Abstract
知识图谱,一种相互连接和可解释的结构。
生成需要更多的人力、领域知识、并需要适用于不同的应用领域。
本论文提出借助LLM,通过0-shot和外部知识不可知的情况下生成知识图谱。
主要贡献:
- 迭代的prompting提取最终图的相关部分
- 0-shot,不需要examples
- 一个可扩展的解决方案,不需要额外资源和人力需求。
1. Introduction
KG组织信息以恰当的图结构,节点表示实体,而边表示实体之间的关系。
每个节点和边也可以有额外的属性。
KG具有如下的优点:
- 异质资源信息的推断和整合
- 可以捕捉直接和间接的知识
- 可以直接有效的查询信息
当然,KG的构造也会出现一系列的问题:
比如,缺乏大规模标注数据用于关系提取,导致了利用异质数据集的工具的发展。
而且,开放域中的实体识别和解析理解能力表现的更差,并且缺乏对应的建立好的工具箱和基本知识。
依靠LLM prompting来提升KG的构建效果
2. Research Aims and Motivations
2.1 Problem Statement
要实现高质量数据、可扩展性、自动化的平衡。
问题主要集中在如下方面:
- 数据可用性和可获得性:会受到隐私政策、不同平台、格式和语言的影响。并且数据是动态更新的,可能会导致现有数据的过时。
- 数据质量:需要完整、正确、可靠。为保证这点需要人力去注释数据。尽可能的使得数据可靠并且减少人力,是研究的目标。
- 可扩展性:要适用于不同维度和异构的数据
- 主观性和语境知识:需要语境信息和其他资源。
- 语义消歧:解析同义词、多义词等
- 特定领域的专业知识:保证质量但是会消耗大量人力
- 额外资源: 目前主流解析实体与关系依赖KB,可能会漏。OpenIE不依赖外部知识,但是容易生成错误的triplets。
- 评价: 没有统一的标准和数据。
- 流水线定义:不同阶段任务的交互与整合。
2.2 Main Contribution
选择GPT3.5作为LLM
主要贡献:
- 迭代采用基于LLM prompt的流水线来自动的实现KGs的生成(不需要人力)
- 每个阶段提出合适的prompt能够提取实体(包含描述和类型),关系(包含描述),识别相近三元式,解析实体和关系(不需要第三方资源)
- 0-shot,不需要example
- 借助一些prompt的结果构建基准,有助于应用额外的评估指标。
3 Methodology
3.1 LLM Prompting
采用GPT-3.5-turbo-0301版本
主要用到如下的角色:
- system: 告诉模型如何回答
- user: 用户的信息/请求
- assistant:模型的回答
task instructions -> system prompt
data to operate -> user prompt
receive results -> assistant prompt
温度设置为0(保证每次input获得相同的回答)
3.2 Methodology Overview
整体架构如下:
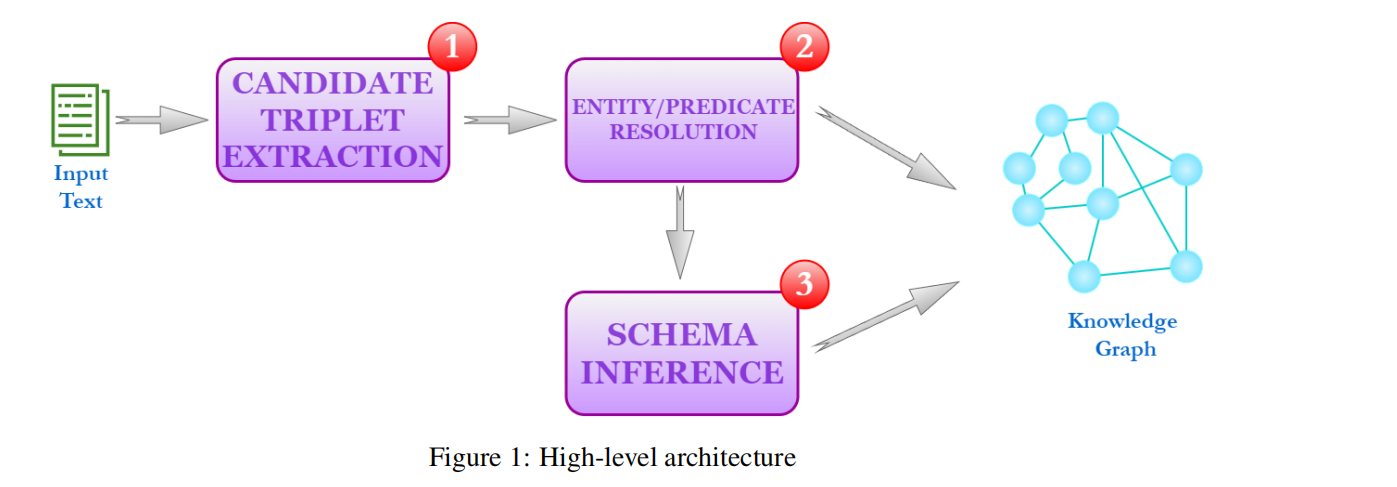
简单介绍一下三个部分:
3.2.1 Candidate Triplet Extraction
合适的实体提取(entity),主要提取出如下部分:
- label
- description
- 类型表(超出实体本身)
关系主要需要提取出label和description
3.2.2 Entity/Predicate Resolution
目标是识别并合并相同含义的实体与关系。
主要面临的挑战:自然语言的模糊性和多义性。
通过初步聚类的方法实现
3.2.3 Schema Inference
KG模式以供重用等,本文提出了一种自动提取模式的方法。
3.3 Knowledge Graph Construction Pipeline
KG的详细的工作过程整体如下:
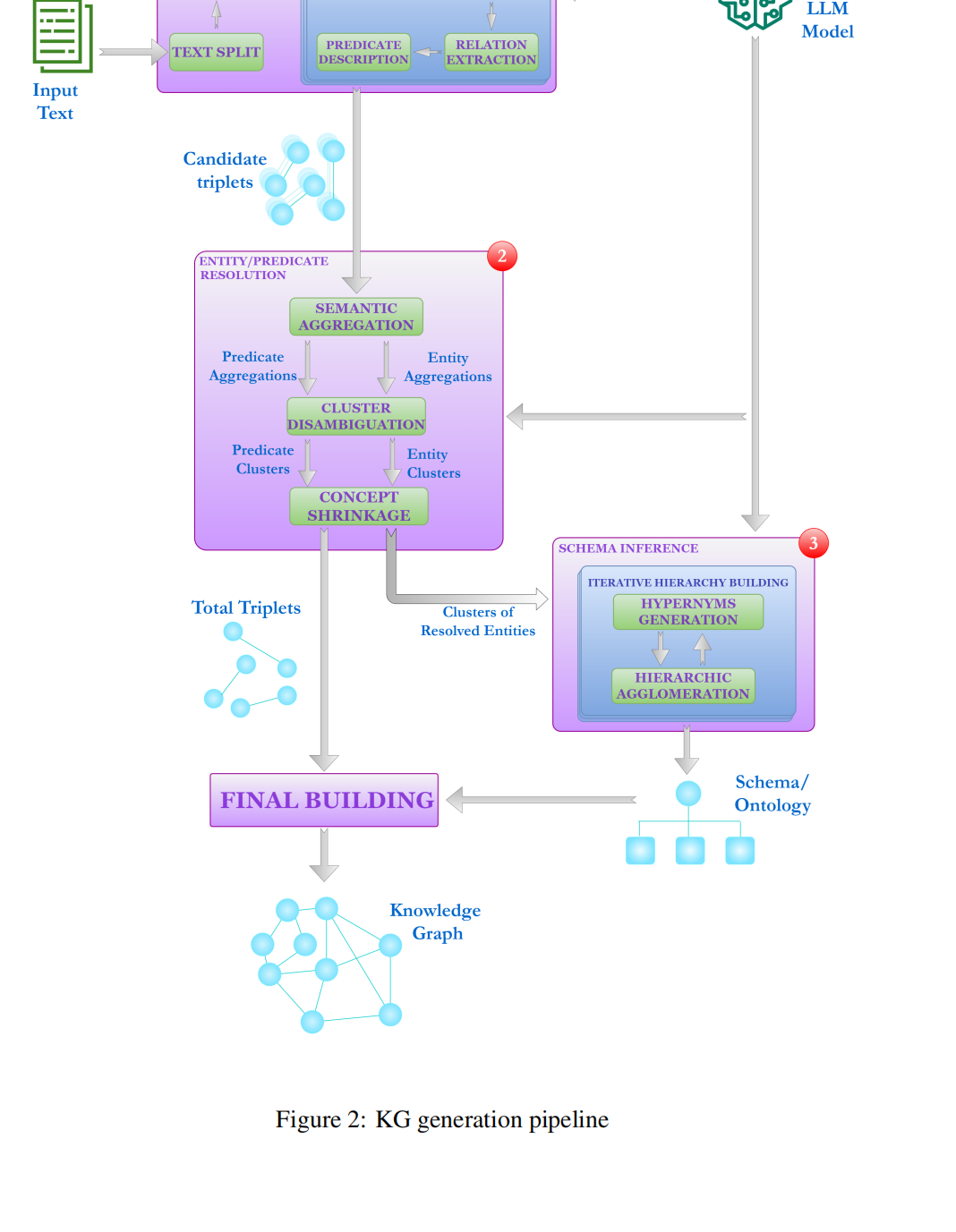
3.3.1 Candidate Triplet Extraction
从文本分解(text split)开始,得到一些text chunks,
之后,先进行实体的提取,再进行关系的提取。相较于直接提取三元组准确率更高,并且简化了任务的复杂程度。
Text Split
主要遇到的两个问题:
- 脱离全文的语境:当失去了整体文本,词语和表达可能会失去原有的含义
- 相近实体的分割:两个实体处于同一个三元组中,但是可能会划分到不同的文本块中。
通过如下的两种方式去解决:
- 当处理文本块的时候做summary来保存整体的信息,公式如下所示:
\(summary_i = summarization_task(summary_{i-1},chunk_{i-1})\) - 减少两个实体被分割的概率:让chunk具有更大的尺寸和更大的重叠范围
Entity Extraction
主要使用如下的system prompt:
- \(S1\):对实体含义的一种解释
- \(S2\):从用户文本中获得实体的具体要求,比如对提供文本描述和类型表的要求
- \(S3\):对输出格式的要求
S1是不必要的。但是加入S1和未加入S1会导致明显的差异。
加入S1:减少获得的实体的数量,但是会更加关注名词和命名实体,更少关注通用和抽象的名词
不加S1:减少对实体的描述
举例的话,一页文本描述信息(Cagliari网页),S1约束下提取27个实体,而未加入S1提取62个实体(多出"History and art")这种。
描述(Cagliari)的话,比如
加入S1:
The capital city of Sardinia, offering history, art,
seashores, parks, and fine cuisine
不加S1:
The capital of Sardinia
作者认为,加入S1的影响是积极的。
GPT提取完实体\(E\)后,直接用于关系提取容易出错(提取的关系中实体不在E中,或者可能会出现遗漏)。
采用迭代的方式进行关系提取,每次提取关系的时候关注不同的\(e_i\)(\(e_i\in E\))
Phrase Selection
对于每一个\(e_i\),提取目标文本\(T_i^G\)用于关系提取(减少关系提取复杂度并且提升可靠性)
可以归结为传统的Query-Focused Abstractive Summarization or Open-Domain Question Answering任务,也可以直接用\(e_i\)的描述
Mention Recognition
system prompt:要求在特定文本中识别实体
找到\(T_i^G\)中提到的实体,记为\(E_i\)。
要求GPT对于每个实体,在最后回答"yes/no"。
user prompt:
用户输入就是有序的所有实体和生成文本。最后找标记为“yes”的实体。
Relation Extraction
要求:通过RDF三元组表达实体间的关系,主体和客体为实体列表中的元素(包含ID和名字),并且选择一个合适的额谓语。
user prompt为\(T_i^G\)和\(E_i\),
GPT以三元组\(R_i\)形式回答
system prompt也要包含对富有表达力(expressive)谓词含义的描述。
不能太过于具体。
例如:

两个实体及其对应描述:

比较合适的:
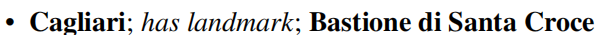
选择has great place for romantic evening过于具体,而includes过于通用。选择明确的(explict)的词语(类似于OpenIE工具的做法)
Predicate Description
system prompt:对每个独立的谓词生成描述,参考RDF三元组和文本
user prompt:\(T_i^G\)和\(R_i\)
注意生成的谓语描述要更加的通用。
例如:
对has landmark描述:It expresses that the Bastione di Santa Croce is a landmark in Cagliar是不合适的。Expresses a relationship between a place and a landmark located
in it是更加合适的。
最后输出的结果通过正则表达式判断是否符合结果,同时需要的时候也要检查ID和label的一致性。
- construction zero-shot knowledge prompting iteratorconstruction zero-shot knowledge prompting relational zero-shot knowledge learning zero-shot zero-shot reasoners language models image image-to-image translation zero-shot shot zero-shot few-shot one-shot hierarchical zero-shot语音adaptive cot chain-of-thought shot zero-shot 样本zero-shot learning zero 据实shot zero-shot few-shot