作业①
(1)实验要求:爬取指定网站的所有图片,通过scrapy框架分别实现单线程和多线程实现
码云链接
主要代码展示
在items.py定义数据
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img = scrapy.Field()
pass
通过xpath爬取图片地址,并将数据传输到pipeline中
def parse(self, response):
# print(response.text)
imgs = response.xpath("//img/@src").extract() #获取图片地址
# print(imgs,type(imgs[0]))
for img in imgs:
pipe = WeatherItem() #创建传输通道
pipe['img'] = img
# print(img)
yield pipe #传输到管道
在pipeliny中导入scrapy框架中的ImagesPipeline用于图片下载。
from scrapy.pipelines.images import ImagesPipeline
定义一个管道imgsPipeLine,根据图片地址进行图片数据的请求,并指定图片存储的路径
class imgsPipeLine(ImagesPipeline):
#根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['img'])
#指定图片存储的路径
def file_path(self, request, response=None, info=None, *, item=None):
imgName=request.url.split('/')[-1]
return imgName
def item_completed(self, results, item, info):
return item#返回给下一个即将被执行的管道类
在settings中打开通道,并设置存储地址,并开启多线程(默认值为16)
# 开启多线程
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# 打开通道
ITEM_PIPELINES = {
# "weather.pipelines.WeatherPipeline": 300,
"weather.pipelines.imgsPipeLine": 300,
}
# 设置存储路径
MEDIA_ALLOW_REDIRECTS=True
IMAGES_STORE='./images'
下载图片显示
(2)心得体会
scrapy框架存在着自己的一套"体系",下载图片与存储数据与之前所学的有着很大的差距。完成本题后学会了如何利用scrapy框架下载图片以及开启多线程。
作业②
(1)实验要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法
码云链接
主要代码展示
在item.py中定义数据
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
name = scrapy.Field() #股票名字
stock_code = scrapy.Field() #股票代码
latest_offer = scrapy.Field() #最新报价
price_limit = scrapy.Field() #涨跌幅
pricer_range = scrapy.Field() #涨跌额
trading_volume = scrapy.Field() #成交量
trading_range = scrapy.Field() #成交额
a = scrapy.Field() #振幅
hightest = scrapy.Field() #最高
lowest = scrapy.Field() #最低
cost = scrapy.Field() #今开
comein = scrapy.Field() #昨收
pass
将所需要的数据改为json格式并提取出所需要的数据
#获取所需要得数据
start = response.text.find('(') + 1
end = response.text.rfind(')')
original_data = response.text[start:end]
#将数据转换为json格式
json_data = json.loads(original_data)
#获取所需要得数据
datas = json_data['data']['diff']
# print(datas,len(datas),type(datas))
stocks_list = []
tags = ['f12','f14','f2','f3','f4','f5','f6','f7','f15','f16','f17','f18'] #标签
#将数据存入二维数组中
for data in datas:
self.number += 1
list =[]
list.append(self.img_number)
for tag in tags:
list.append(data[tag])
self.img_number += 1
stocks_list.append(list)
将数据传输到管道中
#将数据传输给管道
for s in stocks_list:
# print(len(s[0]))
pipe = StockItem()
pipe['id'] = str(s[0])
pipe['stock_code'] = str(s[1])
pipe['name'] = str(s[2])
pipe['latest_offer'] = str(s[3])
pipe['price_limit'] = str(s[4])
pipe['pricer_range'] = str(s[5])
pipe['trading_volume'] = str(s[6])
pipe['trading_range'] = str(s[7])
pipe['a'] = str(s[8])
pipe['hightest'] = str(s[9])
pipe['lowest'] = str(s[10])
pipe['cost'] = str(s[11])
pipe['comein'] = str(s[12])
# print('**')
yield pipe
翻页处理以及设置爬取的股票数量限制
start_urls = [f"http://38.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406848566904145428_1697696179672&pn={i}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697696179673" for i in range(1,7)]
#翻页处理
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
# 117为学号后三位
if self.number > 117:
return
将数据存入数据库
def process_item(self, item, spider):
# print("***")
# 将数据插入数据库
args=[
item.get("id"),
item.get("stock_code"),
item.get("name"),
item.get("latest_offer"),
item.get("price_limit"),
item.get("pricer_range"),
item.get("trading_volume"),
item.get("trading_range"),
item.get("a"),
item.get("hightest"),
item.get("lowest"),
item.get("cost"),
item.get("comein"),
]
sql = "insert into stock_table values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# print('****')
# 执行语句
self.cursor.execute(sql,args)
# 提交
self.client.commit()
return item
数据结果展示
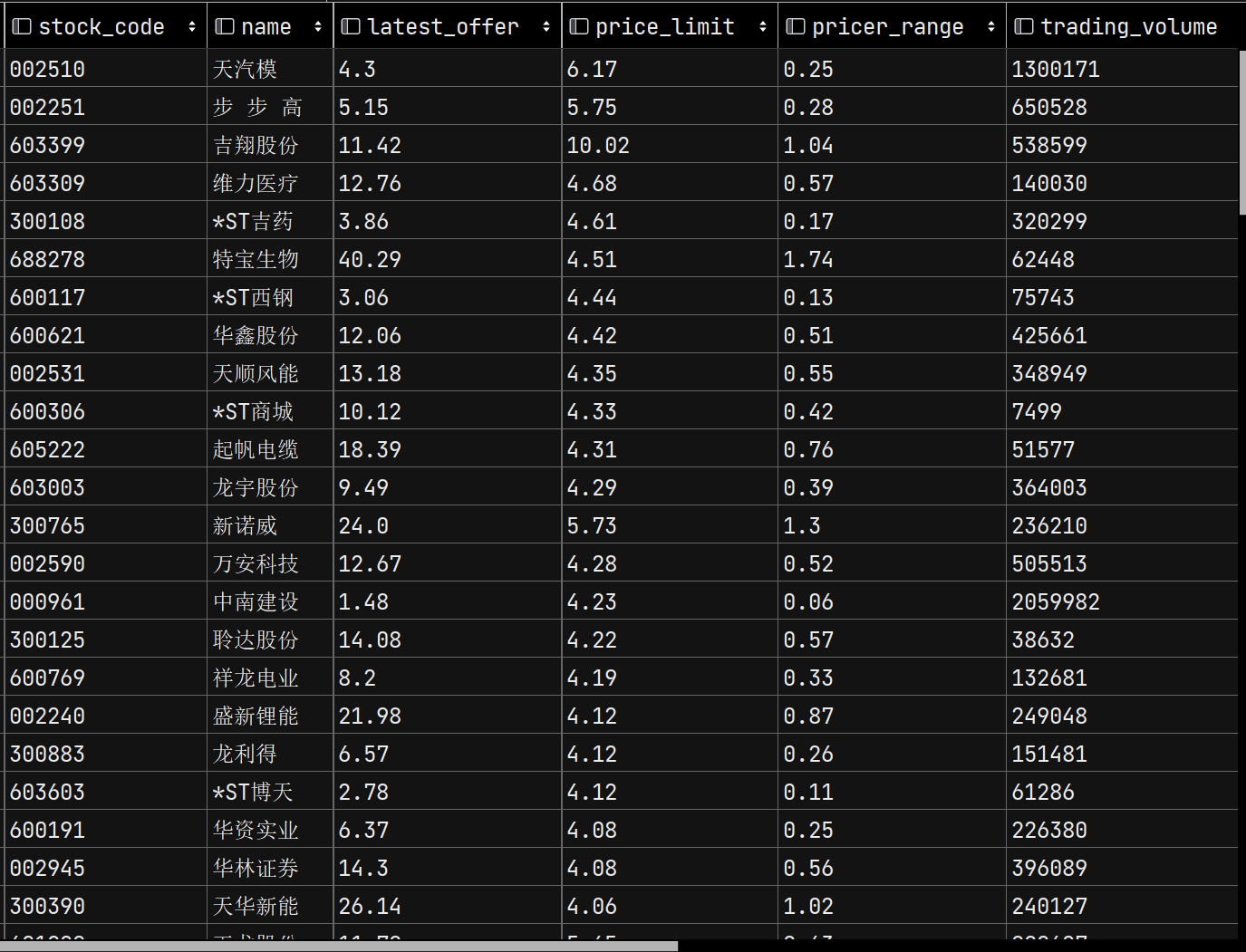
(2)心得体会
通过本次实验,学习了一种新的存数据库的方式,同时也了解到了如何进行翻页处理。由于本次网页是动态网页,一开始的时候使用xpath一直无法提取出所需要的数据,可以通过查看网页源代码中是否存在所需要的数据,若存在,则可以直接使用xpath进行数据爬取,反之采用json进行处理。
作业②
(1)实验要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法。使用scrapy框架+xpath+mysql数据库存储方式爬取外汇网站数量
码云链接
主要代码展示
在item.py中定义数据
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
pass
获取所需要的数据
def parse(self, response):
trs = response.xpath("//tr[position() > 1]")
# print(len(trs),type(trs))
bank_list =[]
for tr in trs:
list = []
# print(type(tr))
CURRENCY = tr.xpath(".//td[1]//text()").extract_first()
TBP = tr.xpath(".//td[2]//text()").extract_first()
CBP = tr.xpath(".//td[3]//text()").extract_first()
TSP = tr.xpath(".//td[4]//text()").extract_first()
CSP = tr.xpath(".//td[5]//text()").extract_first()
TIME = tr.xpath(".//td[7]//text()").extract_first()
list.extend((CURRENCY,TBP,CBP,TSP,CSP,TIME))
# print(list)
bank_list.append(list)
将数据传输到管道
for b in bank_list:
# print(b)
pipe = BankItem()
# print("**")
pipe['currency'] = str(b[0])
pipe['tbp'] = str(b[1])
pipe['cbp'] = str(b[2])
pipe['tsp'] = str(b[3])
pipe['csp'] = str(b[4])
pipe['time'] = str(b[5])
# print("*****")
yield pipe
将数据存到数据库中
def process_item(self, item, spider):
args = [
item.get("currency"),
item.get("tbp"),
item.get("cbp"),
item.get("tsp"),
item.get("csp"),
item.get("time"),
]
sql = "insert into bank_table values(%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,args)
self.client.commit()
return item
数据结果展示
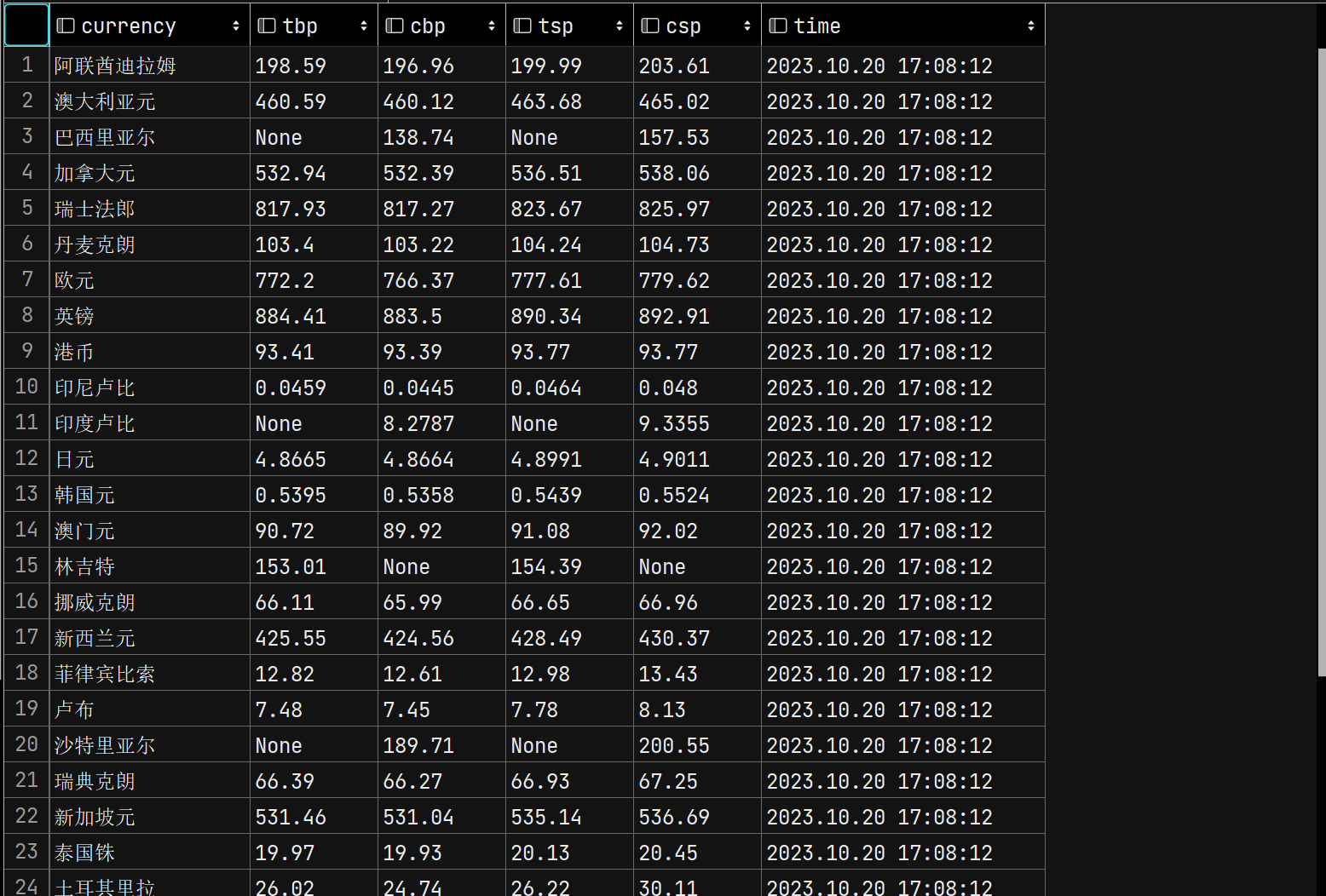
(2)心得体会
在进行数据提取的过程中,存在数据越界的情况,通过一步步调试发现,存在空值。因此采用每次爬取一个数据进行爬出,则空值会输出为None。便可以解决空值的情况。