全站
Node-js用FlexSearch给Hexo添加极速全站搜索
title: Node.js用FlexSearch给Hexo添加极速全站搜索 tags: [Node.js,node,Javascript,Debian,Linux,FlexSearch,搜索] 新版原文: https://www.carlzeng.top/search?q=Node.js用Flex ......
用了阿里云的CDN全站加速,后台登录不了
fastadmin框架,用了阿里云的CDN全站加速,后台登录不进去了,输入用户名密码,提示登录成功,然后就跳出请登录的页面,接着又跳转到你已经登录的页面,就这样不断重复跳,因为不断跳,调试模式也没办法看。loginip_check也已经设置成了false,cdn设置了php文件不缓存。请问一下是哪里 ......
Linux基础41 全站https, 项目全站https, 阿里云负载均衡, 阿里云https
三、全站HTTPS 前端和后端所有的链接都是https 如下图(采用下面的方式, 上面的方式可以当没必要, 内部通讯没必要https) 1.环境准备 主机外网IP内网IP身份 lb01 10.0.0.4 172.16.1.4 负载均衡 web01 172.16.1.7 web服务器 web02 17 ......
abp vnext 强制全站使用中文
// 可以生效 app.UseAbpRequestLocalization(options => { options.SetDefaultCulture("zh-hans"); options.RequestCultureProviders.Clear();//不允许用户自行更改语言 //optio ......
全站tag列表 文章归档 友情链接
全站tag列表 {w:tag field="id,tag,total" limit="20"}{loop $data $v}<li><a href="{tag_url($v['id'])}" target="_blank">{$v[tag]}({$v[total]})</a></li>{/loop} ......
帝国cms 全站伪静态规则设置
帝国cms 因为目前来说是免费使用得,而且对于数据承载量以及其他栏目设置方面还是比较友好得,现在大部分网站已经采用帝国cms系统来做了。伪静态相对于静态来说会有更多得好处,今天就说下帝国cms 伪静态规则设置方面得问题 帝国CMS伪静态nginx版: rewrite ^([^\.]*)/listin ......
爬虫:scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章
[toc] ### scrapy架构介绍 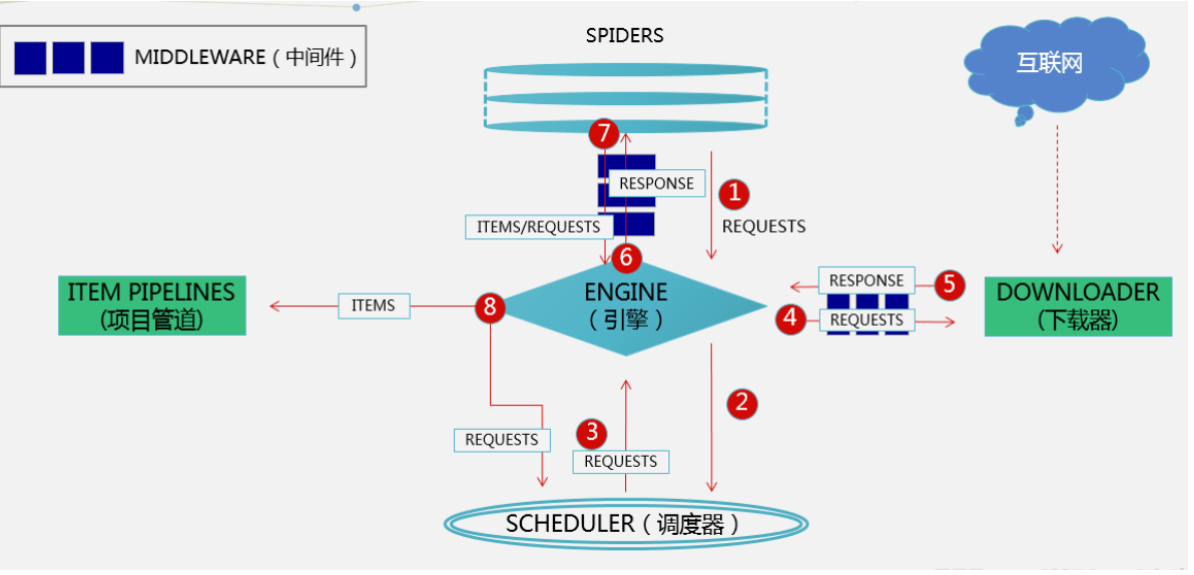 ```python # 引擎(EGINE) 引擎负责控制系统所 ......
【故障公告】阿里云抢占式实例服务器被释放引发全站故障
5月7日23:50-5月8日1:40期间,由于园子自建 k8s 集群所使用的大部分阿里云抢占式实例服务器被同时释放,造成200多个 pod 宕机,引发全站故障,由此给您带来很大的麻烦,请您谅解。我们会吸取教训,靠节约无法服务好用户,唯有自己变强。 ......
Day 25 25.1 Scrapy框架之全站爬虫(CrawlSpider)
Scrapy框架之全站爬虫(CrawlSpider) 在之前 Scrapy 的基本使用当中,spider 如果要重新发送请求的话,就需要自己解析页面,然后发送请求。 而 CrawlSpider 则可以通过设置 url 条件自动发送请求。 LinkExtractors CrawlSpider 是 Sp ......
【故障公告】数据库服务器 CPU 近 100% 造成全站故障,雪上加霜难上加难的三月
数据库服务器 CPU 近 100% 问题几乎每年都要发生一次,上次发生在去年1月31日,每次都是通过主备切换或者重启实例解决。今年这个问题真会找时间,在园子非常困难的时期,在昨天刚刚因疯狂蜘蛛袭击被整得精疲力尽之后,在星期天早上难得睡个懒觉的时候,在今天早上 8:30 左右来袭。 ......
全站抓取与分布式增量抓取
scrapy的crawlspider爬虫 学习目标: 了解 crawlspider的作用 应用 crawlspider爬虫创建的方法 应用 crawlspider中rules的使用 1、crawlspider是什么 回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址 ......
爬虫相关 scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章、
==scrapy架构介绍== # 引擎(EGINE) 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。 # 调度器(SCHEDULER) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, ......