先上一段代码 :
func main() {
content := "长沙boy"
content1 := "boy"
fmt.Printf("content: %d\n", unsafe.Sizeof(content))
fmt.Printf("content1: %d\n", unsafe.Sizeof(content1))
}
打印的结果:
content: 16
content1: 16
问题1、从这里能看出,这个16基本字符串的内容长短没关系,那是和什么相关?
还是上面那个例子,很多人意识到打印长度,应该换成 len()方法
fmt.Printf("content: %d\n", len(content))
fmt.Printf("content1: %d\n", len(content1))
打印结果:
content: 9
content1: 3
问题2,为什么这个字符长度会是9和3 ?
第一个问题,需要查看下string的底层实现。
string 在runtime中的定义
在runtime的string.go中有定义:
type stringStruct struct {
str unsafe.Pointer
len int
}
看到这里,第一个问题有答案了,unsafe.Sizeof` 打印string 为什么是16,
因为打印的是结构体的大小,所以不管什么内容的string,大小都为16,
unsafe.Pointer 和 int 各占8个 ,当然这个和操作系统的位数有关。
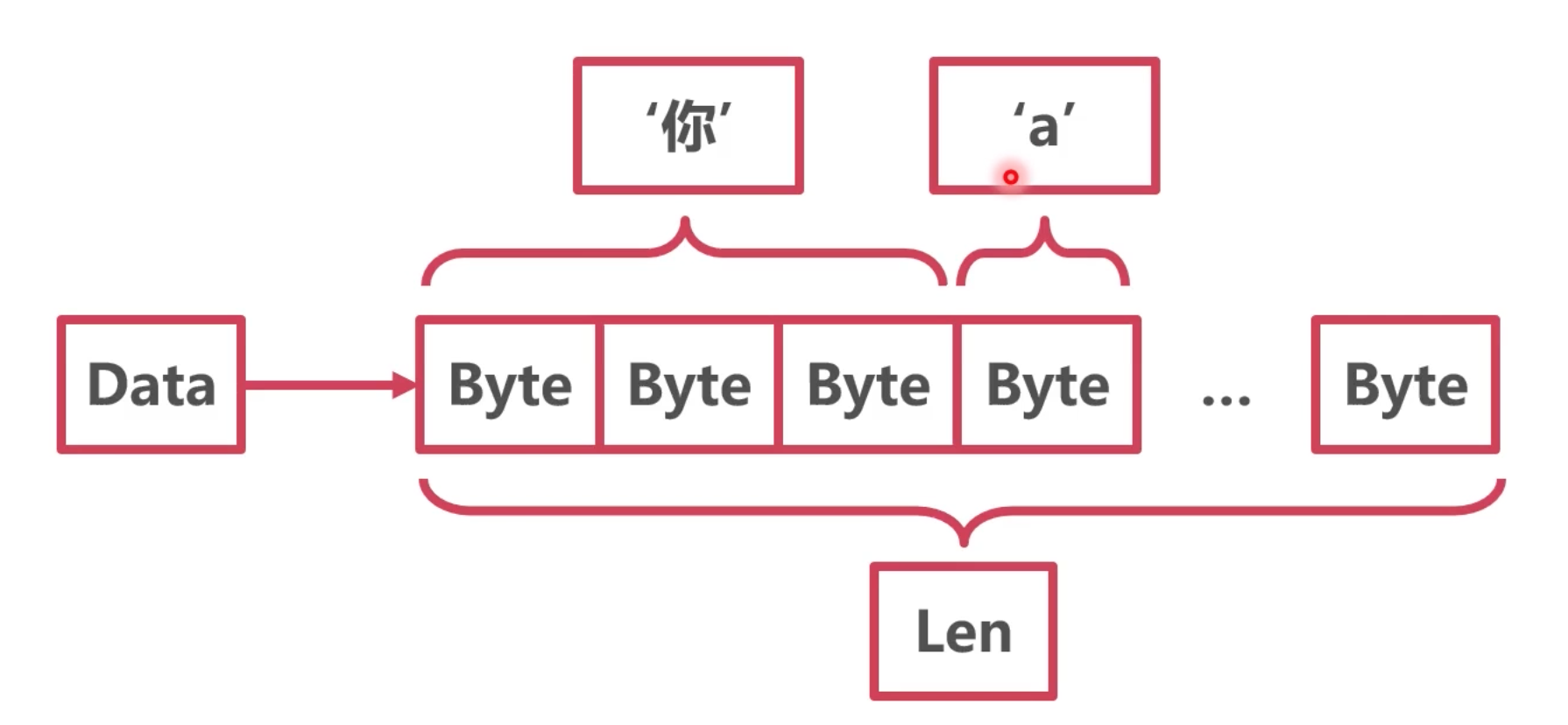
小结:
字符串本质是个结构体
str指针指向底层Byte数组
Len表示Byte数组的长度
string的字符串长度
能看出调用 len()打印的长度,就是 stringStruct的len的长度。
验证下:
content := "长沙boy"
// util.StringHeader 以前是放在 reflect反射包中
c := (*util.StringHeader)(unsafe.Pointer(&content))
fmt.Printf("c: %d\n", c.Len)
打印:c: 9
那为什么是9? 不是3或者5?
要引入编码问题:
Unicode
一种统一的字符集
囊括了159种文字的144679个字符
14万个字符至少需要3个字节表示
英文字母均排在前128个
因为,英文字符也会占3个字节,会超出浪费。
UTF-8变长编码
Unicode的一种变长格式
128个US-ASCIl字符只需一个字节编码
西方常用字符需要两个字节
其他宇符需要了个字节,极少需要4个字节
go就是采用这个编码,这样就能解释了,为什么 长沙boy 是9,中文3个,英文每个字母1个。
string的读取
content := "长沙boy"
for i := 0; i < len(content); i++ {
fmt.Println(content[i])
}
打印:
233
149
191
230
178
153
98
111
121
显然不对,这样字节值。
应该采用这个方式:
content := "长沙boy"
for _, c := range content {
fmt.Printf("%c\n", c)
}
go底层是采用了 runtime下的 utf-8.go中定义的两个方法:
// encoderune writes into p (which must be large enough) the UTF-8 encoding of the rune.
// It returns the number of bytes written.
func encoderune(p []byte, r rune) int {}
// If the string appears to be incomplete or decoding problems
// are encountered (runeerror, k + 1) is returned to ensure
// progress when decoderune is used to iterate over a string.
func decoderune(s string, k int) (r rune, pos int) {}
能看到值转为了 rune 类型后再进行的。
小结:
对字符串使用len方法得到的是字节数不是字符数
对宇符串直接使用下标访问,得到的是字节
宇符串被range遍历时,被解码成rune类型的字符
UTF-8 编码解码算法位于 runtime/utf8.go
宇符串的切分
转为rune数组
切片
转为 string
s=string ([]rune(s)[:3) 取前3个
rune类型是Go语言中的一个基本类型,其实就是一个int32的别名,主要用于表示一个字符类型大于一个字节小于等于4个字节的情况下,特别是中文字符。