爬取壁纸网站和爬取其他的网站没有太大的区别。
这里爬取的是Wallhaven壁纸网站。Awesome Wallpapers - wallhaven.cc
步骤1
准备第三方库
import requests from bs4 import BeautifulSoup import os import datetime
步骤2
申请request,要做个假的UA放到header里面。
headers = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/568.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/4E423F'}
# 随便写的
html = "https://wallhaven.cc/toplist"
requests_html = requests.get(html, headers=headers)
步骤3
F12里面看下我们需要的东西在哪里,不要被预览图所在的位置所迷惑.
利用BeautifulSoup,提取href值。
Soup_all = BeautifulSoup(requests_html.text, 'lxml').find_all("a", class_="preview") for Soup in Soup_all: print(Soup['href'])
步骤4
把这些链接存到list里面,方便依次爬取
url_list = []
for Soup in BeautifulSoup(requests_html.text, 'lxml').find_all("a", class_="preview"):
url_list.append(Soup['href'])
步骤5
图片链接直接在<img id="wallpaper">的src属性里面了
for link in url_list: requests_html = requests.get(link, headers=headers) bs_html = BeautifulSoup(requests_html.text, "lxml") img = bs_html.find('img', id='wallpaper') r = requests.get(img['src']) num += 1 with open("/Users/artcgb/Downloads/壁纸/+ str(num) + ".jpg", 'wb') as f: f.write(r.content)
源代码:
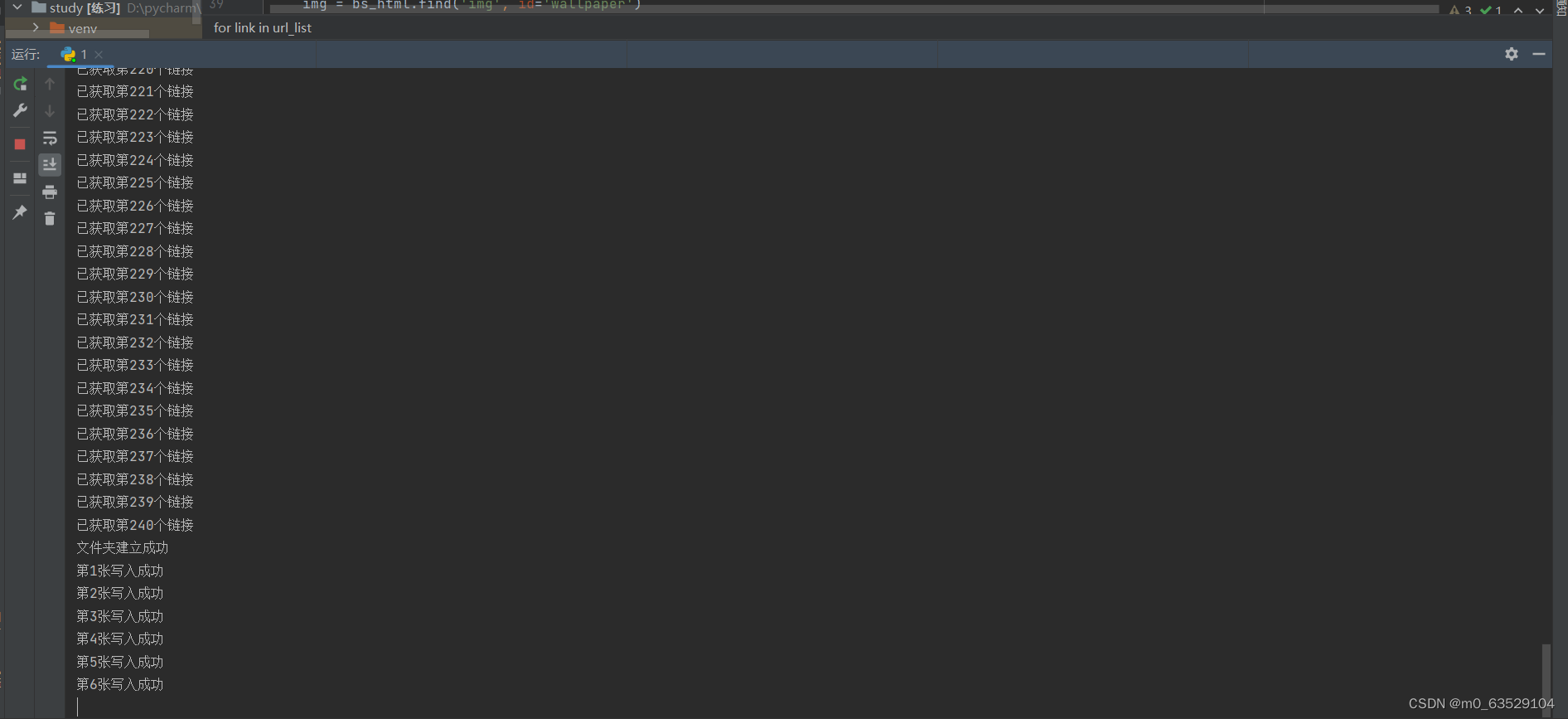
import requests from bs4 import BeautifulSoup import os import datetime now = str(datetime.datetime.today().date()) # 获取当前日期 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58'} num = 0 url_list = [] for page in range(1, 2): html1 = "https://wallhaven.cc/latest?page=" + str(page) html2 = "https://wallhaven.cc/hot?page=" + str(page) html_list = [html1, html2] for html in html_list: requests_html = requests.get(html, headers=headers) bs_html = BeautifulSoup(requests_html.text, "lxml") for link in bs_html.find_all('a', class_="preview"): image_link = link['href'] url_list.append(image_link) num += 1 print("已获取第" + str(num) + "个链接") a = os.path.exists("D:\\test\\picture" + now) if a: print("文件夹已存在,PASS") else: os.mkdir("D:\\test\\picture" + now) print("文件夹建立成功") # 建立文件夹存放图片 num = 0 for link in url_list: requests_html = requests.get(link, headers=headers) bs_html = BeautifulSoup(requests_html.text, "lxml") img = bs_html.find('img', id='wallpaper') r = requests.get(img['src']) num += 1 with open("D:\\test\\picture" + now + "/" + str(num) + ".jpg", 'wb') as f: f.write(r.content) print("第" + str(num) + "张写入成功")
运行结果:


此文章仅用作技术学习,无其他用途。