scrapy的crawlspider爬虫
学习目标:
- 了解 crawlspider的作用
- 应用 crawlspider爬虫创建的方法
- 应用 crawlspider中rules的使用
1、crawlspider是什么
回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
思路:
- 从response中提取所有的满足规则的url地址
- 自动的构造自己requests请求,发送给引擎
对应的crawlspider就可以实现上述需求,能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎,同时能够指定callback函数
即:crawlspider爬虫可以按照规则自动获取连接
2、crawlspider豆瓣TOP250爬虫
通过crawlspider爬取豆瓣TOP250详情页的信息
思路分析:
- 定义一个规则,来进行列表页翻页,follow需要设置为True
- 定义一个规则,实现从列表页进入详情页,并且指定回调函数
- 在详情页提取数据
注意:连接提取器LinkExtractor中的allow对应的正则表达式匹配的是href属性的值
3、创建crawlspider爬虫并观察爬虫内的默认内容
3.1 创建crawlspider爬虫:
scrapy startproject project
cd project
scrapy genspider -t crawl douban book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p=1
url: 豆瓣图书 https://book.douban.com/latest?subcat=全部&p=1
3.2 spider中默认生成的内容如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DzSpider(CrawlSpider):
name = 'dz'
# allowed_domains = ['duanzixing.com']
start_urls = ['http://duanzixing.com/']
rules = (
# [0-9]{1,} \d+
# Rule(LinkExtractor(allow=r'https://duanzixing.com/page/\d+/'), callback='parse_item', follow=False),
Rule(LinkExtractor(allow=r'https://duanzixing.com/page/\d+/'), callback='parse_item', follow=True),
# Rule(LinkExtractor(allow=r'Items/'), follow=True),
)
def parse_item(self, response):
item = {}
print(response, response.request.url)
return item
3.3 观察跟普通的scrapy.spider的区别
在crawlspider爬虫中,没有parse函数
重点在rules中:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
4、crawlspider使用的注意点:
- 除了用命令
scrapy genspider -t crawl <爬虫名> <allowed_domail>创建一个crawlspider的模板,页可以手动创建 - crawlspider中不能再有以parse为名的数据提取方法,该方法被crawlspider用来实现基础url提取等功能
- Rule对象中LinkExtractor为固定参数,其他callback、follow为可选参数
- 不指定callback且follow为True的情况下,满足rules中规则的url还会被继续提取和请求
- 如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
5、了解crawlspider其他知识点
-
链接提取器LinkExtractor的更多常见参数
-
allow: 满足括号中的're'表达式的url会被提取,如果为空,则全部匹配
-
deny: 满足括号中的're'表达式的url不会被提取,优先级高于allow
-
allow_domains: 会被提取的链接的domains(url范围),如:
['https://movie.douban.com/top250'] -
deny_domains: 不会被提取的链接的domains(url范围)
-
restrict_xpaths: 使用xpath规则进行匹配,和allow共同过滤url,即xpath满足的范围内的url地址会被提取
如:
restrict_xpaths='//div[@class="pagenav"]' -
restrict_css: 接收一堆css选择器, 可以提取符合要求的css选择器的链接
-
attrs: 接收一堆属性名, 从某个属性中提取链接, 默认href
-
tags: 接收一堆标签名, 从某个标签中提取链接, 默认a, area
值得注意的, 在提取到的url中, 是有重复的内容的. 但是我们不用管. scrapy会自动帮我们过滤掉重复的url请求
-
-
模拟使用
正则用法: links1 = LinkExtractor(allow=r'list_23_\d+.html')
xpath用法: links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
css用法: links3 = LinkExtractor(restrict_css='.x')
5.提取连接
-
Rule常见参数
- LinkExtractor: 链接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback: 表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow: 连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,默认True表示会,Flase表示不会
- process_links: 当链接提取器LinkExtractor获取到链接列表的时候调用该参数指定的方法,这个自定义方法可以用来过滤url,且这个方法执行后才会执行callback指定的方法
总结
- crawlspider的作用:crawlspider可以按照规则自动获取连接
- crawlspider爬虫的创建:scrapy genspider -t crawl xxx www.xxx.com
- crawlspider中rules的使用:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
scrapy_redis
一、scrapy_redis分布式原理
学习目标
- 了解 scarpy_redis的概念和功能
- 了解 scrapy_redis的原理
- 了解 redis数据库操作命令
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
1 scrapy_redis是什么
安装
pip install scrapy_redis == 0.7.2
2 为什么要学习scrapy_redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
- 请求对象的持久化
- 去重的持久化
- 和实现分布式
3 scrapy_redis的原理分析
3.1 回顾scrapy的流程
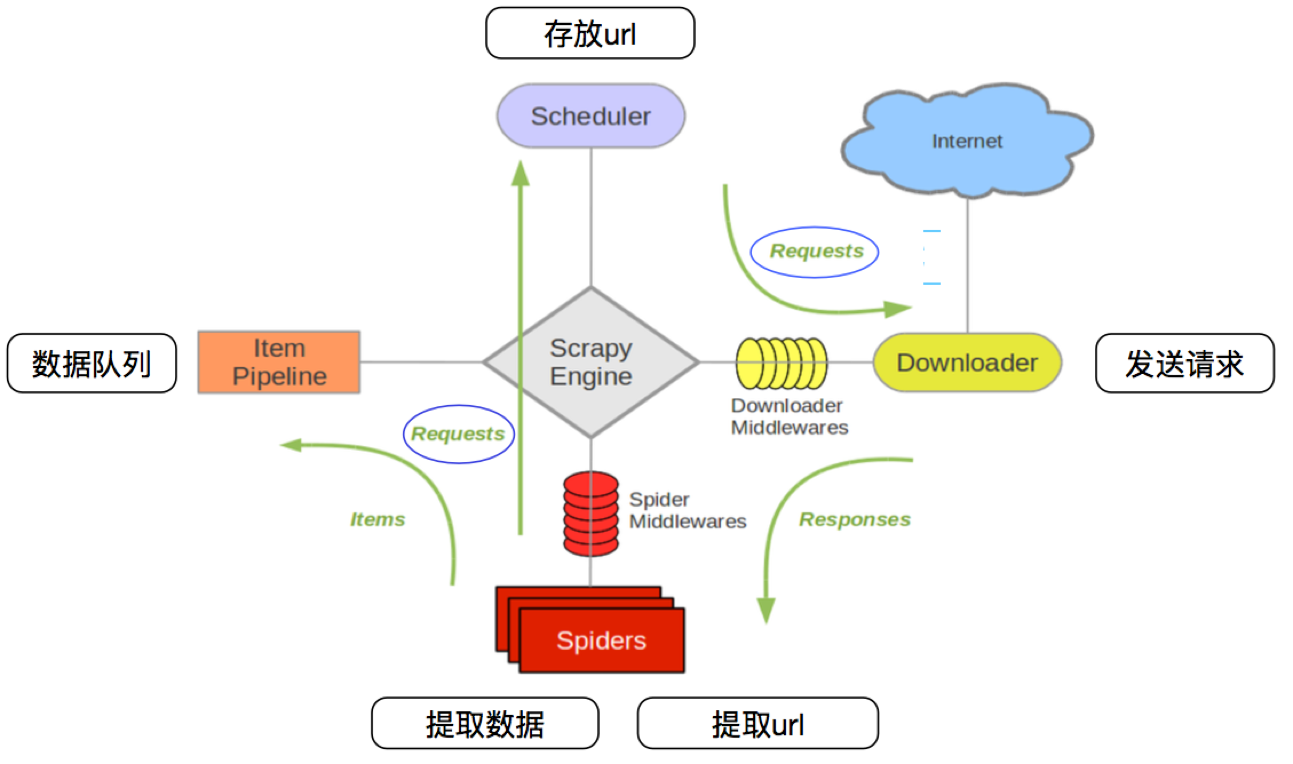
那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
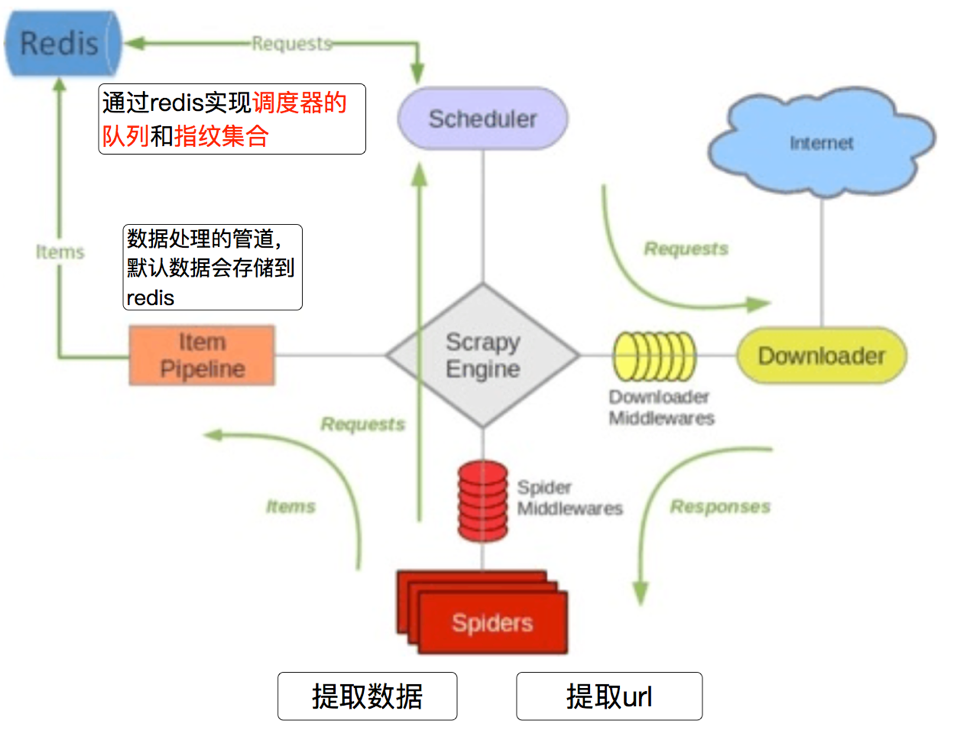
3.2 scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
具体流程如下:
4 对于redis的复习
由于时间关系,大家对redis的命令遗忘的差不多了, 但是在scrapy_redis中需要使用redis的操作命令,所有需要回顾下redis的命令操作
4.1 redis是什么
redis是一个开源的内存型数据库,支持多种数据类型和结构,比如列表、集合、有序集合等,同时可以使用redis-manger-desktop等客户端软件查看redis中的数据,关于redis-manger-desktop的使用可以参考扩展阅读
4.2 redis服务端和客户端的启动
redis-server.exe redis-windwos.conf启动服务端redis-cli客户端启动
4.3 redis中的常见命令
select 1切换dbkeys *查看所有的键type 键查看键的类型flushdb清空dbflushall清空数据库
4.4 redis命令的复习
redis的命令很多,这里我们简单复习后续会使用的命令

小结
scarpy_redis的分布式工作原理
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
二、配置分布式爬虫
学习目标
配置完成使用分布式爬虫
1、概述
分布式爬虫
- 使用多台机器搭建一个分布式的机器,然后让他们联合且分布的对同一组资源进行数据爬取
- 原生的scrapy框架是无法实现分布式爬虫?
- 原因:调度器,管道无法被分布式机群共享
- 如何实现分布式
- 借助:scrapy-redis组件
- 作用:提供了可以被共享的管道和调度器
- 只可以将爬取到的数据存储到redis中
2、创建分布式crawlspider爬虫
- scrapy startproject fbsPro
- cd fbsPro
- scrapy genspider -t crawl fbs www.xxx.com
3、redis-settings需要的配置
-
(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" -
(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler" -
(可选). 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True -
(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 100 , } -
(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_DB = 0 # (不指定默认为0) # 设置密码 REDIS_PARAMS = {'password': '123456'}
4、settings.py
settings.py
这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline
需要添加redis的地址,程序才能够使用redis
在settings.py文件修改pipelines,增加scrapy_redis。
# 配置分布式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 或者使用下面的方式
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_PARAMS = {'password': '123456'}
注意:scrapy_redis的优先级要调高
6、爬虫文件代码中 fbs.py
from scrapy_redis.spiders import RedisCrawlSpider
# 注意 一定要继承RedisCrawlSpider
class FbsSpider(RedisCrawlSpider):
name = 'fbs'
# allowed_domains = ['www.xxx.com']
# start_urls = ['http://www.xxx.com/']
redis_key = 'fbsQueue' # 使用管道名称(课根据实际功能起名称)
7、scrapy-redis键名介绍
scrapy-redis中都是用key-value形式存储数据,其中有几个常见的key-value形式:
1、 “项目名:items” -->list 类型,保存爬虫获取到的数据item 内容是 json 字符串
2、 “项目名:dupefilter” -->set类型,用于爬虫访问的URL去重 内容是 40个字符的 url 的hash字符串
3、 “项目名:requests” -->zset类型,用于scheduler调度处理 requests 内容是 request 对象的序列化 字符串
8、完整代码配置
-
网址
阳光问政为例
-
settings.py
BOT_NAME = 'fbsPro' SPIDER_MODULES = ['fbsPro.spiders'] NEWSPIDER_MODULE = 'fbsPro.spiders' USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False # 配置分布式 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400, } # 或者使用下面的方式 REDIS_HOST = "127.0.0.1" REDIS_PORT = 6379 REDIS_PARAMS = {'password': '123456'} -
fbs.py
实现方式就是之前的
crawlspider类型的爬虫import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider # 注意 一定要继承RedisCrawlSpider class FbsSpider(RedisCrawlSpider): name = 'fbs' # allowed_domains = ['www.xxx.com'] # start_urls = ['http://www.xxx.com/'] redis_key = 'fbsQueue' # 使用管道名称 link = LinkExtractor(allow=r'/political/politics/index?id=\d+') rules = ( Rule(link, callback='parse_item', follow=True), ) def parse_item(self, response): item = {} yield item -
redis中
-
redis-windwos.conf
- 56行添加注释 取消绑定127.0.0.1 # bind 127.0.0.1
- 75行 修改保护模式为no protected-mode no
-
启动redis
-
队列中添加url地址
添加:lpush fbsQueue https://wz.sun0769.com/political/index/politicsNewest
查看:lrange fbsQueue 0 -1
-
-
运行
scrapy crawl fbs
-
去redis中查看存储的数据