1.算法理论概述
MNIST手写数字数据库是机器学习中常用的数据集,包含了0到9这10个数字的手写图片。本文介绍一种基于AutoEncoder自编码器的MNIST手写数字识别算法,通过训练自编码器对MNIST数据集进行特征提取和降维,对提取的特征进行分类识别。该算法在MNIST数据集上表现良好,并且具有较高的识别准确率。
该算法的主要步骤如下:
第一步:数据预处理
从MNIST数据库中加载手写数字图片,对图片进行预处理,将像素值缩放到[0, 1]范围内,以便于神经网络的训练。
第二步:构建AutoEncoder自编码器
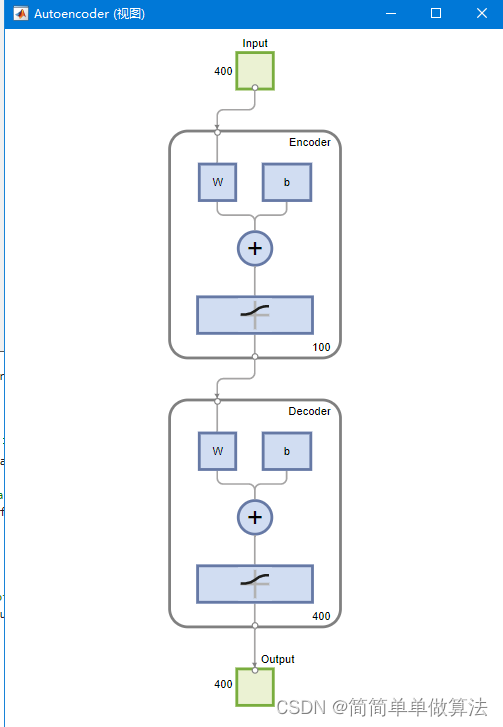
自编码器是一种无监督学习的神经网络,用于将输入数据经过编码和解码过程后,重构与原始输入相似的输出。在该算法中,构建一个多层的自编码器网络,包括输入层、编码层和解码层。编码层的神经元数量较少,从而实现对输入数据的降维。具体步骤如下:
a) 输入层:将MNIST手写数字图片展平为一个一维向量,作为自编码器的输入。
b) 编码层:选择适当的神经元数量,将输入特征进行编码,得到编码后的特征向量。
c) 解码层:通过反向传播算法优化网络参数,实现对编码特征的解码,得到重构后的输出。
d) 损失函数:定义一个适当的损失函数,衡量重构输出与原始输入之间的差异,通过最小化损失函数优化网络参数。
自编码器的前向传播过程

基于AutoEncoder自编码器的MNIST手写数字数据库识别算法是一种有效的图像分类算法。通过自编码器进行特征提取和降维,可以得到较低维度的特征表示,可以在MNIST数据集上取得较高的识别准确率。该算法也可以扩展到其他图像识别任务中,具有较好的通用性和适用性。在实际应用中,可以根据具体情况对自编码器和SVM进行参数调优,进一步提高识别性能和效率。
2.算法运行软件版本
MATLAB2022a
3.算法运行效果图预览



4.部分核心程序
%训练第一个自动编码器(Autoencoder)
hiddenSize1 = 100;
autoenc1 = trainAutoencoder(xTrainImages,hiddenSize1,'MaxEpochs',500,'L2WeightRegularization',0.004,'SparsityRegularization',4,'SparsityProportion',0.15,'ScaleData',false);
figure
plotWeights(autoenc1);
view(autoenc1)
%获取第一个自动编码器的特征
feat1 = encode(autoenc1,xTrainImages);
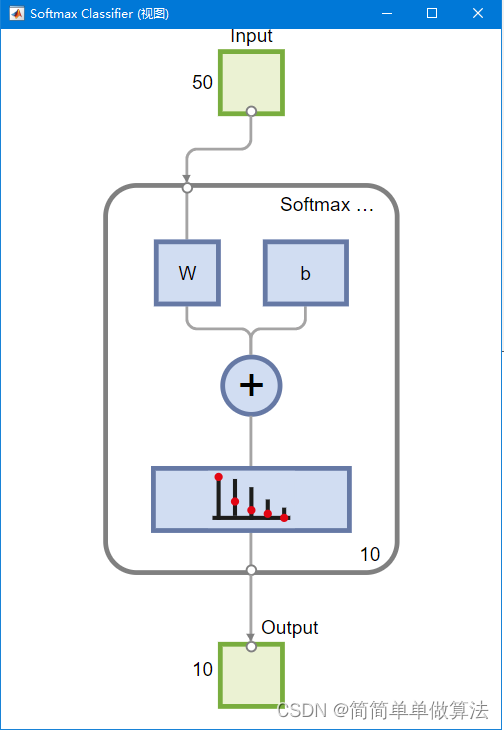
view(softnet)
% 将自动编码器和softmax分类层堆叠成深度神经网络(Deep Neural Network,DNN)
deepnet = stack(autoenc1,autoenc2,softnet);
view(deepnet)
%进行识别
tmp2s = imgs(:,:,1);
y = deepnet(tmp2s(:));
y
[V,I] = max(y);
disp('识别结果为:');