数据采集与融合实践第四次作业
码云链接 : 第四次作业代码链接
作业①
实验内容
要求
-
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
-
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
思路解析:
- 编写一个类别,专门用于股票数据的存放
class gupiao:
def __init__(self,table_name,attrs):
self.conn = sqlite3.connect(r'G:\database\gupiao.db')
self.cursor = self.conn.cursor()
self.table_name = table_name
self.attrs = attrs
# try:
self.cursor.execute(f"create table {table_name}{attrs};")
# except :
# print("Error")
def insertItem(self,item_list):
self.cursor.execute(f"insert into {self.table_name} values{item_list};")
def showItems(self):
self.cursor.execute(f"select * from {self.table_name};")
result = self.cursor.fetchall()
for row in result:
print(row)
def close(self):
self.conn.commit()
self.conn.close()
- 编写一个函数,获取一个driver
def getLocalDriver(driver_path=None):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
if driver_path ==None:
driver_path = r'G:\Chrome Driver\chromedriver-win64\chromedriver.exe'
driver_service = Service(driver_path)
driver = webdriver.Chrome(service=driver_service, options=chrome_options)
return driver
- 主体函数
def download():
urls = ['http://quote.eastmoney.com/center/gridlist.html#hs_a_board','http://quote.eastmoney.com/center/gridlist.html#sh_a_board','http://quote.eastmoney.com/center/gridlist.html#sz_a_board']
attrs = '(id varchar(5),stockno varchar(10),name varchar(10),attr1 varchar(10),' \
'attr2 varchar(10),attr3 varchar(10),attr4 varchar(10),attr5 varchar(10),' \
'attr6 varchar(10),attr7 varchar(10),attr8 varchar(10),attr9 varchar(10),attr10 varchar(10))'
for url in urls:
table_name = url.split("#")[-1]
db = gupiao(table_name=table_name,attrs=attrs)
driver = getLocalDriver()
driver.get(url)
# content = driver.page_source
tbody = driver.find_element(By.XPATH,'//table[@id="table_wrapper-table"]/tbody')
tr_list = tbody.find_elements(By.XPATH,'.//tr')
print(len(tr_list))
for tr in tr_list :
td_list = tr.find_elements(By.XPATH,'.//td')
td_list = td_list[:3]+td_list[4:14]
item_list = [td.text for td in td_list ]
db.insertItem(str(tuple(item_list)))
db.showItems()
db.close()
- 运行结果,直接在命令行中输出

心得
这一题难度不大,常规的页面解析和selenium的使用,用来熟悉selenium
作业②
实验内容
要求
-
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
-
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国 mooc 网:https://www.icourse163.org
-
输出信息:MYSQL 数据库存储和输出格式
思路解析
这一题难度比上一题大了不少,首先我们希望能够实现程序模拟浏览器登录mooc,模拟浏览器搜索,模拟浏览器点击
- 打开mooc 首页,我们首先需要实现,点击“登录/注册"的按钮
- 查找到对应的按钮元素实现点击,弹出一个iframe页面,这里需要非常注意,我们需要让浏览器驱动将"焦点"切换到这一个窗口,因为这个iframe 和主页页面不属于一个窗口,如果我们希望在iframe下查找元素,就必须要先切换焦点,然后就可以查找输入框元素,输入登录信息,找到点击按钮,就可实现登录
- 登录完成之后,实现模拟浏览器搜索,在上面一步之后,记得将窗口切换回主页面,然后去查找搜索框,模拟搜索即可

- 搜索结果如下,需要注意的是,部分页面是广告,如果我们去爬取广告会报错,因此需要添加一个异常捕获模块,这样就算去解析广告页面也不会出错,另外,一部分数据在每个课程的页面详情页,如果使用单个浏览器去爬取详细页,需要实现点击这个课程,然后爬取完数据之后,在回退到原来的页面,这样子爬取效率就非常低,因此我开了两个driver(方法就是指定不同的端口,这样子两个浏览器就不会冲突了),一个用于解析搜索页面,一个用于爬取详细页。
-
部分代码如下
def download(total_num=3): data_list=[] cnt = 0 page_num=0 while page_num<total_num: page_num = page_num + 1 course_list = driver.find_elements(By.XPATH, '//div[@class="m-course-list"]/div/div') print(len(course_list)) for coursecard in course_list: try: courseItem_list = [] courseItem_list.append(str(cnt)) cnt += 1 # 课程名称 courseItem_list.append(coursecard.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text) # 学校 学校可能为空 try: courseItem_list.append(coursecard.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text) except: courseItem_list.append('') # 教师 courseItem_list.append(coursecard.find_element(By.XPATH, './/a[@class="f-fc9"]').text) # 参与人数 courseItem_list.append(coursecard.find_element(By.XPATH, './/span[@class="hot"]').text) # 详细页链接 course_url = coursecard.find_element(By.XPATH, './/div[@class="t1 f-f0 f-cb first-row"]/a[1]').get_attribute( 'href') # 课程详细页 page_driver.get(course_url) time.sleep(1.5) #进行时间 courseItem_list.append(page_driver.find_element(By.XPATH, '//div[@class="course-enroll-info_course-info_term-info_term-time"]').text) teamMeamber_list = page_driver.find_elements(By.XPATH, '//div[@data-action="点击课程团队头像"]') courseItem_list.append(','.join([member.text for member in teamMeamber_list])) # print(tuple(courseItem_list)) data_list.append(tuple(courseItem_list)) # mooc.insertItem(tablename,tuple(courseItem_list)) except: cnt =cnt-1 pass next_button = driver.find_element(By.XPATH, '//li[@class="ux-pager_btn ux-pager_btn__next"]/a[@class="th-bk-main-gh"]') next_button.click() time.sleep(3) return data_list if __name__=="__main__": url = 'https://www.icourse163.org/' driver = getLocalDriver() page_driver = getLocalDriver(port=1000) login(driver,login_url=url) search(driver,searchKey="大数据") tablename ='testtable' mooc = moocdb(tablename) datalist = download(total_num=1) for data in datalist : mooc.insertItem(str(data)) # print('insert') mooc.show() -
运行结果,命令行直接输出

心得
这个实验做起来还是蛮难的,一开始以为只需要直接进入搜索页面爬数据就好了,没想到还要模拟登录,因为我忘记了行开出一个弹窗,要切换焦点,导致我在这里卡了半天,太久没写过模拟登录的程序了,然后开了两个端口服务提高了爬取效率
作业3
实验内容
-
配置环境,这里就不贴图了,下面的实验均是在环境之下运行的
-
任务一
编写python 脚本
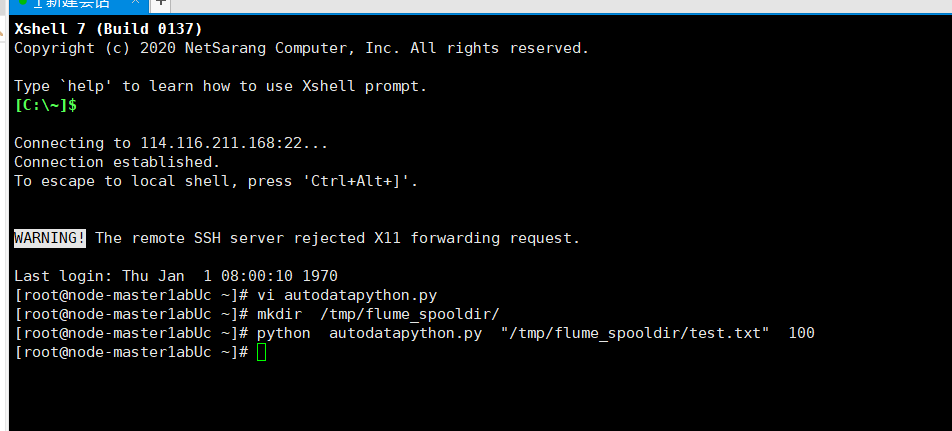
使用 more 查看结果
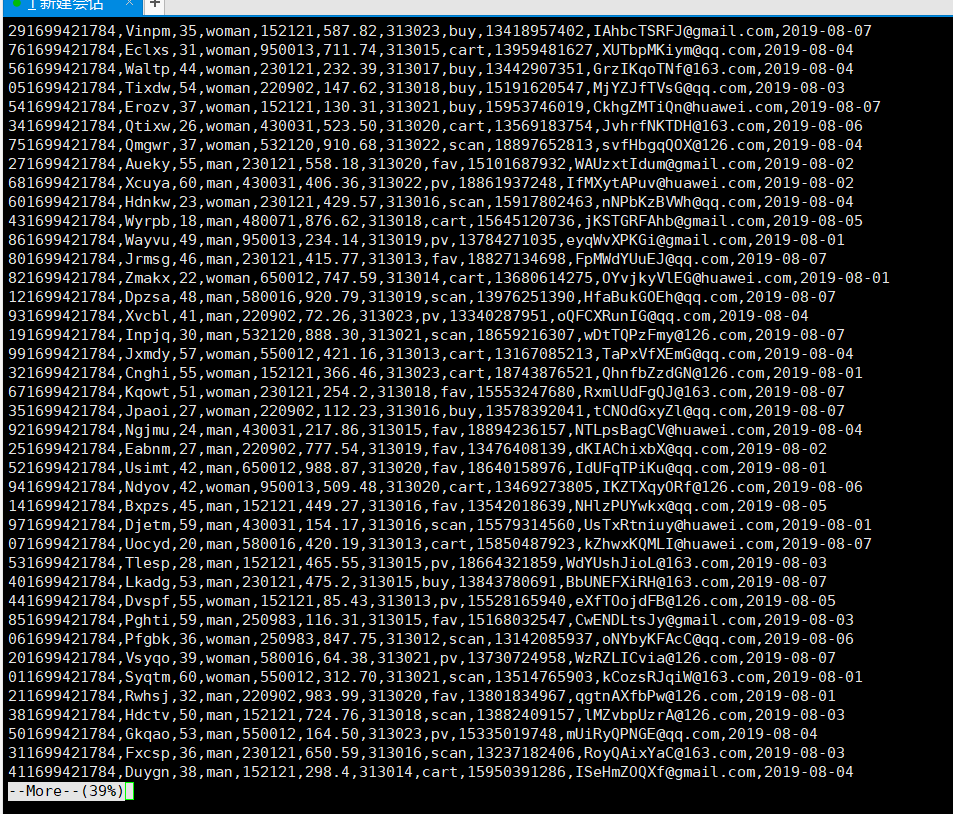
- 任务二,配置kafka
步骤一
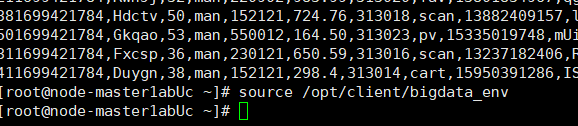
步骤二

步骤三

- 任务三, 配置Flume
下载并解包Flume


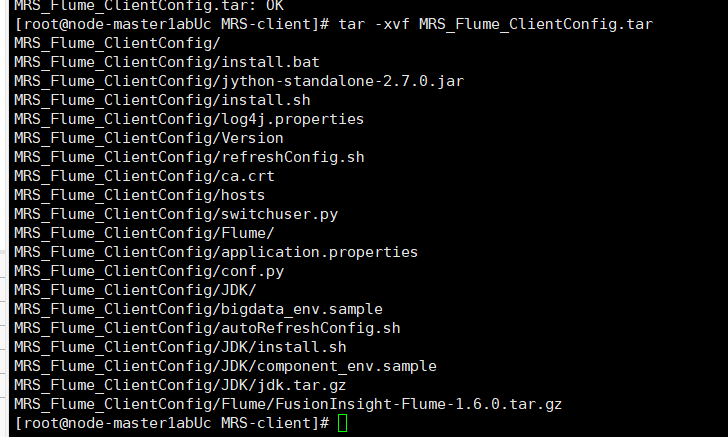
配置Flume 环境变量
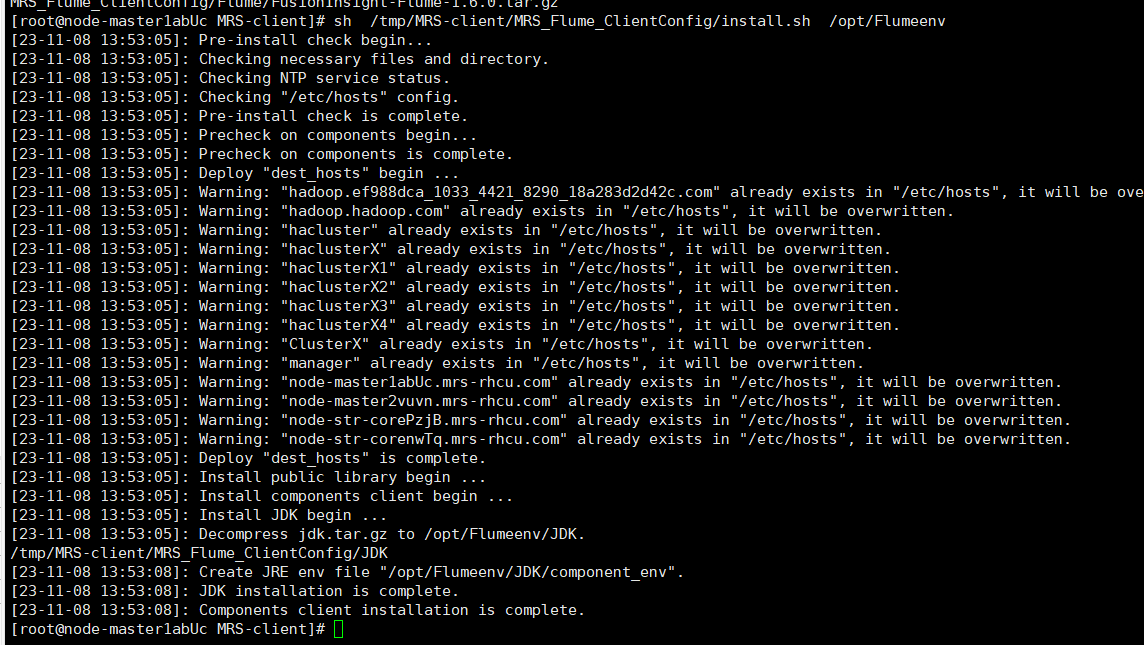

解压并安装Flume

重启Flume服务

- 任务四
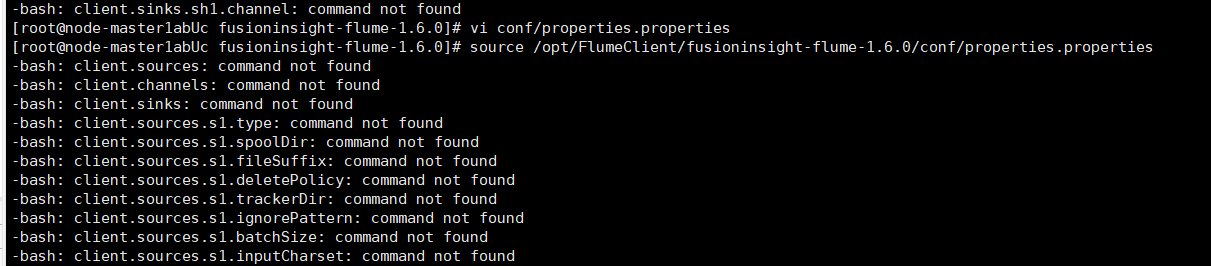
修改配置环境并source,虽然说了一大堆not found 但是不影响后面步骤的进行

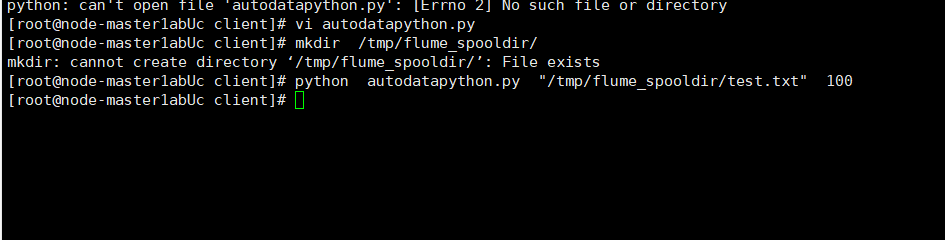
新开一个窗口,执行python脚本
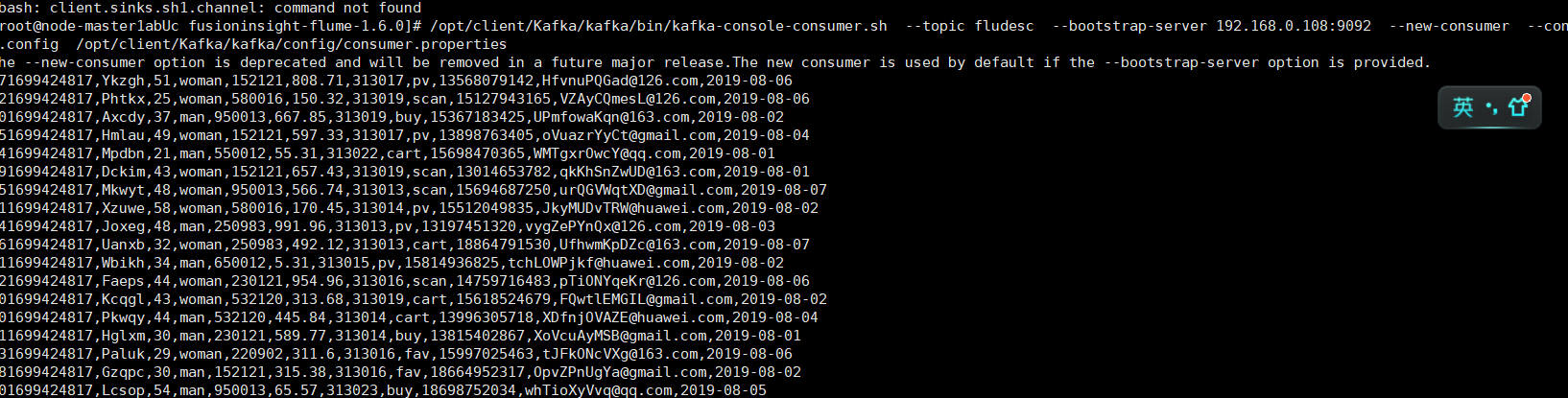
切回原来的窗口,可以看到已经有数据产生了
心得
实验不难,按照手册一步步来,但是对Flume其实还有有点懵懵的,有时间在好好研究一下吧