堆这个数据结构在我大学的教材上没有讲解,但平时听说过堆排序什么的,无疑是要用到这个数据结构,所以本篇文章主要是总结下堆的概念和实现。
堆概念
在维基百科中,是这样定义堆的:
堆(英语:Heap)是计算机科学中的一种特别的树状数据结构。若是满足以下特性,即可称为堆:“给定堆中任意节点 P 和 C,若 P 是 C 的母节点,那么 P 的值会小于等于(或大于等于) C 的值”。若母节点的值恒小于等于子节点的值,此堆称为最小堆(min heap);反之,若母节点的值恒大于等于子节点的值,此堆称为最大堆(max heap)。在堆中最顶端的那一个节点,称作根节点(root node),根节点本身没有母节点(parent node)。
从上面的定义我们可以了解到,堆分为最大堆和最小堆,即中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。堆的实现通过构造二叉堆(binary heap),实为二叉树的一种。所以一个堆要满足以下性质:
- 堆总是一棵完全二叉树
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
为什么要为完全二叉树呢?我们知道完全二叉树除最后一层外,其它层的节点个数都是满的,最后一层节点都靠左排列,如下图所示:
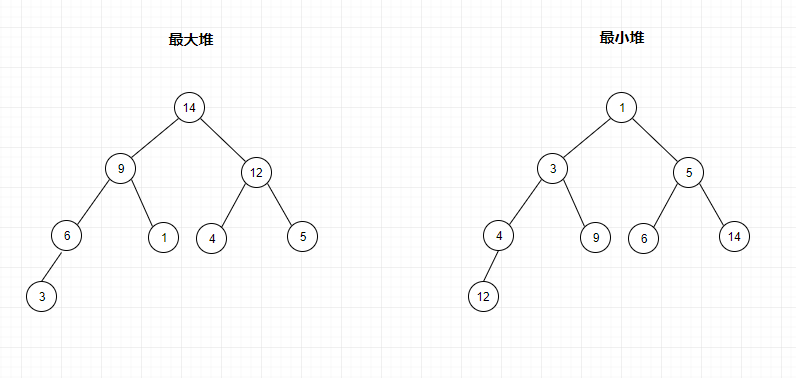
堆性质
我们知道完全二叉树适合用数组来存储,不会出现空闲的位置,堆也是用数组来实现的,假设现在我们有以下数组:
{12, 6, 4, 9, 1, 5, 14, 3}
如果我们要将这个数据插入到堆(最大堆)里面,那么按照堆的性质,最终的形式如下:
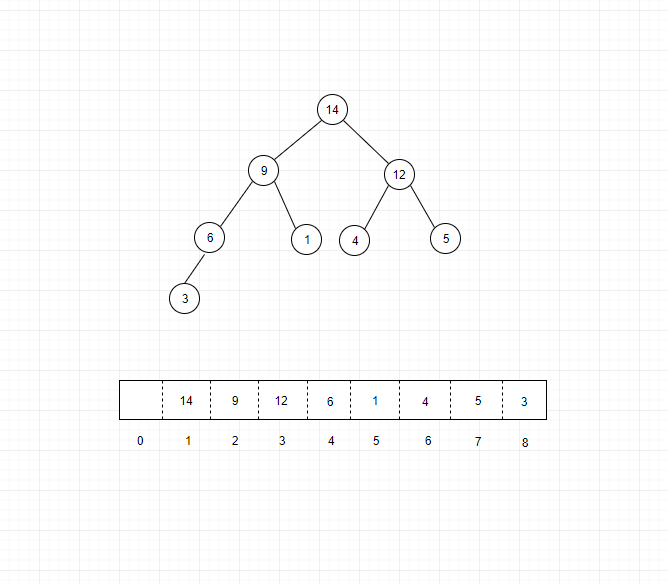
上面的二叉树很明显是完全二叉树,数据是存储在数组里面的,数组的第一个位置我们空着不用,主要是为了计算方便。从图中我们可以看到,数组中下标为 $i$ 的节点的左子节点,就是下标为$i∗2$的结点,右子节点的下标为$i∗2+1$,其父结点为${i \over 2}$。
对于堆的常用操作,包括插入和删除堆顶元素,下面我们以最大堆来为例,最小堆就不说了。
最大堆
根据上面的组总结,我们先将获取节点位置的方法实现一下:
/**
* 根据给定节点的下标,找到其左儿子的下标
* @param i 给定节点的下标
* @return 其左儿子的下标
*/
public int left(int i) {
return 2 * i;
}
/**
* 根据给定节点的下标,找到其右儿子的下标
* @param i 给定节点的下标
* @return 其右儿子的下标
*/
public int right(int i) {
return 2 * i + 1;
}
/**
* 根据给定节点的下标,找到其父节点的下标
*
* @param i 给定节点的下标
* @return 其父节点的下标
*/
public int parent(int i) {
// 为根节点
if (i == 0)
return -1;
return i / 2;
}
然后定义类中的属性,包括数据存储的数组、容量和当前元素个数。接着我们实现构造函数,如下所示:
private T[] data; // 数据存储
private int count; // 堆目前所含数据量大小
private int capacity; // 堆容量大小
public MaxHeap(int capacity) {
this.capacity = capacity;
this.count = 0;
this.data = (T[]) new Comparable[capacity + 1];
}
public MaxHeap(T[] data, int capacity) {
if (capacity <= 0) {
throw new IllegalArgumentException("capacity must not be 0");
}
if (capacity <= data.length) {
throw new IllegalArgumentException("capacity must greater than the length of data");
}
this.capacity = capacity;
this.count = data.length;
buildHeap(data);
}
private void buildHeap(T[] array) {
data = (T[]) new Comparable[capacity];
this.count = array.length;
System.arraycopy(array, 0, data, 1, count);
for (int k = count; k > 0 ; k--) {
heapUp(k);
}
}
插入元素
对于插入操作,我们要保证在插入元素之后,堆依然要保证其两个性质。我们先将元素添加到数组的末尾,也就是完全二叉树的最后一层的空节点位置,如下所示:
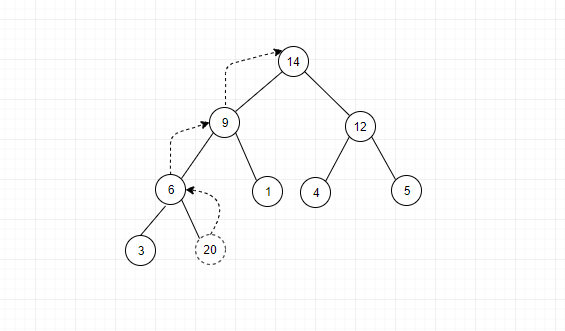
如上图所示,现在我们要插入20这个元素,放在了6元素的右子结点上,但现在明显不满足堆的第二个性质,6比20小,所以我们需要进行调整,将6和20的位置互换,如果还不满足,那就继续,使其满足堆的两个性质,这个过程被称为堆化(heapify)。这里的堆化过程是从下向上的堆化过程。
这个过程其实是比较好理解的,下面我们来用代码实现一下:
public void add(T value) {
Objects.requireNonNull(value, "value must not be null");
if (count >= capacity - 1) return;
++count;
this.data[count] = value;
heapUp(count);
}
heapUp这个方法就是调整堆中的元素,使其满足堆的性质,过程比较简单:
/**
* 上浮
*/
private void heapUp(int index) {
checkPosition(index);
int nodeIndex = index;
T value = this.data[nodeIndex];
if (value == null)
return;
while (nodeIndex > 0 && parent(nodeIndex) >0
&& data[nodeIndex].compareTo(data[parent(nodeIndex)]) > 0) {
swap(nodeIndex, parent(nodeIndex));
nodeIndex = parent(nodeIndex);
}
}
/**
* 交换两个位置的数据
*
* @param index1
* @param index2
*/
private void swap(int index1, int index2) {
checkPosition(index1);
checkPosition(index2);
T tempValue = this.data[index1];
this.data[index1] = this.data[index2];
this.data[index2] = tempValue;
}
删除堆顶元素
由于堆的特殊性质,堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值,所以堆中的最大值(最小值)必在堆顶,现在我们把堆顶元素删除了,就不是二叉树了,一个解决的方式是:将数组末尾的元素移动到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的结点,此时元素应该和子节点比较,如果大于等于子节点或者没有子节点,停止比较;否则,选择子节点中最大的元素,进行交换,执行此步,直到结束。这个过程被称为自上而下的堆化过程,如下所示:
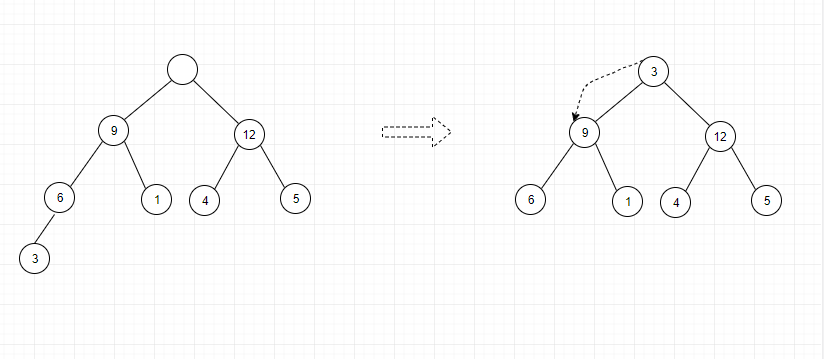
代码如下:
public T remove() {
if (count == 0) return null;
T value = this.data[1];
this.data[1] = this.data[this.count];
this.data[this.count] = null;
--this.count;
heapDown(count, 1);
return value;
}
heapDown为自上而下的堆化过程:
/**
* 下沉
*
* @param n 总数量
* @param i 当前节点位置
*/
private void heapDown(int n, int i) {
while (true) {
int maxPos = i;
int left = left(i);
int right = right(i);
if (left <= n && this.data[i].compareTo(this.data[left]) < 0)
maxPos = left;
if (right <= n && this.data[maxPos].compareTo(this.data[right]) < 0)
maxPos = right;
if (maxPos == i)
break;
swap(i, maxPos);
i = maxPos;
}
}
堆排序
上面说了关于堆的概念及其实现,那么我们可以利用堆做些什么呢? 我们可以利用堆来做排序(原地排序)。排序有升序与降序之分,相应的最大堆通常被用来进行"升序"排序,而最小堆通常被用来进行"降序"排序。这是为何?主要是堆排序算法利用堆的特性,比如最大堆的堆顶元素最大,最小堆堆顶元素最小。下面我们来根据最大堆来分析下。
堆排序(升序)的基本思路是:建堆和排序。简单概括如下:
- 建堆:将数列a[1...n]构造成最大堆。
- 排序:将a[1]和a[n]交换,使a[n]是a[1...n]中的最大值;然后将a[1...n-1]重新调整为最大堆。 接着,将a[1]和a[n-1]交换,使a[n-1]是a[1...n-1]中的最大值;然后将a[1...n-2]重新调整为最大值。 依次类推,直到整个数列都是有序的。
建堆
所谓原地排序,就是我们不要再利用其他数组了,直接使用给定的数组,就可以进行排序了。所以我们建堆也是原地建堆,不利用其他数组。这里最容易想到的就是前面的入堆操作,假设最初堆中就只有一个元素,然后再有元素过来了,就相当于插入操作,然后按照堆的特性自下向上进行调整。不过这种需要每个都进行调整,还有一种比较好的方式来实现。
记得前面我们删除堆顶元素的操作吗?删除堆顶元素时采用自上而下的操作,其实我们只要从第一个非叶子结点开始,从后往前处理数组,并且每个数据都是从上往下堆化的。对于完全二叉树,假设根结点编号从1开始,那么它的第一个叶子节点的编号必为${i \over 2} + 1$,所以第一个非叶子节点编号就是${i \over 2}$ 了,叶子节点只能自己和自己比较,所以我们就可以不用堆化了,所以${i \over 2} + 1$ 到 ${n}$的节点都是叶子,我们就不考虑他们了。堆化代码如下:
/**
* 原地建堆
*/
public static void buildMaxHeap(int[] data, int n) {
// 从第一个非叶子结点开始调整
for (int i = n / 2; i >= 1; --i) {
heapify(data, n, i);
}
}
/**
* 堆化
*
* @param data
* 数组
* @param n
* 总数量
* @param i
* 当前位置
*/
private static void heapify(int[] a, int n, int i) {
while (true) {
int maxPos = i;
int left = left(i);
int right = right(i);
if (left <= n && a[i] < a[left])
maxPos = left;
if (right <= n && a[maxPos] < a[right])
maxPos = right;
if (maxPos == i)
break;
swap(a, i, maxPos);
i = maxPos;
}
}
排序
建好堆后,接下来我们就可以来排序了,对于升序来说,由于堆顶元素就是最大元素,所以每次操作时,我们需要将堆顶元素移动到数组末尾,将原数组末尾的元素移动到堆顶,然后将前面的元素重新堆化,使其满足堆的特性,就这样依次操作,知道排序完成。过程是比较简单的,代码如下:
/**
* 排序
*/
public static void sort(int[] data, int n) {
buildMaxHeap(data, n);
int k = n;
while (k > 1) {
swap(data, 1, k);
--k;
heapify(data, k, 1);
}
}
/**
* 交换两个位置的数据
*
* @param data
* 数组
* @param index1
* 位置1
* @param index2
* 位置2
*/
private static void swap(int[] data, int index1, int index2) {
int tempValue = data[index1];
data[index1] = data[index2];
data[index2] = tempValue;
}
时间复杂度
建堆的时间复杂度为$O(n)$,排序的时间复杂度为$O(nlogn)$