9.6-1-日志收集组件Fluentd高级配置(1)
一、配置文件
在 Fluentd 的配置文件中,有几个常用的关键字和组件,包括 source 、 match 、filter 、 system 、 label 和 @include 。
- source :用于定义 Fluentd 接收数据的来源。
- match :用于定义 Fluentd 对匹配到的数据进行处理,输出到不同的目标等。
- filter :用于在 match 中对匹配到的数据流进行处理和转换操作。
- system :用于设置 Fluentd 自身的配置选项。
- label :用于创建一个逻辑分组,可以将多个输入源、处理规则和输出目标组合在一起。
- @include :用于导入其他配置文件,以便将配置分散到多个文件中进行管理
二、source
source 主要用于定义 Fluentd 接收数据的来源。Fluentd 标准输入插件包括 http 和forward:
- http:提供了一个 HTTP 端点来接受传入的 HTTP 消息,
- forward:提供了一个 TCP 端点来接受 TCP 数据包。
<source>
@type tail
path /var/log/app.log
tag app.logs
format json
</source>配置示例使用 tail 插件来监视文件 /var/log/app.log 的变化,将日志数据标记为app.logs ,且数据格式为 JSON。
当然,也可以同时是两者。例如:
# 在33080端口接受TCP事件
<source>
@type forward
port 33080
</source>
# http://<ip>:33006/myapp.access?json={"event":"data"}
<source>
@type http
port 33006
</source> 输入源可以一次指定多个, @type 参数用来指定输入插件,输入插件扩展了 Fluentd,以检索和提取来自外部的日志事件。
一个输入插件通常创建一个线程、套接字和一个监听套接字,它也可以被写成定期从数据源中提取数据。
Fluentd 提供了丰富的输入插件,以满足不同类型的日志数据来源。以下是一些常见的输入插件及其用途:
- in_tail :监视指定文件的变化,例如日志文件,实时收集新添加的日志行。
- in_forward :作为 Fluentd 的中央服务器,用于接收其他 Fluentd 客户端发送的事件数据。
- in_udp :通过 UDP 协议接收日志事件,这在无需建立持久连接的场景下非常有用。
- in_tcp :通过 TCP 协议接收日志事件,支持稳定的、可靠的传输方式。
- in_unix :监听 UNIX 套接字,接收来自本地进程或外部应用程序的日志事件。
- in_http :通过 HTTP 协议接收来自 Web 服务的结构化日志,可以方便地集成到现有的 Web 应用程序中。
- in_syslog :接收来自 Syslog 服务器的日志事件,支持 Syslog 协议相关的特性和格式。
- in_exec :运行自定义命令或脚本,将其标准输出解析为日志事件进行处理。
- in_sample :用于测试目的,生成随机的示例日志事件,用于验证 Fluentd 配置和管道的正确性。
- in_windows_eventlog :在 Windows 环境中,用于收集 Windows 事件日志。
tail 插件应该是平时我们使用得最多的输入插件!
in_tail 输入插件允许 Fluentd 从文本文件的尾部读取事件,其行为类似于 tail -F命令。
下面的配置就定义了输入插件为 tail ,其中的 path 属性指定了日志的源路径:
<source>
@type tail
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
<parse>
@type apache2
</parse>
</source>注意:
- 当 Fluentd 第一次被配置为 in_tail 时,它将从该日志的尾部开始读取,而不是从开始,一旦日志被轮转,Fluentd 就会从头开始读取新文件,它保持着对当前 inode号的跟踪。
- 就会从头开始读取新文件,它保持着对当前 inode号的跟踪。
如果 Fluentd 重新启动,它会从重新启动前的最后一个位置继续读取,这个位置记录在 pos_file 参数指定的位置文件中。
三、match
match 用于定义 Fluentd 对匹配到的数据进行处理,输出到不同的目标:
<match app.logs>
@type elasticsearch
host localhost
port 9200
</match>匹配标签为 app.logs 的数据流,并将其输出到 Elasticsearch。通过指定Elasticsearch 的主机和端口,Fluentd 将收集的日志数据发送到 Elasticsearch 进行索引和存储。
# 将满足 myapp.acccess 标签的事件全部输出到
# /var/log/fluent/access.%Y-%m-%d
<match myapp.access>
@type file
path /var/log/fluent/access
</match>同样输出也可以一次指定多个, @type 参数指定使用哪一个输出插件。
Fluentd 输出插件的缓冲和刷新模式:
缓冲方式:
- 内存缓冲(memory)模式:
1) 描述:内存缓冲模式是最简单和最快速的模式。它将事件直接存储在内存中,并在达到一定条件时立即刷新到目标输出
2) 适用场景:内存缓冲模式适用于对延迟要求较高的场景,因为它可以快速将事件发送出去。如果Fluentd进程意外终止,内存中的缓冲数据将会丢失。 - 文件缓冲(file)模式:
1) 描述:文件缓冲模式将事件写入磁盘上的临时文件中。当达到一定条件时(例如文件大小或时间间隔),Fluentd 将刷新文件并发送到目标输出。
2) 适用场景:文件缓冲模式适用于对数据持久性要求较高的场景,因为即使Fluentd进程意外终止,文件中的缓冲数据也可以被恢复。但是,相比于内存缓冲,文件缓冲模式的性能可能会稍差一些。 - 无缓冲队列(none)模式:
1) 描述:Fluentd 不会进行任何缓冲,而是直接将事件发送到目标输出。
2) 适用场景:这种模式适用于对实时性要求非常高的场景,但是由于没有缓冲,如果目标输出不可用或出现故障,事件可能会丢失。 - custom(自定义)缓冲模式:
1) 描述:允许根据自己的需求定制缓冲模式。通过编写自定义的缓冲插件,用户可以实现特定的缓冲逻辑,例如将事件缓存到数据库或其他存储系统中。
2) 使用场景:这种模式适用于对缓冲逻辑有特殊需求的场景。
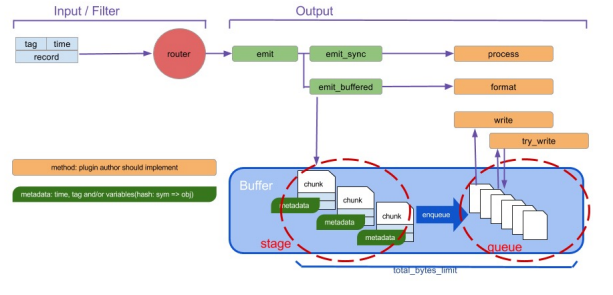
刷新模式:
- interval(时间间隔)模式:
1)描述:在这种模式下,Fluentd 会按照预设的时间间隔定期刷新缓冲区。你可以设置刷新的时间间隔,例如每秒、每分钟或每小时刷新一次。
2)适用场景:用于需要定期刷新缓冲区并将数据发送到目标输出的场景。 - size(大小)模式:
1)描述:在这种模式下,Fluentd 会根据缓冲区的大小来触发刷新操作。可以设置缓冲区的最大size,例如每个缓冲区最多存储1000个事件。一旦缓冲区达到了设定的大小,Fluentd 将立即刷新缓冲区并发送数据到目标输出。
2)适用场景:用于需要根据缓冲区大小来控制刷新频率的场景。 - immediate(立即)模式:
1)描述:在这种模式下,Fluentd 会在每次接收到事件后立即刷新缓冲区并将数据发送到目标输出。这意味着每个事件都会触发一次刷新操作,确保数据尽快被
发送出去。
2)适用场景:用于需要实时传输数据的场景,但可能会对性能产生一定影响。 这些刷新模式可以根据你的需求进行配置和调整,以确保适合你的特定应用场景 - copy(复制)模式:
1)描述:在这种模式下,Fluentd 会将事件同时发送到多个输出目标,而不是仅发送到一个目标。这样可以实现数据的冗余备份或者将数据同时发送到不同的处理流程中。
2)适用场景:用于需要将数据复制到多个目标的场景。
输出插件可以支持所有的模式,但可能只支持其中一种模式,如果配置中没有<buffer> 部分,Fluentd 会自动选择合适的模式。
每个插件都具有不同的功能和用途,可以根据需求选择适合的插件进行配置。
- out_copy :将事件复制到多个输出源。
- out_null :丢弃所有接收到的事件,用于测试或不需要保留数据的情况。
- out_roundrobin :将事件按照轮询的方式均匀地分发给多个输出源。
- out_stdout :将事件输出到标准输出(stdout),通常用于开发和调试。
- out_exec_filter :将事件传递给外部程序进行过滤和处理。
- out_forward :将事件转发到远程 Fluentd 实例或 Fluent Bit。
- out_mongo / out_mongo_replset :将事件写入 MongoDB 数据库。
- out_exec :将事件传递给外部命令进行处理。
- out_file :将事件写入本地文件。
- out_s3 :将事件存储到 Amazon S3 对象存储服务。
- out_webhdfs :将事件存储到 Hadoop 分布式文件系统(HDFS)中的 WebHDFS接口。
- ......
使用 out_file 作为输出目的地插件, out_file 输出插件将事件写入文件。当满足timekey 条件时,将创建该文件,要改变输出频率,需要修改 timekey 的值,如下所示:
<match pattern>
@type file
path /var/log/fluent/myapp
compress gzip
<buffer>
timekey 1d
timekey_use_utc true
timekey_wait 10m
</buffer>
</match>
9.6-2-日志收集组件Fluentd高级配置(2)
四、buffer
在 Fluentd 的 配置块中,可以使用以下参数来配置缓冲区(buffer)的行为 和属性:
- @type :指定缓冲区插件的类型,例如 file , memory , kafka 等。
- flush_mode :设置刷新模式,可以是 interval (基于时间间隔刷新)或immediate (立即刷新)。
- flush_interval :当 flush_mode 设置为 interval 时,指定缓冲区的刷新间隔时间。
- flush_thread_count :指定用于刷新缓冲区的线程数。
- flush_at_shutdown :设置是否在 Fluentd 关闭时刷新缓冲区。
- chunk_limit_size :设置每个缓冲区块的最大大小限制(以字节为单位)。
- total_limit_size :设置缓冲区的总大小限制(以字节为单位)。
- queue_limit_length :设置缓冲队列的最大长度。
- overflow_action :设置缓冲区溢出时的处理方式,可以是 block (阻塞写入)或 throw_exception (抛出异常)。
- retry_max_times :设置发送失败后重试的最大次数。
- retry_wait :设置重试之间的等待时间。
- retry_exponential_backoff :设置是否启用指数退避算法进行重试等待时间的计算。
- retry_forever :设置是否启用无限重试,即不会放弃重试,直到发送成功。
- compress :设置是否压缩缓冲区中的数据。
- timekey :设置基于时间窗口的缓冲区刷新策略。
- timekey_wait :设置时间窗口刷新前的等待时间。
- timekey_use_utc :设置是否使用 UTC 时间来计算时间窗口。
这些参数可以根据你的需求进行配置,以控制缓冲区的行为、性能和容错能力。请注意,不同类型的缓冲区插件可能支持不同的参数,具体取决于所选的插件。
五、filter
使用 filter 可以指定事件的处理流程,多个 filter 可以串联起来使用:
Input -> filter 1 -> ... -> filter N -> Output在 Fluentd 的 配置块中,可以使用以下参数来配置日志过滤器(filter)的行 为和属性:
- @type :指定过滤器插件的类型,例如 record_transformer , grep ,kubernetes_metadata 等。
- @label :指定应用于过滤器输出的标签。
- add_tag_prefix :为匹配成功的日志事件添加前缀。
- remove_tag_prefix :移除匹配成功的日志事件的前缀。
- add_tag_suffix :为匹配成功的日志事件添加后缀。
- remove_tag_suffix :移除匹配成功的日志事件的后缀。
- @id :为过滤器指定唯一的 ID。
- regexp :使用正则表达式进行匹配。
- exclude :排除匹配成功的日志事件。
- key :指定要匹配、修改或删除的字段键名。
- pattern :指定用于匹配的模式或值。
- inject_key :插入新的键值对到日志事件中。
- remove_keys :从日志事件中删除指定的键。
- hash_value_field :指定要哈希化的字段。
- hash_salt :指定哈希函数的盐值。
- hash_algorithm :指定哈希算法。
- hash_hexdigest :设置是否将哈希结果表示为16进制字符串。
- lowercase :将匹配字段的值转换为小写。
- uppercase :将匹配字段的值转换为大写。
Fluentd 的 <filter> 配置块中使用 @type 参数:
- record_transformer :该插件允许对日志事件的记录进行转换和修改。它通常用于添加、删除或修改日志事件中的字段,并支持使用正则表达式匹配和替换字段值。
- grep :该插件用于基于正则表达式对日志事件进行匹配和过滤。它根据指定的模式匹配日志事件,并可以设置将匹配或不匹配的事件传递到下一个步骤的选项。
- kubernetes_metadata :该插件用于从 Kubernetes 服务中获取相关的元数据信息,并将其添加到日志事件中。通过访问 Kubernetes API 来收集容器和 Pod 的标签、名称、命名空间等信息,并将其注入到日志事件中。
比如我们添加一个标准的 record_transformer 过滤器来匹配事件。
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param "#{Socket.gethostname}"
</record>
</filter>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>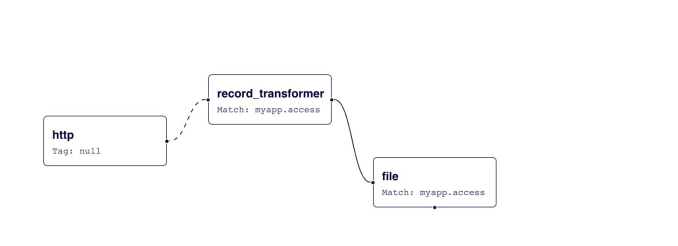
接收到的事件 {"event":"data"} 首先进入 record_transformer 过滤器,该过滤器将 host_param 字段添加到事件中,然后过滤后的事件变为{"event":"data","host_param":"webserver1"} 进入 file 文件输出插件。
当使用 Fluentd 的 kubernetes_metadata 插件时,可以通过以下方式配置它,以获取Kubernetes 容器和 Pod 的元数据信息并将其注入到日志事件中:
<filter your_input_tag>
@type kubernetes_metadata
kubernetes_url 'https://kubernetes.default.svc.cluster.local'
include_namespace_id true
include_pod_id true
include_container_name true
include_container_id false
include_labels true
include_annotations true
cache_size 1000
cache_ttl 300
</filter>在上述示例中, your_input_tag 是此过滤器的输入标签。Fluentd 将会从Kubernetes API 中获取容器和 Pod 的元数据信息,并将其注入到匹配的日志事件中。可以根据需求调整参数值,以满足具体需求。
此配置指定了以下参数:
- @type :必需参数,用于指定过滤器插件类型为 kubernetes_metadata 。
- kubernetes_url :可选参数,指定 Kubernetes API 的 URL。默认值为'https://kubernetes.default.svc.cluster.local' ,适用于大多数
Kubernetes 集群配置。 - include_namespace_id :可选参数,指定是否包含命名空间ID,默认为 true 。
- include_pod_id :可选参数,指定是否包含Pod ID,默认为 true 。
- include_container_name :可选参数,指定是否包含容器名称,默认为 true 。
- include_container_id :可选参数,指定是否包含容器ID,默认为 false 。
- include_labels :可选参数,指定是否包含标签,默认为 true 。
- include_annotations :可选参数,指定是否包含注释,默认为 true 。
- cache_size :可选参数,指定缓存大小,默认为 1000 。
- cache_ttl :可选参数,指定缓存过期时间(以秒为单位),默认为 300 。
注意:为了使用 kubernetes_metadata 插件,需要在 Fluentd 系统上启用相应的插件,并确保 Fluentd 运行在正确的权限和配置下,以便访问 Kubernetes API。
六、system
在 Fluentd 中, system 是一个提供系统级日志收集的插件。该插件可以帮助咱们轻松地获取系统级别的日志信息,并将其发送到所选的目标。
system 插件支持多种系统日志源,如 Syslog、Windows Event Log、Journalctl 等,使你可以灵活地收集各种类型的系统日志。
使用 system 插件收集 Syslog 日志常用功能和配置示例:
<source>
@type system
@id input_syslog
<parse>
@type syslog
</parse>
</source>通过上述配置, system 插件会收集来自 Syslog 的日志事件,并使用 syslog 解析器解析这些事件。
在 Fluentd 的 system 插件中,还有一些其他的细节数据和选项可以配置和使用。以下是这些细节数据和选项的说明:
1、log_level:可以设置日志的级别。日志级别可以是 debug 、 info 、 warn 、 error或 fatal ,用于控制日志的详细程度。
<source>
@type system
@id input_syslog
log_level info
</source>通过上述配置,将设置 system 插件的日志级别为 info 。
2、suppress_repeated_stacktrace:在错误日志中,可以选择是否抑制重复的堆栈跟踪信息。当设置为 true 时,如果连续的错误日志具有相同的堆栈跟踪,只会输出第一个错误的堆栈跟踪信息。
<source>
@type system
@id input_syslog
suppress_repeated_stacktrace true
</source>3、emit_error_log_interval:设置发出错误日志的时间间隔。当出现错误时,插件会将错误信息写入日志,该选项可以设置两次错误日志之间的最小时间间隔(以秒为单位)。
<source>
@type system
@id input_syslog
emit_error_log_interval 60
</source>4、suppress_config_dump:可以选择是否在错误日志中抑制配置信息的输出。当设置为 true 时,错误日志将不包含配置信息的详细输出。
<source>
@type system
@id input_syslog
suppress_config_dump true
</source>5、without_source:可以选择是否在生成的记录中排除原始日志消息。当设置为true 时,生成的记录将不包含原始的日志消息。
<source>
@type system
@id input_syslog
without_source true
</source>6、process_name(仅在 system 指令中可用):在系统级别日志收集时,可以获取生成日志事件的进程的名称,并将其存储在记录字段中。
<source>
@type system
@id input_syslog
process_name_key process_name
</source>通过上述配置, system 插件会将进程名称存储在记录字段 process_name 中。
当使用 system 插件进行系统级别日志收集时,可以获取生成日志事件的进程的名称( process_name ),并将其存储在记录字段中。
以下是一个示例:
<source>
@type system
@id input_syslog
process_name_key process_name
</source>
<match **>
@type stdout
</match>通过上述配置, system 插件将获取系统级别的日志,并将生成日志事件的进程的名称存储在记录字段 process_name 中。然后,日志将通过 stdout 输出插件打印到控制台。
例如,如果有一个应用程序名为 myapp ,并且该应用程序生成了一条日志消息,那么输出的日志记录可能如下所示:
{
"message": "This is a log message",
"process_name": "myapp"
}在上面的示例中, process_name 字段包含了生成日志事件的进程的名称,即 myapp 。
可以根据需要在 Fluentd 的后续处理过程中使用该字段,例如根据进程名称对日志进行过滤、分类或路由到不同的目标,从而实现更具体的日志处理和分析。
9.6-3-日志收集组件Fluentd高级配置(3)
七、label
label 指令可以对内部路由的过滤器和输出进行分组, label 降低了 tag 处理的复杂性。 label 参数是内置插件参数,因此需要 @ 前缀。
例如下面的配置示例:
<source>
@type forward
</source>
<source>
@type tail
@label @SYSTEM
</source>
<filter access.**>
@type record_transformer
<record>
# ...
</record>
</filter>
<match **>
@type elasticsearch
# ...
</match>
<label @SYSTEM>
<filter var.log.middleware.**>
@type grep
# ...
</filter>
<match **>
@type s3
# ...
</match>
</label>这个示例配置文件中有两个输入源(source):
- 第一个输入源是类型为 forward 的源,它用来接收通过 Fluentd 的转发协议发送的日志事件。
- 第二个输入源是类型为 tail 的源,利用 @SYSTEM 标签进行修饰。
接下来是 filter 和 match 配置块:
- 配置块 <filter access.**> 定义了针对标签为 access.** 的过滤器。它使用了record_transformer 插件对日志事件进行转换或添加字段的操作。具体的转换逻辑在 <record> 中定义。
- 配置块 <match **> 定义了将所有标签匹配到的日志事件发送到 Elasticsearch 中进行存储。具体的 Elasticsearch 配置尚未提供,在实际使用时需要根据实际情况进行填写。
最后是 label @SYSTEM 配置块:
- 配置块 <filter var.log.middleware.**> 定义了针对标签为var.log.middleware.** 的过滤器。它使用了 grep 插件对日志事件通过正则表达式进行过滤。
- 配置块 <match **> 定义了将所有标签匹配到的日志事件发送到 S3 存储桶中。具体的 S3 配置尚未提供,在实际使用时需要根据实际情况进行填写。
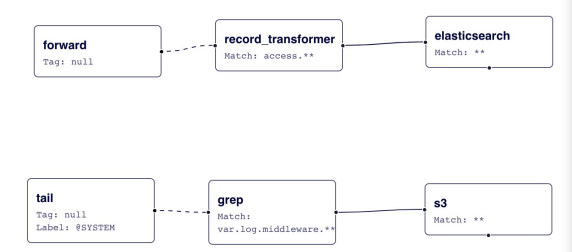
在该配置中, forward 事件被路由到 record_transformer 过滤器,然后输出到elasticsearch ;
而 in_tail 事件被路由到 @SYSTEM 标签内的 grep 过滤器,然后输出到 s3。
label 参数对于没有 tag 前缀的事件流分离很有用。
@include
在 Fluentd 中, @include 是用于包含其他配置文件的指令。
通过使用 @include ,可以将其他配置文件中的配置块导入到当前的 Fluentd 配置文件中,以便进行复用和模块化。
# 包含 ./config.d 目录中的所有配置文件
@include config.d/*.conf@include 指令支持常规文件路径、glob 模式和 http URL 约定:
## 路径可以是一个具体的文件名,也可以是一个匹配模式,以批量包含多个文件。
# 绝对路径
@include /path/to/config.conf
# 如果使用相对路径,指令将使用此配置文件的目录名来扩展路径
@include extra.conf
# glob 匹配模式
@include config.d/*.conf
# http
@include http://example.com/fluent.conf八、parse
在 Fluentd 中, 是一个内置标签,用于解析日志事件中的数据,并将其转换为 结构化的格式。通过解析,可以提取日志事件中的字段,并对其进行处理、转换或过 滤。
<parse> 指令可以在 <source> 、 <match> 或 <filter> 下配置,例如:
<source>
@type tail
path /path/to/apache.log
tag apache.access
<parse>
@type apache2
</parse>
</source>使用了 tail 插件作为输入源来监听 Apache 日志文件。然后,使用 标签以 nginx 类型指定解析方式。
Fluentd 将会根据 Apache 的常见日志格式解析每条日志事件,并将其转换为结构化的 JSON 格式。
除了解析 nginx 格式外,Fluentd 还支持其他许多日志格式的解析,包括:
- regexp:使用正则表达式解析器解析日志事件。你可以指定自定义的正则表达式来提取字段。
- apache2:用于解析 Apache HTTP Server 的访问日志。
- apache_error:用于解析 Apache HTTP Server 的错误日志。
- nginx:用于解析 Nginx Web 服务器的访问日志。
- syslog:用于解析 Syslog 协议格式的日志事件。
- csv:用于解析以逗号分隔的值 (CSV) 格式的日志事件。
- tsv:用于解析以制表符分隔的值 (TSV) 格式的日志事件。
- ltsv:用于解析 Labeled Tab-separated Values (LTSV) 日志格式的插件。
- json:用于解析 JSON 格式的日志事件。
- multiline:用于解析多行日志事件的插件,如堆栈跟踪或消息跨越多行的情况。
- none:不执行任何解析,将日志事件直接传递给输出插件。
比如我们的日志事件中有包含多行日志的数据,那么我们就可以使用 multiline 这个解析器来解决,该插件可以用来解析多行日志。这个插件是正则表达式解析器的多行版本。
多行解析器使用 formatN 和 format_firstline 参数解析日志, format_firstline用于检测多行日志的起始行。 formatN ,其中 N 的范围是 [1..20],是多行日志的Regexp 格式列表。
与其他解析器插件不同,此插件需要输入插件中的特殊代码,例如处理format_firstline 。目前,in_tail 插件适用于多行,但其他输入插件不适用于它。
比如有一条如下所示的输入日志:
Started GET "/users/123/" for 127.0.0.1 at 2023-07-12 12:00:11 +0900
Processing by UsersController#show as HTML
Parameters: {"user_id"=>"123"}
Rendered users/show.html.erb within layouts/application (0.3ms)
Completed 200 OK in 4ms (Views: 3.2ms | ActiveRecord: 0.0ms)我们可以添加如下所示的配置来进行解析:
<parse>
@type multiline
format_firstline /^Started/
format1 /Started (?<method>[^ ]+) "(?<path>[^"]+)" for (?<host>[^ ]+) at (?<time>[^ ]+ [^ ]+ [^ ]+)\n/
format2 /Processing by (?<controller>[^\u0023]+)\u0023(?<controller_method>[^ ]+) as (?<format>[^ ]+?)\n/
format3 /( Parameters: (?<parameters>[^ ]+)\n)?/
format4 / Rendered (?<template>[^ ]+) within (?<layout>.+) \([\d\.]+ms\)\n/
format5 /Completed (?<code>[^ ]+) [^ ]+ in (?<runtime>[\d\.]+)ms \(Views: (?<view_runtime>[\d\.]+)ms \| ActiveRecord: (?<ar_runtime>[\d\.]+)ms\)/
</parse>其中的 format_firstline /^Started/ 用来指定第一行日志的匹配规则, formatN指定后面几行的匹配规则,最后可以解析成如下所示的结果:
time:
1371178811 (2013-06-14 12:00:11 +0900)
record:
{
"method" :"GET",
"path" :"/users/123/",
"host" :"127.0.0.1",
"controller" :"UsersController",
"controller_method":"show",
"format" :"HTML",
"parameters" :"{ \"user_id\":\"123\"}",
...
}同样有如下所示的 JAVA 日志事件:
2023-07-03 14:27:33 [main] INFO Main - Start
2023-07-03 14:27:33 [main] ERROR Main - Exception
javax.management.RuntimeErrorException: null
at Main.main(Main.java:16) ~[bin/:na]
2023-07-03 14:27:33 [main] INFO Main - End我们可以使用下面的配置来解析:
<parse>
@type multiline
format_firstline /\d{4}-\d{1,2}-\d{1,2}/
format1 /^(?<time>\d{4}-\d{1,2}-\d{1,2} \d{1,2}:\d{1,2}:\d{1,2}) \[(?<thread>.*)\] (?<level>[^\s]+)(?<message>.*)/
</parse>这样就可以解析成如下所示的结果了:
time:
2013-03-03 14:27:33 +0900
record:
{
"thread" :"main",
"level" :"INFO",
"message":" Main - Start"
}
time:
2013-03-03 14:27:33 +0900
record:
{
"thread" :"main",
"level" :"ERROR",
"message":" Main - Exception\njavax.management.RuntimeErrorException: null\n at Main.main(Main.java:16) ~[bin/:na]"
}
time:
2013-03-03 14:27:33 +0900
record:
{
"thread" :"main",
"level" :"INFO",
"message":" Main - End"
}九、模糊匹配
在Fluentd中,匹配模式(tag)用于确定哪些日志事件应该被路由到特定的输出插件。
匹配模式(tag)是一个用于过滤和匹配日志事件标签的字符串。当一个日志事件的标签与
匹配模式(tag)匹配时,该事件将被发送到配置的输出插件。
匹配模式(tag)可以使用通配符来进行更灵活的匹配。下面是一些常用的匹配模式(tag)示例:
- 精确匹配: 使用完整的标签名称进行匹配,例如: myapp.logs ;
- 通配符匹配: 使用通配符 * 匹配一个或多个字符,例如: myapp.* 将匹配myapp.logs 、 myapp.errors 等;
- 多级通配符匹配: 使用通配符 ** 匹配任意层级的字符,例如: myapp.** 将匹配myapp.logs 、 myapp.errors 以及 myapp.system.logs 等;
- * :匹配满足一个 tag 部分的事件, 比如: a.* 将匹配 a.b 这样的 tag, 但是不会处理a 或者 a.b.c 这类 tag;
- ** :匹配满足0个或多个 tag 部分的事件,比如 a.** 将匹配 a、a.b、a.b.c 这三种 tag;{X, Y, Z} :匹配满足 X、Y 或者 Z 的 tag,比如 {a, b} 将匹配 a 或者 b,但是不会匹配 c,这种格式也可以和通配符组合使用,比如 a.{b.c}.* 或 a.{b.c}.** ;
- #{...} :会把花括号内的字符串当做是 ruby 的表达式处理。比如
<match "app.#{ENV['FLUENTD_TAG']}">
@type stdout
</match>如果设置了环境变量 FLUENTD_TAG 为 dev,那上面等价于 app.dev 。
- 当指定了多个模式时(使用一个或多个空格分开),只要满足其中任意一个就行。
比如: <match a b> 匹配 a 和 b, <match a.** b.*> 匹配 a, a.b, a.b.c, b.d 等
当有多个 match,需要注意一下它们的顺序,如下面的例子,第二个 match 永远也不会生效:
<match **>
@type blackhole_plugin
</match>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>正确的写发应该是将确定的tag尽量写在前面,模糊匹配的写在后面。
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
# Capture all unmatched tags. Good :)
<match **>
@type blackhole_plugin
</match>另外需要注意顺序的是 filter 和 match,如果将 filter 放在 match 之后,那么它也永远不会生效。
关于 Fluentd 的更多使用配置可以参考官方文档了解更多信息 https://docs.fluentd.org。
十、案例分享
场景一
- 将 /root/my.txt 文件中的日志数据按照指定的格式解析后,通过HTTP POST方法发送到 http://localhost:9090/ 地址。
- 发送的数据格式为JSON,每3秒发送一次。
<source>
@type tail
path /root/my.txt
pos_file /root/my.txt.pos
tag mylog
<parse>
@type regexp
expression /(?<key>\w+)\s(?<value>\w+)/
</parse>
</source>
<match mylog>
@type http
endpoint http://localhost:9090/
open_timeout 2
http_method post
<format>
@type json
</format>
<buffer>
flush_interval 3s
</buffer>
</match>场景二
- 读取指定路径(可以是环境变量或默认路径)的日志文件,不对源数据进行解析,然后向每条记录中添加主机名信息,并将处理后的数据输出到标准输出。
<source>
@type tail
# 这里使用HISTFILE环境变量,如果没有设置,使用默认值/root/.bash_history
path "#{ENV["HISTFILE"] || /root/.bash_history}"
pos_file /root/.bash_history.pos
tag history
<parse>
@type none
</parse>
</source>
<filter history>
@type record_transformer
<record>
hostname ${hostname}
</record>
</filter>
<match history>
@type stdout
</match>场景三
- 收集用户操作记录转发到另一个fluentd节点,同时将数据发送到Kafka和存入HDFS。
- 数据流为:fluentd采集端 -> fluentd收集端 -> kafka和HDFS
- 示例用户操作记录数据为:
root pts/1 2023-06-26 10:59 (10.180.206.1):root 2023-06-26 11:00:09 130 tail -f /var/log/command.his.log采集节点的配置:
<source>
@type tail
path /var/log/command.his.log
pos_file /var/log/command.his.log.pos
tag history
<parse>
@type regexp
# 使用正则解析日志文件
expression /^(?<who_user>\w+)\s(?<pts>\S+)\s(?<who_time>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2})\s\((?<remote_ip>\d+\.\d+\.\d+\.\d+)\):(?<user>\w+)\s(?<time>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2})\s(?<res>\d+)\s(?<command>.+)$/
time_key time
</parse>
</source>
<filter history>
@type record_transformer
<record>
# event内容增加hostname这一行
hostname ${hostname}
</record>
</filter>
<match history>
@type forward
send_timeout 60s
recover_wait 10s
hard_timeout 60s
<buffer>
# 1秒钟向另一个fluentd节点转发一次
flush_interval 1s
</buffer>
<server>
name myserver1
host 10.180.xxx.xxx
port 24225
weight 60
</server>
</match>fluentd收集节点的配置:
<source>
@type forward
port 24225
bind 0.0.0.0
tag remote
</source>
<match remote>
# 使用copy方式,分两路输出
@type copy
<store>
@type kafka2
brokers 10.180.xxx.xxx:9092
use_event_time true
<buffer topic>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
<format>
@type json
</format>
default_topic history
required_acks -1
</store>
<store>
@type webhdfs
host 10.180.xxx.xxx
port 50070
path "/history/access.log.%Y%m%d_%H.#{Socket.gethostname}.log"
<buffer>
flush_interval 60s
</buffer>
</store>
</match>
9.7 基于ElastAlert的告警通知