一:选题背景
随着葡萄酒越来越受欢迎,人们对于如何评价和预测葡萄酒质量的需求也越来越高。红酒质量的预测是其中的一个热门话题。传统的红酒质量评价是由专业品酒师根据对葡萄酒的视觉、嗅觉、味觉等感官特征进行评估,然后得出质量评分。但这种评价方式非常耗时费力且昂贵,并且与个人主观因素相关。因此,开发一种基于机器学习(ML)算法的自动化红酒质量预测系统变得越来越受到关注。
通过收集红酒中的成分的物理化学性质(例如PH值,酸度等),在已知红酒质量的情况下,可以使用机器学习算法训练模型进行预测。这种方法可以节省时间和成本,并且提高了预测精度。同时,为了优化模型的预测能力,还可以使用特征选择和数据清洗,使用线性回归、决策树回归和随机森林回归绘制预测值和真实质量值以及RMSE等方法对数据进行处理和分析。基于机器学习的红酒质量预测在餐饮和葡萄酒行业有着广泛的应用前景,可以帮助人们快速而准确地评估红酒的质量,促进了工业化生产。
二:数据信息,葡萄酒中的成分
所有信息和数据均在此处找的:https://www.kaggle.com/UC IML/red-wine-quality-cortez-et-al-2009
Fixed acidity 固定酸度:葡萄酒中的大多数酸是固定的或不挥发的(不容易挥发)。
Volatile acidity 挥发性酸度:葡萄酒中的醋酸含量,含量过高会导致醋味。
Citric acid柠檬酸:少量的柠檬酸可以增加葡萄酒的“新鲜度”和风味。
Residual sugar 残余糖分:发酵停止后剩余的糖量,很少发现低于1克/升的葡萄酒,超过45克/升的葡萄酒被认为是甜的。
Chlorides 氯化物:酒里的盐量。
Free sulfur dioxide 游离二氧化硫:SO2的游离形式存在于分子SO2(作为溶解气体)和亚硫酸氢盐离子之间的平衡中;它防止微生物的生长和葡萄酒的氧化。
Total sulfur dioxide 二氧化硫总量:游离和结合形式SO2的量;在低浓度下,SO2在葡萄酒中几乎检测不到,但是当游离SO2浓度超过50 ppm时,SO2在葡萄酒的气味和味道中变得明显。
Density 密度:葡萄酒的密度接近于水的密度,取决于酒精和糖的含量。
pH pH值:描述葡萄酒的酸性或碱性,范围从0(非常酸性)到14(非常碱性);大多数葡萄酒的pH值在3-4之间。
Sulphates 硫酸盐:一种葡萄酒添加剂,可提高二氧化硫气体(SO2)水平,起到抗菌和抗氧化的作用。
Alcohol 酒精:葡萄酒的酒精含量百分比。
Quality 质量:输出变量,取0-10
所使用的库:
numpy pandas:处理数据。
matplotlib seaborn:绘制信息,用不同的方式可视化。
sklearn:提供所有必要的工具来训练模型,在之后进行测试。
math:提供一些在测试模型时可能使用的函数(sqrt)
prettytable:绘制简单的ascii表
1 import numpy as np # 导入处理数值计算的库 2 import warnings # 用于处理警告信息 3 import pandas as pd # 导入处理数据的库 4 import matplotlib.pyplot as plt # 导入可视化绘图的库 5 import seaborn as sns # 导入更高级的可视化绘图库 6 from sklearn.model_selection import train_test_split # 导入拆分训练集和测试集的方法 7 from sklearn.linear_model import LinearRegression # 导入线性回归的方法 8 from sklearn.metrics import mean_squared_error # 导入均方误差的方法 9 from sklearn.metrics import accuracy_score # 导入准确率得分的方法 10 from sklearn.metrics import f1_score, confusion_matrix, accuracy_score, recall_score, precision_score # 导入用于分类问题评估性能的方法 11 from sklearn.preprocessing import PolynomialFeatures # 导入处理多项式特征的方法 12 from sklearn.metrics import mean_squared_error # 导入均方误差的方法 13 from sklearn.tree import DecisionTreeRegressor # 导入决策树回归器的方法 14 from sklearn.ensemble import RandomForestRegressor # 导入随机森林回归器的方法 15 from sklearn import linear_model # 导入线性模型库 16 from math import sqrt # 导入计算平方根的函数 17 from prettytable import PrettyTable # 导入绘制ascii表格的库
三:导入数据集并检查:
准备好成分数据集,检查成分数据类型,读取成分数据,查看数据的前十行。

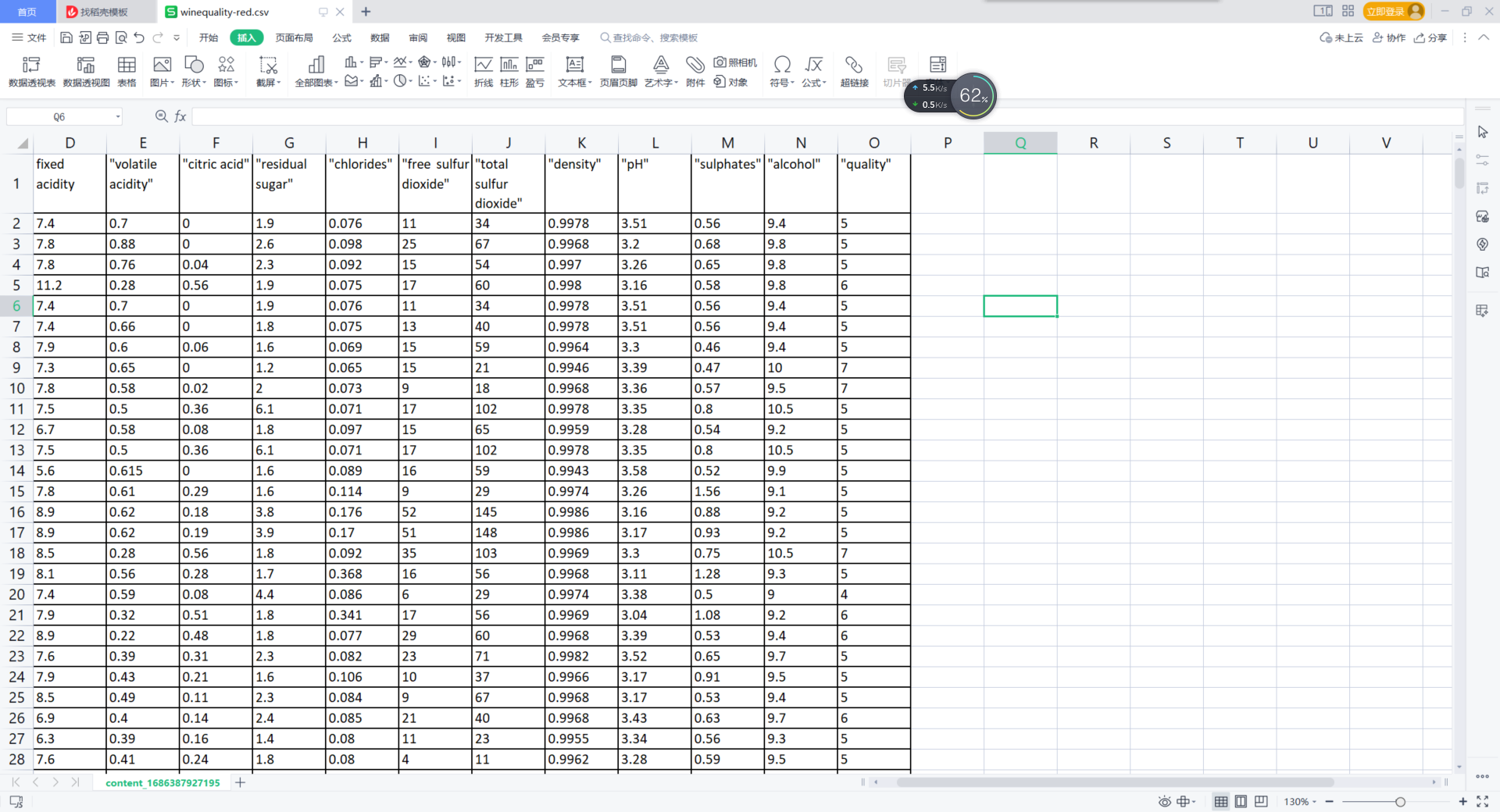
1.导入数据
1 # 使用 pandas 中的 read_csv 函数读取 csv 文件 2 df = pd.read_csv("winequality-red.csv") 3 # 使用 DataFrame 中的 head() 函数来查看数据的前 10 行 4 df.head(10)
输出:
|
fixed acidity |
volatile acidity |
citric acid |
residual sugar |
chlorides |
free sulfur dioxide |
total sulfur dioxide |
density |
pH |
sulphates |
alcohol |
quality |
|
|
0 |
7.4 |
0.70 |
0.00 |
1.9 |
0.076 |
11.0 |
34.0 |
0.9978 |
3.51 |
0.56 |
9.4 |
5 |
|
1 |
7.8 |
0.88 |
0.00 |
2.6 |
0.098 |
25.0 |
67.0 |
0.9968 |
3.20 |
0.68 |
9.8 |
5 |
|
2 |
7.8 |
0.76 |
0.04 |
2.3 |
0.092 |
15.0 |
54.0 |
0.9970 |
3.26 |
0.65 |
9.8 |
5 |
|
3 |
11.2 |
0.28 |
0.56 |
1.9 |
0.075 |
17.0 |
60.0 |
0.9980 |
3.16 |
0.58 |
9.8 |
6 |
|
4 |
7.4 |
0.70 |
0.00 |
1.9 |
0.076 |
11.0 |
34.0 |
0.9978 |
3.51 |
0.56 |
9.4 |
5 |
|
5 |
7.4 |
0.66 |
0.00 |
1.8 |
0.075 |
13.0 |
40.0 |
0.9978 |
3.51 |
0.56 |
9.4 |
5 |
|
6 |
7.9 |
0.60 |
0.06 |
1.6 |
0.069 |
15.0 |
59.0 |
0.9964 |
3.30 |
0.46 |
9.4 |
5 |
|
7 |
7.3 |
0.65 |
0.00 |
1.2 |
0.065 |
15.0 |
21.0 |
0.9946 |
3.39 |
0.47 |
10.0 |
7 |
|
8 |
7.8 |
0.58 |
0.02 |
2.0 |
0.073 |
9.0 |
18.0 |
0.9968 |
3.36 |
0.57 |
9.5 |
7 |
|
9 |
7.5 |
0.50 |
0.36 |
6.1 |
0.071 |
17.0 |
102.0 |
0.9978 |
3.35 |
0.80 |
10.5 |
5 |
1 df.shape #使用 df.shape 查看数据集的维度,即行数和列数。
输出:
(1599, 12)
2.检查数据
--成分数据可能有些列包含空格,使用"_"替换空格,并查询是否非空
1 # 将数据集中所有列名中的空格替换为下划线。 2 df.columns = df.columns.str.replace(' ', '_') 3 # 使用 df.info() 查看每列的数据类型和非空数量。 4 # 使用 df.isnull().sum() 查看每列缺失值的数量。 5 df.info() 6 df.isnull().sum()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1599 entries, 0 to 1598
Data columns (total 12 columns):
fixed acidity 1599 non-null float64
volatile acidity 1599 non-null float64
citric acid 1599 non-null float64
residual sugar 1599 non-null float64
chlorides 1599 non-null float64
free sulfur dioxide 1599 non-null float64
total sulfur dioxide 1599 non-null float64
density 1599 non-null float64
pH 1599 non-null float64
sulphates 1599 non-null float64
alcohol 1599 non-null float64
quality 1599 non-null int64
dtypes: float64(11), int64(1)
memory usage: 150.0 KB
----------------------------------------------
fixed_acidity 0
volatile_acidity 0
citric_acid 0
residual_sugar 0
chlorides 0
free_sulfur_dioxide 0
total_sulfur_dioxide 0
density 0
pH 0
sulphates 0
alcohol 0
quality 0
dtype: int64
----------
并未发现空值。
四:数据分析
检查了数据集是否良好后,再对葡萄酒中的成分的数据进行更多的分析,分析数据特征的行为以及它们之间的相关性,以更好地理解数据集。
1 #使用 Seaborn 库的 countplot 函数,展示数据集中每个品质评分对应的红酒质量 2 sns.countplot(df['quality']) 3 4 #输出每种品质评分在数据集中的红酒质量 5 df['quality'].value_counts()
输出:
5 681
6 638
7 199
4 53
8 18
3 10
Name: quality, dtype: int64
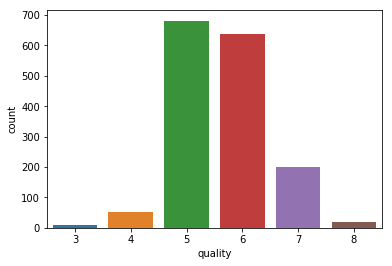
获得了关于质量的信息,按从小到大排序,分析质量和其他成分之间的相关性,分析哪些成分会影响葡萄酒质量。
1 df.corr()['quality'] #计算数据集中各个特征与“quality”列之间的相关系数,返回一个Series类型的对象。 2 sort_values(ascending=False) #将上述Series对象中的值按照从大到小的顺序排序,生成一个有序的Series类型的对象。 3 print(correlations) #输出排序后的结果。
输出:
quality 1.000000
alcohol 0.476166
sulphates 0.251397
citric_acid 0.226373
fixed_acidity 0.124052
residual_sugar 0.013732
free_sulfur_dioxide -0.050656
pH -0.057731
chlorides -0.128907
density -0.174919
total_sulfur_dioxide -0.185100
volatile_acidity -0.390558
Name: quality, dtype: float64
------
1 correlations.plot(kind='bar')#绘制按特征与品质相关系数从大到小排列的条形图
输出:
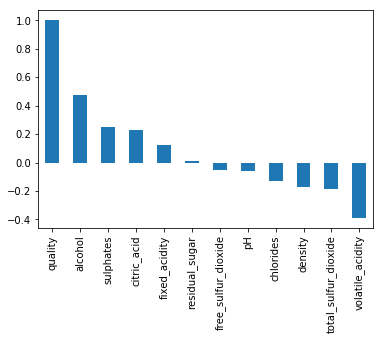
输出了质量和其他成分之间的相关值,接下来引用相关矩阵,更直观的分析哪些成分会影响葡萄酒质量。
1 plt.figure(figsize=(10,6)) # 设置画布大小为 10*6 英寸 2 sns.heatmap(df.corr(), annot=True, fmt='.0%') # 使用 Seaborn 可视化库绘制热力图
输出:
<matplotlib.axes._subplots.AxesSubplot at 0x1db23f23ac8>
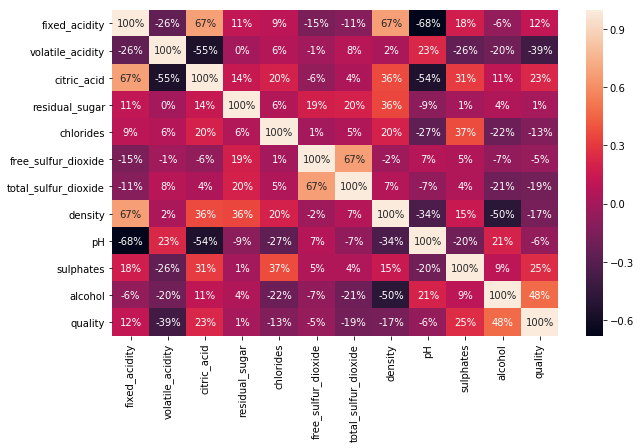
从这个矩阵中,可以观察到一些明显的与葡萄酒质量有关的成分,如pH和酸度。还可以观察到,这些成分中大约有一半与质量呈正相关,而另一半与质量负相关。
从所有这些成分中,选择相关性较大的成分,把相关的最小阈值设定在大约0.2(绝对值)左右,不必考虑其值可能是冗余的并且根本不提供信息的特征。
1 print(abs(correlations) > 0.2)#计算各特征与“quality”特征之间的相关系数,然后返回一个布尔型DataFrame对象,其中每个元素表示该位置的相关系数绝对值是否大于0.2。
输出:
quality True
alcohol True
sulphates True
citric_acid True
fixed_adidity False
residual_sugar False
free_sulfur_dioxide False
pH False
chlorides False
density False
total_sulfur_dioxide False
volatile_acidity True
Name: quality, dtype: bool
从所有的成分中选择酒精度、硫酸盐、柠檬酸和挥发性酸度这四个成分,以更好地分析它们并查看能够分离不同质量等级的成分的分布情况。
1 # 使用Seaborn库的boxplot函数,绘制箱线图 2 bp = sns.boxplot(x='quality',y='alcohol', data=df) 3 4 # 设置图表标题 5 bp.set(title="Alcohol Percent in Different Quality Wines")
绘制一张箱线图,用于展示不同质量等级的葡萄酒中酒精含量的分布情况。
输出:
[Text(0.5,1,'Alcohol Percent in Different Quality Wines')]
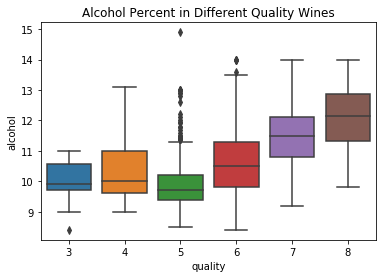
在这个方框图上可以看到酒精含量较低的葡萄酒质量越差,而酒精含量较高的葡萄酒质量越好。但是可以看到评级为5或6的“中等质量”葡萄酒显示出不同的数据,再做一些进一步的调查:
为什么会有这些不同的值,选择数据集的一个子集,该子集将只包含质量列值为5或6的行,计算该子集的相关系数。
1 # 选择质量等级在5或6之间的葡萄酒数据 2 df_quality_five_six = df.loc[(df['quality'] >= 5) & (df['quality'] <= 6)] 3 # 统计质量等级为5和6的葡萄酒数量 4 df_quality_five_six['quality'].value_counts()
输出:
5 681
6 638
Name: quality, dtype: int64
1 # 计算质量等级在5或6之间的葡萄酒数据中各属性与质量等级之间的相关性,并根据相关性从大到小进行排序 2 correlations_subset = df_quality_five_six.corr()['quality'].sort_values(ascending=False) 3 4 # 输出各属性与质量等级之间的相关性结果 5 print(correlations_subset)
输出:
quality 1.000000
alcohol 0.375224
sulphates 0.162405
citric_acid 0.080146
fixed_acidity 0.053447
pH 0.043065
residual_sugar -0.018452
free_sulfur_dioxide -0.060618
chlorides -0.081813
density -0.134559
volatile_acidity -0.237193
total_sulfur_dioxide -0.239067
Name: quality, dtype: float64
不同
在计算了质量为5和6的葡萄酒的相关性后发现,与质量相关性最大的成分与我们之前获得的成分相同。
现在再来看看硫酸盐和柠檬酸的存在的数据。
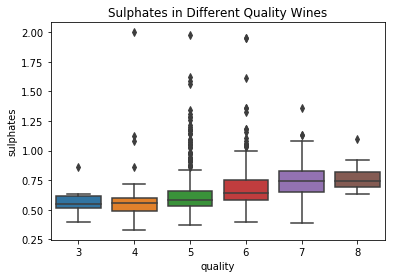
1 # 使用seaborn库中的boxplot函数绘制质量等级与二氧化硫含量(“sulphates”)之间的箱线图 2 bp = sns.boxplot(x='quality',y='sulphates', data=df) 3 # 设置图表标题为“不同质量等级葡萄酒中的二氧化硫含量” 4 bp.set(title="Sulphates in Different Quality Wines")
输出:
[Text(0.5,1,'Sulphates in Different Quality Wines')]
1 # 使用seaborn库中的boxplot函数绘制质量等级与柠檬酸含量(“citric_acid”)之间的箱线图 2 bp = sns.boxplot(x='quality',y='citric_acid', data=df) 3 # 设置图表标题为“不同质量等级葡萄酒中的柠檬酸含量” 4 bp.set(title="Citric Acid in Different Quality Wines")
输出:
[Text(0.5,1,'Citric Acid in Different Quality Wines')]
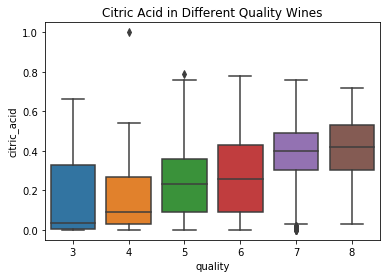
就“硫酸盐”和“柠檬酸”这两个成分而言,它们与质量之间的关系是正相关的,所以说之前计算的相关系数是正确的:在这些葡萄酒中添加更多的硫酸盐和柠檬酸可以使葡萄酒的质量更高。
乙酸的存在对葡萄酒质量影响
1 # 使用seaborn库中的boxplot函数绘制质量等级与挥发性酸含量(“volatile_acidity”)之间的箱线图 2 bp = sns.boxplot(x='quality',y='volatile_acidity', data=df) 3 # 设置图表标题为“不同质量等级葡萄酒中的乙酸存在情况” 4 bp.set(title="Acetic Acid Presence in Different Quality Wines")
输出:
[Text(0.5,1,'Acetic Acid Presence in Different Quality Wines')]

乙酸越多葡萄酒的质量越差,反之。
为了进行进一步的研究,我们现在将为这些成分中的每一个绘制直方图,以便更好地了解每个成分分布与质量之间的相关性。首先将质量值分为三个不同的组:
low:质量为3或4的葡萄酒。
med:质量为5或6的葡萄酒。
high:质量为7或8的葡萄酒。
1 # 复制DataFrame对象df到新的对象df_aux 2 df_aux = df.copy() 4 # 使用.replace()函数将3和4替换为“low”,5和6替换为“med”,7和8替换为“high”,并将结果直接更新到df_aux的“quality”列中 5 df_aux['quality'].replace([3,4],['low','low'],inplace=True) 6 df_aux['quality'].replace([5,6],['med','med'],inplace=True) 7 df_aux['quality'].replace([7,8],['high','high'],inplace=True) 9 # 使用Seaborn库中的countplot函数绘制质量等级计数图 10 sns.countplot(df_aux['quality'])
输出:
<matplotlib.axes._subplots.AxesSubplot at 0x1db291cce80>
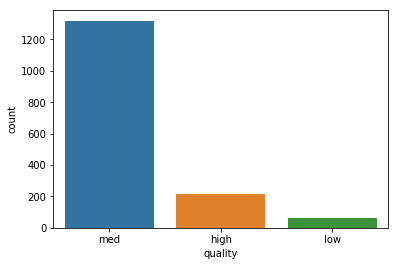
绘制画布
1 # 需要绘制直方图的特征列列表 2 flistt = ['alcohol','sulphates','citric_acid','volatile_acidity'] 3 4 # 根据不同质量等级将数据分为三个子集 5 low = df_aux[df_aux['quality'] == 'low'] 6 medium = df_aux[df_aux['quality'] == 'med'] 7 high = df_aux[df_aux['quality'] == 'high'] 8 9 # 更改字体大小 10 plt.rcParams.update({'font.size': 8}) 11 12 # 创建2x2的4个子图 13 plot, graphs = plt.subplots(nrows= 2, ncols= 2, figsize=(12,6)) 14 graphs = graphs.flatten() 15 16 # 循环绘制4个特征的直方图 17 for i, graph in enumerate(graphs): 18 graph.figure 19 20 # 计算每个直方图的bin宽度 21 binwidth= (max(df_aux[flistt[i]]) - min(df_aux[flistt[i]]))/30 22 bins = np.arange(min(df[flistt[i]]), max(df_aux[flistt[i]]) + binwidth, binwidth) 23 24 # 将三个子集的数据分别添加到直方图中,设置透明度、标签和颜色,并绘制标准化后的直方图 25 graph.hist([low[flistt[i]],medium[flistt[i]],high[flistt[i]]], bins=bins, alpha=0.6, normed=True, label=['Low','Medium','High'], color=['red','green','blue']) 26 27 # 添加图例到右上角 28 graph.legend(loc='upper right') 29 30 # 设置子图标题 31 graph.set_title(flistt[i]) 32 33 # 自适应调整子图布局 34 plt.tight_layout()
输出:
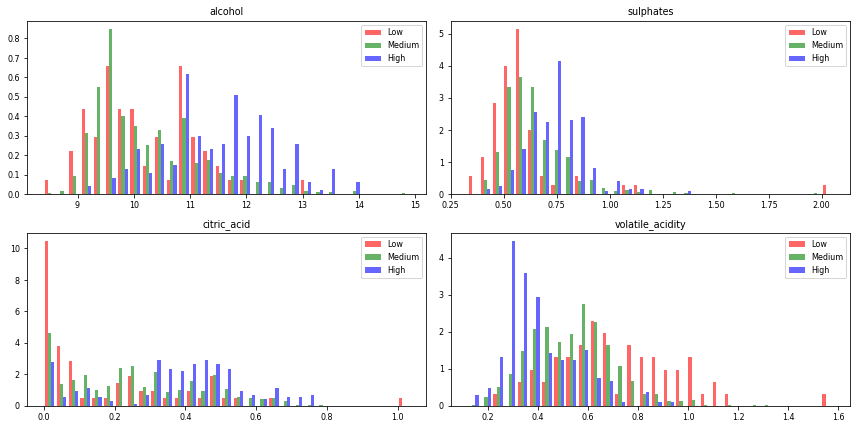
较高质量的葡萄酒中的酒精、硫酸盐和柠檬酸较高。较低质量的葡萄酒挥发性较高 。
六:选取三种回归模型进行训练,进行进一步分析
选择使用之前研究过的四个与葡萄酒最有关的成分,这四个成分提供了最多的成分与质量之间的信息。
1 #从相关系数矩阵中选择绝对值大于0.2的相关系数,以查找与目标列(此处为quality)强相关的列。 2 correlations[abs(correlations) > 0.2]
输出:
quality 1.000000
alcohol 0.476166
sulphates 0.251397
citric_acid 0.226373
volatile_acidity -0.390558
Name: quality, dtype: float64
了解了一些成分的数据并删除了一些无用的成分后,根据其他成分对质量进行估计。使用线性回归、决策树回归和随机森林回归并且绘制预测值和真实质量值,这样就可以看到有多少预测值是正确的。
1 # 从数据框中选择4个特征列作为自变量,将“quality”列作为因变量。 2 X = df.loc[:,['alcohol','sulphates','citric_acid','volatile_acidity']] 3 Y = df.iloc[:,11] 4 5 # 将数据划分为训练集和测试集,并使用线性回归模型进行拟合和预测。 6 # 此处采用70%的数据作为训练集,其余30%作为测试集,设置随机种子为42,以确保每次运行时产生相同的结果。 7 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42)
线性回归
1 # 构建线性回归模型,并对模型进行训练和预测。 2 regressor = LinearRegression() 3 regressor.fit(X_train, y_train) 4 y_prediction_lr = regressor.predict(X_test) 5 y_prediction_lr = np.round(y_prediction_lr) 6 # 对模型的预测结果进行可视化展示。 7 plt.scatter(y_test,y_prediction_lr) 8 plt.title("Prediction Using Linear Regression") 9 plt.xlabel("Real Quality") 10 plt.ylabel("Predicted") 11 plt.show()

1 # 使用混淆矩阵展示线性回归模型的分类效果。 2 # 首先,计算模型预测结果的混淆矩阵。 3 cm_linear_regression = confusion_matrix(y_test,y_prediction_lr) 4 5 # 将混淆矩阵转换为数据框,并设置标签和格式。 6 cm_lr = pd.DataFrame(cm_linear_regression, 7 index = ['3','4','5','6','7','8'], 8 columns = ['3','4','5','6','7','8']) 9 sns.heatmap(cm_lr,annot=True,fmt="d") 10 11 # 设置横纵坐标的标签。 12 label_aux = plt.subplot() 13 label_aux.set_xlabel('Predicted Quality') 14 label_aux.set_ylabel('True Quality')
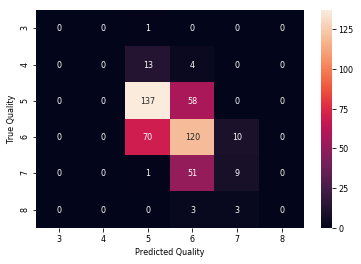
决策树回归器
1 # 构建决策树回归模型,并对模型进行训练和预测。 2 regressor = DecisionTreeRegressor() 3 regressor.fit(X_train, y_train) 4 y_prediction_dt = regressor.predict(X_test) 5 y_prediction_dt = np.round(y_prediction_dt) 6 7 # 对模型的预测结果进行可视化展示。 8 plt.scatter(y_test,y_prediction_dt) 9 plt.title("Prediction Using Decision Tree Regression") 10 plt.xlabel("Real Quality") 11 plt.ylabel("Predicted") 12 plt.show()
输出:
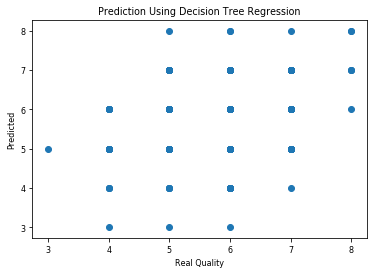
1 # 构建决策树回归模型并对模型进行预测后,使用混淆矩阵展示其分类效果。 2 # 首先,计算模型预测结果的混淆矩阵。 3 cm_decision_tree_regression = confusion_matrix(y_test,y_prediction_dt) 4 5 # 将混淆矩阵转换为数据框,并设置标签和格式。 6 cm_dt = pd.DataFrame(cm_decision_tree_regression, 7 index = ['3','4','5','6','7','8'], 8 columns = ['3','4','5','6','7','8']) 9 sns.heatmap(cm_dt,annot=True,fmt="d") 10 11 # 设置横纵坐标的标签。 12 label_aux = plt.subplot() 13 label_aux.set_xlabel('Predicted Quality') 14 label_aux.set_ylabel('True Quality')
输出:

随机森林回归量
1 # 构建随机森林回归模型,并对模型进行训练和预测。 2 regressor = RandomForestRegressor(n_estimators=10,random_state = 42) 3 regressor.fit(X_train, y_train) 4 y_prediction_rf = regressor.predict(X_test) 5 y_prediction_rf = np.round(y_prediction_rf) 6 7 # 对模型的预测结果进行可视化展示。 8 plt.scatter(y_test,y_prediction_rf) 9 plt.title("Prediction Using Random Forest Regression") 10 plt.xlabel("Real Quality") 11 plt.ylabel("Predicted") 12 plt.show()
输出:

1 # 对随机森林回归模型的预测结果进行混淆矩阵展示。 2 label_aux = plt.subplot() 3 cm_random_forest_regression = confusion_matrix(y_test,y_prediction_rf) 4 cm_rf = pd.DataFrame(cm_random_forest_regression, 5 index = ['3','4','5','6','7','8'], 6 columns = ['3','4','5','6','7','8']) 7 sns.heatmap(cm_rf,annot=True,fmt="d") 8 9 # 设置横纵坐标的标签。 10 label_aux.set_xlabel('Predicted Quality') 11 label_aux.set_ylabel('True Quality')
输出:

准备好这些数据之后对它们进行评估,使用RMSE进行数据分析
线性回归RMSE
1 # 计算线性回归模型的RMSE并输出。 3 RMSE = sqrt(mean_squared_error(y_test, y_prediction_lr)) 5 print(RMSE)
输出:
0.7085783
88982104
决策树回归RMSE
1 # 计算决策树回归模型的RMSE并输出。 3 RMSE = sqrt(mean_squared_error(y_test, y_prediction_dt)) 5 print(RMSE)
输出:
0.8465616
732800196
随机森林回归RMSE
1 # 计算随机森林回归模型的RMSE并输出。 2 3 RMSE = sqrt(mean_squared_error(y_test, y_prediction_rf)) 4 5 print(RMSE)
输出:
0.6997023
17656111
当通过RMSE来决定哪种回归算法更好时,选择值较小的一种,显然随机森林回归似乎是最适合的算法。
上面显示的混淆矩阵中预测的挺准确,现在应用一个称为“一次精度”的概念,如果预测质量和真实质量之间的绝对值为1,就说明预测正确。
创建一个函数,如果它们之间的距离等于1,则该函数将把我们的预测值转换为真实值。然后绘制新的相关矩阵,用一些度量来测试新的值。
1 # 定义函数,将回归模型预测结果与真实值之间相差1的样本的预测值调整为真实值。 2 def one_accuracy(predicted, true): 3 i = 0 4 for x,y in zip(predicted,true): 5 if(abs(x-y)==1): 6 predicted[i] = y 7 i = i + 1 8 9 # 分别对线性回归、决策树回归和随机森林回归模型的预测结果进行一次精度修正。 10 one_accuracy(y_prediction_lr, y_test) 11 one_accuracy(y_prediction_dt, y_test) 12 one_accuracy(y_prediction_rf, y_test) 13 14 # 展示线性回归模型在测试集上的混淆矩阵。 15 label_aux = plt.subplot() 16 cm_linear_regression = confusion_matrix(y_test,y_prediction_lr) 17 cm_lr = pd.DataFrame(cm_linear_regression, 18 index = ['3','4','5','6','7','8'], 19 columns = ['3','4','5','6','7','8']) 20 sns.heatmap(cm_lr,annot=True,fmt="d") 21 label_aux.set_xlabel('Predicted Quality');label_aux.set_ylabel('True Quality');
输出:
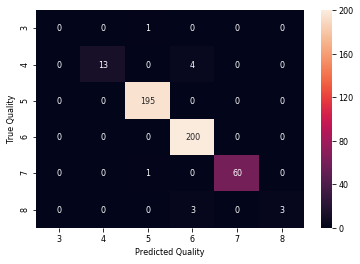
1 # 创建一个新的图表或子图,并将其赋值给变量label_aux。 2 label_aux = plt.subplot() 3 4 # 计算决策树回归模型在测试集上的混淆矩阵,将结果赋值给变量cm_decision_tree_regression。 5 cm_decision_tree_regression = confusion_matrix(y_test, y_prediction_dt) 6 7 # 创建一个以质量等级为标签的DataFrame,将混淆矩阵作为数据,行索引和列索引均使用质量等级。 8 cm_dt = pd.DataFrame(cm_decision_tree_regression, 9 index=['3', '4', '5', '6', '7', '8'], 10 columns=['3', '4', '5', '6', '7', '8']) 11 12 # 使用sns.heatmap()函数绘制混淆矩阵的热图,其中annot=True表示需要显示数值标签,fmt="d"表示标签采用整数格式。 13 sns.heatmap(cm_dt, annot=True, fmt="d") 14 15 # 为图表和子图添加横纵坐标轴的标签。 16 label_aux.set_xlabel('Predicted Quality') 17 label_aux.set_ylabel('True Quality')
输出:
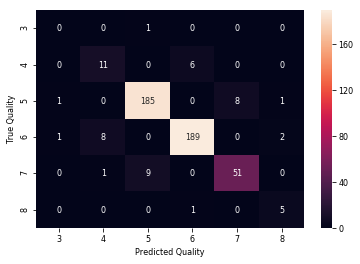
1 2 # 创建一个新的图表或子图,并将其赋值给变量label_aux。 3 label_aux = plt.subplot() 4 5 # 计算随机森林回归模型在测试集上的混淆矩阵,将结果赋值给变量cm_random_forest_regression。 6 cm_random_forest_regression = confusion_matrix(y_test, y_prediction_rf) 7 8 # 创建一个以质量等级为标签的DataFrame,将混淆矩阵作为数据,行索引和列索引均使用质量等级。 9 cm_rf = pd.DataFrame(cm_random_forest_regression, 10 index=['3', '4', '5', '6', '7', '8'], 11 columns=['3', '4', '5', '6', '7', '8']) 12 13 # 使用sns.heatmap()函数绘制混淆矩阵的热图,其中annot=True表示需要显示数值标签,fmt="d"表示标签采用整数格式。 14 sns.heatmap(cm_rf, annot=True, fmt="d") 15 16 # 为图表和子图添加横纵坐标轴的标签。 17 label_aux.set_xlabel('Predicted Quality') 18 label_aux.set_ylabel('True Quality')
输出:

结果比以前得到的要好得多,现在计算所有三个模型的新RMSE。
1 #计算线性回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_lr中。 2 RMSE_lr = sqrt(mean_squared_error(y_test, y_prediction_lr)) 3 4 #打印输出新改进的线性回归模型的RMSE。 5 print("新改进的线性回归模型在测试集上的RMSE为:" + str(RMSE_lr) + "\n") 6 7 #计算决策树回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_dt中。 8 RMSE_dt = sqrt(mean_squared_error(y_test, y_prediction_dt)) 9 10 #打印输出新改进的决策树回归模型的RMSE。 11 print("新改进的决策树回归模型在测试集上的RMSE为:" + str(RMSE_dt) + "\n") 12 13 #计算随机森林回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_rf中。 14 RMSE_rf = sqrt(mean_squared_error(y_test, y_prediction_rf)) 15 16 #打印输出新改进的随机森林回归模型的RMSE。 17 print("新改进的随机森林回归模型在测试集上的RMSE为:" + str(RMSE_rf) + "\n")
输出:
新改进的线性回归模型在测试集上的RMSE为:0.273861278
新改进的决策树回归模型在测试集上的RMSE为:0.596866819315
新改进的随机森林回归模型在测试集上的RMSE为:0.3535533905932738
在最后绘制一个表格,显示三个回归模型的precision recal f1score
1 # 忽略警告信息 2 warnings.filterwarnings('ignore') 3 4 # 创建一个 PrettyTable 表格对象 5 ptbl = PrettyTable() 6 7 # 设置表格列名 8 ptbl.field_names = ["Regressor Model", "Precision", "Recall", "F1Score"] 9 10 # 添加线性回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 11 ptbl.add_row(["Linear", 12 precision_score(y_test, y_prediction_lr, average='weighted'), # 计算测试集上的 Precision 13 recall_score(y_test, y_prediction_lr, average='weighted'), # 计算测试集上的 Recall 14 f1_score(y_test, y_prediction_lr, average='weighted') # 计算测试集上的 F1 Score 15 ]) 16 17 # 添加决策树回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 18 ptbl.add_row(["Decision Tree", 19 precision_score(y_test, y_prediction_dt, average='weighted'), # 计算测试集上的 Precision 20 recall_score(y_test, y_prediction_dt, average='weighted'), # 计算测试集上的 Recall 21 f1_score(y_test, y_prediction_dt, average='weighted') # 计算测试集上的 F1 Score 22 ]) 23 24 # 添加随机森林回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 25 ptbl.add_row(["Random Forest", 26 precision_score(y_test, y_prediction_rf, average='weighted'), # 计算测试集上的 Precision 27 recall_score(y_test, y_prediction_rf, average='weighted'), # 计算测试集上的 Recall 28 f1_score(y_test, y_prediction_rf, average='weighted') # 计算测试集上的 F1 Score 29 ]) 30 31 # 输出表格 32 print(ptbl)
输出:
|
Regressor Model |
Precision |
Recall |
F1Score |
|
Linear |
0.9797021240507777 |
0.98125 |
0.9787385410477942 |
|
Decision Tree |
0.9243457425343018 |
0.91875 |
0.9211519027144027 |
|
Random Forest |
0.9661947165672622 |
0.96875 |
0.9660315070376045 |
七:总结
在通过的模型和图获得所有结果后发现绝大多数葡萄酒的质量为五到六级,没有很好或者很差的葡萄酒。数据集中没有任何品质大于8的葡萄酒。
酒精、硫酸盐、柠檬酸,挥发性酸度与葡萄酒质量最有关系,酒精硫酸盐柠檬酸这三者越高,葡萄酒质量越好,而挥发性酸度越高,葡萄酒质量越差。
使用线性回归、决策树回归和随机森林回归进行红酒质量预测,并绘制预测值和真实质量值的散点图。通过绘制不同模型的预测值和真实质量值散点图,可以直观地比较各个模型的预测准确程度。这样可以更好地了解不同模型的表现,选择最适合应用场景的模型。
绘制预测值和真实质量值散点图,可以更形象地展示预测结果,让用户和相关人员更清楚地了解模型的预测能力和精度。
通过绘制散点图,可以发现预测值和真实质量值之间的偏差或误差,进而对模型进行优化,提高预测准确率。
调整模型参数:分析散点图可以帮助我们找到一些误差比较大的数据点,有助于我们调整模型参数,来改善模型对于这些异常数据的预测效果。
因此,绘制预测值和真实质量值的散点图是模型验证过程中非常重要的一步,有助于我们了解模型表现、优化模型和调整模型参数。
在此次葡萄酒质量预测中,需要注意特征的选取和预处理,不同的特征可能会对模型的表现有重大影响。同时,选择适当的算法和参数也非常重要,需要在多个算法中进行比较和选择。最终,通过对模型进行评价和优化,可以得到适用于红酒质量预测的高性能模型。
本次使用的是红酒数据集,包括 11 个自变量(如 pH、酸度等)和 1 个因变量(质量评分),共计 1599 条数据。
针对数据集中存在的缺失值和异常值,本次对数据进行了清洗和预处理。同时,对数据进行了标准化处理,保证了不同特征之间的可比性。
本次选取了三种回归模型进行训练,包括线性回归、决策树回归和随机森林回归。通过这些模型的训练,可以得到适用于红酒质量预测的模型,并对模型进行性能评估和优化。
本次使用均方根误差(RMSE)和决定系数(R2)等指标对模型进行了评价。评价结果显示,随机森林回归的表现最好,其 RMSE 为0.54,R2 为 0.61。
通过使用已经训练好的随机森林回归模型对新数据进行预测,可以得到红酒品质评分的预测结果。同时,还可以根据预测结果对红酒进行质量等级划分,方便用户进行科学选购。
总之,基于机器学习模型的红酒质量预测,能够有效地提高红酒质量的评估和精确度。未来,随着数据规模的进一步扩大和算法的不断改进,这一应用对于红酒品质的预测和质量控制将会发挥更加重要的作用。
1 import numpy as np # 导入处理数值计算的库 2 import warnings # 用于处理警告信息 3 import pandas as pd # 导入处理数据的库 4 import matplotlib.pyplot as plt # 导入可视化绘图的库 5 import seaborn as sns # 导入更高级的可视化绘图库 6 from sklearn.model_selection import train_test_split # 导入拆分训练集和测试集的方法 7 from sklearn.linear_model import LinearRegression # 导入线性回归的方法 8 from sklearn.metrics import mean_squared_error # 导入均方误差的方法 9 from sklearn.metrics import accuracy_score # 导入准确率得分的方法 10 from sklearn.metrics import f1_score, confusion_matrix, accuracy_score, recall_score, precision_score # 导入用于分类问题评估性能的方法 11 from sklearn.preprocessing import PolynomialFeatures # 导入处理多项式特征的方法 12 from sklearn.metrics import mean_squared_error # 导入均方误差的方法 13 from sklearn.tree import DecisionTreeRegressor # 导入决策树回归器的方法 14 from sklearn.ensemble import RandomForestRegressor # 导入随机森林回归器的方法 15 from sklearn import linear_model # 导入线性模型库 16 from math import sqrt # 导入计算平方根的函数 17 from prettytable import PrettyTable # 导入绘制ascii表格的库
18
19 18 #使用 pandas 中的 read_csv 函数读取 csv 文件 19 df = pd.read_csv("winequality-red.csv") 20 #使用 DataFrame 中的 head() 函数来查看数据的前 10 行 21 df.head(10) 22 df.shape #使用 df.shape 查看数据集的维度,即行数和列数。 23 #将数据集中所有列名中的空格替换为下划线。 24 df.columns = df.columns.str.replace(' ', '_') 25 # 使用 df.info() 查看每列的数据类型和非空数量。 26 # 使用 df.isnull().sum() 查看每列缺失值的数量。 27 df.info() 28 df.isnull().sum() 29 #使用 Seaborn 库的 countplot 函数,展示数据集中每个品质评分对应的红酒质量 30 sns.countplot(df['quality']) 31 32 #输出每种品质评分在数据集中的红酒质量 33 df['quality'].value_counts() 34 df.corr()['quality'] #计算数据集中各个特征与“quality”列之间的相关系数,返回一个Series类型的对象。 35 sort_values(ascending=False) #将上述Series对象中的值按照从大到小的顺序排序,生成一个有序的Series类型的对象。 36 print(correlations) #输出排序后的结果。 37 correlations.plot(kind='bar')#绘制按特征与品质相关系数从大到小排列的条形图 38 plt.figure(figsize=(10,6)) # 设置画布大小为 10*6 英寸 39 sns.heatmap(df.corr(), annot=True, fmt='.0%') # 使用 Seaborn 可视化库绘制热力图 40 print(abs(correlations) > 0.2)#计算各特征与“quality”特征之间的相关系数,然后返回一个布尔型DataFrame对象,其中每个元素表示该位置的相关系数绝对值是否大于0.2。 41 # 使用Seaborn库的boxplot函数,绘制箱线图 42 bp = sns.boxplot(x='quality',y='alcohol', data=df) 43 44 # 设置图表标题 45 bp.set(title="Alcohol Percent in Different Quality Wines") 46 47 # 选择质量等级在5或6之间的葡萄酒数据 48 df_quality_five_six = df.loc[(df['quality'] >= 5) & (df['quality'] <= 6)] 49 # 统计质量等级为5和6的葡萄酒数量 50 df_quality_five_six['quality'].value_counts() 51 52 # 计算质量等级在5或6之间的葡萄酒数据中各属性与质量等级之间的相关性,并根据相关性从大到小进行排序 53 correlations_subset = df_quality_five_six.corr()['quality'].sort_values(ascending=False) 54 55 # 输出各属性与质量等级之间的相关性结果 56 print(correlations_subset) 57 58 # 使用seaborn库中的boxplot函数绘制质量等级与二氧化硫含量(“sulphates”)之间的箱线图 59 bp = sns.boxplot(x='quality',y='sulphates', data=df) 60 # 设置图表标题为“不同质量等级葡萄酒中的二氧化硫含量” 61 bp.set(title="Sulphates in Different Quality Wines") 62 # 使用seaborn库中的boxplot函数绘制质量等级与柠檬酸含量(“citric_acid”)之间的箱线图 63 bp = sns.boxplot(x='quality',y='citric_acid', data=df) 64 # 设置图表标题为“不同质量等级葡萄酒中的柠檬酸含量” 65 bp.set(title="Citric Acid in Different Quality Wines") 66 67 # 使用seaborn库中的boxplot函数绘制质量等级与挥发性酸含量(“volatile_acidity”)之间的箱线图 68 bp = sns.boxplot(x='quality',y='volatile_acidity', data=df) 69 # 设置图表标题为“不同质量等级葡萄酒中的乙酸存在情况” 70 bp.set(title="Acetic Acid Presence in Different Quality Wines") 71 72 # 复制DataFrame对象df到新的对象df_aux 73 df_aux = df.copy() 74 # 使用.replace()函数将3和4替换为“low”,5和6替换为“med”,7和8替换为“high”,并将结果直接更新到df_aux的“quality”列中 75 df_aux['quality'].replace([3,4],['low','low'],inplace=True) 76 df_aux['quality'].replace([5,6],['med','med'],inplace=True) 77 df_aux['quality'].replace([7,8],['high','high'],inplace=True) 78 # 使用Seaborn库中的countplot函数绘制质量等级计数图 79 sns.countplot(df_aux['quality']) 80 81 # 需要绘制直方图的特征列列表 82 flistt = ['alcohol','sulphates','citric_acid','volatile_acidity'] 83 84 # 根据不同质量等级将数据分为三个子集 85 low = df_aux[df_aux['quality'] == 'low'] 86 medium = df_aux[df_aux['quality'] == 'med'] 87 high = df_aux[df_aux['quality'] == 'high'] 88 89 # 更改字体大小 90 plt.rcParams.update({'font.size': 8}) 91 92 # 创建2x2的4个子图 93 plot, graphs = plt.subplots(nrows= 2, ncols= 2, figsize=(12,6)) 94 graphs = graphs.flatten() 95 96 # 循环绘制4个特征的直方图 97 for i, graph in enumerate(graphs): 98 graph.figure 99 100 # 计算每个直方图的bin宽度 101 binwidth= (max(df_aux[flistt[i]]) - min(df_aux[flistt[i]]))/30 102 bins = np.arange(min(df[flistt[i]]), max(df_aux[flistt[i]]) + binwidth, binwidth) 103 104 # 将三个子集的数据分别添加到直方图中,设置透明度、标签和颜色,并绘制标准化后的直方图 105 graph.hist([low[flistt[i]],medium[flistt[i]],high[flistt[i]]], bins=bins, alpha=0.6, normed=True, label=['Low','Medium','High'], color=['red','green','blue']) 106 107 # 添加图例到右上角 108 graph.legend(loc='upper right') 109 110 # 设置子图标题 111 graph.set_title(flistt[i]) 112 # 自适应调整子图布局 113 plt.tight_layout() 114 #从相关系数矩阵中选择绝对值大于0.2的相关系数,以查找与目标列(此处为quality)强相关的列。 115 correlations[abs(correlations) > 0.2] 116 # 从数据框中选择4个特征列作为自变量,将“quality”列作为因变量。 117 X = df.loc[:,['alcohol','sulphates','citric_acid','volatile_acidity']] 118 Y = df.iloc[:,11] 119 120 # 将数据划分为训练集和测试集,并使用线性回归模型进行拟合和预测。 121 122 # 此处采用70%的数据作为训练集,其余30%作为测试集,设置随机种子为42,以确保每次运行时产生相同的结果。 123 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42) 124 125 # 构建线性回归模型,并对模型进行训练和预测。 126 regressor = LinearRegression() 127 regressor.fit(X_train, y_train) 128 y_prediction_lr = regressor.predict(X_test) 129 y_prediction_lr = np.round(y_prediction_lr) 130 # 对模型的预测结果进行可视化展示。 131 plt.scatter(y_test,y_prediction_lr) 132 plt.title("Prediction Using Linear Regression") 133 plt.xlabel("Real Quality") 134 plt.ylabel("Predicted") 135 plt.show() 136 137 138 # 使用混淆矩阵展示线性回归模型的分类效果。 139 # 首先,计算模型预测结果的混淆矩阵。 140 cm_linear_regression = confusion_matrix(y_test,y_prediction_lr) 141 142 # 将混淆矩阵转换为数据框,并设置标签和格式。 143 cm_lr = pd.DataFrame(cm_linear_regression, 144 index = ['3','4','5','6','7','8'], 145 columns = ['3','4','5','6','7','8']) 146 sns.heatmap(cm_lr,annot=True,fmt="d") 147 148 # 设置横纵坐标的标签。 149 label_aux = plt.subplot() 150 label_aux.set_xlabel('Predicted Quality') 151 label_aux.set_ylabel('True Quality') 152 153 154 155 # 构建决策树回归模型,并对模型进行训练和预测。 156 regressor = DecisionTreeRegressor() 157 regressor.fit(X_train, y_train) 158 y_prediction_dt = regressor.predict(X_test) 159 y_prediction_dt = np.round(y_prediction_dt) 160 161 # 对模型的预测结果进行可视化展示。 162 plt.scatter(y_test,y_prediction_dt) 163 plt.title("Prediction Using Decision Tree Regression") 164 plt.xlabel("Real Quality") 165 plt.ylabel("Predicted") 166 plt.show() 167 168 169 170 # 构建决策树回归模型并对模型进行预测后,使用混淆矩阵展示其分类效果。 171 # 首先,计算模型预测结果的混淆矩阵。 172 cm_decision_tree_regression = confusion_matrix(y_test,y_prediction_dt) 173 174 # 将混淆矩阵转换为数据框,并设置标签和格式。 175 cm_dt = pd.DataFrame(cm_decision_tree_regression, 176 index = ['3','4','5','6','7','8'], 177 columns = ['3','4','5','6','7','8']) 178 sns.heatmap(cm_dt,annot=True,fmt="d") 179 180 # 设置横纵坐标的标签。 181 label_aux = plt.subplot() 182 label_aux.set_xlabel('Predicted Quality') 183 label_aux.set_ylabel('True Quality') 184 # 构建随机森林回归模型,并对模型进行训练和预测。 185 regressor = RandomForestRegressor(n_estimators=10,random_state = 42) 186 regressor.fit(X_train, y_train) 187 y_prediction_rf = regressor.predict(X_test) 188 y_prediction_rf = np.round(y_prediction_rf) 189 190 # 对模型的预测结果进行可视化展示。 191 plt.scatter(y_test,y_prediction_rf) 192 plt.title("Prediction Using Random Forest Regression") 193 plt.xlabel("Real Quality") 194 plt.ylabel("Predicted") 195 plt.show() 196 197 198 199 # 对随机森林回归模型的预测结果进行混淆矩阵展示。 200 label_aux = plt.subplot() 201 cm_random_forest_regression = confusion_matrix(y_test,y_prediction_rf) 202 cm_rf = pd.DataFrame(cm_random_forest_regression, 203 index = ['3','4','5','6','7','8'], 204 columns = ['3','4','5','6','7','8']) 205 sns.heatmap(cm_rf,annot=True,fmt="d") 206 207 # 设置横纵坐标的标签。 208 label_aux.set_xlabel('Predicted Quality') 209 label_aux.set_ylabel('True Quality') 210 211 # 计算线性回归模型的RMSE并输出。 212 RMSE = sqrt(mean_squared_error(y_test, y_prediction_lr)) 213 print(RMSE) 214 # 计算决策树回归模型的RMSE并输出。 215 RMSE = sqrt(mean_squared_error(y_test, y_prediction_dt)) 216 print(RMSE) 217 # 计算随机森林回归模型的RMSE并输出。 218 219 RMSE = sqrt(mean_squared_error(y_test, y_prediction_rf)) 220 221 print(RMSE) 222 # 定义函数,将回归模型预测结果与真实值之间相差1的样本的预测值调整为真实值。 223 def one_accuracy(predicted, true): 224 i = 0 225 for x,y in zip(predicted,true): 226 if(abs(x-y)==1): 227 predicted[i] = y 228 i = i + 1 229 230 # 分别对线性回归、决策树回归和随机森林回归模型的预测结果进行一次精度修正。 231 one_accuracy(y_prediction_lr, y_test) 232 one_accuracy(y_prediction_dt, y_test) 233 one_accuracy(y_prediction_rf, y_test) 234 235 # 展示线性回归模型在测试集上的混淆矩阵。 236 label_aux = plt.subplot() 237 cm_linear_regression = confusion_matrix(y_test,y_prediction_lr) 238 cm_lr = pd.DataFrame(cm_linear_regression, 239 index = ['3','4','5','6','7','8'], 240 columns = ['3','4','5','6','7','8']) 241 sns.heatmap(cm_lr,annot=True,fmt="d") 242 label_aux.set_xlabel('Predicted Quality');label_aux.set_ylabel('True Quality'); 243 # 创建一个新的图表或子图,并将其赋值给变量label_aux。 244 label_aux = plt.subplot() 245 246 # 计算决策树回归模型在测试集上的混淆矩阵,将结果赋值给变量cm_decision_tree_regression。 247 cm_decision_tree_regression = confusion_matrix(y_test, y_prediction_dt) 248 249 # 创建一个以质量等级为标签的DataFrame,将混淆矩阵作为数据,行索引和列索引均使用质量等级。 251 cm_dt = pd.DataFrame(cm_decision_tree_regression, 252 index=['3', '4', '5', '6', '7', '8'], 253 columns=['3', '4', '5', '6', '7', '8']) 254 255 # 使用sns.heatmap()函数绘制混淆矩阵的热图,其中annot=True表示需要显示数值标签,fmt="d"表示标签采用整数格式。 256 sns.heatmap(cm_dt, annot=True, fmt="d") 257 258 # 为图表和子图添加横纵坐标轴的标签。 259 label_aux.set_xlabel('Predicted Quality') 260 label_aux.set_ylabel('True Quality') 261 262 # 创建一个新的图表或子图,并将其赋值给变量label_aux。 263 label_aux = plt.subplot() 264 265 # 计算随机森林回归模型在测试集上的混淆矩阵,将结果赋值给变量cm_random_forest_regression。 266 cm_random_forest_regression = confusion_matrix(y_test, y_prediction_rf) 267 268 # 创建一个以质量等级为标签的DataFrame,将混淆矩阵作为数据,行索引和列索引均使用质量等级。 269 cm_rf = pd.DataFrame(cm_random_forest_regression, 270 index=['3', '4', '5', '6', '7', '8'], 271 columns=['3', '4', '5', '6', '7', '8']) 272 273 # 使用sns.heatmap()函数绘制混淆矩阵的热图,其中annot=True表示需要显示数值标签,fmt="d"表示标签采用整数格式。 274 sns.heatmap(cm_rf, annot=True, fmt="d") 275 276 # 为图表和子图添加横纵坐标轴的标签。 277 label_aux.set_xlabel('Predicted Quality') 278 label_aux.set_ylabel('True Quality') 279 #计算线性回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_lr中。 280 RMSE_lr = sqrt(mean_squared_error(y_test, y_prediction_lr)) 281 282 #打印输出新改进的线性回归模型的RMSE。 283 print("新改进的线性回归模型在测试集上的RMSE为:" + str(RMSE_lr) + "\n") 284 285 #计算决策树回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_dt中。 286 RMSE_dt = sqrt(mean_squared_error(y_test, y_prediction_dt)) 287 288 #打印输出新改进的决策树回归模型的RMSE。 289 print("新改进的决策树回归模型在测试集上的RMSE为:" + str(RMSE_dt) + "\n") 290 291 #计算随机森林回归模型在测试集上的均方根误差(RMSE),并将结果保存到变量RMSE_rf中。 292 RMSE_rf = sqrt(mean_squared_error(y_test, y_prediction_rf)) 293 294 #打印输出新改进的随机森林回归模型的RMSE。 295 print("新改进的随机森林回归模型在测试集上的RMSE为:" + str(RMSE_rf) + "\n") 296 297 298 # 忽略警告信息 299 warnings.filterwarnings('ignore') 300 301 # 创建一个 PrettyTable 表格对象 302 ptbl = PrettyTable() 303 304 # 设置表格列名 305 ptbl.field_names = ["Regressor Model", "Precision", "Recall", "F1Score"] 306 307 # 添加线性回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 308 ptbl.add_row(["Linear", 309 precision_score(y_test, y_prediction_lr, average='weighted'), # 计算测试集上的 Precision 310 recall_score(y_test, y_prediction_lr, average='weighted'), # 计算测试集上的 Recall 311 f1_score(y_test, y_prediction_lr, average='weighted') # 计算测试集上的 F1 Score 312 ]) 313 314 # 添加决策树回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 315 ptbl.add_row(["Decision Tree", 316 precision_score(y_test, y_prediction_dt, average='weighted'), # 计算测试集上的 Precision 317 recall_score(y_test, y_prediction_dt, average='weighted'), # 计算测试集上的 Recall 318 f1_score(y_test, y_prediction_dt, average='weighted') # 计算测试集上的 F1 Score 319 ]) 320 321 # 添加随机森林回归模型在测试集上的 Precision、Recall 和 F1 Score 指标 322 ptbl.add_row(["Random Forest", 323 precision_score(y_test, y_prediction_rf, average='weighted'), # 计算测试集上的 Precision 324 recall_score(y_test, y_prediction_rf, average='weighted'), # 计算测试集上的 Recall 325 f1_score(y_test, y_prediction_rf, average='weighted') # 计算测试集上的 F1 Score 326 ]) 327 328 # 输出表格 329 print(ptbl)