1. 分类
1.1 motivation
只有两种分类结果的问题成为二分类问题,通常使用0指代false,1指代true
样本也可分为负样本(negative class)和正样本(positive class),例如针对邮件是否为垃圾邮件的问题,正常邮件就是负样本,垃圾邮件就是正样本
由此可知,正负样本并不代表样本的好坏,只是为了传达0、1信息
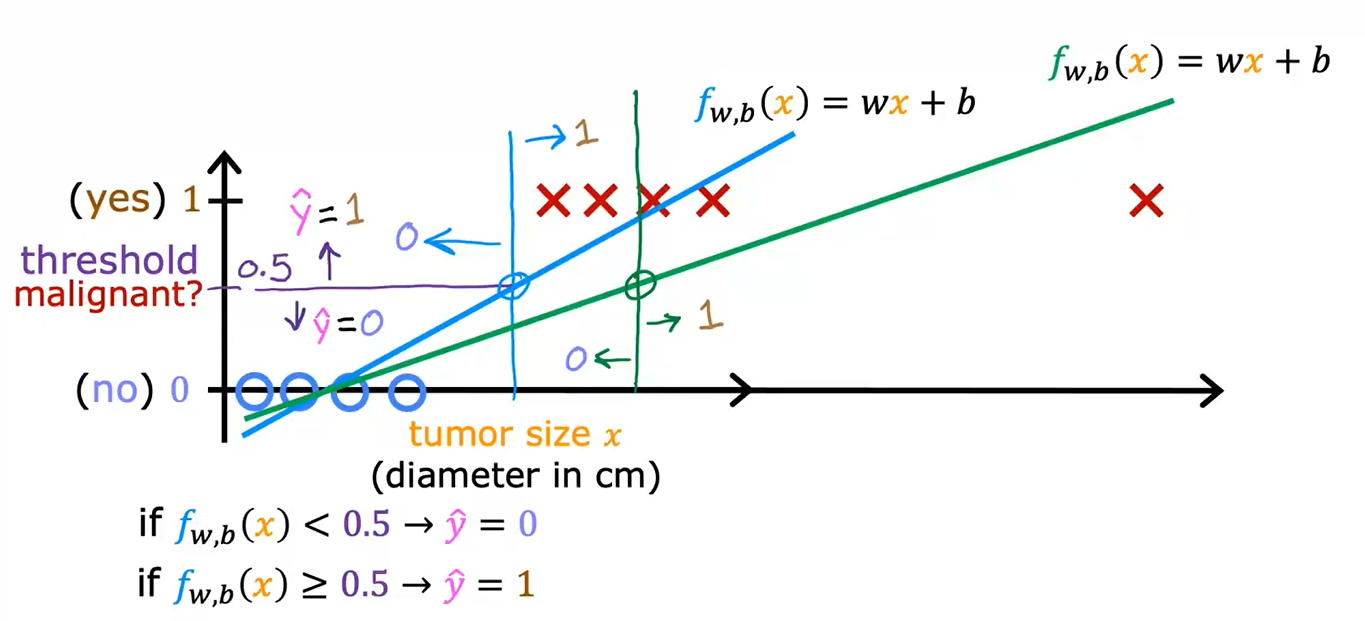
下图展示了一种情况,增加了最右边的看似不会影响分类结果的样本,使用线性回归进行分类的方法得到了更为错误的结果
1.2 逻辑回归
Logistic Regression,逻辑回归,尽管名字中含有“回归”,但逻辑回归实际上是一种分类算法,而不是回归算法。
逻辑回归的基本思想是,它使用一个称为逻辑函数(或S形函数)的数学函数来将输入特征映射到一个介于0和1之间的输出。这个输出可以被解释为某个事件发生的概率。逻辑函数通常采用S形曲线的形状,最常见的是Sigmoid函数。Sigmoid函数将任何实数映射到0和1之间,具体形式为:
其中,$P(Y=1|X) $是事件发生的概率,X 是输入特征,z 是线性组合特征和权重的函数,通常表达为 \(z = w_0 + w_1x_1 + w_2x_2 + ... + w_n*x_n\)。
逻辑回归在实际应用中非常有用,尤其是在二元分类问题中,它可以用于医学诊断、信用风险评估、垃圾邮件过滤等许多领域。它是入门级机器学习算法之一,通常易于理解和实现。
1.3 决策边界
Decision Boundary


2. 逻辑回归的代价函数
2.1 函数
逻辑回归的代价函数不能和线性回归一样使用平均绝对误差
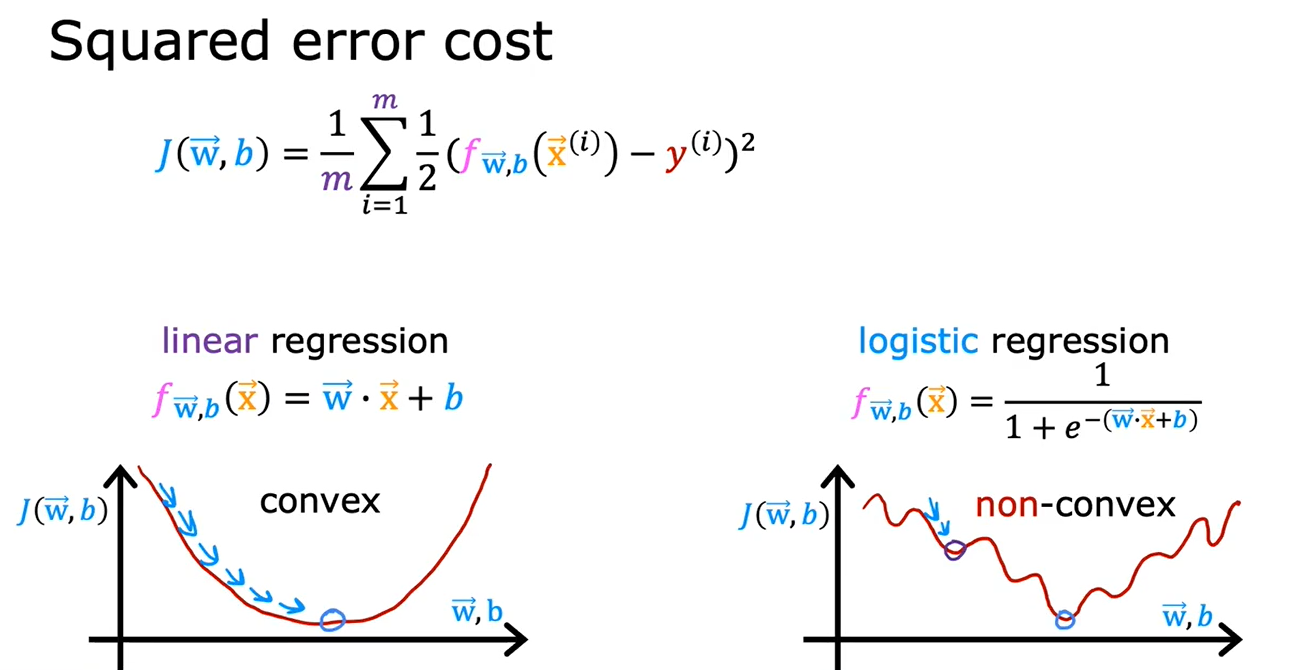
最常见的损失函数是对数损失(Log Loss)或交叉熵损失(Cross-Entropy Loss),有时也被称为逻辑损失(Logistic Loss)或负对数似然(Negative Log-Likelihood)。
对数损失函数的形式如下:
写成分段函数是:

图像如图:
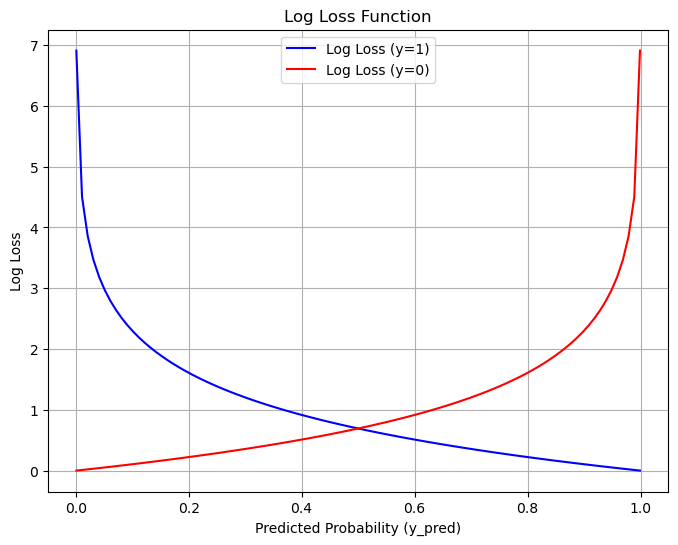
选择这个损失函数后,整个函数就是凸函数了,此时可以安心使用梯度下降法求全局最小值
通常将"损失函数"(Loss Function)和"成本函数"(Cost Function)视为类似的概念,尽管这两个术语在许多情况下可以互换使用,但有时也可以根据上下文来区分它们。一些人可能倾向于在描述模型性能度量时使用"损失函数",而在描述训练过程中的目标函数时使用"成本函数"。不过,这种区分并不是严格的规则,因此在实际使用中,可以将它们视为同义词。
老师给出的ppt里,二者不一样

2.2 代码
损失函数:
def compute_cost_logistic(X, y, w, b):
"""
Computes cost
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i)
cost = cost / m
return cost
3. 梯度下降法

将导数代入式子,即:

计算偏导:
def compute_gradient_logistic(X, y, w, b):
"""
Computes the gradient for linear regression
Args:
X (ndarray (m,n): Data, m examples with n features
y (ndarray (m,)): target values
w (ndarray (n,)): model parameters
b (scalar) : model parameter
Returns
dj_dw (ndarray (n,)): The gradient of the cost w.r.t. the parameters w.
dj_db (scalar) : The gradient of the cost w.r.t. the parameter b.
"""
m,n = X.shape
dj_dw = np.zeros((n,)) #(n,)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b) #(n,)(n,)=scalar
err_i = f_wb_i - y[i] #scalar
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j] #scalar
dj_db = dj_db + err_i
dj_dw = dj_dw/m #(n,)
dj_db = dj_db/m #scalar
return dj_db, dj_dw
梯度下降函数:
def gradient_descent(X, y, w_in, b_in, alpha, num_iters):
"""
Performs batch gradient descent
Args:
X (ndarray (m,n) : Data, m examples with n features
y (ndarray (m,)) : target values
w_in (ndarray (n,)): Initial values of model parameters
b_in (scalar) : Initial values of model parameter
alpha (float) : Learning rate
num_iters (scalar) : number of iterations to run gradient descent
Returns:
w (ndarray (n,)) : Updated values of parameters
b (scalar) : Updated value of parameter
"""
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_db, dj_dw = compute_gradient_logistic(X, y, w, b)
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( compute_cost_logistic(X, y, w, b) )
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]} ")
return w, b, J_history #return final w,b and J history for graphing