论文标题:Bootstrapping Multi-view Representations for Fake News Detection
论文作者:Qichao Ying, Xiaoxiao Hu, Yangming Zhou, Zhenxing Qian, Dan Zeng, Shiming Ge
论文来源:AAAI 2023,Paper
代码来源:Code
介绍
基于深度学习的多模态虚假新闻检测(Fake News Detection, FND)一直饱受关注,本文发现以往关于多模态FND的研究仍未解决两个主要问题:
-
不同工作虽提出一系列复杂的特征提取和跨模态融合网络来从新闻中获取表征判断是否存在异常。然而,没有足够的机制保证每个模态提取的信息都能够被充分用于最终的新闻检测决策环节,也鲜有显式机制衡量不同模态信息对检测的直接贡献。
-
跨模态一致性(cross-modal consistency)(即研究图像的语义如何与文本对齐)在一些已有工作中被赋予过高权重,该因素与新闻真假程度的关联应被重新考虑,如图1所示。

图1:微博(左二)和GossipCop(右二)的假新闻检测BMR结果示例。“IP”(图像图案)、“IS”(图像语义)、“T”(文本)行分别为BMR提供的单视图预测结果,表示新闻中可疑的部分。“CC”这一行(跨模态一致性)显示了对跨模态一致性的预测,“Pred”这一行提供最终FND的预测结果。
本文的贡献
-
提出了一种新的假新闻检测方案,该方案生成多视图表示,给出了它们每个个体的重要性,并优化融合的特征。
-
提出一种新思路:通过单视图预测和跨模态一致性学习来解纠缠单模态和多模态特征中的信息,然后自适应地重新加权和自引导以更好地检测。
-
提出的BMR检测不仅在流行数据集上优于最先进的多模态FND方案,而且还提供了一种解释不同表示的贡献的机制。
方法
图2:BMR的网络架构。分别从文本视图、图像图案视图和图像语义视图中提取表征。改进的MMoE与单视图预测和跨模态一致性学习一起,共同指导单模态特征优化和跨模态特征生成。最终决定是在引导这些多视图表示时做出的。
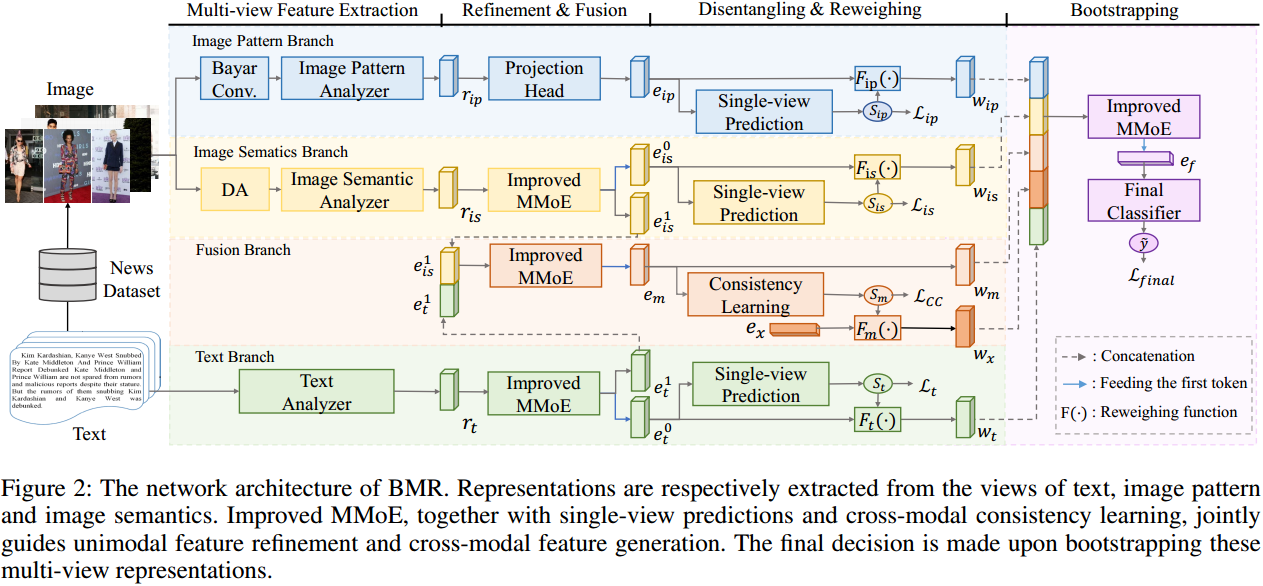
图2描述了BMR的流程,其中包含四个阶段,即多视图特征提取、精炼与融合、解纠缠与重加权、Bootstrapping。在前三个阶段,有四个分支对应于四个视图的表示,包括图像图案分支、图像语义分支、文本分支和融合分支。
多视图特征提取
输入:\(\mathcal{N}=[\mathbf{I},\mathbf{T}]\in\mathcal{D}\),
\(\mathbf{I}, \mathbf{T}, \mathcal{D}\)分别表示图像、文本、数据集。
本文的观点假设是:图像的总体分布以及篡改或压缩后留下的微小痕迹有助于揭露假新闻
首先提取粗糙的多视图表示:
- 使用InceptionNetV3提取图像图案特征(\(r_{ip}\))
- 使用mask自编码器(MAE)提取图像语义特征(\(r_{is}\))
- 使用BERT提取文本特征(\(r_{t}\))。
然后从两个方面明确地解缠图像图案和语义学习:
- 架构差异。CNN以图像识别而闻名,而基于掩码语言/图像建模的transformer模型在建立长程注意力上有优势;
- 输入差异。在IP分支中加入了BayarConv,它作为可学习高通滤波器,可以保留图像中高频信息,有利于过滤图像语义。在IS分支中加入了数据增强(DA)方法(例如翻转,调节颜色),从而鼓励网络学习更加鲁棒的语义特征,而丢弃掉小幅度的图案变化带来的差异。
基于iMMoE的特征细化与融合
对于IP分支,通过将InceptionNetV3的分类头替换为一个基于MLP的投影头,把 \(r_{ip}\) 投影到一个新的表示 \(e_{ip}\) ,\(e_{ip}\)的输出大小等于MAE的单个token大小;
对于IS分支和T分支,提出了改进的MMoE(iMMoE)网络来重新细化 \(r_{is}\) 和 \(r_{t}\) ,此外,还在融合分支中生成了一个新的表示 \(e_{m}\)。
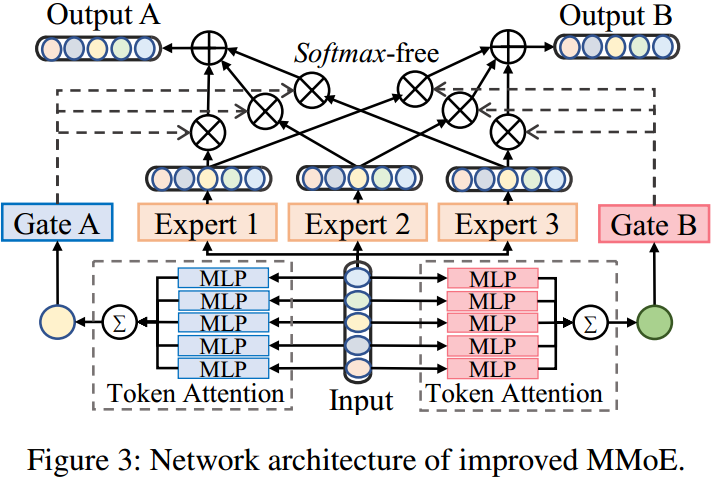
如图3所示,iMMoE包含几个专家系统、门控和token注意力。
MMoE网络最初设计用于通过在所有任务中共享专家来从数据中建模多任务关系,输入 \(x\) 被均匀地发送到 \(n\) 个专家网络中,\(k\) 个门使用 \(\textit{softmax}\) 函数自适应地权衡专家的输出作为最终输出。\(N\) 是超参数,\(k\) 是下游任务的数量:
其中,\(E_i\) 和 \(G_i^k\) 是任务 \(k\) 的 \(i_{th}\) 专家和gate的 \(i_{th}\) 输出。
在BMR中,我们将多视图单模态表示的挖掘和跨模态特征融合视为不同的子任务。它们既应该共享共同的特征,又要保留各自的鲜明特征。
我们从两个方面改进MMoE网络。
首先,我们用一个权重共享的MLP通过token关注来计算每个token表示的重要性分数,并根据分数将所有token表示聚合为一个来执行降维。然后将聚合表示送入gate中,以计算每个专家的权重。
其次,原始MMoE网络的gate中的 \(\textit{softmax}\) 要求所有专家必须对所有输出做出积极贡献,根据我们的实验,发现这个限制不是必需的。因此我们解除了 \(\textit{softmax}\) 的约束,允许权重为负或大于1。
综上,iMMoE将公式(1)修正为公式(2):
其中,\(t\) 是token的数量,\(\textit{MLP}_k\) 表示任务 \(k\) 的token注意力,\(k \in [1,2]\)。
运用iMMoE网络,我们将 \(r_{is}\) 和 \(r_t\) 分别细化为特征 \([e^0_{is}, e^1_{is}]\) 和 \([e^0_t, e^1_t]\) 。\(e^0_{is}\) 和 \(e^0_t\) 被保留用于单视图预测。同时,将 \(e^1_{is}\) 和 \(e^1_t\) 联合输入到融合分支的iMMoE网络中,生成一个多模态特征 \(e_m\) ,并保留该特征用于跨模态一致性学习和Bootstrapping。
解缠和重加权
经过细化和融合,我们从四个分支获得了新的表示。接下来,我们通过单视图预测处理图像图案、图像语义和文本的表示,同时在融合分支中处理融合表示以进行一致性学习。
单视图预测和重加权
单视图预测使用 \(e_{ip}\) 、\(e^0_{is}\) 的第一个token和 \(e^0_t\) 的第一个token来预测 \(\mathcal{N}\) 的保真度。
我们基于两个考虑来设计这个模块。一方面,许多假新闻在图像噪声、分布或文字上都存在明显的异常。因此,用单视图特征对 \(\mathcal{N}\) 进行预测在经验上是可行的。另一方面,每个单视图预测的置信度可以被投射到自适应重新权衡表示的权重中,作为模态的注意力。因此,我们使用MLP将每个单视图表示投影为分数,并使用另一个MLP,即图2中的 \(F(·)\),将分数投影为权重。以 \(S_{ip}\) 和 \(w_{ip}\) 的生成为例:
其中 \(MLP_{ip}(·)\) 表示基于MLP的单视图预测器。
以同样的方式,我们生成成对的预测分数并重新加权表示 \(\{S_{is}, w_{is}\}\),\(\{S_m, w_m\}\) 和 \(\{S_t, w_t\}\) 。然后,重新加权的表示就可以进行Bootstrapping了。
跨模态一致性学习
目标:训练BMR来预测给定的文本-图像对是否匹配
做法:首先在数据集 \(\mathcal{D}\) 的基础上制作一个新的数据集 \(\mathcal{D}^{\prime}=[\mathcal{D}_{real},\mathcal{D}_{syn}]\) ,其中具有相关文本和图像的新闻被标记为 \(y^{\prime}=1\) ,否则 \(y^{\prime}=0\) 。图4展示了跨模态一致性学习的三个训练数据,其中正例是直接借用 \(\mathcal{D}\) 的真实新闻,负例是通过任意组合不同真实新闻的图像和文本合成的“新闻”。

因为相比于原本真实的新闻,通过合成得到的“虚假新闻”具有跨模态一致性的可能性要更低,所以模型可以基于这种混合数据集学习相关性。
操作:给BMR投喂 \(\mathcal{N}^{\prime}=[\mathbf{I}^{\prime},\mathbf{T}^{\prime}]\in\mathcal{D}^{\prime}\) ,再计算得到相应的 \(e_m\) 后,使用基于MLP的预测器输出一致性分数 \(S_m\) ,并期望分数接近标签 \(y^{\prime}\) 。跨模态一致性学习的训练过程只激活了BMR中的一部分模块。该任务可以与主任务并行学习。
重新加权多模态表示
\(\mathcal{N}\) 上预测的一致性得分也调整了多模态特征表示。而我们认为多模态特征不应该仅仅表示跨模态相关性,还有许多其他因素,如共同分布,情绪差异等,可以帮助决定新闻是否假。
因此,不能简单地使用 \(S_m\) 来衡量 \(e_m\) 。我们使用 \(S_m\) 来重加权一个表征跨模态不相关性的独立可训练的token \(e_x\) ,从而把相关性从其它跨模态信息中解缠出来。\(w_x=e_{x}\cdot F_{m}(S_{m})\) ,\(w_m=e_m\) ,它们都是用于bootstrapping的多模态特征表示。
Bootstrapping和损失函数
多视图表示 \([w_{is}, w_{ip}, w_m, w_x, w_t]\) 使用另一个iMMoE引导,这进一步细化了对决策至关重要的信息。最终的基于mlp的分类器获得输出 \(e_f\) 的第一个token来预测 \(\tilde{y}\) ,预计它将接近标签 \(y\) 。
虚假新闻检测是一个二元分类问题。我们计算真值标签 \(y\) 和预测分数 \(\tilde{y}\) 之间的BCE损失,对于粗分类结果 \(S_{ip}, S_{is}, S_t\) 也和真值标签 \(y\) 进行BCE损失计算。我们也计算利用真值制作的标签 \(y^{\prime}\) 和 \(S_m\) 之间的BCE损失。
因此,损失函数定义为:\(\mathcal{L}_{CC}=\mathcal{L}_{BCE}(y^{\prime},S_{m})\) ,\(\mathcal{L}_{final}=\mathcal{L}_{BCE}(y,y^{\prime})\) ,\(\mathcal{L}_{t}=\mathcal{L}_{BCE}(y,S_{t})\) ,\(\mathcal{L}_{ip}=\mathcal{L}_{BCE}(y,S_{ip})\) ,\(\mathcal{L}_{is}=\mathcal{L}_{BCE}(y,S_{is})\)
单视图FND分类损失是 \(\mathcal{L}_{is}\) 、\(\mathcal{L}_{ip}\) 和 \(\mathcal{L}_{t}\) 的总和,命名为:
BMR的总损失定义如下:
其中 \(α\) 和 \(β\) 为超参数。
实验
数据集:Weibo、GossipCop、Weibo-21
其中,Weibo包含3749条真实新闻和3783条假新闻用于培训,1000条假新闻和996条真实新闻用于测试。GossipCop包含7974条真实新闻和2036条假新闻用于培训,2285条真实新闻和545条假新闻用于测试。Weibo-21是一个新发布的数据集,共包含4640条真实新闻和4487条假新闻,我们将其分成训练数据和测试数据,比例为9:1。
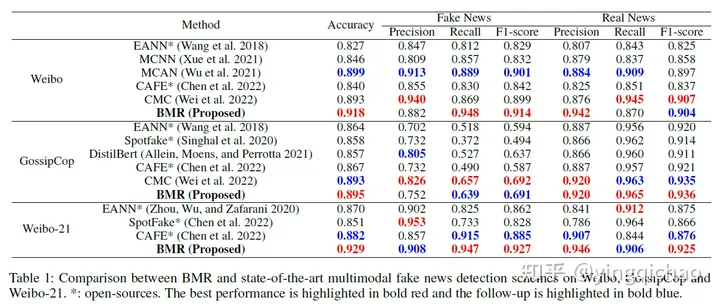
表1:BMR与微博、GossipCop和微博-21上最先进的多模态假新闻检测方案的比较。*:开源。最佳表现用红色粗体突出,后续表现用蓝色粗体突出。
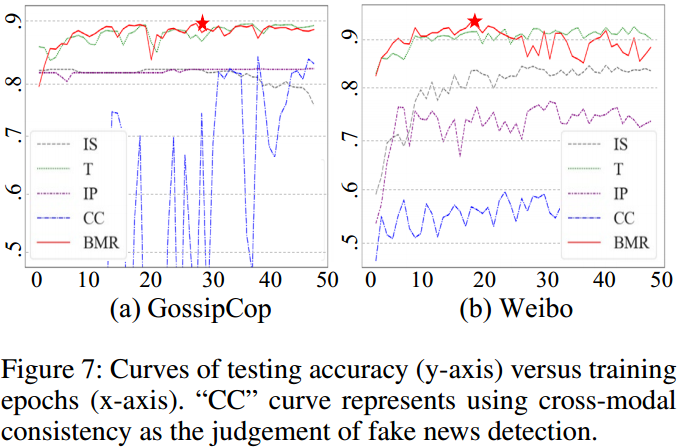
对于粗分类器是否会由于1)过拟合2)对于假新闻由于无法从单一模态提取得到异常信息造成欠拟合,从而导致方案整体性能随着训练过程出现下降,上图展示了在Gossip与Weibo数据集上的训练时各粗分类器与跨模态一致性分类器准确率曲线。可以看到,在20-30轮训练时,模型的性能可以达到最佳,而过多或者过少的训练则确实会导致一些粗分类器发生过/欠拟合现象,同时,粗分类器准确率低于最终决策分类器的准确率,文本粗分类器准确率在所有三个数据集上都与最终决策分类器准确率最为接近,也意味着对许多虚假新闻,文本的真假程度对整条新闻的真实性影响很大。
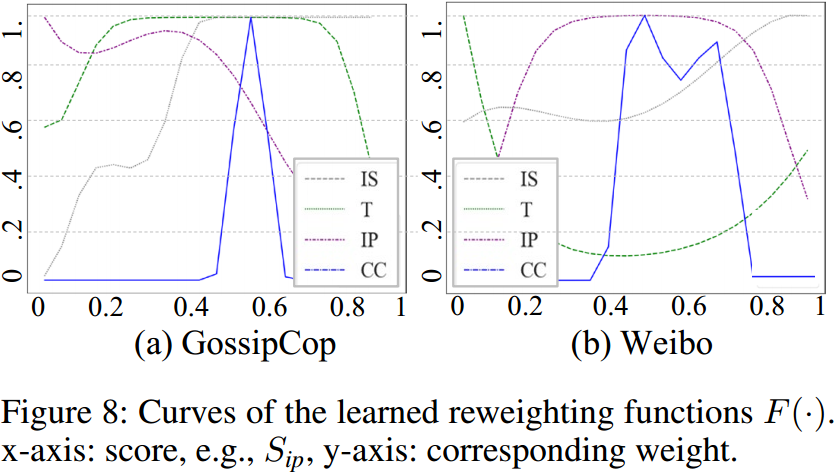
打印了不同粗分类器与跨模态一致性分类器配对使用的加权函数,可以看到,多数加权函数呈现倒V形状,也即当粗分类器能够非常确信其判决结果时,在送入决策过程前抑制对应特征。此决策机制鼓励尽可能使用更多角度、更多模态的信息,防止单一模态主导全局,这与人类做谨慎判断的过程也是相符合的。
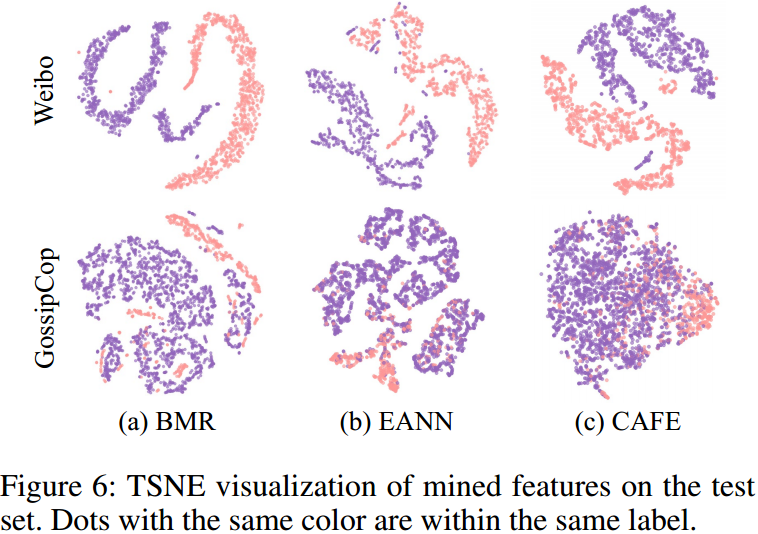
测试集分类可视化:
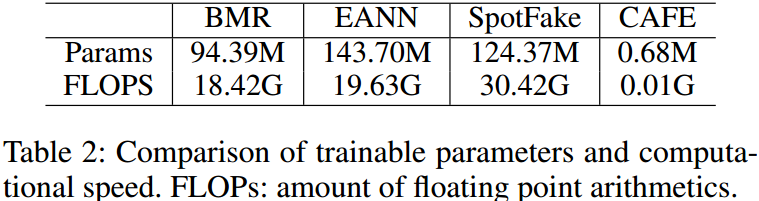
模型大小:
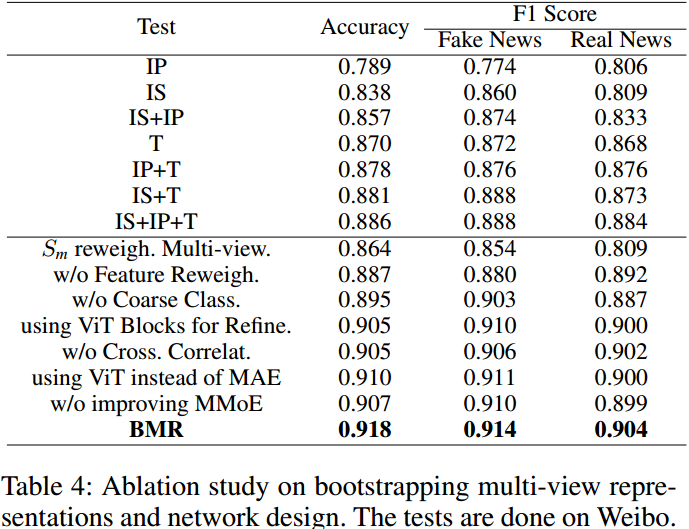
消融实验:
- Representations Bootstrapping Multi-view Detection 笔记representations bootstrapping multi-view detection representations clustering community detection multi-view commonsense-aware commonsense completion multi-view bootstrapping convolution multi-view clustering attribute representations bootstrapping fhe multi-modalities bootstrapping modalities languages process bootstrapping has finished