综合设计——多源异构数据采集与融合应用综合实践
[码云地址](多源异构数据采集与融合应用综合实践: Call of Silence数据采集与融合综合实验 (gitee.com))
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:Call of Silence 项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 项目目标:通过在web端输入文本、图片、视频等多源数据进行内容提取并对其进行概括 技术路线:前端3件套(html、css、js)、flask、 |
| 团队成员学号 | 052103117、102102142、102102148、102102149、102102150、102102154、102102155、172109005 |
| 这个项目目标 | 对获取的多模态信息进行分析概括 |
| 其他参考文献 | [1]梁永侦.基于深度学习的图像风格迁移方法研究[J].计算机时代,2023,(08):107-112.DOI:10.16644/j.cnki.cn33-1094/tp.2023.08.024 [2]熊文楷.基于深度学习的中国画风格迁移[J].科技与创新,2023,(13):176-178.DOI:10.15913/j.cnki.kjycx.2023.13.054 [3]郑卓.基于深度学习的风格迁移技术研究[D].浙江工商大学,2023.DOI:10.27462/d.cnki.ghzhc.2023.001362 |
项目整体介绍
1、项目名称:多模态内容概括
2、项目背景:在当今社会,随着数字化时代的来临,信息呈现爆炸式增长,而这些信息涵盖了多种形态,本项目主要功能就是对获取的多模态信息进行分析概括,帮助用户从信息中快速获取主要内容。
3、项目意义:面对互联网时代的信息过载,用户更需要一种智能化的工具来过滤、提炼信息,以便更快速地获取关键信息。多模态信息分析程序的功能满足了这一需求,帮助用户从海量信息中快速获取主要内容。
-
数据采集
- 采用selenium框架对bilibili中视频、封面、音频等数据进行爬取
-
前端开发:
- 使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
- 用于上传文本、图片和视频等文件。
-
后端开发:
- 利用flask框架进行后端搭建。
- 用于接收前端发送的请求,对收到的数据进行保存和处理,最后返回文本结果。
-
数据处理与分析:
- 文本分析:采用星火的接口对输入的文本内容进行分析概括。
- 图片分析:
- 采用星火的接口对输入的图片进行概括,将概括后的文本进行分析概括返回图片概括后的结果。
- 视频分析:对于视频分析,没有找到合适的模型和接口进行概括,因此我们采用提取视频中的音频,对音频内容进行概括。
- 采用百度的接口对输入的视频提取主要内容并返回给用户。
-
风格迁移:
- 输入俩张图片,一张作为被学习的风格图片,一张作为学习的融合图片,通过VGG19神经网络进行训练,得到的模型,可以将任意俩张图片进行风格迁移
5、项目部分功能展示
①项目页面展示

②文本概括功能展示

③图片概括功能展示

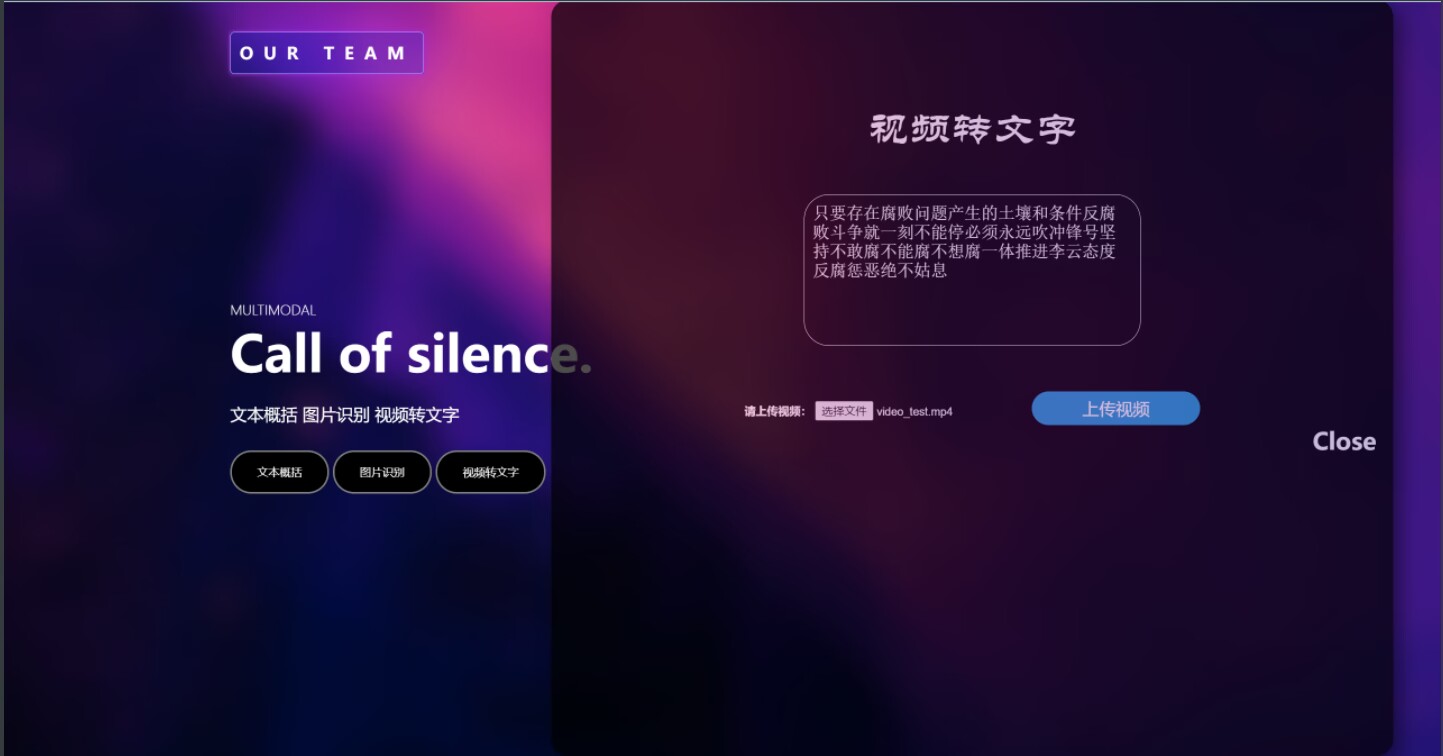
④视频概括功能展示
个人分工
后端接口的编写以及风格迁移代码的实现
后端代码:
from 文本概括 import xinghuomodel
from 图片概括 import imageunderstand
from flask import Flask, request, jsonify, make_response
import json
from flask_cors import CORS
import random
import os
from datetime import datetime
from 视频提取音频 import videotoaudio
from 音频转文字 import audiototext
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
CORS(app)
@app.after_request
def cors(environ):
environ.headers['Access-Control-Allow-Origin'] = '*'
environ.headers['Access-Control-Allow-Methods'] = '*'
environ.headers['Access-Control-Allow-Headers'] = 'x-requested-with,content-type'
return environ
@app.route("/text",methods=["POST","OPTIONS","GET"])
def text():
if request.method == "POST":
data = json.loads(request.data)
text = data['data']
answer = xinghuomodel(text+"\n请你总结上面这段话的内容")
return jsonify({'answer': answer})
if request.method == "GET":
return jsonify({"success":200,"msg":"1"})
if request.method == "OPTIONS":
return jsonify({'data': 'success'})
@app.route("/photo",methods=["POST","OPTIONS","GET"])
def photo():
if request.method == "POST":
print(request.headers)
# print(request.data["file"])
# print(list(request.files.values()))
f = request.files.get("file")
print(f)
filename = f.filename
# filename = secure_filename(f.filename)
print(filename)
randomnum = random.randint(0, 100)
filename = datetime.now().strftime("%Y%m%d%H%M%S") + "_" + str(randomnum) + "." + filename.rsplit('.', 1)[1]
filepath = basedir + "/static/file/" + filename
f.save(filepath)
a = imageunderstand(filepath)
return jsonify({'data': a})
@app.route("/audio",methods=["POST","OPTIONS","GET"])
def audio():
if request.method == "POST":
f = request.files.get("file")
print(f)
filename = f.filename
randomnum = random.randint(0, 100)
head = datetime.now().strftime("%Y%m%d%H%M%S") + "_" + str(randomnum) + "."
filename = head + filename.rsplit('.', 1)[1]
filepath = basedir + "/static/file/" + filename
filepath2 = basedir+"/static/file/" + head + "wav"
f.save(filepath)
videotoaudio(filepath,filepath2)
result = audiototext(filepath2)
return result
if __name__ == "__main__":
app.run("0.0.0.0")
风格迁移代码:
import torch
import torchvision.utils
from PIL import Image
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms, models
# 设置图片大小
img_size = 512
# 设置训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Normalize(mean=[0.500, 0.500, 0.500],
std=[0.229, 0.224, 0.225])
# 加载图片
def load_img(img_path):
img = Image.open(img_path).convert(
'RGB')
img = img.resize((img_size, img_size)) # 对图片进行裁剪,为512x512
img = transforms.ToTensor()(img)
img = transform(img).unsqueeze(0)
return img
# 显示图片
def show_img(tensor):
image = tensor.cpu().clone()
image = image.squeeze(0)
return image
# 构建神经网络
class VGGNet(nn.Module):
def __init__(self):
super(VGGNet, self).__init__()
self.select = ['0', '5', '10', '19', '28']
self.vgg = models.vgg19(pretrained=True).features
def forward(self, x):
features = []
for name, layer in self.vgg._modules.items():
x = layer(x)
if name in self.select:
features.append(x)
return features
# for name, layer in models.vgg19(pretrained=True).features._modules.items():
# print(name)
# print(layer)
# 加载图片
content_img = load_img("C:/Users/86188/Desktop/pythonProject/stylemoving/image/dog.jpg").to(device)
style_img = load_img("C:/Users/86188/Desktop/pythonProject/stylemoving/image/fangao.jpg").to(device)
target = content_img.clone().requires_grad_(True)
optimizer = torch.optim.Adam([target], lr=0.003) # 选择优化器
vgg = VGGNet().to(device).eval()
total_step = 3000 # 训练次数
style_weight = 100
# 设置tensorboard,用于可视化
writer = SummaryWriter("log")
content_features = [x.detach() for x in vgg(content_img)]
style_features = [x.detach() for x in vgg(style_img)]
# 开始训练
for step in range(total_step):
target_features = vgg(target)
style_loss = 0
content_loss = 0
for f1, f2, f3 in zip(target_features, content_features, style_features):
content_loss = torch.mean((f1 - f2) ** 2) + content_loss
_, c, h, w = f1.size()
f1 = f1.view(c, h * w)
f3 = f3.view(c, h * w)
# 计算gram matrix
f1 = torch.mm(f1, f1.t())
f3 = torch.mm(f3, f3.t())
style_loss = torch.mean((f1 - f3) ** 2) / (c * h * w) + style_loss
loss = content_loss + style_weight * style_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
writer.add_scalar("loss", loss, step)
denorm = transforms.Normalize((-2.12, -2.04, -1.80), (4.37, 4.46, 4.44))
img = target.clone().squeeze()
img = denorm(img).clamp_(0, 1)
img = show_img(img)
print("Step [{}/{}], Content Loss: {:.4f}, Style Loss: {:.4f}".format(step, total_step, content_loss.item(), style_loss.item()))
if step%100==0:
writer.add_image("target", img, global_step=step)
if step==total_step-1:
torch.save(vgg,"C:/Users/86188/Desktop/pythonProject/stylemoving/model/5.pth")#保存模型
torchvision.utils.save_image(img,"C:/Users/86188/Desktop/pythonProject/stylemoving/model/5.jpg")#风格迁移之后的图片
writer.close()
训练之后的模型保存下来之后,再次尝试融合图片但是出来的是原图,问题目前还是没有解决,因此进行一次风格迁移就需要从头开始训练,一次大概半小时,时间太久,所以这部分的功能暂时阉割