郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NIPS 2016
Abstract
有效的探索仍然是强化学习(RL)的主要挑战。常见的探索抖动策略,如ε-贪婪,不进行时间扩展(或深度)探索;这可能导致数据需求呈指数级增长。然而,在复杂的环境中,大多数用于统计有效RL的算法在计算上是不可处理的。随机化价值函数提供了一种很有前途的泛化有效探索方法,但现有算法与非线性参数化价值函数不兼容。作为解决此类情况的第一步,我们开发了自举DQN。我们证明了自举DQN可以将深度探索与深度神经网络相结合,实现比任何抖动策略都快的指数级学习。在Arcade学习环境中,自举DQN大大提高了大多数游戏的学习速度和累积性能。
1 Introduction
我们研究了智能体与未知环境相互作用的强化学习(RL)问题。智能体采取一系列动作,以最大限度地提高累积奖励。与标准的规划问题不同,RL智能体不是从对环境的完美了解开始的,而是通过经验来学习。这导致了探索与开发之间的根本权衡;智能体可以通过探索不太了解的状态和动作来提高其未来奖励,但这可能需要牺牲即时奖励。为了有效地学习,智能体应该只有在有宝贵的学习机会的时候才去探索。此外,由于任何动作都可能产生长期后果,因此智能体应该对可能的观察序列的信息价值进行推理。如果没有这种时序延伸的(深度)探索,学习时间可能会因指数因素而恶化。
RL理论文献提供了多种可证明有效的深度勘探方法[9]。然而,其中大多数是为具有小有限状态空间的马尔可夫决策过程(MDP)设计的,而其他则需要解决计算上难以解决的规划任务[8]。这些算法在复杂环境中是不实用的,在复杂环境下,智能体必须进行泛化才能有效操作。因此,RL的大规模应用依赖于统计上低效的探索策略[12],甚至根本没有探索[23]。我们在第4节中更详细地回顾了相关文献。
常见的抖动策略,如“-贪婪”,用一个数字来近似一个动作的值。大多数时候,他们会选择估计值最高的动作,但有时他们会随机选择另一个动作。在本文中,我们考虑了一种受汤普森采样启发的有效勘探的替代方法。这些算法有一些不确定性的概念,而是在可能的值上保持分布。他们根据最优策略的概率随机选择一个策略进行探索。最近的工作表明,随机值函数可以实现类似于Thompson采样的功能,而不需要棘手的精确后验更新。然而,这项工作仅限于线性参数化价值函数[16]。我们提出了这种方法的自然扩展,可以使用复杂的非线性泛化方法,如深度神经网络。我们证明了具有随机初始化的自举可以在低计算成本下为神经网络产生合理的不确定性估计。自举DQN利用这些不确定性估计进行高效(深入)探索。我们证明,这些好处可以扩展到大规模问题,而这些问题并不是为了突出深层勘探而设计的。自举DQN大大减少了学习时间,并提高了大多数游戏的性能。该算法计算效率高,可并行化;在一台机器上,我们的实现运行速度比DQN慢大约20%。
2 Uncertainty for neural networks
深度神经网络(DNN)代表了许多监督和强化学习领域的最新技术[12]。我们想要一种在统计上计算高效的探索策略,以及值函数的DNN表示。为了有效地探索,第一步是量化价值估计中的不确定性,以便智能体能够判断探索动作的潜在好处。神经网络文献提出了大量基于参数贝叶斯推理的不确定性量化工作[3,7]。事实上,我们在实验中发现具有随机初始化[5]的简单非参数自举更有效,但本文的主要思想将适用于DNN中的任何其他不确定性方法。
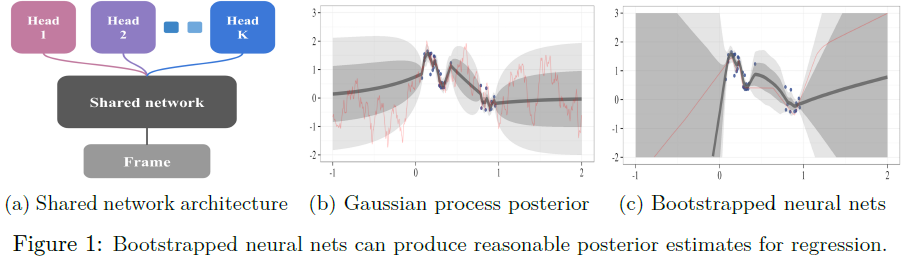
bootstrap原理是通过样本分布来近似总体分布[6]。在最常见的形式中,引导程序将数据集D和估计器作为输入。为了从自举分布生成样本,对基数等于D的数据集~D进行均匀采样,并从D进行替换。然后将自举样本估计取为(~D)。bootstrap被广泛认为是20世纪应用统计学的一大进步,甚至有理论保证[2]。在图1a中,我们提出了一种从大型深度神经网络生成自举样本的高效且可扩展的方法。该网络由一个共享架构组成,其中K个自举“头”独立分支。每个头部仅在其数据的自举子样本上进行训练,并表示单个自举样本。共享网络学习所有数据的联合特征表示,这能够以降低头部之间的多样性为代价提供显著的计算优势。这种类型的自举可以在单个前向/反向传播中有效地训练;它可以被认为是数据相关的dropout,其中每个头的dropout掩码对于每个数据点是固定的[19]。
图1展示了在具有噪声数据的回归任务中,自举神经网络的不确定性估计示例。我们在数据中的50个自举样本上训练了一个全连接的2层神经网络,每层具有50个校正线性单元(ReLU)。按照标准,我们用随机参数值初始化这些网络,这在模型中引入了重要的初始多样性。我们无法使用先前文献[7]中的丢弃方法为该问题生成有效的不确定性估计。更多细节见附录A。
3 Bootstrapped DQN