机器学习(ML)在大规模数据可用的许多应用中的成功,导致了人们对科学学科中类似成就的期望越来越高。数据科学的使用在涉及尚未完全理解的过程的科学问题中尤其有希望。然而,纯粹用数据驱动的方法来建模物理过程可能会有问题。例如,它可以创建一个复杂的模型,它既不能超越训练它的数据,也不能在物理上解释它。当训练数据不足时,这个问题会变得更严重,这在科学和工程领域是很常见的。基于可解释理论的机器学习模型更有可能防止从数据中学习导致不可推广性能的虚假模式。在处理与高风险相关的关键问题(例如,极端天气或生态系统崩溃)时,这一点尤为重要。因此,在复杂的科学和工程应用中,单纯的机器学习方法和单纯的科学知识方法都不能被认为是充分的知识发现方法。该项目正在开发新的技术,以探索基于知识的模型和机器学习模型之间的连续性,其中科学知识和数据是协同集成的。这种综合方法有可能加速一系列科学和工程学科的发现。该项目将培训精通此类方法的跨学科科学家,并将通过同行评议的出版物、开源软件和一系列研讨会传播该项目的成果,以参与更广泛的科学界。
该项目旨在开发一个框架,利用数据科学模型的独特能力,自动从数据中学习模式和模型,而不忽视积累的科学知识的财富。具体来说,该项目通过探索几种将科学知识和机器学习模型结合在一起的方法,建立了知识引导机器学习(KGML)的基础,使用四个领域的试点应用:水生生态动力学、气候和天气、水文和转化生物学。之所以选择这些试点应用,是因为它们正处于知识引导机器学习能够产生变革性影响的临界点。KGML有潜力为科学家和工程师提供对他们感兴趣的领域的新见解,这将需要开发创新的新的机器学习方法和架构,可以结合科学原理。本项目开发的科学知识、KGML方法和软件有可能扩展到广泛的科学应用中,其中使用了机械模型(也称为基于过程的模型)。
Motivation and Goals
机器学习(ML)模型在有大规模数据可用的商业应用中取得了巨大的成功,例如计算机视觉和自然语言处理,开始在推动科学发现方面发挥重要作用。事实上,数据科学在科学学科中的作用正开始从提供简单的分析工具(例如,在大型强子对撞机实验中检测粒子)转变为提供成熟的知识发现框架(例如,在生物信息学和气候科学中)。数据科学的使用在涉及过程的科学问题中尤其有希望,这些过程由于潜在现象的固有复杂性而不能被我们当前的知识体系完全理解。然而,数据科学的黑盒应用概念在科学领域的成功有限。
科学学科中的知识发现有两个主要特征,这些特征阻碍了数据科学模型在商业领域取得成功的水平。首先,科学问题在本质上往往缺乏约束,因为它们涉及大量变量,但代表性的训练样本却很少。此外,科学数据中的变量通常显示出复杂和非平稳的模式,可以随时间动态变化。由于这个原因,有限数量的标记实例可用于训练或交叉验证,往往不能代表科学问题中关系的真正本质。因此,用于评估和确保数据科学模型的通用性的标准方法可能会崩溃并导致误导的结论。特别地,很容易在训练集和测试集上学习看起来良好的伪关系(即使在使用了交叉验证等方法之后),但不能很好地泛化到可用标记数据之外的数据。代表性样本的缺乏是将科学问题与涉及语言翻译或物体识别等互联网规模数据的主流问题区分开来的主要挑战之一,在深度学习等数据科学领域,大量标记或未标记数据对算法的成功至关重要。
限制黑盒数据科学方法成功的科学领域的第二个主要特征是科学发现的基本性质。虽然传统数据科学模型的共同目标是生成可操作的模型,但科学领域的知识发现过程并没有结束于此。相反,是将学习到的模式和关系转化为可解释的理论和假设,从而导致科学知识的进步,例如,通过解释或发现变量之间的因果机制。因此,即使黑盒模型实现了更精确的性能,但产生了物理上不一致的结果(因此缺乏提供对底层过程的机械理解的能力),它也不能用作后续科学发展的基础。此外,基于可解释理论的机器学习模型更有可能防止从数据中学习导致不可推广性能的虚假模式。这在处理本质上至关重要且与高风险相关的问题(例如,极端天气或生态系统崩溃)时尤为重要。因此,在复杂的科学和工程应用中,单纯的ml方法和单纯的科学知识方法都不能被认为是充分的知识发现方法。相反,有必要探索基于知识的模型和ML模型之间的连续性,其中科学知识和数据以一种协同的方式集成。
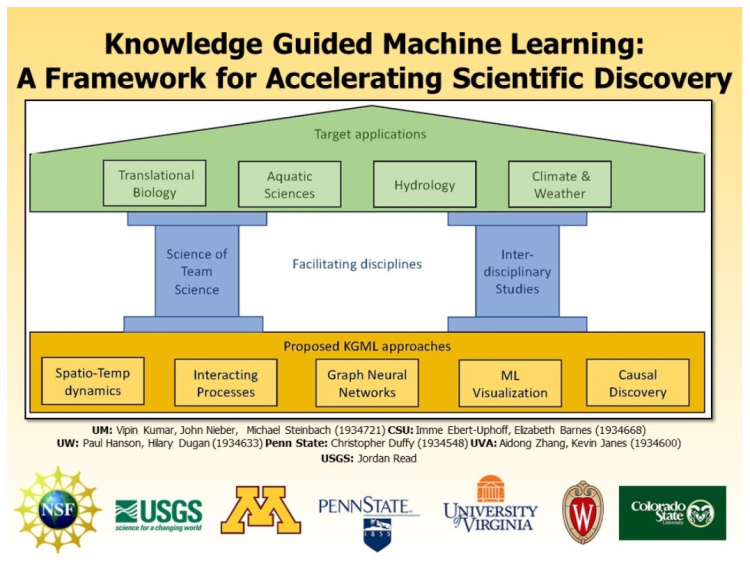
本研究旨在开发一个框架,利用数据科学模型的独特能力,从数据中自动学习模式和模型,而不忽视积累的科学知识的宝藏。如图1所示,通过探索几种将科学知识和机器学习模型结合在一起的方法,本文提出的工作建立了知识引导机器学习的基础,这些方法使用了四个领域的试点应用:水生态动力学、气候和天气、水文和转化生物学。之所以选择这些试点应用程序,是因为它们正处于知识引导机器学习能够产生变革性影响的临界点。
该提案的主要目标是正式概念化“知识引导的机器学习(KGML)”范式,在知识发现过程中,科学理论与机器学习模型系统地集成。这种模式将广泛适用于改进物理和生物系统的建模,其中使用了机械模型(也称为基于过程的),因此,KGML有可能加速一系列科学和工程学科的发现。
The KGML Paradigm
知识引导的机器学习(KGML)范式旨在为机器学习(ML)的角色带来革命性的变化,以加速科学发现,KGML是一个包揽全局的范例,它包含了将ML方法与不同学科中各种形式的科学知识相结合的任何方法。这种模式的发展将需要创新的新的机器学习方法和架构,可以纳入科学原理。
这个HDR框架项目正在寻求KGML研究的路线图,为这一新兴范式的研究开辟一些新的可能性。我们特别关注于为应用程序构建KGML框架的基础,在这些应用程序中,领域知识以机械模型或基于过程的模型的形式可用,这些模型使用已知的科学原理或机制捕获输入和输出变量之间的关系。
Targeted Applications
通过探索几种将科学知识和机器学习模型结合在一起的方法,该研究为知识引导的机器学习奠定了基础,这些方法使用了四个领域的试点应用:水生态动力学、气候和天气、水文学和转化生物学。所选择的问题是HDR框架提案的理想测试平台,不仅因为它们具有重大的社会相关性,还因为它们所涉及的问题的丰富性和相互关联性,以及解决这些问题所需的建模方法的多样性。只有通过处理具有多样性和复杂性的问题和建模方法,人们才有希望为KGML的新框架建立基础,而为孤立的场景追求这样的框架很可能导致特别的解决方案。这个项目的成功将测量方面的能力KGML框架,使科学进步的有针对性的应用领域和程度奠定了基础,为更广泛的努力创造一个全面的HDR研究所带来的科学,工程,和数据科学社区一起利用KGML框架。
原文获取地址:第1步:打开微信搜索:1号程序员,并关注。第2步:在对话框中输入:E007,即可获取资源地址。