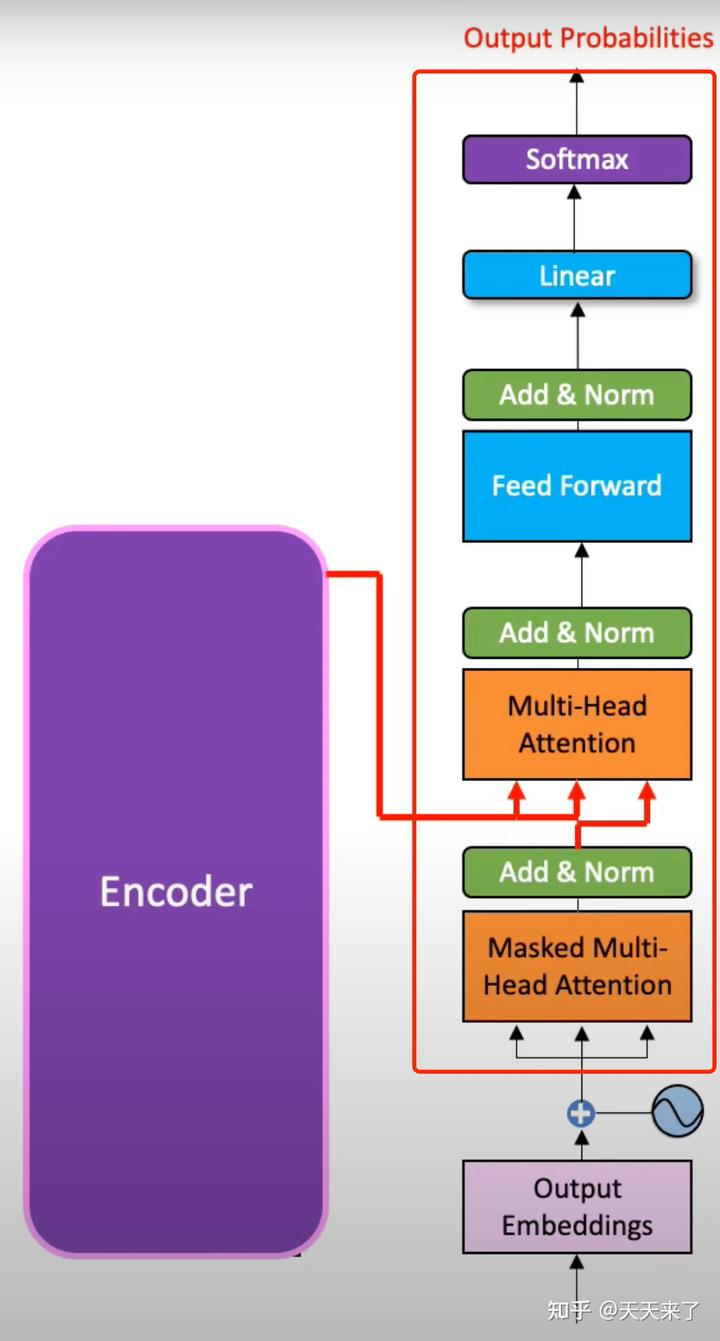

1.数据流程
注:解码的过程会多一个Attention,先加掩码来避免解码获取当前word后的词
数据的计算流程:embeding——》multi head attention——》Add&Norm——》FNN——》Add&Norm——》Linear——》softmax
FNN和多头Attention后面都跟着残差网络:
多头Attention的残差网络:LayerNorm(x+multi head attention(x))
FNN的残差网络:LayerNorm(x+FNN(x))
Feed Forward 层比较简单,是一个两层的全连接层(先升维再降维的过程),第一层加激活函数,第二层不使用激活函数。最后其输出再经过一层Add & Norm。
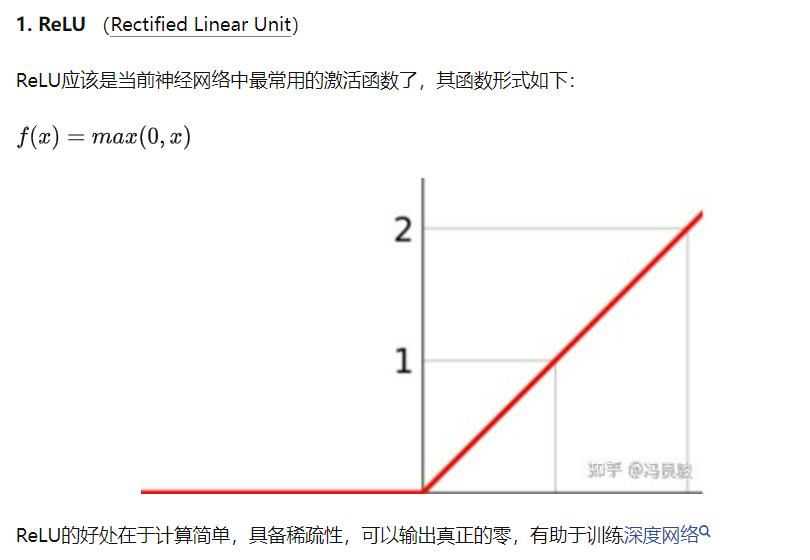
计算过程:y = f(Wx+b)W+b,transfrom论文中使用relu,即为y = max(0, Wx+b)W+b。而在BERT中引入了GeLU激活函数
2.大模型中使用的激活函数
swish激活函数:


各自的优势和缺点
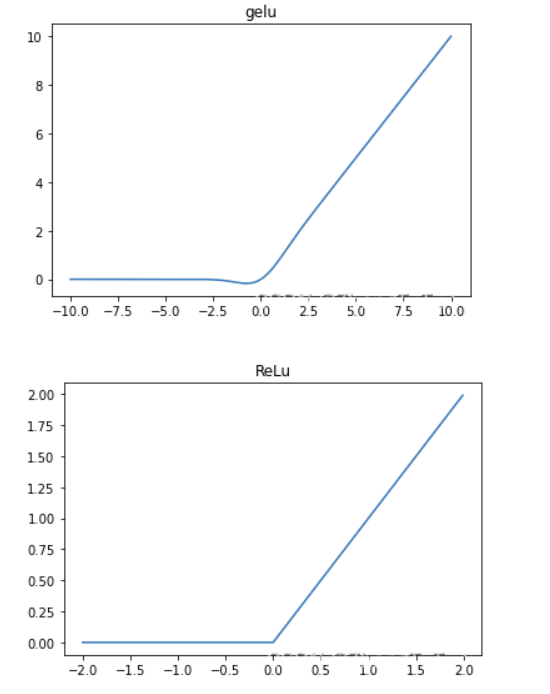
相对于 Sigmoid 和 Tanh 激活函数,ReLU 和 GeLU 更为准确和高效,因为它们在神经网络中的梯度消失问题上表现更好。梯度消失通常发生在深层神经网络中,意味着梯度的值在反向传播过程中逐渐变小,导致网络梯度无法更新,从而影响网络的训练效果。而 ReLU 和 GeLU 几乎没有梯度消失的现象,可以更好地支持深层神经网络的训练和优化。
而 ReLU 和 GeLU 的区别在于形状和计算效率。ReLU 是一个非常简单的函数,仅仅是输入为负数时返回0,而输入为正数时返回自身,从而仅包含了一次分段线性变换。但是,ReLU 函数存在一个问题,就是在输入为负数时,输出恒为0,这个问题可能会导致神经元死亡,从而降低模型的表达能力。GeLU 函数则是一个连续的 S 形曲线,介于 Sigmoid 和 ReLU 之间,形状比 ReLU 更为平滑,可以在一定程度上缓解神经元死亡的问题。不过,由于 GeLU 函数中包含了指数运算等复杂计算,所以在实际应用中通常比 ReLU 慢。
总之,ReLU 和 GeLU 都是常用的激活函数,它们各有优缺点,并适用于不同类型的神经网络和机器学习问题。一般来说,ReLU 更适合使用在卷积神经网络(CNN)中,而 GeLU 更适用于全连接网络(FNN)。
geglu和swiglu都是基于glu的门线性单元而来,glu使用的是原始的sigmoid激活函数,geglu使用gelu来替代sigmoid,swiglu使用swish激活函数


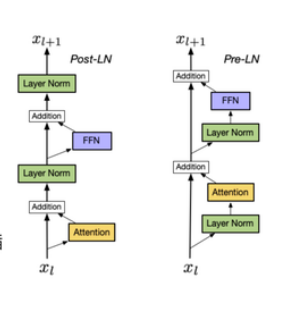
LayerNorm的方式:post Norm,pre Norm RmsNorm deepNorm,一般norm是在FNN和attention之后,前置就是在FNN和Attention计算之前就进行norm计算

位置编码:
