RNN
经典的RNN结构:
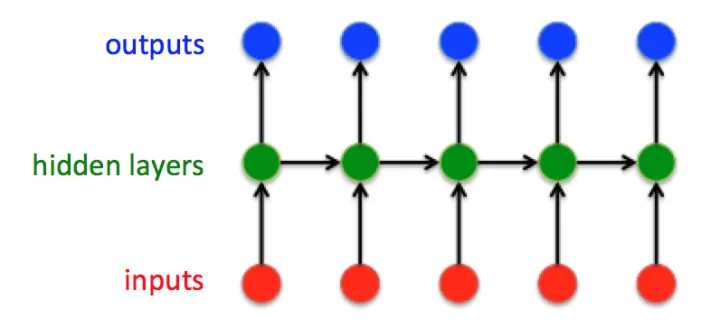
这是经典的RNN结构,输入向量是:
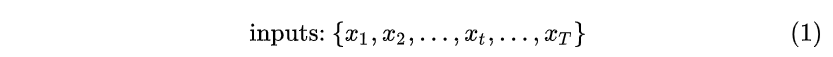
隐藏层状态向量:
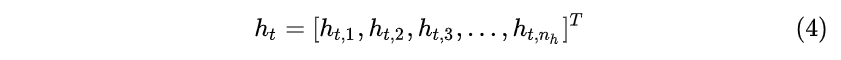
输出向量是:
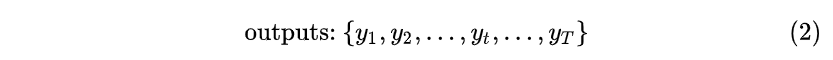
那么,我们可以计算
\(t\)时刻输入层->\(t\)时刻隐藏层\(h_{t}^{ih}=W_{ih}*x_t+b_{ih}\)
\(t-1\)时刻隐藏层->\(t\)时刻隐藏层\(h_{t}^{hh}=W_{hh}*h_{t-1}+b_{hh}\)
\(t\)时刻输入层 和\(t-1\)时刻隐藏层->\(t\)时刻隐藏层\(h_{t}=tanh(h_{t}^{ih}+h_{t}^{hh})=tanh((W_{ih}*x_t+b_{ih})+(W_{hh}*h_{t-1}+b_{hh}))\)
\(t\)时刻隐藏层->\(t\)时刻输出层\(y_{t}=W_{ho}*h_{t}+b_{ho}\)
在\(t=1\)时刻,如果没有特别指定初始状态,一般都会使用全0的\(h_0\)作为初始状态输入到\(h_1\)中。
值得注意的是,任意时刻\(t\),所有的权值\(W\)和\(b\)都是相等的,这就是RNN的权值共享。
其实RNN可以简单的表示为:
\(y_{t}=RNN(x_t,h_{t-1})
=RNN(x_t,x_{t-1},h_{t-2})
=RNN(x_t,x_{t-1},...,x_2,x_1)\)
Sequence to Sequence模型
seq2seq一般是由Encoder和Decoder组成。
Encoder的output是无意义的,所以一般说Encoder输出都是指Encoder的hidden
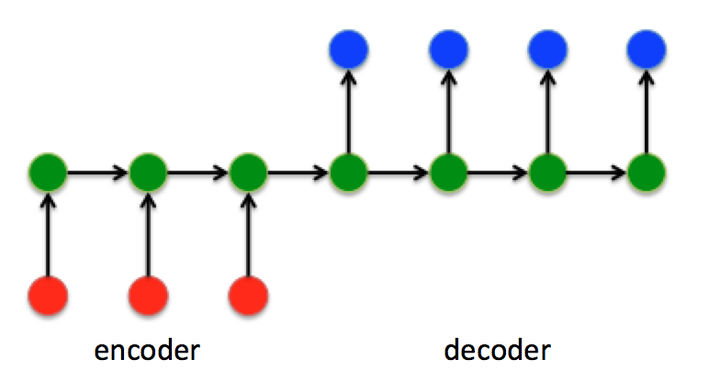
由图可知,Encoder中\(h_i\)的最后一个\(h_t\)作为Decoder的初始状态输入\(S_0\)。
基于此,Decoder几乎获取不到Encoder前面隐藏层状态的信息(信息较少,或者说权值低)。所以,加入Attention改进这一情况。
Attention
