视变换矩阵M,我们将计算查询图像中对象的四个角。 为此,我们将基于原始图像的形状计算其四个角,然后使用cv2.perspectiveTransform()函数将其转换为目标角:
pts_corners_dst = cv2.perspectiveTransform(pts_corners_src, M)
这里,pts_corners_src包含原始图像的四个角,M是透视变换矩阵; pts_corners_dst输出包含查询图像中对象的四个角。 我们可以使用cv2.polyline()函数绘制检测到的物体的轮廓:
img_obj = cv2.polylines(image_scene, [np.int32(pts_corners_dst)], True, (0, 255, 255), 10)
最后,我们还可以使用cv2.drawMatches()函数绘制匹配,如下所示:
img_matching = cv2.drawMatches(image_query, keypoints_1, img_obj, keypoints_2, best_matches, None, matchColor=(255, 255, 0), singlePointColor=(255, 0, 255), flags=0)
下一个屏幕截图中可以看到feature_matching_object_recognition.py脚本的输出:

在前面的屏幕截图中,您可以看到特征匹配和单应性计算,这是对象识别的两个关键步骤。
基于标记的增强现实
在本节中,我们将了解基于标记的增强现实的工作原理。 您可以使用许多库,算法或包来生成和检测标记。 从这个意义上说,提供最先进的检测标记表现的是 ArUco。
ArUco 自动检测标记并纠正可能的错误。 此外,ArUco 通过将多个标记与通过颜色分割计算的遮挡遮罩相结合,提出了一种遮挡问题的解决方案。
如前所述,姿势估计是增强现实应用中的关键过程。 可以基于标记执行姿势估计。 使用标记的主要好处是可以在可以精确得出标记的四个角的图像中高效且鲁棒地检测到它们。 最后,可以从先前计算出的标记的四个角获得相机姿态。 因此,在接下来的小节中,我们将从创建标记和字典开始,了解如何创建基于标记的增强现实应用。
创建标记和字典
使用 ArUco 的第一步是创建标记和字典。 首先, ArUco 标记是由外部和内部单元(也称为位)组成的正方形标记。 外部单元设置为黑色,从而可以快速,可靠地检测到外部边界。 其余的单元(内部单元)用于编码标记。 还可以创建具有不同大小的 ArUco 标记。 标记的大小指示与内部矩阵相关的内部单元数。 例如,5 x 5(n=5)的标记大小由 25 个内部单元组成。 此外,您还可以设置标记边界中的位数。
其次,标记字典是被认为在特定应用中使用的标记集。 虽然以前的库仅考虑固定字典,但 ArUco 提出了一种自动方法,用于生成具有所需数量和位数的标记。 从这个意义上讲,ArUco 包括一些预定义的词典,涵盖了与标记数量和标记大小有关的许多配置。
创建基于标记的增强现实应用时要考虑的第一步是打印要使用的标记。
在aruco_create_markers.py脚本中,我们正在创建一些准备打印的标记。 第一步是创建字典对象。 ArUco 具有一些预定义的字典:DICT_4X4_50 = 0,DICT_4X4_100 = 1,DICT_4X4_250 = 2,DICT_4X4_1000 = 3,DICT_5X5_50 = 4,DICT_5X5_100 = 5,DICT_5X5_250 = 6,DICT_5X5_1000 = 7,DICT_6X6_50 = 8,DICT_6X6_100 = 9,DICT_6X6_250 = 10, DICT_6X6_1000 = 11,DICT_7X7_50 = 12,DICT_7X7_100 = 13,DICT_7X7_250 = 14和DICT_7X7_1000 = 15。
在这种情况下,我们将使用由250标记组成的cv2.aruco.Dictionary_get()函数创建字典。 每个标记的大小为7 x 7(n=7):
aruco_dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
此时,可以使用cv2.aruco.drawMarker()函数绘制标记,该函数返回准备打印的标记。 cv2.aruco.drawMarker()的第一个参数是dictionary对象。 第二个参数是标记id,其范围在0和249之间,因为我们的词典中包含250标记。 第三个参数sidePixels是创建的标记图像的大小(以像素为单位)。 第四个参数(可选,默认为1)为borderBits,它设置标记边界中的位数。
因此,在此示例中,我们将创建三个标记,这些标记会改变标记边界中的位数:
aruco_marker_1 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=1)
aruco_marker_2 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=2)
aruco_marker_3 = cv2.aruco.drawMarker(dictionary=aruco_dictionary, id=2, sidePixels=600, borderBits=3)
这些标记图像可以保存在磁盘上(使用cv2.imwrite()):
cv2.imwrite("marker_DICT_7X7_250_600_1.png", aruco_marker_1)
cv2.imwrite("marker_DICT_7X7_250_600_2.png", aruco_marker_2)
cv2.imwrite("marker_DICT_7X7_250_600_3.png", aruco_marker_3)
在aruco_create_markers.py脚本中,我们还显示了创建的标记。 输出可以在下一个屏幕截图中看到:
在前面的屏幕截图中,显示了三个创建的标记。
检测标记
您可以使用cv2.aruco.detectMarkers()函数来检测图像中的标记:
corners, ids, rejected_corners = cv2.aruco.detectMarkers(gray_frame, aruco_dictionary, parameters=parameters)
cv2.aruco.detectMarkers()的第一个参数是要在其中检测标记的灰度图像。 第二个参数是字典对象,它应该先前已经创建。 第三个参数建立了在检测过程中可以自定义的所有参数。 此函数返回以下信息:
- 返回检测到的标记的角列表。 对于每个标记,将返回其四个角(左上,右上,右下和左下)。
- 返回检测到的标记的标识符列表。
- 返回被拒绝的候选者列表,该列表由找到的所有正方形组成,但是它们没有正确的编码。 此拒绝候选者列表对于调试目的很有用。 每个被拒绝的候选人都由其四个角组成。
aruco_detect_markers.py脚本从网络摄像头检测标记。 首先,使用上述cv2.aruco.detectMarkers()函数检测标记,然后,使用cv2.aruco.drawDetectedMarkers()函数绘制检测到的标记和拒绝的候选者,如下所示:
# Draw detected markers:
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=corners, ids=ids, borderColor=(0, 255, 0))
# Draw rejected markers:
frame = cv2.aruco.drawDetectedMarkers(image=frame, corners=rejected_corners, borderColor=(0, 0, 255))
如果执行aruco_detect_markers.py脚本,检测到的标记将以绿色边框绘制,而被拒绝的候选者将以红色边框绘制,如以下屏幕截图所示:

在前面的屏幕截图中,您可以看到检测到一个标记(带有id=2),该标记以绿色边框绘制。 此外,您还可以看到两个带有红色边框的被拒绝候选人。
相机校准
在使用检测到的标记获取相机姿态之前,有必要了解相机的校准参数。 从这个意义上讲,ArUco 提供了执行此任务所需的校准程序。 请注意,校准过程仅执行一次,因为未更改相机光学器件。 校准过程中使用的主要函数是cv2.aruco.calibrateCameraCharuco()。
前述函数使用从板上提取的几个视图中的一组角来校准摄像机。 校准过程完成后,此函数返回相机矩阵(3 x 3浮点相机矩阵)和包含失真系数的向量。 更具体地说,3 x 3矩阵对焦距和相机中心坐标(也称为固有参数)进行编码。 失真系数模拟了相机产生的失真。
该函数的签名如下:
calibrateCameraCharuco(charucoCorners, charucoIds, board, imageSize, cameraMatrix, distCoeffs[, rvecs[, tvecs[, flags[, criteria]]]]) -> retval, cameraMatrix, distCoeffs, rvecs, tvecs
此处,charucoCorners是包含检测到的 charuco 角的向量,charucoIds是标识符的列表,board代表电路板布局,imageSize是输入图像尺寸。 输出向量rvecs包含为每个板视图估计的旋转向量的向量,tvecs是为每个图案视图估计的平移向量的向量。 如前所述,相机矩阵cameraMatrix和失真系数distCoeffs也将返回。
该板是使用cv2.aruco.CharucoBoard_create()函数创建的:
签名如下:
CharucoBoard_create(squaresX, squaresY, squareLength, markerLength, dictionary) -> retval
此处,squareX是在x方向上的平方数,squaresY是在y方向上的平方数,squareLength是棋盘方边的长度(通常 markerLength是标记的边长(与squareLength相同的单位),dictionary设置字典中要使用的第一个标记,以便在板上创建标记。 例如,为了创建一个木板,我们可以使用以下代码行:
dictionary = cv2.aruco.Dictionary_get(cv2.aruco.DICT_7X7_250)
board = cv2.aruco.CharucoBoard_create(3, 3, .025, .0125, dictionary)
img = board.draw((200 * 3, 200 * 3))
在下一个屏幕截图中可以看到创建的木板:

稍后,cv2.aruco.calibrateCameraCharuco()函数将在校准过程中使用此板:
cal = cv2.aruco.calibrateCameraCharuco(all_corners, all_ids, board, image_size, None, None)
校准过程完成后,我们会将相机矩阵和失真系数都保存到磁盘中。 为此,我们使用 Pickle,它可以用于对 Python 对象结构进行序列化和反序列化。
校准过程完成后,我们现在可以执行相机姿态估计。
aruco_camera_calibration.py脚本执行校准过程。 请注意,通过使用先前创建和印刷的电路板,此脚本可用于创建电路板和执行校准过程。
相机姿态估计
为了估计摄像机姿态,可以使用cv2.aruco.estimatePoseSingleMarkers()函数,该函数可以估计单个标记的姿态。 姿势由旋转和平移向量组成。 签名如下:
cv.aruco.estimatePoseSingleMarkers( corners, markerLength, cameraMatrix, distCoeffs[, rvecs[, tvecs[, _objPoints]]] ) -> rvecs, tvecs, _objPoints
这里,cameraMatrix和distCoeffs分别是相机矩阵和失真系数; 应向他们提供在校准过程之后获得的值。 corners参数是一个向量,其中包含每个检测到的标记的四个角。 markerLength参数是标记边的长度。 请注意,返回的翻译向量将以相同的单位表示。 此函数为每个检测到的标记返回rvecs(旋转向量),tvecs(平移向量)和_objPoints(所有检测到的标记角的对象点数组)。
标记坐标系以标记的中心为中心。 因此,标记的四个角的坐标(在其自己的坐标系中)如下:
(-markerLength/2, markerLength/2, 0)(markerLength/2, markerLength/2, 0)(markerLength/2, -markerLength/2, 0)(-markerLength/2, -markerLength/2, 0)
最后,ArUco 还提供cv.aruco.drawAxis()函数,该函数可用于绘制每个检测到的标记的系统轴。
签名如下:
cv.aruco.drawAxis( image, cameraMatrix, distCoeffs, rvec, tvec, length ) -> image
除length参数以外,所有参数先前都已在以前的函数中引入,该参数设置绘制轴的长度(与tvec相同的单位)。 下一个屏幕截图显示了脚本aruco_detect_markers_pose.py的输出:
在上一个屏幕截图中,您可以看到仅检测到一个标记,并且已绘制了该标记的系统轴。
相机姿态估计和基本增强
此时,我们可以叠加一些图像,形状或 3D 模型,以查看完整的增强现实应用。 在第一个示例中,我们将使用标记的大小覆盖一个矩形。 执行此功能的代码如下:
if ids is not None:
# rvecs and tvecs are the rotation and translation vectors respectively
rvecs, tvecs, _ = cv2.aruco.estimatePoseSingleMarkers(corners, 1, cameraMatrix, distCoeffs)
for rvec, tvec in zip(rvecs, tvecs):
# Define the points where you want the image to be overlaid (remember: marker coordinate system):
desired_points = np.float32(
[[-1 / 2, 1 / 2, 0], [1 / 2, 1 / 2, 0], [1 / 2, -1 / 2, 0], [-1 / 2, -1 / 2, 0]])
# Project the points:
projected_desired_points, jac = cv2.projectPoints(desired_points, rvecs, tvecs, cameraMatrix, distCoeffs)
# Draw the projected points:
draw_points(frame, projected_desired_points)
第一步是定义要覆盖图像或模型的点。 由于我们希望将矩形覆盖在检测到的标记上,因此这些坐标为[[-1 / 2, 1 / 2, 0], [1 / 2, 1 / 2, 0], [1 / 2, -1 / 2, 0], [-1 / 2, -1 / 2, 0]]。
请记住,我们必须在标记坐标系中定义这些坐标。 下一步是使用cv2.projectPoints()函数投影这些点:
projected_desired_points, jac = cv2.projectPoints(desired_points, rvecs, tvecs, cameraMatrix, distCoeffs)
最后,我们使用draw_points()函数绘制这些点:
def draw_points(img, pts):
""" Draw the points in the image"""
pts = np.int32(pts).reshape(-1, 2)
img = cv2.drawContours(img, [pts], -1, (255, 255, 0), -3)
for p in pts:
cv2.circle(img, (p[0], p[1]), 5, (255, 0, 255), -1)
return img
下一个屏幕截图中可以看到aruco_detect_markers_draw_square.py脚本的输出:

在前面的屏幕截图中,您可以看到一个青色矩形已覆盖在检测到的标记上。 此外,您还可以看到以洋红色绘制的矩形的四个角。
相机姿态估计和高级增强
可以轻松修改aruco_detect_markers_draw_square.py脚本,以覆盖更高级的增强功能。
在这种情况下,我们将覆盖一棵树的图像,可以在下一个屏幕截图中看到:

为了执行此扩充,我们对draw_augmented_overlay()函数进行了编码,如下所示:
def draw_augmented_overlay(pts_1, overlay_image, image):
"""Overlay the image 'overlay_image' onto the image 'image'"""
# Define the squares of the overlay_image image to be drawn:
pts_2 = np.float32([[0, 0], [overlay_image.shape[1], 0], [overlay_image.shape[1], overlay_image.shape[0]], [0, overlay_image.shape[0]]])
# Draw border to see the limits of the image:
cv2.rectangle(overlay_image, (0, 0), (overlay_image.shape[1], overlay_image.shape[0]), (255, 255, 0), 10)
# Create the transformation matrix:
M = cv2.getPerspectiveTransform(pts_2, pts_1)
# Transform the overlay_image image using the transformation matrix M:
dst_image = cv2.warpPerspective(overlay_image, M, (image.shape[1], image.shape[0]))
# cv2.imshow("dst_image", dst_image)
# Create the mask:
dst_image_gray = cv2.cvtColor(dst_image, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(dst_image_gray, 0, 255, cv2.THRESH_BINARY_INV)
# Compute bitwise conjunction using the calculated mask:
image_masked = cv2.bitwise_and(image, image, mask=mask)
# cv2.imshow("image_masked", image_masked)
# Add the two images to create the resulting image:
result = cv2.add(dst_image, image_masked)
return result
draw_augmented_overlay()函数首先定义叠加图像的正方形。 然后,计算变换矩阵,该变换矩阵用于变换覆盖图像以获得dst_image图像。 接下来,我们创建mask并使用先前创建的mask计算按位运算以获得image_masked图像。 最后一步是在dst_image和image_masked之间执行加法以获得result图像,最后将其返回。
下一个屏幕截图中可以看到aruco_detect_markers_augmented_reality.py脚本的输出:

为了覆盖更复杂和高级的 3D 模型,可以使用 OpenGL。 开放图形库(OpenGL)是用于渲染 2D 和 3D 模型的跨平台 API。
从这个意义上讲,PyOpenGL 是最常见且标准的跨平台 Python 绑定到 OpenGL。
基于 Snapchat 的增强现实
在本节中,我们将了解如何创建一些有趣的基于 Snapchat 的过滤器。 在这种情况下,我们将创建两个过滤器。 第一个在检测到的脸上的鼻子和嘴之间覆盖了一个大胡子。 第二个在检测到的面部上覆盖一副眼镜。
在以下小节中,您将看到如何实现此功能。
基于 Snapchat 的增强现实 OpenCV 胡须覆盖
在snapchat_augmeted_reality_moustache.py脚本中,我们在检测到的面部上覆盖了胡须。 从网络摄像头连续捕获图像。 我们还提供了使用测试图像代替从网络摄像头捕获的图像的可能性。 这对于调试算法很有用。 在解释此脚本的关键步骤之前,我们将看下一个屏幕截图,它是使用测试图像时算法的输出:

第一步是检测图像中的所有面部。 如您所见,青色矩形表示图像中检测到的脸部的位置和大小。 该算法的下一步是遍历图像中所有检测到的面部,在其区域内搜索鼻子。 洋红色矩形表示图像中检测到的鼻子。 一旦检测到鼻子,下一步就是调整要覆盖小胡子的区域,该区域是根据之前计算出的鼻子的位置和大小计算得出的。 在这种情况下,蓝色矩形表示将要覆盖胡须的位置。 您还可以看到图像中检测到两个鼻子,并且只有一个胡须覆盖。 这是因为执行基本检查是为了知道所检测到的鼻子是否有效。 一旦我们检测到有效的鼻子,小胡子就会被覆盖,如果离开我们会继续在检测到的面部上进行迭代,否则将分析另一帧。
因此,在此脚本中,面部和鼻子都被检测到。 为了检测这些对象,创建了两个分类器,一个用于检测人脸,另一个用于检测鼻子。 要创建这些分类器,以下代码是必需的:
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
nose_cascade = cv2.CascadeClassifier("haarcascade_mcs_nose.xml")
创建分类器后,下一步就是检测图像中的这些对象。 在这种情况下,将使用cv2.detectMultiScale()函数。 此函数检测输入灰度图像中大小不同的对象,并将检测到的对象作为矩形列表返回。 例如,为了检测面部,可以使用以下代码:
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
在这一点上,我们遍历检测到的面部,尝试检测鼻子:
# Iterate over each detected face:
for (x, y, w, h) in faces:
# Draw a rectangle to see the detected face (debugging purposes):
# cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2)
# Create the ROIS based on the size of the detected face:
roi_gray = gray[y:y + h, x:x + w]
roi_color = frame[y:y + h, x:x + w]
# Detects a nose inside the detected face:
noses = nose_cascade.detectMultiScale(roi_gray)
一旦检测到鼻子,我们将在所有检测到的鼻子上进行迭代,并计算出胡须覆盖的区域。 执行基本检查以滤除假鼻子位置。 如果成功,则胡子将基于先前计算的区域覆盖在图像上:
for (nx, ny, nw, nh) in noses:
# Draw a rectangle to see the detected nose (debugging purposes):
# cv2.rectangle(roi_color, (nx, ny), (nx + nw, ny + nh), (255, 0, 255), 2)
# Calculate the coordinates where the moustache will be placed:
x1 = int(nx - nw / 2)
x2 = int(nx + nw / 2 + nw)
y1 = int(ny + nh / 2 + nh / 8)
y2 = int(ny + nh + nh / 4 + nh / 6)
if x1 < 0 or x2 < 0 or x2 > w or y2 > h:
continue
# Draw a rectangle to see where the moustache will be placed (debugging purposes):
# cv2.rectangle(roi_color, (x1, y1), (x2, y2), (255, 0, 0), 2)
# Calculate the width and height of the image with the moustache:
img_moustache_res_width = int(x2 - x1)
img_moustache_res_height = int(y2 - y1)
# Resize the mask to be equal to the region were the glasses will be placed:
mask = cv2.resize(img_moustache_mask, (img_moustache_res_width, img_moustache_res_height))
mask_inv = cv2.bitwise_not(mask)
img = cv2.resize(img_moustache, (img_moustache_res_width, img_moustache_res_height))
# Take ROI from the BGR image:
roi = roi_color[y1:y2, x1:x2]
# Create ROI background and ROI foreground:
roi_bakground = cv2.bitwise_and(roi, roi, mask=mask_inv)
roi_foreground = cv2.bitwise_and(img, img, mask=mask)
# Show both roi_bakground and roi_foreground (debugging purposes):
# cv2.imshow('roi_bakground', roi_bakground)
# cv2.imshow('roi_foreground', roi_foreground)
# Add roi_bakground and roi_foreground to create the result:
res = cv2.add(roi_bakground, roi_foreground)
# Set res into the color ROI:
roi_color[y1:y2, x1:x2] = res
break
关键是img_moustache_mask图像。 使用要叠加的图像的 Alpha 通道创建此图像。
这样,将仅在图像中绘制覆盖图像的前景。 在以下屏幕截图中,您可以看到基于覆盖图像的 Alpha 通道创建的胡须遮罩:

要创建此掩码,我们执行以下操作:
img_moustache = cv2.imread('moustache.png', -1)
img_moustache_mask = img_moustache[:, :, 3]
下一个屏幕截图中可以看到snapchat_augmeted_reality_moustache.py脚本的输出:

以下屏幕快照中包含的所有胡须都可以在您的增强现实应用中使用:

实际上,我们还创建了moustaches.svg文件,其中包含了这六个不同的胡须。
基于 Snapchat 的增强现实 OpenCV 眼镜覆盖
以类似的方式,我们还对snapchat_agumeted_reality_glasses.py脚本进行了编码,以在检测到的面部的眼睛区域上覆盖一副眼镜。 在这种情况下,为了检测图像中的眼睛,使用了眼睛对检测器。
因此,应该相应地创建分类器:
eyepair_cascade = cv2.CascadeClassifier("haarcascade_mcs_eyepair_big.xml")
在下一个屏幕截图中,可以看到使用测试图像时算法的输出:

青色矩形表示图像中检测到的脸部的位置和大小。 洋红色矩形表示图像中检测到的眼睛对。 黄色矩形表示将要覆盖眼镜的位置,该位置是根据眼睛对区域的位置和大小计算得出的。 如您所见,已将某些透明度添加到眼镜覆盖的图像中,以使其更加逼真。
这也可以在眼镜图像遮罩中看到,该图像在下一个屏幕截图中显示:

下一个屏幕截图中可以看到snapchat_augmeted_reality_glasses.py脚本的输出:

所有这些眼镜可以在以下屏幕截图中看到:

最后,我们还创建了glasses.svg文件,其中包含六种不同的眼镜。 因此,您可以在增强现实应用中播放和使用所有这些眼镜。
QR 码检测
为了完成本章,我们将学习如何检测图像中的 QR 码。 这样,QR 码也可以用作我们的增强现实应用的标记。 cv2.detectAndDecode()函数可检测并解码包含 QR 码的图像中的 QR 码。 图像可以是灰度或彩色(BGR)。
该函数返回以下内容:
- 返回找到的 QR 码的顶点数组。 如果未找到 QR 码,则此数组可以为空。
- 已校正并二值化的 QR 码被返回。
- 返回与此 QR 码关联的数据。
在qr_code_scanner.py脚本中,我们利用上述函数来检测和解码 QR 码。 接下来重点说明要点。
首先,加载图像,如下所示:
image = cv2.imread("qrcode_rotate_45_image.png")
接下来,我们使用以下代码创建 QR 码检测器:
qr_code_detector = cv2.QRCodeDetector()
然后,我们应用cv2.detectAndDecode()函数,如下所示:
data, bbox, rectified_qr_code = qr_code_detector.detectAndDecode(image)
我们在解码数据之前检查是否找到 QR 码,并使用show_qr_detection()函数显示检测到的代码:
if len(data) > 0:
print("Decoded Data : {}".format(data))
show_qr_detection(image, bbox)
show_qr_detection()函数绘制检测到的 QR 码的线条和角点:
def show_qr_detection(img, pts):
"""Draws both the lines and corners based on the array of vertices of the found QR code"""
pts = np.int32(pts).reshape(-1, 2)
for j in range(pts.shape[0]):
cv2.line(img, tuple(pts[j]), tuple(pts[(j + 1) % pts.shape[0]]), (255, 0, 0), 5)
for j in range(pts.shape[0]):
cv2.circle(img, tuple(pts[j]), 10, (255, 0, 255), -1)
下一个屏幕截图中可以看到qr_code_scanner.py脚本的输出:

在前面的屏幕截图中,您可以看到经过校正和二值化的 QR 码(左)和检测到的标记(右),带有蓝色边框,洋红色正方形点突出显示检测结果。
总结
在本章中,我们介绍了增强现实技术的介绍。 我们编写了一些示例,以了解如何构建标记和无标记增强现实应用。 此外,我们看到了如何叠加简单的模型(形状或图像等)。
如前所述,要覆盖更复杂的模型,可以使用 PyOpenGL(Python 的标准 OpenGL 绑定)。 在本章中,为简化起见,未解决该库。
我们还看到了如何创建一些有趣的基于 Snapchat 的过滤器。 应当注意,在第 11 章,“人脸检测,跟踪和识别”中,将介绍用于人脸检测,跟踪和人脸标志定位的更高级算法。 因此,可以轻松修改本章中编码的基于 Snapchat 的过滤器,以包括更健壮的管道,以得出眼镜和胡须应重叠的位置。 最后,我们已经了解了如何检测 QR 码,可以将其用作增强现实应用中的标记。
在第 10 章,“使用 OpenCV 的机器学习”中,将向您介绍机器学习的世界,并且您将了解如何在计算机视觉项目中使用机器学习。
问题
- 初始化 ORB 检测器,找到
keypoints,并使用 ORB 在加载的图像image中计算描述符 - 画出先前检测到的
keypoints - 创建
BFMatcher对象,并匹配先前计算出的descriptors_1和descriptors_2 - 对之前计算出的匹配进行排序,并绘制第一个
20匹配 - 使用 ArUco 在
gray_frame图像中检测标记 - 使用 ArUco 绘制检测到的标记
- 使用 ArUco 绘制拒绝的标记
- 检测并解码图像
image中包含的 QR 码
进一步阅读
以下参考将帮助您更深入地了解增强现实: