19.知识图谱在反欺诈中的应用
知识图谱的应用价值
19.1知识图谱的应用
(1)对多源异构数据和多维复杂关系的处理与可视化展示:
将人类社会生活与生产活动中难以用数学模型直接表示的关联属性,利用语义网络和专业领域知识进行组织存储,形成一张以关系为纽带的数据网络,通过对关系的挖掘与分析,能够找到隐藏在行为之下的利益链条和价值链条,并进行直观的图例展示。
(2)图神经网络支撑深度学习算法应用:
随着关系向量法深入研究,图神经网络将走向产业应用,届时依托于行业知识与经验的深度学习将产生更多贴近产业核心的认

知识图谱与机器学习相结合的智能风控方案是主流趋势。
在金融领域中无论是传统金融或是互联网金融,信用评估、反欺诈和风险控制都是最为关键的环节,随着近些年金融数据的爆发式增长,传统风控系统逐渐力有不逮,而应用机器学习算法和知识图谱的智能风控系统在风险识别能力和大规模运算方面具有突出优势,逐渐成为金融领域风控反欺诈的主要手段。
机器学习和知识图谱相结合是目前主流的解决方案,其中机器学习算法通过概率计算的方式,以数学运算特征反应风险情况,形成易于机器计算的风控模型;而知识图谱通过权威经验和规则创建本体模型和抽取实体的范围,根据实体间关系形成关联数据网的图谱形式,描画囊括个人基础信息、金融行为、社交网络行为等用户综合画像,根据画像情况和模型对应,形成具有金融业务特性的风控体系,在解决方案的决策环节结合规则和概率的综合评价,给出最终的风险评估,整个过程能够实现秒级响应。
知识图谱的应用不仅能够为缺乏可解释性的机器学习算法带来必要的参考系,还可以串联金融业务中产生的大量多源异构数据形成数据中台,挖掘数据深层价值,为实现精准营销、投资关系梳理、产业链风险预警、智能催收等上层应用打下基础。
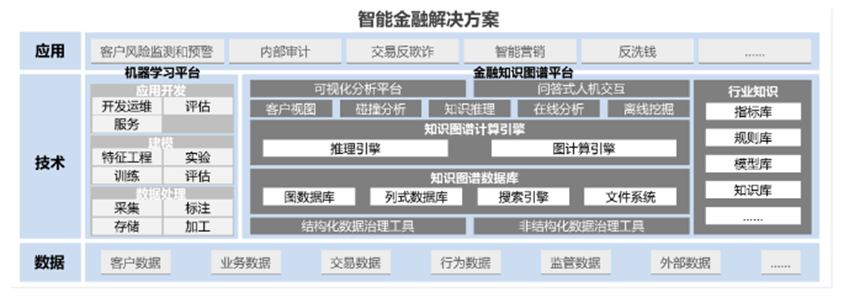
知识图谱在金融领域主要解决的问题是对多源异构数据的知识化整合。金融行业拥有海量包含各行业的数据信息,这些信息又以文字、表格、图形等形式存储在大量文档中,格式非标准统一目呈碎片化存在。
而可用于风控反欺诈,信用评估、营销推荐、产业链分析等应用服务的数据又往往隐藏在多层关联下的细微处,因此采用集自然语言理解技术,处理非标数据,和多维多层级关系挖掘技术,展现数据关联性于一体的知识图谱应用,成为了金融领域较好的中台支撑形式。
以场景最丰富、量级最大的银行业务为例,针对传统技术和手段难以实现的需求,明略科技为某全国股份制银行全行近十年的全量数据构建了包括“企业,个人,机构,账户,交易以及行为数据”在内,规模达十亿节点百亿边的知识图谱数据库。通过知识图谱平台建设来帮助该银行风控体系建立了完整的客户关系网及资金流转全貌,支持了该行非现场审计,系统性风险管控、精准营销等多项应用的研发和实施。
19.2知识图谱在反欺诈中的算法
19.2.1标签传播算法
标签传播算法是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。
利用样本间的关系建立关系完全图模型,在完全图中,节点包括已标注和未标注数据,其边表示两个节点的相似度,节点的标签按相似度传递给其他节点。标签数据就像是一个源头,可以对无标签数据进行标注,节点的相似度越大,标签越容易传播。该算法简单易实现,算法执行时间短,复杂度低且分类效果好,且具有良好的可解释性。
标签传播算法在反欺诈中的应用
通过对调查认定的欺诈客户进行标记,利用标签传播算法,用已标记的“坏”节点信息去预测未标记节点的欺诈风险程度,用边来表示两个节点的相似度,节点的风险程度按照相似度传递给其他节点,风险程度通过图的颜色进行可视化展示。
比如,有三个人:小明、小红、小王,他们是好朋友,现在已知小明是个欠钱不还的人,小红也是个欠钱不还的人那么做为他们的朋友小王,欠钱不还的机率相对一般人,大一些。这和俗话中说的“近朱者赤近墨者黑”是相同的道理。
19.2.2 PageRank算法
PageRank,简称PR,是由Google研发的主要应用于评估网站可靠度和重要性、对网页进行排名的一种算法,是对网页排名进行考量的指标之一。
PageRank算法主要是基于两个假设:一是入链数量假设(一个网页的入链数量越多,那么它的重要程度就越高);二是入链质量假设(高质量的网页将为它的链接页面带去更多权重)。基于这两个假设,PageRank算法为每个页面设置一个初始权重值,根据网页间的链接关系,经过多次迭代后,各个页面的权重值达到稳定。通常认为权重值高的节点是比较可靠的网页。
PageRank算法在反欺诈中的应用
PageRank算法是用PageRank值来标识复杂关系网络中节点重要性的一种方法。在初始阶段,将关系网络中所有节点设置相同的PageRank值,依网络节点相对应的概率转移矩阵不断更新节点的PageRank值,直到节点的PaaeRank值趋干稳定,得到每个节点的最终PageRank值。基于反欺诈数据背景,依据机器学习建模经验将复杂关系网络中每个节点房的最终PageRank值进行高、中、低段分类,寻找高分段的可疑欺诈人群。
这个就是权重越大,风险越大,权重是什么?即认识的人有多少,与他人的联系有多少,重不重要。通俗点讲就是活跃的人群中的坏人比不活跃的人群中的坏人多,可能好人一般是比较低调的吧。
19.2.3社团发现算法
社团发现算法可以借肋网络的各种统计指标来控掘网络中内部关系坚密的社团。社团发现主要其干GN,SIPA Newman等社团发现算法对复杂关系网络中的可疑欺诈团伙进行聚类挖掘。
社团发现算法在反欺诈中的应用
以GN算法为例计算初始复杂关系网络中的边介数(所有节点之间的最短路径中经过该边的最短路径数)及0值(模块度:常用的一种衡量网络社区划分质量的方法),去除边介数最高的边,重新计算当前网络的Q值,若Q值比原来的大,则将现在的Q值和网络分割情况进行更新,否则,进行下一次网络分割,重复直至网络分割完毕。分割后的每个社区中的节点相似度较高,通过寻找欺诈节点在分割后的社区中的分布,挖掘相似度较高的其他可疑欺诈人群。
比如,你发现你们小区里有两伙人,一伙人每天去跳广场舞,另一伙人每天神神秘秘的上课。这俩伙人要去银行借钱。跳广场舞的这伙人里,借钱的都还了,那么这伙人里还没有借钱的人,一旦借钱,还钱的机率就大;上课的一伙人里借钱的人都没还,那么,还没有借钱的人,一旦借钱,不还钱的机率就大。