课程目标
1、掌握不同数据分片策略的配置方式与特点2、Mycat 扩缩容与数据导入导出
3、理解 Mycat 注解的作用与应用场景
4、读写分离的实现和原理
5、Mycat 核心原理分析总结
内容定位
适合在了解了 Mycat 的基本使用之后,想要深入学习Mycat 的同学
1 分片策略详解
Mycat 权威指南.pdf Page 116
1.1 Mycat 分片策略详解
总体上分为连续分片和离散分片,还有一种是连续分片和离散分片的结合,例如先范围后取模。比如范围分片(id 或者时间)就是典型的连续分片,单个分区的数量和边界是确定的。离散分片的分区总数量和边界是确定的,例如对key 进行哈希运算,或者再取模。
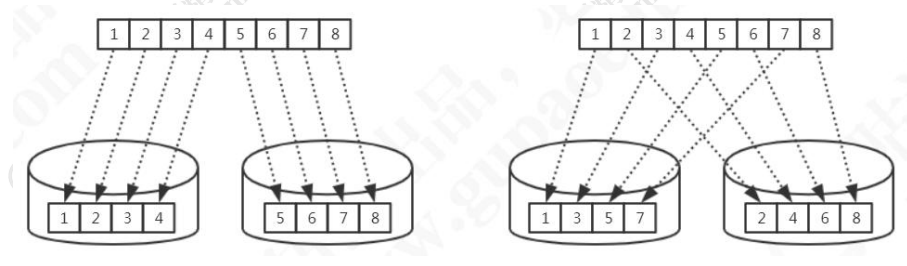
1.1.1 连续分片
范围分片(已演示)
Customer 表
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
# range start-end ,data node index
# K=1000,M=10000. 0-500M=0
500M-1000M=1
1000M-1500M=2
特点:容易出现冷热数据
按自然月分片
三个节点 imall 库创建 sharding_by_month 表(上节课的单库分表也是)
CREATE TABLE `sharding_by_month` (
`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, `db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表
<table name="sharding_by_month" dataNode="122-imall,123-imall,124-imall" rule="qs-sharding-by-month"/>
分片规则
<tableRule name="qs-sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>qs-partbymonth</algorithm>
</rule>
</tableRule>
分片算法
<function name="qs-partbymonth" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2025-10-01</property>
<property name="sEndDate">2025-12-31</property>
</function>
columns 标识将要分片的表字段,字符串类型,与 dateFormat 格式一致。
algorithm 为分片函数。
dateFormat 为日期字符串格式。
sBeginDate 为开始日期。
sEndDate 为结束日期
注意:节点个数要大于月份的个数
测试语句
truncate table sharding_by_month;
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2024-10-16', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2025-10-27', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2026-11-04', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2027-11-11', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2029-12-25', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2030-12-31', database());
注意:以上跟年度没有关系,只跟月度有关。
问题:不在 10 月和 12 月之间的数据,路由到哪个节点?结果不一定。可以在本地调试一下。
另外还有按天分片(可以指定多少天一个分片)、按小时分片
1.1.2 离散分片
十进制取模分片(已演示)
根据分片键进行十进制求模运算。sharding_by_mod 表。
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
truncate table sharing_by_mod;
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (1, '1');
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (2, '2');
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (3, '3');
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (4, '4');
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (5, '5');
INSERT INTO `sharding_by_mod` (`id`, `db_nm`) VALUES (6, '6');
特点:分布均匀,但是迁移工作量比较大
枚举分片
将所有可能出现的值列举出来,指定分片。例如:全国34 个省,要将不同的省的数据存放在不同的节点,可用枚举的方式。
三个节点 imall 库创建 sharding_by_intfile 表
CREATE TABLE `sharding_by_intfile` (
`age` int(11) NOT NULL, `db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表:
<table name="sharding_by_intfile" dataNode="122-imall,123-imall,124-imall" rule="qs-sharding-by-intfile"/>
分片规则:
<tableRule name="qs-sharding-by-intfile">
<rule>
<columns>age</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
分片算法:
<function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
type:默认值为 0,0 表示 Integer,非零表示String。PartitionByFileMap.java,通过 map 来实现。策略文件:partition-hash-int.txt
16=0
17=1
18=2
插入数据测试(注意是在 122mycat 上执行):
truncate table sharding_by_intfile;
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (16, database());
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (17, database());
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (18, database());
特点:适用于枚举值固定的场景。
一致性哈希
一致性 hash 有效解决了分布式数据的扩容问题。
建表语句:
CREATE TABLE `sharding_by_murmur` (
`id` int(10) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表
<table name="sharding_by_murmurhash" primaryKey="id" dataNode="122-imall,123-imall,124-imall"rule="sharding-by-murmur" />
分片规则
<tableRule name="qs-sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>qs-murmur</algorithm>
</rule>
</tableRule>
分片算法
<function name="qs-murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">3</property>
<property name="virtualBucketTimes">160</property>
</function>
测试语句
truncate table sharding_by_murmur;
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (1, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (2, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (3, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (4, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (5, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (6, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (7, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (8, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (9, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (10, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (11, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (12, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (13, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (14, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (15, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (16, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (17, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (18, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (19, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (20, database());
特点:可以一定程度减少数据的迁移。
固定分片哈希
这是先求模得到逻辑分片号,再根据逻辑分片号直接映射到物理分片的一种散列算法。
建表语句:
CREATE TABLE `sharding_by_long` (
`id` int(10) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL
) ;
逻辑表
<table name="sharding_by_long" dataNode="122-imall,123-imall,124-imall" rule="qs-sharding-by-long"/>
分片规则
<tableRule name="qs-sharding-by-long">
<rule>
<columns>id</columns>
<algorithm>qs-sharding-by-long</algorithm>
</rule>
</tableRule>
平均分成 8 片(%1024 的余数,1024=128*8):
<function name="qs-sharding-by-long" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
- partitionCount 为指定分片个数列表。
- partitionLength 为分片范围列表。

第二个例子:
两个数组,分成不均匀的 3 个节点(%1024 的余数,1024=2256+1512):
<function name="qs-sharding-by-long" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
3 个节点,对 1024 取模余数的分布

测试语句
truncate table sharding_by_long;
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (222, database());
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (333, database());
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (666, database());
特点:在一定范围内 id 是连续分布的。
取模范围分片
逻辑表
<table name="sharding_by_pattern" primaryKey="id" dataNode="122-imall,123-imall,124-imall"
rule="sharding-by-pattern" />
建表语句
CREATE TABLE `sharding_by_pattern` (
`id` varchar(20) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL
) ;
分片规则
<tableRule name="sharding-by-pattern">
<rule>
<columns>id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
分片算法
<function name="sharding-by-pattern" class=" io.mycat.route.function.PartitionByPattern"><property name="patternValue">100</property>
<property name="defaultNode">0</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
patternValue 取模基数,这里设置成 100
partition-pattern.txt,一共 3 个节点
id=19%100=19,在 dn1;
id=222%100=22,dn2;
id=371%100=71,dn3
# id partition range start-end ,data node index
###### first host configuration
1-20=0
21-70=1
71-100=2
测试语句
truncate table sharding_by_pattern;
INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (19, database());
INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (222, database());
INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (371, database());
特点:可以调整节点的数据分布。
范围取模分片
建表语句
CREATE TABLE `sharding_by_rang_mod` (
`id` bigint(20) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL
);
逻辑表
<table name="sharding_by_rang_mod" dataNode="122-imall,123-imall,124-imall"
rule="qs-sharding-by-rang-mod" />
分片规则
<tableRule name="qs-sharding-by-rang-mod">
<rule>
<columns>id</columns>
<algorithm>qs-rang-mod</algorithm>
</rule>
</tableRule>
分片算法
<function name="qs-rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
partition-range-mod.txt
# range start-end ,data node group size
0-20000=1
20001-40000=2
解读:先范围后取模。Id 在 20000 以内的,全部分布到dn1。Id在20001-40000的,%2 分布到 dn2,dn3。
插入数据:
truncate table sharding_by_rang_mod;
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (666, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (6667, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (16666, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (21111, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (22222, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (23333, database());
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (24444, database());
特点:扩容的时候旧数据无需迁移
其他分片规则
应用指定分片 PartitionDirectBySubString
日期范围哈希 PartitionByRangeDateHash
冷热数据分片 PartitionByHotDate
也 可 以 自 定 义 分 片 规 则 : extends AbstractPartitionAlgorithmimplementsRuleAlgorithm。
1.1.3 连续分片和离散分片的特点
-
连续分片优点:
- 1)范围条件查询消耗资源少(不需要汇总数据)
- 2)扩容无需迁移数据(分片固定)
-
连续分片缺点:
- 1)存在数据热点的可能性
- 2)并发访问能力受限于单一或少量 DataNode(访问集中)
-
离散分片优点:
- 1)并发访问能力增强(负载到不同的节点)
- 2)范围条件查询性能提升(并行计算)
-
离散分片缺点:
- 1)数据扩容比较困难,涉及到数据迁移问题
- 2)数据库连接消耗比较多
1.1.4 切分规则的选择
- 步骤:
- 1、找到需要切分的大表,和关联的表
- 2、确定分片字段(尽量使用主键),一般用最频繁使用的查询条件
- 3、考虑单个分片的存储容量和请求、数据增长(业务特性)、扩容和数据迁移问题。
例如:按照什么递增?序号还是日期?主键是否有业务意义?一般来说,分片数要比当前规划的节点数要大。
总结:根据业务场景,合理地选择分片规则。
举例:
老师:3.7 亿的数据怎么分表?我是不是分成3 台服务器?
1、一年内到达多少?两年内到达多少?(数据的增长速度)?答:一台设备每秒钟往 3 张表各写入一条数据,一共4 台设备。每张表一天86400*4=345600 条。每张表一个月 10368000 条。
分析:增长速度均匀,可以用日期切分,每个月分一张表。
2、什么业务?所有的数据都会访问,还是访问新数据为主?
答:访问新数据为主,但是所有的数据都可能会访问到
3、表结构和表数据是什么样的?一个月消耗多少空间?
答:字段不多,算过了,三年数据量有 3.7 亿,30G。分析:30G 没必要分库,浪费磁盘空间。
4、访问量怎么样?并发压力大么?
答:并发有一点吧
分析:如果并发量不大,不用分库,只需要在单库分表。不用引入Mycat中间件了。如果要自动路由的话可以用 Sharding-JDBC,否则就是自己拼装表名。
5、3 张表有没有关联查询之类的操作?
答:没有。
分析:还是拼装表名简单一点。
如果从单库变成分库分表,或者节点数的增加和减少,都会涉及到数据迁移的问题。数据迁移有两种,一种是在线不停机的迁移,还有一种是停机的。
2 Mycat 扩缩容
2.1 在线扩缩容思路
- 在线扩容的流程:
- 1、把历史数据,通过中间件迁移到新库
- 2、新的写请求,发送到消息队列,不消费
- 3、数据迁移完毕,迁移程序下线
- 4、消费消息,将增量数据写入新库
- 5、数据一致性验证
- 6、旧数据库下线,切换到新库,重启应用

如果数据已经超过了单个节点的存储上线,或者需要下线节点的时候,就需要对数据重新分片。
2.2 mysqldump 方式
系统第一次上线,把单张表迁移到 Mycat,可以用mysqldump。
MySQL 导出
mysqldump -uroot -p123456 -h127.0.0.1 -P3306 -c -t --skip-extended-insert imall > mysql-1107.sql
-c 代表带列名
-t 代表只要数据,不要建表语句
--skip-extended-insert 代表生成多行 insert(mycat childtable不支持多行插入ChildTable multi insert not provided)
Mycat 导入
mysql -uroot -p123456 -h127.0.0.1 -P8066 imall < mysql-1107.sql
2.3 Mycat 自带的离线扩缩容工具
如果是已有分片表,可以用 mycat 自带的工具,实际上是对mysqldump进行了包装。
2.3.1 准备工作
1、mycat 所在环境安装 mysql 客户端程序。
2、mycat 的 lib 目 录 下 添 加 mysql 的jdbc 驱动包(例如mysql-connector-java-5.1.27.jar)。
3、对扩容缩容的表所有节点数据进行备份,以便迁移失败后的数据恢复。
2.3.2 步骤
以取模分片表 sharding-by-mod 缩容为例

1、复制 schema.xml、rule.xml 并重命名为newSchema.xml、newRule.xml放于 conf 目录下。
2、修改 newSchema.xml 和 newRule.xml 配置文件为扩容缩容后的mycat配置参数(表的节点数、数据源、路由规则)。
注意:
只有节点变化的表才会进行迁移。仅分片配置变化不会迁移。newSchema.xml
<table name="sharding_by_mod" dataNode="122-imall,123-imall,124-imall" rule="qs-sharding-by-mod" />
改成(减少了一个节点):
<table name="sharding_by_mod" dataNode="122-imall,123-imall" rule="qs-sharding-by-mod" />
newRule.xml
修改 count 个数
<function name="qs-sharding-by-mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
3、修改 conf 目录下的 migrateTables.properties 配置文件,告诉工具哪些表需要进行扩容或缩容,没有出现在此配置文件的 schema 表不会进行数据迁移,格式:
注意,1)不迁移的表,不要修改 dn 个数,否则会报错。
2)ER 表,因为只有主表有分片规则,子表不会迁移。imall=sharding-by-mod
4、dataMigrate.sh 中这个必须要配置
通 过 命 令 "find / -name mysqldump" 查找mysqldump路径为"/usr/bin/mysqldump",指定#mysql bin 路径为"/usr/bin/"
#mysql bin 路径
RUN_CMD="$RUN_CMD -mysqlBin= /usr/bin/"
5、停止 mycat 服务
6、执行执行 bin/dataMigrate.sh 脚本
注意:必须要配置 Java 环境变量,不能用 openjdk
7、脚本执行完成,如果最后的数据迁移验证通过,就可以将之前的newSchema.xml和 newRule.xml 替换之前的 schema.xml 和 rule.xml 文件,并重启mycat即可。
注意事项:
1)保证分片表迁移数据前后路由规则一致(取模——取模)。
2)保证分片表迁移数据前后分片字段一致。
3)全局表将被忽略。
4)不要将非分片表配置到 migrateTables.properties 文件中。
5)暂时只支持分片表使用 MySQL 作为数据源的扩容缩容。
migrate 限制比较多,还可以使用 mysqldump。
总结:离线或者在线,主要看数据量,和对于业务的影响程度决定。
上一节课我们已经用 mycat 实现了 MySQL 数据的分片存储,第一个可以实现负载均衡,不同的读写发生在不同的节点上。第二可以实现横向扩展,如果数据持续增加,加机器就 OK 了。
当然,一个分片只有一台机器还不够。为了防止节点宕机或者节点损坏,都要用副本机制来实现。MySQL 数据库同样可以集群部署,有了多个节点之后,节点之间数据又是个大问题。
这里我们来学习一下 MySQL 是怎么实现节点数据同步的。
3 MySQL 主从复制
https://gper.club/articles/7e7e7f7ff3g5bgc3g6c MySQL 主从复制配置
3.1 主从复制的含义
在 MySQL 多服务器的架构中,主节点,也就是产生数据的节点叫master节点。其他的副本,向主节点同步数据的节点,叫做 slave(默认是异步的,客户端的数据在master刷盘就返回)。一个集群里面至少要有一个 master。slave 可以有多个。
3.2 主从复制的用途
数据备份:把数据复制到不同的机器上,以免单台服务器发生故障时数据丢失。负载均衡:结合负载的机制,均摊所有的应用访问请求,降低单机IO。高可用 HA:当节点故障时,自动转移到其他节点,提高可用性。主从复制的架构可以有多种:
3.3 主从复制的形式
一主一从/一主多从
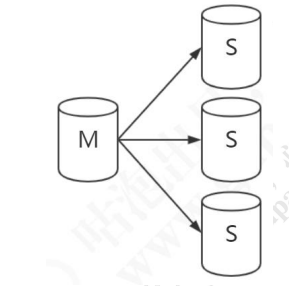
双主复制(互为主从)

级联复制
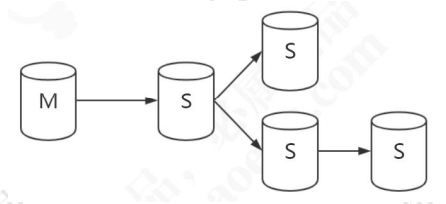
不过在,MySQL 自身并没有自动选举和故障转移的功能,需要依赖其他的中间件或者架构实现,比如 MMM,MHA,percona,mycat。
主从复制是怎么实现的呢?
3.4 binlog
客户端对 MySQL 数据库进行操作的时候,包括DDL 和DML 语句,服务端会在日志文件中用事件的形式记录所有的操作记录,这个文件就是binlog文件(属于逻辑日志,跟 Redis 的 AOF 文件类似)。Binary log,二进制日志。
基于 binlog,我们可以实现主从复制和数据恢复。
binlog 默认是不开启的,需要在服务端手动配置。注意有一定的性能损耗
3.4.1 binlog 配置
编辑 /etc/my.cnf
log-bin=/var/lib/mysql/mysql-bin
server-id=1
重启 MySQL 服务
service mysqld stop
service mysqld start
## 如果出错查看日志
vi /var/log/mysqld.log
cd /var/lib/mysql
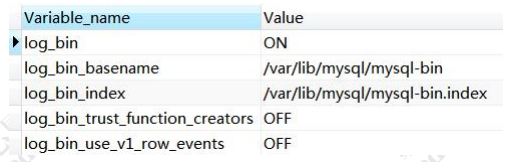
是否开启 binlog
show variables like 'log_bin%';
3.4.2 binlog 格式
STATEMENT:记录每一条修改数据的 SQL 语句(减少日志量,节约IO)。
ROW:记录哪条数据被修改了,修改成什么样子了(5.7 以后默认)。MIXED:结合两种方式,一般的语句用
STATEMENT,函数之类的用ROW。
查看 binlog 格式:
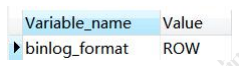
show global variables like '%binlog_format%';
Binlog 文件超过一定大小就会产生一个新的,查看binlog 列表:
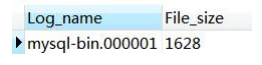
show binary logs;
大小:
show variables like 'max_binlog_size';
查看 binlog 内容
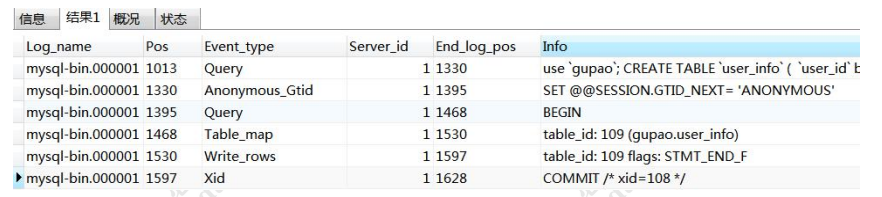
show binlog events in 'mysql-bin.000001';
用 mysqlbinlog 工具,基于时间查看 binlog
(注意这个是 Linux 命令, 不是 SQL)
/usr/bin/mysqlbinlog --start-datetime='2025-08-22 13:30:00' --stop-datetime='2025-08-22 14:01:01' -dgupao/var/lib/mysql/mysql-bin.000001
3.5 主从复制原理
3.5.1 主从复制配置
1、主库开启 binlog,设置 server-id
2、在主库创建具有复制权限的用户,允许从库连接
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'192.168.44.128' IDENTIFIEDBY '123456';
FLUSH PRIVILEGES;
3、从库/etc/my.cnf 配置,重启数据库
server-id=2
log-bin=mysql-bin
relay-log=mysql-relay-bin
read-only=1
log-slave-updates=1
开启 log-slave-updates 参数后,从库从主库复制的数据会写入log-bin日志文件里,这样可以实现互为主备或者级联复制(它自己也可以作为一个master 节点)。
4、在从库执行
stop slave;
change master to
master_host='192.168.44.121',master_user='repl',master_password='123456',master_log_file='mysql-bin.000001', master_log_pos=4;
start slave;
5、查看同步状态
SHOW SLAVE STATUS \G
Slave_IO_Running 和 Slave SQL Running 都为yes 为正常。
3.5.2 主从复制原理
这里面涉及到几个线程:
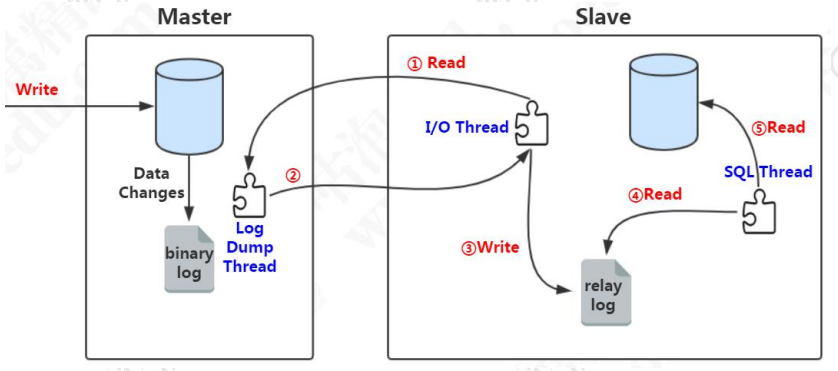
1、slave 服务器执行 start slave,开启主从复制开关,slave 服务器的IO线程请求从 master 服务器读取 binlog(如果该线程追赶上了主库,会进入睡眠状态)。
2、master 服务器创建 Log Dump 线程,把binlog 发送给slave服务器。slave服务器把读取到的 binlog 日志内容写入中继日志 relay log(会记录位置信息,以便下次继续读取)。
3、slave 服务器的 SQL 线程会实时检测 relay log 中新增的日志内容,把relaylog解析成 SQL 语句,并执行。
为什么需要 relay log?
为什么不把接收到的 binlog 数据直接写入从库?
Relay log 相当于一个中转站,也记录了 master 和slave 的同步信息
3.5.3 mycat 读写分离的实现
添加
<dataHost name="host122" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.44.122:3306" user="root" password="123456">
<readHost host="hostS1" url="192.168.44.129:3306" user="root" password="123456"/></writeHost>
</dataHost>
balance:负载的配置,决定 select 语句的负载

writeType:读写分离的配置,决定 update、delete、insert 语句的负载

switchType:主从切换配置

4 Mycat 注解
4.1 注解的作用
当关联的数据不在同一个节点的时候,Mycat 是无法实现跨库join的。
举例:
如果直接在 122-imall 插入主表数据,123-imall 插入明细表数据(本来应该在122),此时关联查询无法查询出来。
-- 122 节点插入
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES(9,1000003, 3, 1, '2019-9-25 11:35:49', '2019-9-25 11:35:49'); -- 123 节点插入
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(9,20250001, 85114752, 19.99, 1, 1, 1);
在 mycat 数据库查询,直接查询没有结果。
select a.order_id,b.goods_id from order_info a, order_detail b where a.order_id = b.order_id;
Mycat 作为一个中间件,有很多自身不支持的SQL 语句,比如存储过程,但是这些语句在实际的数据库节点上是可以执行的。有没有办法让Mycat 做一层透明的代理转发,直接找到目标数据节点去执行这些 SQL 语句呢?
那我们必须要有一种方式告诉 Mycat 应该在哪个节点上执行。这个就是Mycat的注解。我们在需要执行的 SQL 语句前面加上一段代码,帮助Mycat 找到我们的目标节点。
4.2 注解的用法
注解的形式是 :
/!mycat: sql=注解 SQL 语句/
注解的使用方式是 :
/!mycat: sql=注解 SQL 语句/ 真正执行的SQL
使用时将 = 号后的 "注解 SQL 语句" 替换为需要的SQL 语句即可。
注解中的语句有一些限制,或者注意的地方:

使用注解并不额外增加 MyCat 的执行时间;从解析复杂度以及性能考虑,注解SQL 应尽量简单,因为它只是用来做路由的。
注解可以帮我们解决什么问题呢?
4.3 注解使用示例
4.3.1 多表 ShareJoin
注意(表里面必须有三个节点的数据):
https://gper.club/articles/7e7e7f7ff7g59gc1g68 注意,跨库关联查询使用是有限制的
/*!mycat:catlet=io.mycat.catlets.ShareJoin */
select a.order_id,b.goods_id from order_info a, order_detail b where a.order_id = b.order_id;
4.3.2 DDL 或存储过程
customer.id=1 全部路由到 122
-- 表
/*!mycat: sql=select * from customer where id =1 */ CREATE TABLE test2(id INT); -- 存储过程
/*!mycat: sql=select * from customer where id =1 */ CREATE PROCEDURE test_proc() BEGINEND;
4.3.3 特殊语句自定义分片
Mycat 本身不支持 insert select,通过注解支持
122-imall 创建测试表:
CREATE TABLE `test2` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
);
【先确认 order_detail 表有数据】
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES(1,1000001, 1, 2, '2025-9-23 14:35:37', '2025-9-23 14:35:37');
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES(2,1000002, 1, 2, '2025-9-24 14:35:37', '2025-9-24 14:35:37');
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES(3,1000003, 3, 1, '2025-9-25 11:35:49', '2025-9-25 11:35:49');
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(3,20180001, 85114752, 19.99, 1, 1, 1);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(1,20180002, 25411251, 1280.00, 1, 1, 0);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(1,20180003, 62145412, 288.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(2,20180004, 21456985, 399.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(2,20180005, 21457452, 1680.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES(2,20180006, 65214789, 9999.00, 1, 1, 3);
/*!mycat: sql=select * from customer where id =1 */ INSERT INTO test2(id) SELECT id FROMorder_detail;
4.3.4 读写分离
读写分离 : 配置 Mycat 读写分离后,默认查询都会从读节点获取数据,但是有些场景需要获取实时数据,如果从读节点获取数据可能因延时而无法实现实时,Mycat支持通过注解 /balance/ 来强制从写节点(write host)查询数据。
/*balance*/ select a.* from customer a where a.id=6666;
4.3.5 读写分离数据库选择(1.6 版本之后)
/*!mycat: db_type=master */ select * from customer;
/*!mycat: db_type=slave */ select * from customer;
/*#mycat: db_type=master */ select * from customer;
/*#mycat: db_type=slave */ select * from customer;
注解支持的'! '不被 mysql 单库兼容
注解支持的'#'不被 MyBatis 兼容
随着 Mycat 的开发,更多的新功能正在加入
4.4 注解原理
Mycat 在执行 SQL 之前会先解析 SQL 语句,在获得分片信息后再到对应的物理节点上执行。如果 SQL 语句无法解析,则不能被执行。如果语句中有注解,则会先解析注解的内容获得分片信息,再把真正需要执行的 SQL 语句发送到对应的物理节点上。
所以我们在使用注解的时候,应该清楚地知道目标SQL 应该在哪个节点上执行,注解的 SQL 也指向这个分片,这样才能使用。如果注解没有使用正确的条件,会导致原始SQL 被发送到所有的节点上执行,造成数据错误。
5 XA 分布式事务
作为一个服务端的软件,或者说一个伪装成MySQL 数据库的代理层,怎么实现对分布式事务的支持呢?
我们看到 Mycat 的官方介绍,从 1.6.5 版本开始支持XA分布式事务。XA是一种两阶段提交的实现,我们先看看什么是两阶段提交。
5.1 二阶段提交
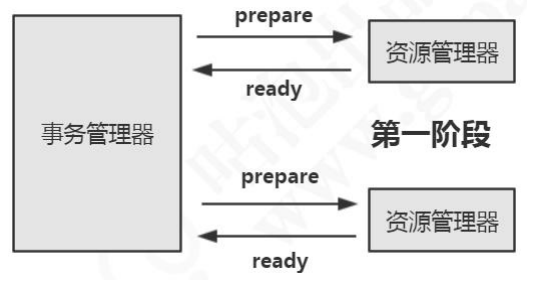
所谓的两个阶段是指准备 prepare 阶段和提交commit 阶段。
- 第一阶段分为两个步骤:
- 1、事务管理器通知参与该事务的各个资源管理器,通知他们开始准备事务。
- 2、资源管理器接收到消息后开始准备阶段,写好事务日志(redoundo)并执行事务,但不提交,然后将是否就绪的消息返回给事务管理器(此时已经将事务的大部分事情做完,以后的操作耗时极小)。
- 第二阶段也分为两个步骤:
- 1、事务管理器在接受各个消息后,开始分析,如果有任意数据库失败,则发送回滚命令,否则发送提交命令。
- 2、各个资源管理器接收到命令后,执行(耗时很少),并将提交消息返回给事务管理器。
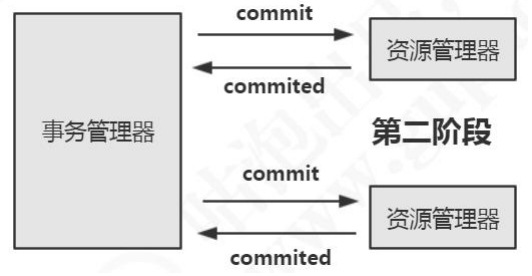
事务管理器接受消息后,事务结束,应用程序继续执行。
为什么要分两步执行?
一是因为分两步,就有了事务管理器统一管理的机会;
二尽可能晚地提交事务,让事务在提交前尽可能地完成所有能完成的工作,这样,最后的提交阶段将是耗时极短,耗时极短意味着操作失败的可能性也就降低。
5.2 XA 规范
在 XA 的分布式事务处理模型里面涉及到三个角色AP(应用程序)、RM(数据库)、TM(事务管理器)。
AP 定义事务的开始和结束,访问事务内的资源。
RM 除了数据库之外,还可以是其他的系统资源,比如文件系统,打印机服务器。
TM 负责管理全局事务,分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚、失败恢复等,是一个协调者的角色,可能是程序或者中间件。
XA 协议主要规定了了 TM 与 RM 之间的交互。
注意:通过实现 XA 的接口,只是提供了对XA 分布式事务的支持,并不是说数据库本身有分布式事务的能力。

5.3 MySQL 对 XA 的支持
XA 是一种两阶段提交的实现。数据库本身必须要提供被协调的接口,比如事务开启,准备,事务结束,事务提交,事务回滚。
https://dev.mysql.com/doc/refman/5.7/en/xa.html
MySQL 单节点运行 XA 事务演示:
use gupao;
-- 开启 XA 事务
xa start 'xid';
-- 插入数据
insert into teacher(tid,tname,tcid) values(100,'qingshan',1);
-- 结束一个 XA 事务
xa end 'xid';
-- 准备提交
xa prepare 'xid';
-- 列出所有处于 PREPARE 阶段的 XA 事务
xa recover;
-- 提交
xa commit 'xid';
工程:ssm-mycat,代码:com.qingshan.xa.XaTest
5.4 Mycat 中分布式事务的实现
Mycat 在 1.6.5 版本以后已经完全支持 XA 分布式强事务类型了。
对前端是资源管理器,对后端是事务管理器。
Mycat 中 XA 的用法:
用户应用侧(AP)的使用流程如下:
(1)set autocommit=0 --在应用层需要设置事务不能自动提交;注意XA事务和本地事务是冲突的。
(2)set xa=on --在 SQL 中设置 XA 为开启状态;
(3)执行 SQL
INSERT INTO `customer` (`id`, `name`) VALUES (6667, '赵先生');
INSERT INTO `customer` (`id`, `name`) VALUES (7778, '钱先生');
INSERT INTO `customer` (`id`, `name`) VALUES (16667, '孙先生');
(4)commit 或者 rollback
对事务进行提交(提交成功或者回滚异常)。流程图如下:

在这里 mycat 起到了事务协调者的角色。不过XA 两阶段提交存在一些问题,比如:
1、同步阻塞问题。资源是锁定的。
2、事务管理器不能挂。
3、数据一致性问题:如果部分参与者没有收到commit,事务不会提交。其他的分布式实现方案,参考微服务架构-Spring Cloud Alibaba-分布式事务。最后我们来看一下 Mycat 的原理。它是怎么帮我们实现分库分表和解决相关的问题的。
6 核心流程总结
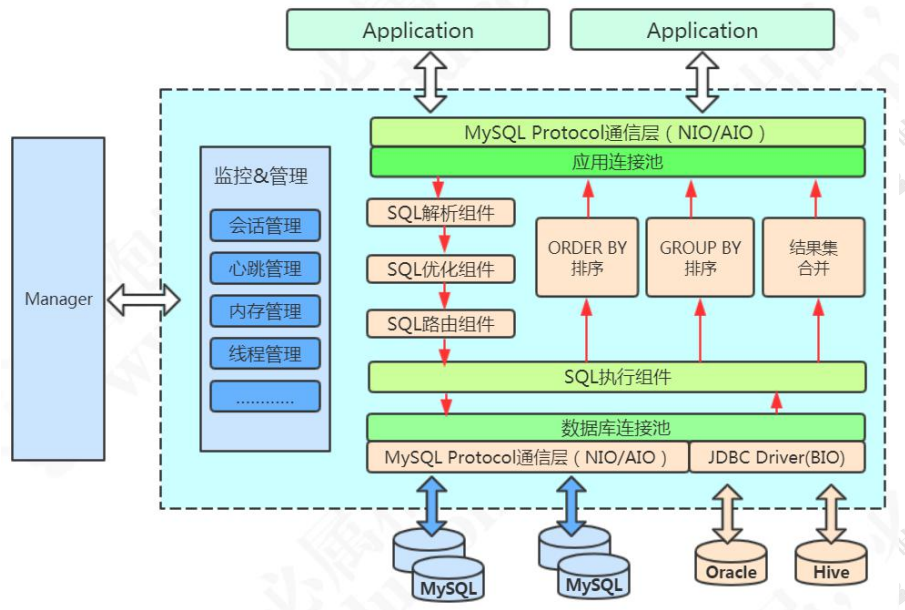
官网的架构图:
6.1 启动
1、MycatServer 启动,解析配置文件,包括服务器、分片规则等2、创建工作线程,建立前端连接和后端连接
6.2 执行 SQL
1、前端连接接收 MySQL 命令
2、解析 MySQL,Mycat 用的是 Druid 的DruidParser
3、获取路由
4、改写 MySQL,例如两个条件在两个节点上,则变成两条单独的SQL
例如 select * from travelrecord where id in(5000001, 10000001);
改写成:
select * from travelrecord where id = 5000001;(dn2执行)select * from travelrecord where id = 10000001;(dn3执行)又比如多表关联查询,先到各个分片上去获取结果,然后在内存中计算5、与后端数据库建立连接
6、发送 SQL 语句到 MySQL 执行
7、获取返回结果
8、处理返回结果,例如排序、计算等等
9、返回给客户端
6.3 源码下载与调试环境搭建
6.3.1 下载源代码,导入工程
git clone https://github.com/MyCATApache/Mycat-Server
6.3.2 配置
schema.xml 放在:src\main\resources
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" /><table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="20" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="127.0.0.1:3306" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
6.3.3 表结构
本地数据库创建 db1、db2、db3 数据库
create database db1;
create database db2;
create database db3;
全部执行建表脚本。
CREATE TABLE `company` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(64) DEFAULT '', `market_value` bigint(20) DEFAULT '0', PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `hotnews` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `title` varchar(64) DEFAULT '', `content` varchar(512) DEFAULT '0', `time` varchar(8) DEFAULT '', `cat_name` varchar(10) DEFAULT '', PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `travelrecord` (
`id` bigint(20) NOT NULL AUTO_INCREMENT, `city` varchar(32) DEFAULT '', `time` varchar(8) DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
6.3.4 逻辑表配置
travelrecord 表,根据 id 范围分片:
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
travelrecord 表分片规则:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
travelrecord 表分片算法
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
autopartition-long.txt
1-10000=0
10000-20000=1
20000-30000=2
hotnews 表,根据 id 取模分片,模以 3
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long"/>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
company 表,全局表,没有分片规则
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
6.3.5 debug 方式启动
debug 方式启动 main 方法
\src\main\java\io\mycat\MycatStartup.java
6.3.6 连接本机 Mycat 服务测试
测试语句
-- 范围分片
insert into travelrecord(`id`, `city`, `time`) values(1, '长沙', '20251020');
-- 取模分片
insert into hotnews(`id`, `title`, `content`) values(1,'咕泡', '盆鱼宴');
-- 全局表
insert into company(`name`, `market_value`) values('spring', 100);
6.3.7 调试入口
连接入口:
io.mycat.net.NIOAcceptor#accept
SQL 入口:
io.mycat.server.ServerQueryHandler#query
调试 DDL
truncate table travelrecord;
普通 Select,这三条语句的路由都不一样:
select * from hotnews where id =1;
select * from hotnews where id =2;
select * from hotnews where id =3;
insert:
insert into travelrecord(`id`, `city`, `time`) values(10000, '长沙', '20251020');
insert into travelrecord(`id`, `city`, `time`) values(20000, '长沙', '20251020');
insert into travelrecord(`id`, `city`, `time`) values(30000, '长沙', '20251020');
Step Out(Shift+F8)可以看到上一层的调用
7 Mycat 高可用
目前 Mycat 没有实现对多 Mycat 集群的支持。集群之前最麻烦的是数据同步和选举。可以暂时使用 HAProxy+Keepalived 实现。
参考:https://gper.club/articles/7e7e7f7ff3g5bgc5g6c
HAProxy+Keepalived 搭建 RabbitMQ 高可用集群。
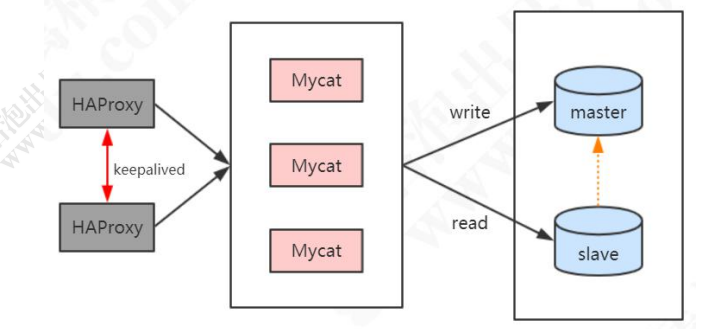
问题:分布式全局 ID 怎么解决?配置在机器之间怎么同步?
sequence_time_conf.properties 里面有机器号。不需要同步