1. 绪论
学到什么程度:

1.1 基本术语
- 特征:反映事件或对象在某方面的表现或性质的事项,例如"色泽""根蒂" "敲声",称为"属性" (attribute) 或"特征" (feature);
- 样本空间:属性张成的空间称为"属性空间" (attribute space) "样本空间" (samp1e space)。"例如我们把"色泽" "根蒂" "敲声"作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间,每个西瓜都可在这个空间中找到自己的坐标位置。x = (青绿;蜷缩;浊响)是其中一个西瓜样本
- 泛化:由于机器学习的目标是根据已知来对未知做出尽可能准确的判断,因此对未知事物判断的准确与否才是衡量一个模型好坏的关键,我们称此为“泛化”能力。
- 分布:此处的“分布”指的是概率论中的概率分布,通常假设样本空间服从一个未知“分布”D,而我们收集到的每个样本都是独立地从该分布中采样得到、即“独立同分布”。如果不是独立同分布,无法学习。通常收集到的样本越多,越能从样本中反推出D的信息,即越接近真相。
- 没有免费的午餐定理:众算法生而平等。脱离具体问题,空泛谈论什么算法更好毫无意义。
数据决定模型的上限,而算法让模型不断接近上限
2. 模型评估与选择
2.1 过拟合与欠拟合

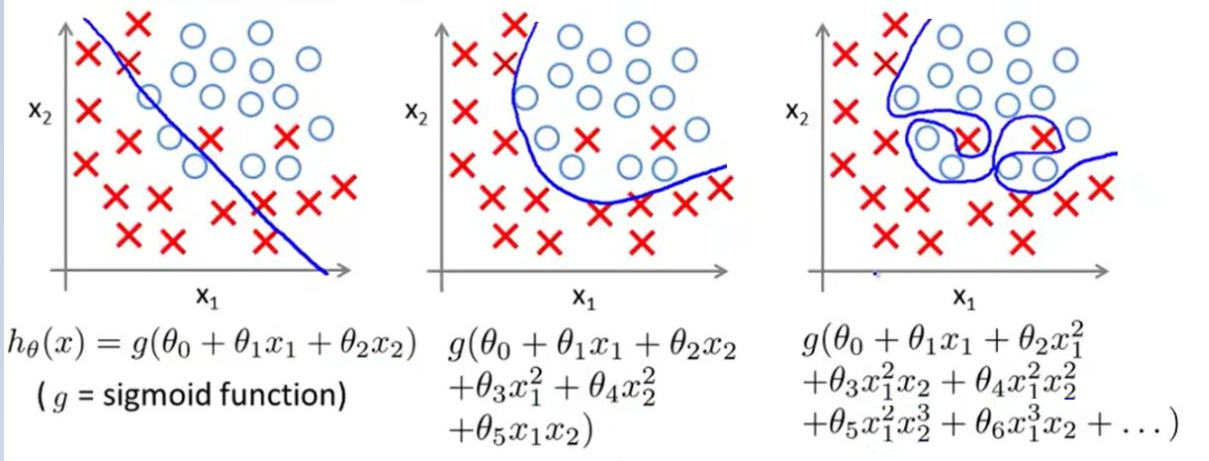
上图分别为:欠拟合,正常,过拟合
图片中的是多项式回归任务。图一左边的应该是欠拟合,没有将x与o正确分类,中间的是正常的,右边的是过拟合,原因在与x的n次方中的n这个超参数设置太大,导致对训练数据过于拟合,此时应引入正则化项来惩罚次数较高从而导致过大的系数。图二同理。
2.2 评估方法
2.2.1 留出法
例如1000个样本,划700个样本为学习集,剩下300个为测试集
2.2.2 交叉验证法
"交叉验证法" (cross alidation) 将数据集\(D\)分为k个大小相似的互斥子集,\(D = D_1 \bigcup D_2 \bigcup... \bigcup D_k\), \(D_i \bigcap D_j = \emptyset (i \not= j)\) (í 每个子集尽可能保持数据分布的一致性,即从\(D\)通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余 的那个子集作为测试集;这样就可获得k组训练/试集,从而可进行k次训练和测试。 最终返回的是这k个测试结果的均值。显然,交叉验证法评估结果的稳定 和保真性在很大程度上取决于k的取值,为强调这一点,通常把交叉验证法称为“k折交叉验证”(k-fold cross validation)。k最常用的取值为10 ,此时称为10折交叉验证,其他常用的k取值有5、20等。
2.2.3 自助法

2.3 性能度量
三种最常用的评估指标:
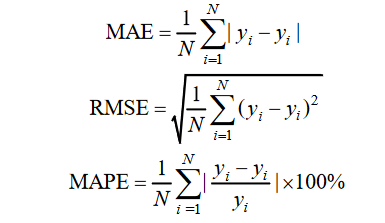
2.3.1 错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。
2.3.2 查准率、查全率与F1
混淆矩阵(Confusion Matrix),针对二元分类问题,将实例分为正类或者负类,会出现四种情况:
(1)实例本身为正类,被预测为正类,即真正类(TP);
(2)实例本身为正类,被预测为负类,即假负类(FN);
(3)实例本身为负类,被预测为正类,即假正类(FP);
(4)实例本身为负类,被预测为负类,即真负类(TN);
查准率(Precision):模型预测为正例数据占预测为正例数据的比例。
查全率(recall):预测为正例的数据占实际为正例数据的比例
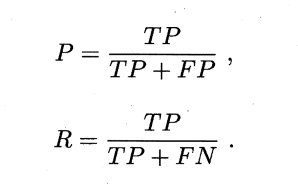
"平衡点 (Break-Event Point ,简称 BEP)就是综合考虑查准率、查全率的性能度量,它是"查准率=查全率"时的取值。若A的BEP大于B,则可断言学习器A优于B。但BEP还是过于简化了些,更常用的是F1度量。
\(F_1\)是基于查准率与查全率的调和平均(harmonicmean)定义的,\(F_\beta\)则是加权调和平均:


2.3.3 ROC与AUC
“真正例率”(True Positive Rate,简称TPR)
“假正例率”(False PositiveRate,简称 FPR)
ROC 是由点(TPR,FPR) 组成的曲线,AUC 就是 ROC 曲线下面积,AUC 越大越好。
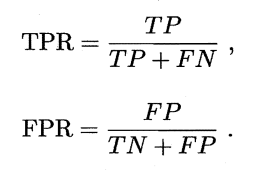
2.4 比较检验
2.5 偏差与方差
学习算法的预测误差,或者说泛化误差(Generalization error) 可以分解为三个部分: 偏差(Bias)方差(Variance)和噪声(Noise)。在估计学习算法性能的过程中,我们主要关注偏差与方差.因为噪声属于不可约减的误差。
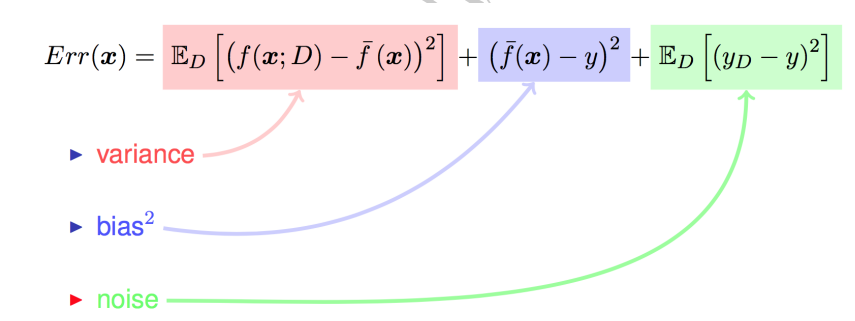
1.偏差: 度量了算法预测结果与真实结果的偏离,刻画了算法的拟合能力;
2.方差: 度量了同样大小的训练集的变动所导致的学习性能的变化,即数据扰动所造成的影响;
3.噪声: 表达了在当前任务上任何算法能达到的泛化误差的下界,即刻画了学习问题本身的难度:
方差与偏差的分解表明,模型的泛化性能是由模型的学习能力、数据量以及数据噪音所决定的。同时偏差与方差是有冲突的,但模型在欠拟合状态时,模型对训练集的拟合程度不够,数据的扰动不足以影响模型;模型在过拟合情况下,模型拟合能力很强,模型也会学习到数据的扰动。