基于动态超表面天线的下行链路大规模MIMO系统
摘要:大规模多输入多输出 (MIMO) 是一项很有前途的技术,可通过利用大量天线将频谱和能源效率提高几个数量级。尽管在理论上取得了进展,但大规模天线阵列的实施在硬件成本、功耗和物理尺寸方面面临着许多实际挑战。在这项工作中,我们研究了下行链路大规模 MIMO 系统,其中基站 (BS) 配备了动态超表面天线 (DMA)。 DMA 可以实现低成本、高能效、平面和紧凑的天线阵列。我们首先1、为基于 DMA 的下行链路大规模 MIMO 系统制定了数学模型。2、然后表征最终系统可实现的总速率,并设计一种高效的交替算法来动态配置 DMA 权重,以最大化可实现的总速率。我们的数值结果表明,除了简单性和低成本之外,正确配置的 DMA 还可以实现与多用户 MIMO 系统的基本限制相当的下行链路总速率性能。
一、介绍
为无线基站(BS)配备大规模天线阵列是提高系统频谱效率并满足不断增长的吞吐量需求的一种有前途的方法[1]。然而,基于传统硬件架构(其中每个天线都需要专用射频链)实现如此大规模的多输入多输出(MIMO)系统面临着许多实际挑战,特别是在大带宽运行时[2]。这些挑战包括高硬件成本和功耗,以及大的物理尺寸和受限的形状,这给在密集的城市环境中部署大规模 MIMO 基站带来了困难。大量研究的重点是通过修改传统天线阵列来降低成本和功耗,利用信号处理技术来减轻这些修改引起的性能下降。所提出的方法包括①减少射频链[3]、[4]数量的混合架构,以及②使用低分辨率量化器[5]和③高效功率放大器[6]来降低功耗。
在这些持续努力的同时,人们提出了用于实现低成本和低功耗大型天线阵列的新颖架构[7]-[9]。一种新兴技术基于动态超表面天线(DMA),它由一系列亚波长超材料辐射器,由波导或空腔激发[10]。一个有吸引力的DMA特性是能够使用简单的固态可切换组件在线重新配置其物理特性。由此产生的简化硬件本质上通过调整天线阵列配置来实现信号处理技术,例如波束成形、模拟组合、压缩和天线选择,而不需要额外的硬件组件[11]。基于超表面的天线成本低、功率效率高,并且可以在相对较小的物理区域的平面表面中封装大量低功率辐射超材料元件[12]。迄今为止,DMA 已被用作雷达系统 [13]、卫星通信 [14] 和微波成像 [15] 的简单、快速、平面和低功耗架构。
在 MIMO 通信的背景下,[16] 研究了 DMA 作为天线阵列的应用,重点关注点对点信道。我们早期的工作 [11] 迈出了探索 DMA 在大规模多用户 (MU) MIMO 系统中的应用的第一步。特别是,[11]专注于上行链路系统,其中 DMA 在 BS 侧使用,即用于接收发送的信号。对于这种设置,[11]提出了一种使用 DMA 进行无线通信的模型,描述了可实现的总速率,并设计了交替 DMA 配置算法。 [11] 的一个重要见解是,在某些情况下,在接收端使用 DMA 与使用全数字优化设计相比,在可实现的总速率以及小尺寸和低成本方面仅存在很小的差距DMA 的数量,使得这个想法本质上是有前途的。然而,迄今为止,尚未研究 DMA 用于下行链路 MU-MIMO 的潜力和有效性。
在这项工作中,我们考虑下行链路场景,即使用 DMA 将一组消息从 BS 传输到多个用户。为了研究使用 DMA 的下行链路大规模 MIMO 系统,我们首先制定了使用基于 DMA 的发射天线的 MU-MIMO 通信模型。使用所提出的模型,我们描述了可实现的和速率的上限,并设计了一种有效的算法来最大化可实现的和速率作为约束线性预编码问题。我们的数值结果表明,通过 DMA 实现的大规模 MU-MIMO 下行链路系统的总速率与此类信道的基本限制相当。此外,与基于传统天线阵列的混合预编码架构(例如相移网络架构[4])相比,DMA 可实现的总速率相似,并且可能有所改进,与具有相同数量的散热器。
本文的其余部分安排如下。第二部分制定了使用 DMA 的下行链路 MU-MIMO 的数学模型。第三部分描述了下行链路可实现的总速率并设计高效的 DMA 配置算法。第四节介绍了模拟结果。
F范数:![]()
酉矩阵: 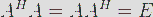 ,若列向量两两正交单位向量,则A酉矩阵。
,若列向量两两正交单位向量,则A酉矩阵。
克罗内克积:
二、系统模型
在本节中,我们制定了所考虑系统的数学模型。我们首先在第 II-A 节中介绍 DMA 的输入输出关系,然后在第 II-B 节中介绍基于 DMA 的大规模 MU-MIMO 下行链路系统。
A、DMA模型。
超表面天线由多个亚波长、频率选择性谐振超材料辐射元件组成[17]。 DMA 是一种由多个微带组成的架构,每个微带由多个可独立调谐的超材料辐射器组成,从而实现大型动态可调谐天线阵列[18]。当用作发射阵列时,每个输出流馈送单个微带,其中信号通过每个 DMA 元件的可配置权重进行加权,然后辐射到无线通道中。
为了对馈入微带的信号与辐射到通道的信号之间的关系进行建模,令 Nd 表示微带的数量,Ne 为每个微带中的元件数量,N , Nd · Ne 为辐射超材料的总数元素。馈送到第 i 个微带的信号沿着波导传播到每个辐射元件,然后在传输之前通过可配置的复数权重进行加权。第 i 个微带的第 l 个元件的元件相关传播被建模为线性时不变滤波器 {hl,i[τ]}LHτ=0,其中 LH 表示滤波器的存储器。元素的可配置权重由 ql,i ∈ Q 表示,其中 Q 表示系数 ql,i 的所有可能值的集合。根据超表面的物理性质,可行值集 Q 有几种典型形式。可能的可行集包括[10]:
①无约束,Q=C
②仅幅度,Q∈(a,b),0<a<b<1
③洛伦兹束缚:![]()
令 si[t] 表示时刻 t 时第 i 个微带线输入端的信号,微带线第 l 个元件传输的信号由下式给出:
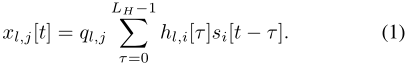
为了以向量形式对 (1) 进行建模,我们使用矩阵 Q ∈ CN×Nd 编写可配置权重,其元素为

其中 l = 1, 2, · · · Ne , Ne 和 i, k = 1, 2, · · · Nd , Nd,我们用 FQ 表示满足上述设置的所有可能矩阵 Q 的集合。对于微带内部的传播,我们使用一组 N × N 对角矩阵 {H[τ]}LH−1 τ=0,其行列索引 (i − 1) Ne + l 处的对角元素为 hl,i[ τ]。使用这些符号,完整阵列的发射信号可以写为向量 x[t] ∈ CN,当微带线的输入是向量 s[t] ∈ CNd 满足 (s[t])i = si [t],由下式给出
![]()
在下一节中,我们将展示如何使用 (2) 中的多元输入输出关系来对具有 DMA 的下行链路 MUMIMO 通信进行建模。
B、大规模 MU-MIMO 下行链路系统模型
我们考虑单小区 MUMIMO 系统中的下行链路场景,其中 BS 配备由 Nd 微带组成的 DMA,每个微带具有 Ne 元素,总共 N = Nd · Ne 元素。 BS同时为K个单天线用户提供服务,如图1所示。
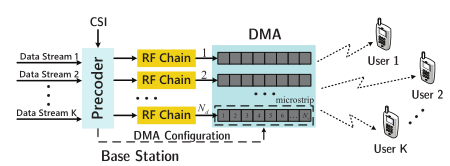
我们考虑一个标准的多径有限内存无线信道,并使用 K × N 矩阵 {G[τ]}LG−1 τ=0 的集合来表示无线信道的抽头延迟线表示,其中 LG 表示总数通道抽头数。通过让由第 t 个时隙的每个辐射元件处的发射信号组成的向量 x[t] ∈ CN 来表示通道输入,则接收向量 y[t] ∈ CK 则由下式给出
![]()
其中 z[t] ∈ CK 是均值为零且协方差矩阵 σ2zIK 的加性高斯噪声向量,与 x[t] 相互独立。无线信道和微带内部传播的影响可以通过将等效信道定义为 〜H[τ] = PL−1 u=0 G[u]H[u − τ] 来组合,其中 L = LH + LG − 1 表示通道抽头总数。使用 DMA 模型 (2),所得下行链路输入输出关系现在可以紧凑地写为
![]()
在这项工作中,我们假设BS处的高斯信令和完美CSI,即{s[t]}是具有相互独立元素的零均值高斯向量,其方差取决于特定的功率分配,并且BS完全了解{ 〜 H[τ]}L−1τ=0 。我们的目标是在提供给 DMA 的总功率(用 PS 表示)的约束下表征下行链路场景可实现的总速率,然后开发一种有效的 DMA 配置方法来最大化总速率,如下一节所述。
三、DMA配置
在本节中,我们提出了一种 DMA 配置方案来最大化可实现的总速率。我们首先关注第 III-A 节中 (4) 中 L = 1 的特殊情况(即频率平坦设置),其中我们推导了 DMA 配置的基本技术。然后,我们将所提出的技术扩展到第 III-B 节中 (4) 中 L > 1 的情况(即频率选择性情况)。
A、频率平坦设置的 DMA 配置
我们从 L = 1 的情况开始。通过写 〜H = 〜H[0],并令 P 为具有非负项和迹 PS 的 Nd×Nd 对角矩阵的集合,给定 Q 和的平均可实现下行链路和速率〜H 由 [19,Ch.1] 给出。 9.5]
![]()
(5)中的矩阵P的对角线整体分配给每个微文字的输入信号。需要强调的是,实现(5)中的基本限制需要脏纸编码[19,Ch.1]。 9.5],这可能在计算上过于复杂而无法在实践中实现。特别地,(5)表示在使用DMA引起的等效信道下可实现的最佳下行链路总速率。我们希望找到使 (5) 最大化的 DMA 权重 Q 和对角矩阵 P,即
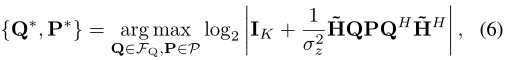
由于 Q ∈ FQ 上的非凸结构约束,找到 (6) 的显式解是一项具有挑战性的任务。这促使我们提出有效的方法来逼近最佳解决方案。遵循[3]、[11]中使用的方法,我们首先忽略 Q 上的结构约束并表征相应的和率最大化矩阵,表示为 Q*UC 和 P*UC,说明以下引理:
引理1:令 V 为矩阵,其列由对应于 ~H 的 Nd 个最大奇异值的右奇异向量组成。那么,最优的全数字配置矩阵为 Q*UC = V [3],相应的功率分配由 (P*UC)i,i = max n 1 λ − σ2zσ2i , 0 o , i ∈ Nd 给出,其中 σ1、σ2、····、σNd 是 ~H 的 Nd 个最大奇异值,并且 λ 的设置使得 Tr (P*UC) = PS。然后,其相应的可实现平均总速率由下式给出
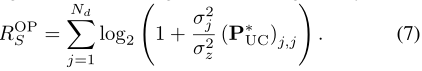
我们注意到,对于每个 Q 和 P,都成立 ~HQPQH ~HH = ~HQ ~PUUH ~PHQH ~HH,其中对角矩阵 ~P 满足 P = ~P2,且 U ∈ U Nd。因此,我们建议设计 Q 〜PU 来近似最小 Frobenius 范数意义上的最优设计 ¯Q*UC = Q*UC(P*UC) 1 2 。因此,我们将 Q 和 ~P 设置为
![]()
请注意,(8) 中 U 的引入提供了额外的自由度,这使我们能够提高近似值的准确性,我们提出了一种交替最小化(AM)算法来求解(8),该算法利用了以下命题中描述的结果。
命题1:a) 对于任意 M ∈ CN×Nd 和对角矩阵 ∼P,QF 的解? M,~P? := arg min Q∈FQ ???Q ∼P − M ??? 2 F 由以下逐项投影给出
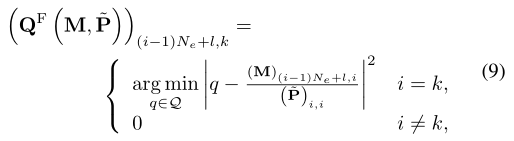
其中 i = 1, 2, · · · , N, j ∈ Nd, l ∈ Ne。
b) 对角矩阵 ∼P 的条目最小化 ∼PF (Q, M) = arg min ∼P2∈P ???Q ∼P − M ??? 2 F 由下式给出
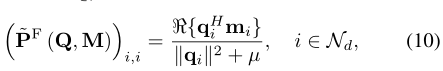
其中 qi 和 mi 分别是 Q 和 M 的第 i 列,μ 的设置使得 k ∼PF (Q, M) k2F = PS。
c) 对于任意M1,M2 ∈ CN×Nd,设 ̅U 和 ̅V 分别为 MH2 M1 的左右奇异向量矩阵,则有:
![]()
证明:证明使用与[11,附录B]中类似的论点获得,并且为了简洁而被省略。
我们建议基于上述命题以交替的方式解决优化问题(8),这在算法1中进行了总结。具体来说,该算法交替在固定P和U下对Q进行优化(步骤2),在固定P和U下对P进行优化(步骤2)固定Q和U(步骤3),并在固定Q和P下优化U(步骤4)。由于目标(8)是可微的,因此保证了收敛性[20]。

B、用于频率选择性设置的 DMA 配置
在这里,我们将第 III-A 节的方法扩展到 L > 1 的情况。我们首先使用[21]中导出的具有存储器的广播信道的容量区域将总速率(5)推广到频率选择性信道。设 ∼Г(ω), ω ∈ [0, 2π), 表示 ∼H[τ] 的离散时间傅立叶变换 (DTFT),最大可实现的和率可写为

其中,具有非负项的对角矩阵集合 {P(ω)} 服从 R 2π 0 tr (P(ω)) dω = 2πPS。(12) 中的积分使得恢复最大化和率的配置矩阵变得困难。为了使问题易于处理,我们固定一些正整数 Nf ,并通过定义 ωn := 2πn Nf ,(12) 可以近似为
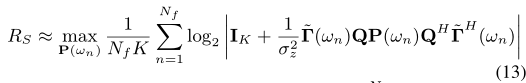
功率约束现在变为 PNf n=1 tr (P(ωn)) = Nf PS。 (13) 中的近似允许我们通过对 Nf 个平坦衰落子信道的速率求和来表达总速率。按照第 III-A 节的方法,我们首先忽略结构约束,在该约束下,通过引理获得相应的最优设计 ¯Q*UC(ωn) = Q*UC(ωn)(P*UC(ωn)) 1 2 1. 将此设置代入 (13) 会产生可实现总速率的上限,由下式给出
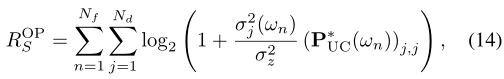
其中 σ1(ωn), · · ·, σNd(ωn) 是 ∼Γ(ωn) 的 Nd 个最大奇异值。我们建议根据以下目标配置 DMA 以接近上限
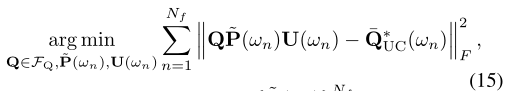
其中对角矩阵 { ~P(ωn)}Nf n=1 服从 PNf n=1 k ~P(ωn)k2F = Nf PS。与(8)类似,酉矩阵 U(ωn) ∈ U Nd 允许我们提高近似的精度。经过一些小的修改,针对平坦通道设置提出的 AM 算法可以扩展到频率选择性设置,从而产生算法 2,该算法利用了以下命题中所述的结果:
引理2:a) 对于任意一组矩阵 {Mn}Nf n=1 和对角矩阵 { ~Pn}Nf n=1,QW?{Mn}, { ~Pn}? 的解:= arg min Q∈FQ PNf n=1 ??Q ∼Pn − Mn ??2 F 是

其中 i = 1, 2, · · · , N, k ∈ Nd, l ∈ Ne。
b) 对角矩阵 { ~Pn}Nf n−1 最小化 ~PWn (Q, {Mn}) := arg min ~Pn PNf n=1 ???Q ~P(ωn) − Mn ??? 2 F ,根据 PNf n=1 k ~Pnk2F = Nf PS 由下式给出
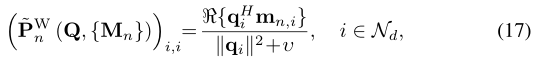
其中qi和mn,i分别是Q和Mn的第i列,ν设置为PNf n=1 k ~Pnk2F = Nf PS。
证明:这个命题的a)部分是通过重复附录a)部分中使用的论证来证明的,即通过明确地写出弗罗贝尼乌斯范数。 b) 部分也可以使用与命题 1 b) 部分类似的论点获得。

四、数值评估
在本节中,我们将与基本限制以及传统的模拟预编码架构相比,对 DMA 实现的总速率性能进行数值评估。我们考虑单小区下行链路 MU-MIMO 设置,其中 K = 16 个用户由 BS 提供服务,这些用户均匀分布在半径 100 m 的六边形区域中,但 BS 周围有一个半径 40 m 的例外区域。我们设置 DMA 元素总数 N = 120,微带线数量 Nd = 12。根据[11],无线信道矩阵 {G[τ]}LG−1 τ=0 生成为 G[τ] = σ2G[τ]D[τ]GR[τ]Σ 1 2T 。这里,{σ2G[τ]}LG−1 τ=0 是每个抽头的衰减曲线,遵循指数衰减曲线,即 σ2G[τ] = e−τ ; {D[τ]}LG−1 τ=0 是表征路径损耗的 K × K 对角矩阵,其中 (D[τ])k,k = γk[τ]/d2k,其中 {γk[τ]} 表示阴影衰落系数是独立于对数正态随机变量得出的,标准差为8dB,dk表示第k次使用与BS之间的距离; {GR[τ]}LG−1 τ=0 是瑞利衰落矩阵; ΣT 是天线阵列的相关矩阵,设置为 ΣT = I ⊗ ΣM ,其中 ΣM 表示同一微带中单元之间的空间相关性,由 Jakes 模型[22]建模。具体来说,(ΣM )i,l = J0(0.8π|i − l|),其中J0(·)是第一类零阶贝塞尔函数。
我们的模拟分别使用算法 1-2 对平坦信道和频率选择性信道可实现的平均总速率进行了数值比较。我们计算以下比率:
•ROPS - 由引理 1 和 (14) 分别给出的平坦和频率选择设置的基本限制;
• RUCS - 具有无约束权重的 DMA,即 Q = C;
• RBAS - 具有幅度权重的 DMA,Q = [2 · 10−4, 1];
• RLPS - 具有洛伦兹约束权重的 DMA,即 Q = {q = j+ejφ 2 |φ ∈ [0, 2π]};
• RSNS - 使用部分连接的相移网络的传统混合预编码[23,(S4)]。
结果是针对不同信噪比 (SNR) 值进行 500 次蒙特卡洛模拟的平均值,定义为 SNR = PNf n=1 tr(Г(ωn)ГH(ωn)) Nf Kσ2z 。为了保持公平比较,我们将每个场景中的权重矩阵 Q 归一化为单位 Frobenius 范数,从而导致平均发射功率相等。对于频率选择性情况,我们设置 LG = 2,并将 H[τ] 的 DTFT 设置为 Ψ(ω) = I ⊗ ΨG(ω),其中 Ne × Ne 对角矩阵 ΨG(ω) 满足 (ΨG( ω))l,l = e−(α−jβ(ω))l,表示考虑元件的频率响应和波导内的传播的单个微带的频率选择性曲线。根据[11],我们设置 β(ω) = 1.592 · ω [m−1] 和 α = 0.0006 [m−1],表示由 Duroid 5880 制成的特性阻抗为 50 欧姆的微带,工作频率为 1.9 GHz,元件间距为0.2 自由空间波长 [24,Ch. 3.8]。
平坦信道和频率选择性信道的平均可实现总速率与 SNR 的关系如图 2 和 3 所示。分别为2和3。观察无花果。在图2-3中,我们注意到 RLPS 接近 RUCS ,这表明洛伦兹约束权重引起的性能损失可以忽略不计。仅振幅权重所实现的性能比洛伦兹约束权重所实现的性能稍差。基于传统部分连接移相器的模拟预编码的性能仅在高SNR区域(超过10dB)达到与DMA类似的性能。此外,DMA 实现的性能与忽略权重矩阵结构约束的无约束全数字优化设计实现的理论极限 ROPS 相当。与平坦衰落情况不同,它如图 2 所示。从图 3 可以看出,在考虑所有 DMA 约束的情况下可实现的性能大致相同。这些结果表明,除了低运行功耗和降低硬件复杂性之外,DMA 还能够实现大规模 MU-MIMO 系统的高性能天线阵列。


五、结论
在这项工作中,我们研究了下行链路 MU-MIMO 系统,其中 BS 使用基于 DMA 的天线阵列。我们制定了 DMA 和下行链路场景的数学模型,描述了下行链路可实现的总速率,并设计了两种用于 DMA 权重配置的 AM 算法。我们的数值结果验证了利用 DMA 是为大规模 MIMO 系统实现大规模天线阵列的一种有前景的方法。特别是,它表明 DMA 实现的性能与基本理论极限相当。