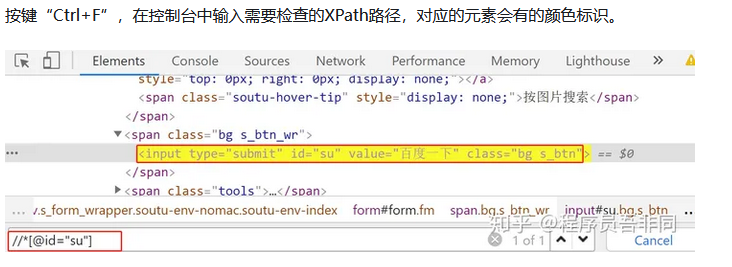
一、直入主题,使用方式
xpath解析原理:
1、实例化一个etree的对象,且需要讲被解析的页面源码数据加载到该对象中
2、调用etree对象中的xpath方法,结合着xpath表达式实现标签的定位和内容的获取
环境的安装
安装lxml模块
pip install lxml
pip install lxml -i xxxxxx
xpath解析
-如何实例化一个对象: from lxml import etree
1、将本地的html文档中的源代码数据加载到etree对象中
etree.parse(filePath)
2、可以讲互联网上的数据源码加载到该对象中
etree.HTML('page_text')
3、xpath('xpath表达式')
二、了解标签,提高数据提前效率
1、无论是xml还是html其实都标签语言,了解标签可以方便的提高数据提取效率
2、通过下面的一个实例来了解一下
· 3、基本标签如下:
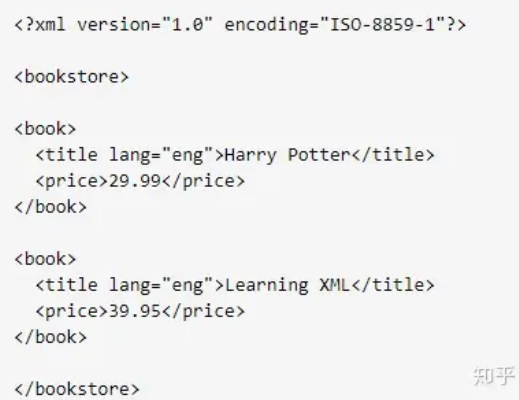



文档参照来自于https://zhuanlan.zhihu.com/p/342903085
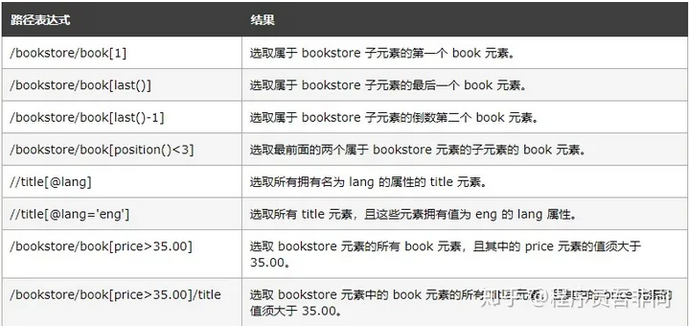
4、XPath常用的定位方式【常用】:
1.元素属性,快速定位,唯一属性: //*[@id="images"]
2.层级与属性结合,解决没有属性问题://div[@id="images"]/a[1]
//没学习这部分之前,一般用bs4的select(.属性 > 下一层 > > >)来获取
3.属性与逻辑结合,解决多个属性重名问题://*[@id="content" and @class="content" ]

注意,表达式里的下标是从1开始的。
绝对定位以/开头,依赖页面的元素的顺序和位置,相对定位以//开头,不依赖页面元素顺序和位置,根据条件进行匹配,优先使用相对定位
4.查找id属性的值包含"kw"的元素: //*[contains(@id,'kw')]
5.查找⽂本⾥包含"新闻"的元素: //*[contains(text(),'新闻')]
获取文本用text() result = li.xpath("./a/text()") # 在li中继续去寻找. 相对查找
获取属性@href : result2 = li.xpath("./a/@href") # 拿到属性值: @属性
6.查找class属性中开始位置包含's_form_wrapper'关键字的元素:
//*[starts-with(@class,'s_form_wrapper')]
7.使⽤多个相对路径去定位⼀个元素⽤//分开:
//div[@class=‘formgroup’]//input[@id=‘user-message’]
8.轴定位,使用::表示
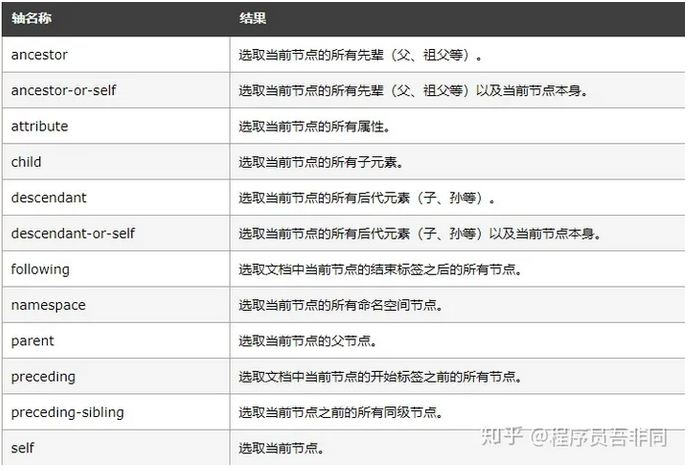
查找id="head"元素后⾯标签名为input的第一个元素
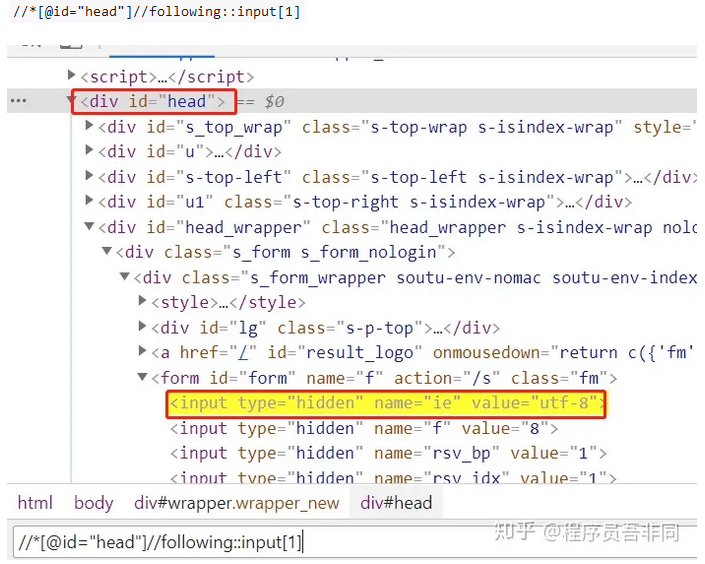
定位轴,平时确实用的很少,感觉还是太麻烦了;如果要获取的话,这里面是多属性的,直接套用3就可以
三、粘贴复制大法
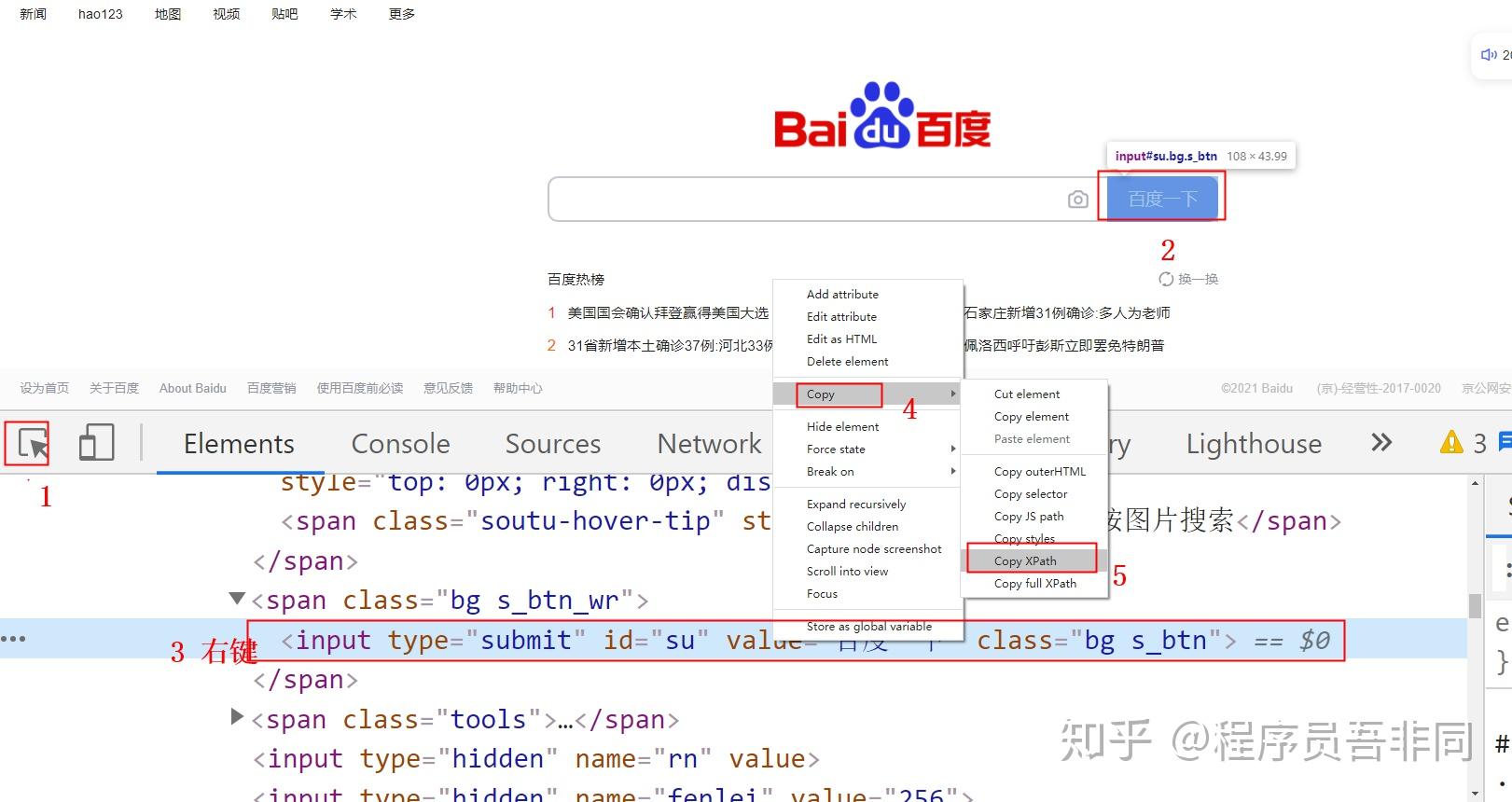
获取到的XPath路径://*[@id="su"]
获取full XPath:/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input