前面介绍了将VAE+GAN解决零样本学习的方法:f-VAEGAN-D2,这里继续讨论引入生成模型处理零样本学习(Zero-shot Learning, ZSL)问题。论文“Latent Embedding Feedback and Discriminative Features for Zero-Shot Classification”提出TF-VAEGAN,以f-VAEGAN-D2为Baseline进行改进。
引言
动机
一些工作利用辅助模块(如Decoder)在训练期间对语义嵌入重建实现循环一致(cycle-consistency)约束,帮助生成器合成语义一致的特征。但这些辅助模块仅在训练中使用,在调整合成与分类预测阶段被丢弃。既然辅助模块在训练中帮助生成器,作者希望能在调整合成阶段帮助生成判别性的特征,减少不同类之间的歧义促进分类。因此作者在文中,增强了特征合成与零样本分类。
此外,为了保证生成的特征语义上尽可能与真实特征分布相近,训练时,对生成特征与原始特征使用循环一致(cycle-consistency)损失。对于语义嵌入也使用类似的一致损失,并在特征合成与分类期间进一步学习。
贡献
在VAEGAN架构的基础上增加一个语义嵌入解码器(Semantic Embedding Decoder, SED),并且:
- 增加了一个用于(广义)零样本学习的反馈模块(feedback module),该模块在训练和合成调整阶段均使用SED。反馈模块首先转换SED的潜在嵌入,然后生成潜在表征供生成器使用。作者表示自己是第一个提出反馈模块用于(广义)零样本学习,而之前的反馈模块用于图像超分辨率。
- 在分类阶段引入判别特征转换(discriminative feature transformation),转换会利用SED的潜在嵌入及相应的视觉特征来减少对象类别之间的歧义。
最后,作者在4个图像数据集、2个视频数据集进行了测试。
方法
设置
- \(x\in\mathcal{X}\)为图像(视频)特征实例;
- \(y\in\mathcal{Y}^s\)为相应的标签,标签集合含\(M\)个可见类,即\(\mathcal{Y}^s=\{y_1\dots,y_M\}\);
- \(\mathcal{Y}^u=\{u_1\dots,u_N\}\)表示\(N\)未见类,并且\(\mathcal{Y}^s\cap\mathcal{Y}^u=\varnothing\);
- 描述类的特定语义嵌入\(a(k)\in\mathcal{A},\forall k\in\mathcal{Y}^s\cup\mathcal{Y}^u\);
- 对于无标签的测试数据\(x_t\in\mathcal{X}\)不在归纳ZSL中使用,仅在转导ZSL中使用;
- ZSL和GZSL的任务目的是分别学习分类器\(f_{zsl}:\mathcal{X}\to\mathcal{Y}^u\ \text{and}\ f_{gzsl}:\mathcal{X}\to\mathcal{Y}^s\cup\mathcal{Y}^u\)。在此之前,首先使用可见类特征\(x_s\)和相应嵌入\(a(y)\)合成特征。然后使用后学习到的模型使用未见类嵌入\(a(u)\)合成特征\(\hat{x}_u\)。结果得到的\(\hat{x}_u\)与\(x_s\)将用来训练分类器\(f_{zsl}\)和\(f_{gzsl}\)。
Baseline:f-VAEGAN-D2
此处再复述一遍f-VAEGAN-D2的损失函数设置。对于VAE部分的Encoder设置为\(E(x,a)\) ,它将输入特征x计算为潜在表征z,使用解码器\(G(z,a)\)从z重构x(解码器与WGAN共享作为条件生成器)。对于E和G,以嵌入a作为条件,VAE优化函数为
KL表示KL散度,\(p(z|a)\)表示先验分布假设为\(\mathcal{N}(0,1)\),\(\log G(z,a)\)为重构损失。对于WGAN部分,有着生成器\(G(z,a)\)和判别器\(D(x,a)\)。G从随机噪声z合成特征\(\hat{x}\in\mathcal{X}\),D对于输出的x输出实数,表示x是真实还是合成的概率,对于G和D,以嵌入a作为条件,优化函数为WGAN损失
\(\begin{aligned}\hat{x}=G(z,a)\end{aligned}\)是合成特征,\(\lambda\)是惩罚系数,\(\tilde{x}\)为\(x\)和\(\hat{x}\)的随机插值。令\(\alpha\)为超参数,整体的优化函数为
局限
公式(1)第2项训练时,保证生成的特征与原始视觉特征循环一致(cyclically-consistent)。但在语义嵌入上并没有这种循环一致(cycle-consistency)约束,而其他通过辅助模块(除了生成器)在嵌入上实现循环一致的方法,仅作用在了训练,而在合成特征与分类阶段丢弃了辅助模块。
因此,在该论文,作者引入SED在训练、合成特征和分类阶段对语义嵌入实现循环一致约束,让生成器与SED互补学习并减少ZSL分类过程的歧义。
整体框架
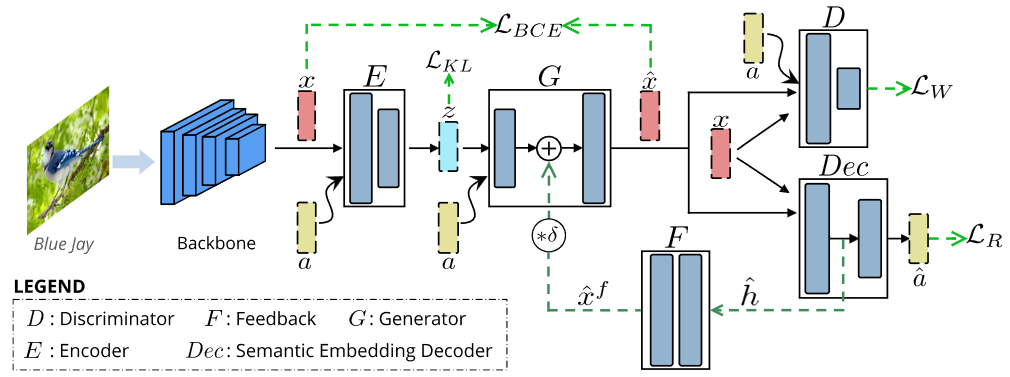
对于给出的图片,骨干网络提取特征x与相应的语义嵌入a输入编码器E。E输出潜在表征z,z与a输入生成器G合成特征\(\hat{x}\)。判别器D学习区分真实特征x与合成特征\(\hat{x}\)。
E与G构成VAE使用二元交叉熵损失(\(\mathcal{L}_{BCE}\))和KL散度优化(\(\mathcal{L}_{KL}\))。G与D构成WGAN,使用WGAN损失\(\mathcal{L}_{W}\)优化。此外,加入了反馈模块F转换Dec(也就是SED)输出的潜在嵌入\(\hat{h}\),并喂入G,让G迭代细化\(\hat{x}\)。
Dec和反馈模块F在分类过程中,共同增强特征合成、减少类别间的歧义。Dec接受x与\(\hat{x}\),重构生成嵌入\(\hat{a}\)。使用循环一致损失\(\mathcal{L}_R\)训练。学习后的Dec将被用在ZSL/GZSL分类中。F转换Dec的潜在嵌入,反馈给G以实现改进的特征合成。
语义嵌入解码器(SED)
语义嵌入解码器\(Dec:\mathcal{X}\to\mathcal{A}\),对于生成特征\(\hat{x}\)重构语义嵌入\(a\)。为了循环一致性,保证生成语义一致的特征,使用L1重构损失。
令\(\beta\)为解码器重构误差的权重超参数,整个TF-VAEGAN的优化函数为
接下来介绍SED在分类过程中的重要性以及它在特征合成的作用。
判别特征转换(Discriminative Feature Transformation)
生成器G仅使用可见类特征和嵌入来学习每个类的“单个语义嵌入到多个实例”映射。与G类似,SED也仅使用可见的类进行训练,但学习每个类的“多个实例到一个嵌入”逆映射,实现互补学习。如下图(a)所示,使用SED的潜在嵌入(\(x\oplus h\))作为分类阶段的重要信息源以减少特征间的歧义。
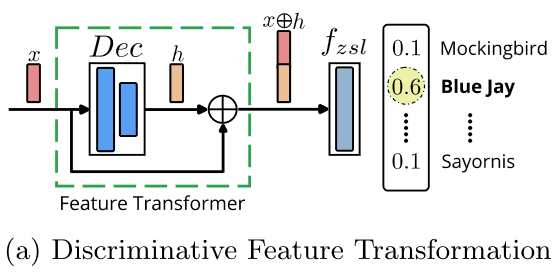
Dec在分类阶段,通过输入特征\(x\)与相应的潜在嵌入\(h\)进行连接操作\(\oplus\),即特征转换(Transformation),然后将转换后的特征用于ZSL/GZSL分类。
首先进行G和Dec的训练。然后使用Dec将(合成或真实)特征转换到嵌入空间\(\mathcal{A}\)(也就是框架图中Dec生成的\(\hat{a}\))。再然后将Dec中间的潜在嵌入与视觉特征连接。令\(h_s,\hat{h}_s\in\mathcal{H}\)表示Dec潜在嵌入,输入为\(x_s,\hat{x}_s\)分别实现转换:\(x_s\oplus h_s\)或\(\hat{x}_u\oplus \hat{x}_u\)。转换的特征用于学习分类器:
接下来介绍Dec在特征合成阶段的使用。
反馈模块(Feedback Module)

\(\bigstar,\blacktriangle,\boldsymbol{\bullet}\)表示3种类。生成特征\(\hat{x}\)由类特定嵌入a通过生成器G合成.\(\hat{a}\)由SED重构得到,并用于进一步加强合成特征\(\hat{x}_e\)。
f-VAEGAN-D2使用生成器直接通过类嵌入a合成特征\(\hat{x}\)(如(a)所示),这会造成真实与合成特征间存在gap。为此引入了一个反馈循环,在训练与合成特征阶段迭代优化特征生成(如(b)所示)。反馈回路由Dec到G,经过反馈模块F。F能在训练和合成阶段有效利用Dec。
令\(g^l\)表示G的第\(l\)层输出;\(\hat{x}^f\)表示加入了\(g^l\)的反馈结果,反馈的输出可表示为
其中\(\hat{x}^f=F(h)\),h为Dec的潜在表征,\(\delta\)为控制模块的参数。然而,对于未见类,合成的特征不太可靠,作者对反馈循环进行了改进。
反馈模块的输入
ZSL中,判别器D是需要条件的,目的是为了区分可见类的真假特征,而未见类图像没有相应的嵌入(也就是转导的图像没有标签、语义嵌入配对)。这时需要Dec,它通过将实例的图像转为类相关的语义嵌入,Dec比D更适合向G提供反馈,Dec的结果更适合作为反馈的输入。
训练策略
首先通过标准的GAN训练方式,对G和D经过全面训练。然后使用D和冻结的G对F进行训练。G的输出由于F的反馈得到改善,D和F得到进一步对抗训练。由于G被固定没对特征合成作出改进,这种训练不是最优的。为了进一步利用反馈改进合成,采用了迭代交替训练G和F。迭代中,G的训练不变,而F含两个子迭代(如下图所示)。
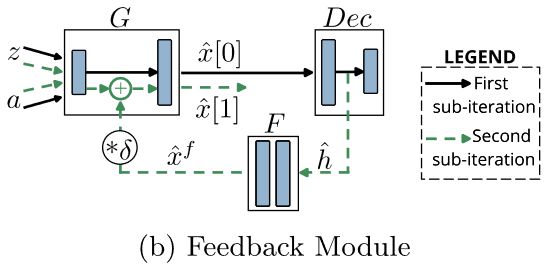
- 第一次子迭代:噪声z与语义嵌入a输入G,得初始合成特征\(\hat{x}[0]=G(z,a)\),并输入Dec。
- 第二次子迭代:Dec的结果\(\hat{h}\)输入F,得到\(\hat{x}^f[t]=F(\hat{h})\),并通过式(6)加入G的潜在表征,在第一次子迭代用过的z和a与\(\hat{x}^f[t]\)输入G合成\(\hat{x}^f[t+1]\)。
\(\hat{x}[t+1]\)输入Dec与D,使用式(4)训练。实践中第二次子迭代仅发生一次(t=0)。F让G学习Dec的h,从而增强特征的生成。
(广义)零样本分类
以上还没涉及转导的未见类图像,在Tf-VAEGAN中,通过输入嵌入\(a(u)\)和z到G:\(\hat{x}_u=G(z,a(u),\hat{x}^f[0])\)。合成的未见类特征\(\hat{x}\)与真实特征\(x_s\)分别输入Dec得到潜在特征并连接,即\(x_s\oplus h_s\)或\(\hat{x}_u\oplus \hat{x}_u\),并分别用于训练分类器\(f_{zsl}\)或\(f_{gzsl}\)。对测试样本\(x_t\)也是同样处理方式:\(x_t\oplus h_t\),然后对它进行预测。
实验
实现细节
判别器D、编码器E和生成器G由4096个隐藏单元的两层全连接 (Fully-connected, FC)网络实现。加入无条件判别器D2(架构图中为画出,可参考f-vAEGAN-D2)。许多设置于f-VAEGAN-D2的论文一致,如z与a的维度相同(\(d_z=d_a\))这里不再赘述。
泛化能力
作者将SED加入到f-CLSWGAN并于原始f-CLSWGAN对比证明,该模块可以迁移到不同架构并提高性能。
特征可视化

参考文献
- Narayan, Sanath, et al. "Latent embedding feedback and discriminative features for zero-shot classification." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16. Springer International Publishing, 2020.