一、样本匹配
YOLO系列算法一般的网络输出如图1所示:

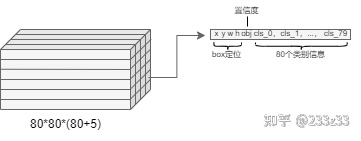
图1
输出为80*80*85的Tensor(以COCO数据集为例),即在80*80的尺度上,每一个点位都输出一个长度85的Tensor,85意为80个类别信息、1个box坐标信息以及1个置信度信息。对于yolov5来说,每一个点位上有3个不同宽高比例的anchor,那么yolov5在80*80的尺度上就有80*80*3=19200个anchor,如此大量的anchor中有大量的负样本和少数正样本,所谓的正负样本分配,分配的就是anchor。每一个anchor都对应到80*80尺度上的一个输出(80个类别信息、1个box坐标信息以及1个置信度信息),取出正样本anchor对应的网络输出,再和人工标注ground truth一同送入损失函数,不断迭代以收敛网络。
此外如果想了解YOLOv5的样本匹配机制可以阅读另一篇文章:YOLOv5的样本匹配部分写在该文MMDetection移植yolov5——(三)训练实现 - 知乎 (zhihu.com)第二部分。
二、SimOTA原理
1.OTA
简单说一下OTA(OTA具体内容可以去看下边的论文)。
OTA原论文链接:[PDF] OTA: Optimal Transport Assignment for Object Detection-论文阅读讨论-ReadPaper
原文中作者提到一个好的样本分配策略应该满足以下几点:
1)基于网络自身的预测来计算 anchor box 或者 anchor point 与 gt 的匹配关系,充分考虑不同结构/复杂度的模型可能会有不同行为;
2)考虑到感受野的问题,以及大部分场景下,目标的质心都与目标的几何中心有一定的联系,将正样本限定在目标中心的一定区域内做样本匹配这样能很好地解决收敛不稳定的问题;
3)不同目标设定不同的正样本数量(dynamic k ):不可能为同一场景下的目标A和B分配同样的正样本数,如果真是那样,那要么A有很多低质量的正样本,要么B仅仅只有一两个正样本;


图2
4)全局信息:有些 anchor box/point 处于正样本之间的交界处、或者正负样本之间的交界处,如图2所示。这类 anchor box/point 的正负划分,甚至若为正,该是谁的正样本,都应充分考虑全局信息。
OTA就是满足上述4点的、一个好的样本匹配策略。
2.SimOTA
OTA动态样本匹配策略在YOLOX中会增加约20%~25%的训练时间,于是将OTA中的Sinkhorn-Knopp迭代最优方案求解的过程去除,得到了YOLOX中使用的Simplified OTA (SimOTA)。
以下内容可以对应着YOLOX的官方源码(YOLOX/yolo_head.py at main · Megvii-BaseDetection/YOLOX · GitHub)来看。YOLOX网络输出(训练阶段)如图3所示。
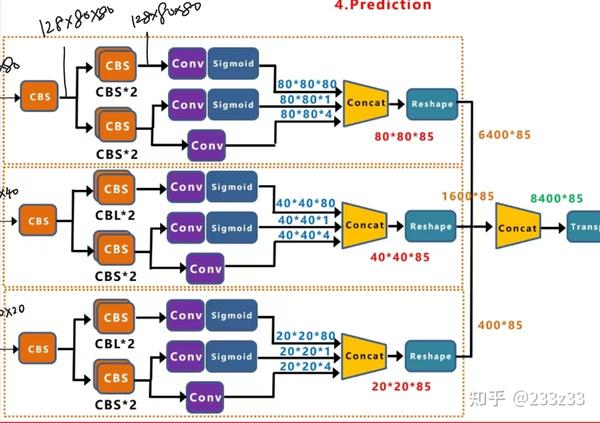

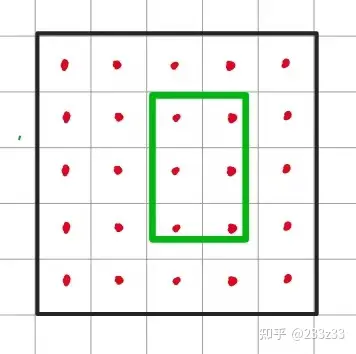
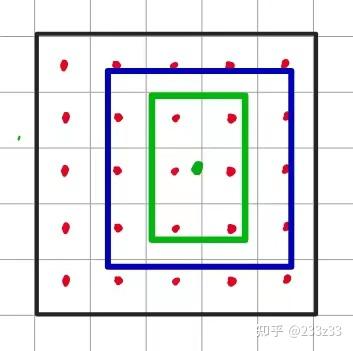
这里为了节省篇幅以及易于理解,以20*20尺度为例,YOLOX是anchor-free目标检测器,在20*20的feature map上有400个anchor point (锚点),每一个anchor point都对应一个输出(80+1+4)。下面进行SimOTA之前先了解两个概念:in_boxes(anchor point在ground truth中)、in_center(anchor point在ground truth的展开域中),具体如图4、图5所示。


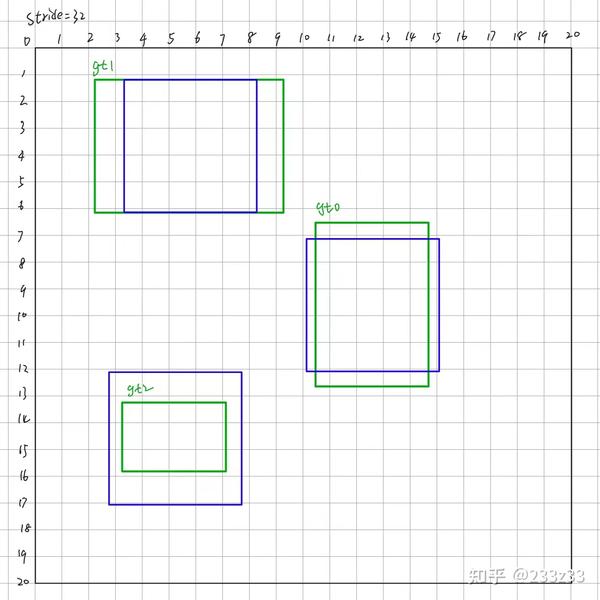
回到20*20的feature map上,假设这个20*20的feature map是yolox以COCO数据集(80类)中的某张图片为输入得到的,这张图片有三个gt,如图6所示。

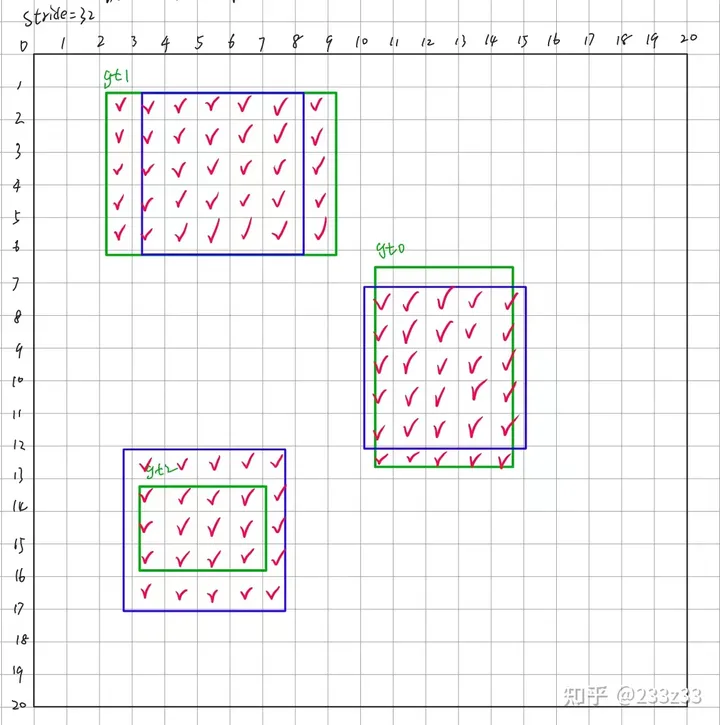
根据in_boxes的概念,挑选出中心点(anchor point)落在gt中的网格,根据in_centers的概念,挑选出中心点(anchor point)落在gt展开域中的网格,取并集,并且得到一个长度为400的Bool类型的Tensor——fg_mask(foreground mask,前景信息),形如[False, False, False, True, True, ... ,False, False],其中有95个True,如图7所示。

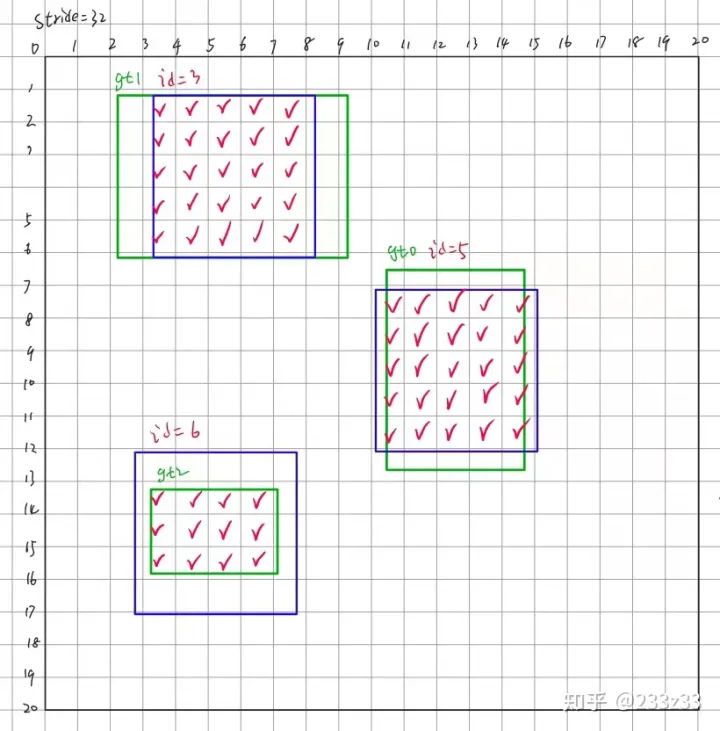
根据in_boxes的概念,挑选出中心点(anchor point)落在gt中的网格,根据in_centers的概念,挑选出中心点(anchor point)落在gt展开域中的网格,取交集,并且得到一个shape为3*95的Bool类型的Tensor——is_in_boxes_and_centers,其中is_in_boxes_and_centers[i]代表第i个gt的in_boxes & in_centers,如图8所示。

到此为止,先梳理一下,目前以COCO(80类)中某张图片为输入,得到20*20的feature map,图片中有3个gt,现在我们有以下信息:
- 网络输出的类别信息,400*80的Tensor——pred_cls;
- 网络输出的置信度信息,400*1的Tensor——pred_obj;
- 网络输出的box回归信息,400*4的Tensor——pred_box;
- 20*20 feature map上得到的前景信息,长度为400的Bool类型Tensor——fg_mask,其中为True的为前景,其余False部分为背景,有95个True;
- 20*20 feature map上得到的各个gt的前景信息,3*95的Bool类型Tensor——is_in_boxes_and_centers,这边看下面的图结合理解:


现在我们需要根据前景信息fg_mask对网络输出进行初步的筛选(网路输出20*20的feature map上400个点位,每个点位都有类别信息、置信度信息、回归信息,这些信息大部分都是没有用的):
pred_cls = pred_cls[fg_mask] # 95*80
pred_obj = pred_obj[fg_mask] # 95*1
pred_box = pred_box[fg_mask] # 95*4计算simOTA中的cost成本矩阵,包括以下步骤:
- 计算iou loss损失;
# 计算3个gt与95个网络输出框(pred_box)的iou
pair_wise_ious = bbox_iou(gt_bboxes, box_pred) # 得到一个3*95的iou矩阵
# 计算iou loss损失
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8) # 3*95的iou loss矩阵iou矩阵如图iou矩阵如图9所示。


图9 iou矩阵
- 计算cls loss损失;
# 先对3个gt的cls信息进行one hot编码
gt_cls = F.one_hot(gt_class,80) # 3*95*80
# 得到类别信息
cls_preds_ = cls_pred * obj_pred # 3*95*80
# 计算cls loss
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_ , gt_cls) # 3*95- 计算得到SimOTA关键的cost矩阵;
cost = (pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000 * (~is_in_boxes_and_centers))简而言之,我们根据fg_mask得到400个anchor point里面有95个是初步认定的正样本,我们根据它们与gt box的iou、类别损失、前景背景信息得到一个3*95的cost矩阵,表示每一个gt与每一个正样本之间的成本cost(成本cost越小优先级越高)。cost矩阵如图10所示。


图10 cost矩阵
dynamic_k_matching算法,包括以下步骤:
- cost矩阵shape为3*95,取n_candidate_k = min(10, 95) = 10;
- 在iou矩阵中,根据n_candidate_k=10,取对于每一个gt,取其与95个pred box的所有iou里最大的10个并且求和,得到dynamic_k示意图如下;
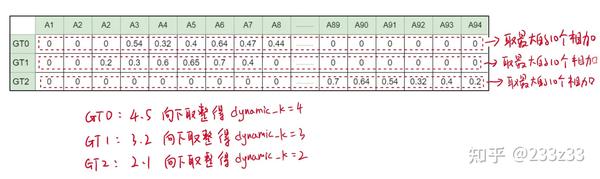

- 根据dynamic_k,从cost矩阵中,GT0那一行找出4个最小的值,GT1那一行找出3个最小的值,GT2那一行找出2个最小的值,示意图如下;


上图中,A3与GT0匹配成功,A91与GT2匹配成功,A92与GT2匹配成功,A4与GT1匹配成功(为什么不是GT0? 每一个anchor只能与一个GT匹配成功,如果出现A4与GT0和GT1同时被选中的情况,取cost最小的),A5与GT0匹配成功,A6与GT0匹配成功。
- 根据匹配成功的信息,得到matching matrix (shape与iou矩阵和cost矩阵相同),如下:


matching matrix中就是最终的样本分配的结果,从图中可以看见的部分可以得知,最终正样本为A3、A4、A5、A6、...... 、A91、A92。
至此,YOLOX的SimOTA讲解完毕。以上内容中相关信息均是虚构,不过意思已经传达到了。
三、代码结构与注释
1.代码结构

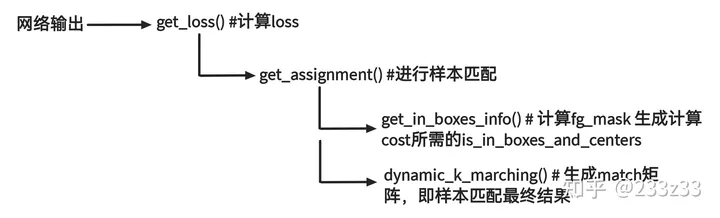
2.注释
get_assignment( )
@torch.no_grad()
def get_assignments(
self,
batch_idx,
num_gt,
total_num_anchors,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
bbox_preds,
obj_preds,
labels,
imgs,
mode="gpu",
):
if mode == "cpu":
print("------------CPU Mode for This Batch-------------")
gt_bboxes_per_image = gt_bboxes_per_image.cpu().float()
bboxes_preds_per_image = bboxes_preds_per_image.cpu().float()
gt_classes = gt_classes.cpu().float()
expanded_strides = expanded_strides.cpu().float()
x_shifts = x_shifts.cpu()
y_shifts = y_shifts.cpu()
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info( # fg_mask:为网格展开区域 与 gt_bbox 的并集区域 并集区域也即目标区域为True 其余视作背景区域 为False
gt_bboxes_per_image, # is_in_boxes_and_center为网格展开区域 与 gt_bbox 的交集区域
expanded_strides,
x_shifts,
y_shifts,
total_num_anchors,
num_gt,
)
# 初步筛选
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # 该图片筛掉背景对应的网络bbox输出值,留下目标区域网格对应的网络bbox输出
cls_preds_ = cls_preds[batch_idx][fg_mask] # 根据batch_idx得到当前图片对应的网络cls输出,并且筛除背景网格对应的部分
obj_preds_ = obj_preds[batch_idx][fg_mask] # 根据batch_idx得到当前图片对应的网络obj输出,并且筛除背景网格对应的部分
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
if mode == "cpu":
gt_bboxes_per_image = gt_bboxes_per_image.cpu()
bboxes_preds_per_image = bboxes_preds_per_image.cpu()
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False) # 目标区域网格对应的bbox输出 与 gt的iou
gt_cls_per_image = ( # 将gt的类别进行one-hot编码,并重复多次(目标区域网格数目)
F.one_hot(gt_classes.to(torch.int64), self.num_classes)
.float()
.unsqueeze(1)
.repeat(1, num_in_boxes_anchor, 1)
)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
if mode == "cpu":
cls_preds_, obj_preds_ = cls_preds_.cpu(), obj_preds_.cpu()
with torch.cuda.amp.autocast(enabled=False):
cls_preds_ = (
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* obj_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
cost = ( # gt_bbox展开域和gt_bbox的并集区域为A 交集区域为B 交集以内的网格中心(或者说是anchor)的cost很大 并集以内、交集以外的cost很小
pair_wise_cls_loss # 同时考虑每个anchor和gt_bbox的cls和iou的损失计算
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
(
num_fg, # 前景数目
gt_matched_classes, # 正样本到的gt类别
pred_ious_this_matching, # 正样本的iou
matched_gt_inds,
) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
if mode == "cpu":
gt_matched_classes = gt_matched_classes.cuda()
fg_mask = fg_mask.cuda()
pred_ious_this_matching = pred_ious_this_matching.cuda()
matched_gt_inds = matched_gt_inds.cuda()
return (
gt_matched_classes,
fg_mask, # 注意 在dynamic_k_matching中更新过来的
pred_ious_this_matching,
matched_gt_inds,
num_fg,
)get_in_boxes_info( )
def get_in_boxes_info(
self,
gt_bboxes_per_image, # x,y,w,h格式
expanded_strides, # 1*8400
x_shifts, # 1*8400
y_shifts, # 1*8400
total_num_anchors, # 8400
num_gt,
):
expanded_strides_per_image = expanded_strides[0]
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
x_centers_per_image = (
(x_shifts_per_image + 0.5 * expanded_strides_per_image) # 8400
.unsqueeze(0) # 1*8400
.repeat(num_gt, 1)
) # [n_anchor] -> [n_gt, n_anchor]
y_centers_per_image = (
(y_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
)
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1) # 1*1
.repeat(1, total_num_anchors) # 1*8400
)
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
b_l = x_centers_per_image - gt_bboxes_per_image_l # 网格中心与gt左边界的间距
b_r = gt_bboxes_per_image_r - x_centers_per_image # 网格中心与gt右边界的间距
b_t = y_centers_per_image - gt_bboxes_per_image_t # 网格中心与gt上边界的间距
b_b = gt_bboxes_per_image_b - y_centers_per_image # 网格中心与gt下边界的间距
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # 1*8400*4
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0 # 1*8400 # 判断8400个网格中心当中,每一个网格中心是否落入gt(n个gt对应n*8400)中
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0 # 判断8400个网格中心点当中,每一个网格中心点是否落入当前图片中的任意一个gt中
# in fixed center
center_radius = 2.5 # 不要理解为表面的意思 2.5表示半径为2.5个网格 直径为5个网格
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat( # 这边理解为,以gt_bbox的中心点作为中心,无论在多大的feature map上,以2.5个网格为半径
1, total_num_anchors # 1*8400 # 展开区域,区域为正方形,长宽都是5个网格(注意gt中心的落点随机)
) - center_radius * expanded_strides_per_image.unsqueeze(0) # 1*8400
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
c_l = x_centers_per_image - gt_bboxes_per_image_l # 网格中心与gt展开左边界的间距
c_r = gt_bboxes_per_image_r - x_centers_per_image # 网格中心与gt展开右边界的间距
c_t = y_centers_per_image - gt_bboxes_per_image_t # 网格中心与gt展开上边界的间距
c_b = gt_bboxes_per_image_b - y_centers_per_image # 网格中心与gt展开下边界的间距
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2) # 1*8400*4
is_in_centers = center_deltas.min(dim=-1).values > 0.0 # 判断8400个网格中心当中,每一个网格中心是否落在gt展开域
is_in_centers_all = is_in_centers.sum(dim=0) > 0 # 判断8400个网格中心当中,每一个网格中心是否落入当前图片中的任意一个gt展开域中
# in boxes and in centers
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all # 取并集 用于区分目标区域和背景区域
# 上边提到的所谓的anchor 我理解为“网格” anchor free并没有显式的体现出anchor box 因为没有anchor的宽和高 所以叫做anchor free
is_in_boxes_and_center = ( # 取交集
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]
)
return is_in_boxes_anchor, is_in_boxes_and_centerdynamic_k_matching( )
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
# Dynamic K
# ---------------------------------------------------------------
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8) # 匹配矩阵
ious_in_boxes_matrix = pair_wise_ious # iou矩阵 gt与pred 或者叫 真实框与锚点矩阵 进来一般是一个n_gt*m的tensor m是筛除背景后的锚点数量
n_candidate_k = min(10, ious_in_boxes_matrix.size(1)) # 候选名额
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1) # 得到排名前n_candidate_k的iou值 每一个gt都取
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1) # 对每个gt的 前10的iou值求和取整 作为每个gt的dynamic_k(>=1)
dynamic_ks = dynamic_ks.tolist()
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx], largest=False
)
matching_matrix[gt_idx][pos_idx] = 1
del topk_ious, dynamic_ks, pos_idx
anchor_matching_gt = matching_matrix.sum(0) # 每一个anchor与多少个gt匹配
if (anchor_matching_gt > 1).sum() > 0: # 处理一个anchor与多个gt匹配的情况
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1
fg_mask_inboxes = matching_matrix.sum(0) > 0 # 前景
num_fg = fg_mask_inboxes.sum().item() # 前景数目
fg_mask[fg_mask.clone()] = fg_mask_inboxes # fg_mask是根据gt和gt扩展域初步筛选的前景,这边根据dynamic_k_matching再次筛选一次
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[
fg_mask_inboxes
]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds