一. Network:SFMNet
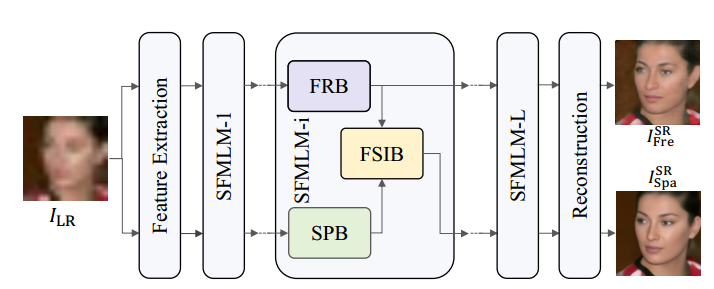
1.网络采用U-Net结构,其中SFMLM-i是不同分辨率的每层结构
2.SPB是空域分支,FRB是频域分支,分别经过FRB和SPB的两个分支信息经过FSIB分支进行信息的融合
3. FRB结构:
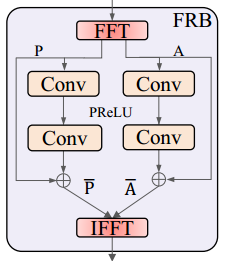


class FreBlock9(nn.Module): def __init__(self, channels, args): super(FreBlock9, self).__init__() self.fpre = nn.Conv2d(channels, channels, 1, 1, 0) self.amp_fuse = nn.Sequential(nn.Conv2d(channels, channels, 3, 1, 1), nn.LeakyReLU(0.1, inplace=True), nn.Conv2d(channels, channels, 3, 1, 1)) self.pha_fuse = nn.Sequential(nn.Conv2d(channels, channels, 3, 1, 1), nn.LeakyReLU(0.1, inplace=True), nn.Conv2d(channels, channels, 3, 1, 1)) self.post = nn.Conv2d(channels, channels, 1, 1, 0) def forward(self, x): # print("x: ", x.shape) _, _, H, W = x.shape msF = torch.fft.rfft2(self.fpre(x)+1e-8, norm='backward') msF_amp = torch.abs(msF) msF_pha = torch.angle(msF) # print("msf_amp: ", msF_amp.shape) amp_fuse = self.amp_fuse(msF_amp) # print(amp_fuse.shape, msF_amp.shape) amp_fuse = amp_fuse + msF_amp pha_fuse = self.pha_fuse(msF_pha) pha_fuse = pha_fuse + msF_pha real = amp_fuse * torch.cos(pha_fuse)+1e-8 imag = amp_fuse * torch.sin(pha_fuse)+1e-8 out = torch.complex(real, imag)+1e-8 out = torch.abs(torch.fft.irfft2(out, s=(H, W), norm='backward')) out = self.post(out) out = out + x out = torch.nan_to_num(out, nan=1e-5, posinf=1e-5, neginf=1e-5) # print("out: ", out.shape) return out
4. FSIB结构:
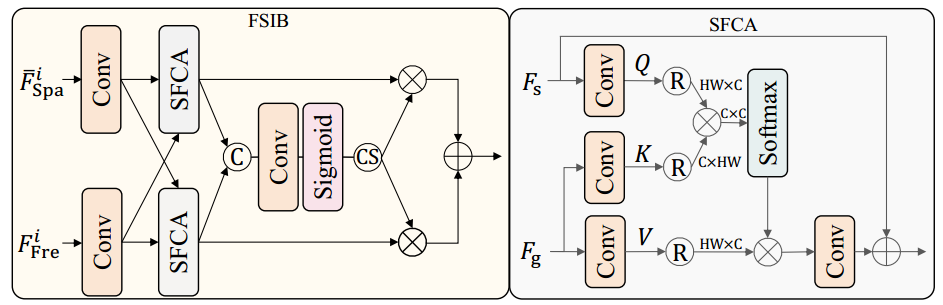
class Attention(nn.Module): def __init__(self, dim=64, num_heads=8, bias=False): super(Attention, self).__init__() self.num_heads = num_heads self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) self.kv = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=bias) self.kv_dwconv = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=bias) self.q = nn.Conv2d(dim, dim , kernel_size=1, bias=bias) self.q_dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim, bias=bias) self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias) def forward(self, x, y): b, c, h, w = x.shape kv = self.kv_dwconv(self.kv(y)) k, v = kv.chunk(2, dim=1) q = self.q_dwconv(self.q(x)) q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads) k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads) v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads) q = torch.nn.functional.normalize(q, dim=-1) k = torch.nn.functional.normalize(k, dim=-1) attn = (q @ k.transpose(-2, -1)) * self.temperature attn = attn.softmax(dim=-1) out = (attn @ v) out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w) out = self.project_out(out) return out class FuseBlock7(nn.Module): def __init__(self, channels): super(FuseBlock7, self).__init__() self.fre = nn.Conv2d(channels, channels, 3, 1, 1) self.spa = nn.Conv2d(channels, channels, 3, 1, 1) self.fre_att = Attention(dim=channels) self.spa_att = Attention(dim=channels) self.fuse = nn.Sequential(nn.Conv2d(2*channels, channels, 3, 1, 1), nn.Conv2d(channels, 2*channels, 3, 1, 1), nn.Sigmoid()) def forward(self, spa, fre): ori = spa fre = self.fre(fre) spa = self.spa(spa) fre = self.fre_att(fre, spa)+fre spa = self.fre_att(spa, fre)+spa fuse = self.fuse(torch.cat((fre, spa), 1)) fre_a, spa_a = fuse.chunk(2, dim=1) spa = spa_a * spa fre = fre * fre_a res = fre + spa res = torch.nan_to_num(res, nan=1e-5, posinf=1e-5, neginf=1e-5) return res
二. 表达:
1. For PSNR-oriented model, both pixel-level and frequency-level loss functions are adopted to guide the learning of the network.
- CVPR_Spatial-Frequency Super-Resolution Resolution Frequency Learningcvpr_spatial-frequency super-resolution resolution cross-refinement super-resolution high-frequency cvpr_spatial-frequency super-resolution super-resolution convolutional resolution real-time super-resolution scale-arbitrary resolution super-resolution continuous resolution diffusion super-resolution vdsr-accurate convolutional frequency high-frequency