本文分享自华为云社区 《bert模型昇腾迁移部署案例》,作者:AI印象。
镜像构建
1. 基础镜像(由工具链小组统一给出D310P的基础镜像)
From xxx
2. 安装mindspore 2.1.0,假定whl包和tar包已经下载到本地,下载地址:https://www.mindspore.cn/lite/docs/zh-CN/r2.0/use/downloads.html
ADD . /usr/local/ RUN cd /usr/local && \ pip install mindspore_lite-2.1.0-cp37-cp37m-linux_x86_64.whl && \ tar -zxvf mindspore-lite-2.1.0-linux-x64.tar.gz && \ ln -s /usr/local/mindspore-lite-2.1.0-linux-x64 /usr/local/mindspore-lite
3. 安装cann包6.3.RC2版本,假定也下载到本地,下载地址:https://support.huawei.com/enterprise/zh/ascend-computing/cann-pid-251168373/software
RUN ./Ascend-cann-toolkit_6.3.RC2_linux-x86_64.run --install
4. 安装pip依赖
RUN pip install --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple onnx onnxruntime flask gunicorn
5. 安装昇腾迁移工具tailor,假定也下载到本地
RUN pip install tailor-0.2.1-py3-none-any.whl
6. 生成镜像
docker build -t bert_poc_test:v1.0.0 .
容器部署
宿主机用户目录/home/xxx/下存放着若干文件:
/home/xxx --- model --- model.onnx --- model.mindir --- infer --- run.sh --- infer_server.py --- mslite_model.py
1. 运行容器
docker run -itd --privileged -p 50033:22 -p 8443:8443 -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /home/xxx:/home/xxx --name bert_d310p bert_poc_test:v1.0.0 /bin/bash
参数说明:
-itd 设置交互守护运行容器,可以退出容器
-- privileged 设置特权容器,可以查看所有npu卡信息
-p 主机端口和容器端口映射
2. 进入容器
docker exec -it bert_d310p bash
进入容器内部,执行npu-smi info命令查看npu卡使用情况
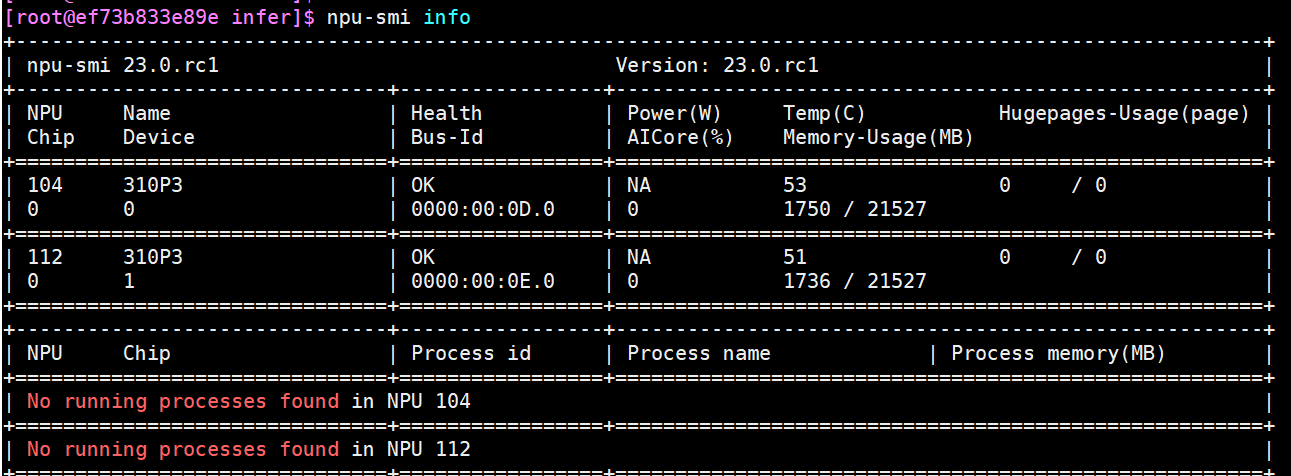
3. 使用tailor工具转换并优化模型文件
tailor --model_path=/home/xxx/model/ model.onnx --input_shape=input_ids:1,70 --aoe=True
执行成功后在/home/xxx/model/ output/model_fp16_aoe_xxx/convert目录下会生成转换成功的mindir文件,然后将这个文件拷贝到/home/xxx/model下
4. 修改infer_server.py指定模型文件路径, 这里给出例子
import os from flask import Flask from mslite_model import MsliteModel import numpy as np app = Flask(__name__) os.environ['DEVICE_ID'] = "0" model_path = "/home/xxx/model/model.mindir" input_data = np.random.randn(1,70).astype(np.int32) model = MsliteModel(model_path) @app.route('/', methods=['POST']) def infer(): print("receive request") res = model([input_data]) return str(res) if __name__ == '__main__': app.run(debug=False, host="0.0.0.0", port=8443)
5. 修改run.sh文件指定进程个数,这里给出例子
#! /bin/bash source /usr/local/Ascend/ascend-toolkit/set_env.sh host_ip=$(hostname -i) service_port=8443 listen_address="${host_ip}:${service_port}" worker_num=60 worker_threads=5 worker_timeout=120 gunicorn -w ${worker_num} --threads ${worker_threads} -t ${worker_timeout} -b ${listen_address} infer_server:app
6. 启动服务
sh run.sh
7. 外部调用请求
使用curl:
curl -kv -X POST http://{宿主机ip}:8443/
性能评估
1. 安装java
下载jdk包
拷贝到/opt/jdk
解压
然后设置环境变量:
export JAVA_HOME=/opt/jdk/jdk1.8.0_252
export PATH=${JAVA_HOME}/bin:${PATH}
2. 安装jemter
下载jmeter包
拷贝到/opt/jmeter
解压
然后设置环境变量
export PATH=/opt/jmeter/apache-jmeter-5.4.1/bin:${PATH}
也可以持久化到 /etc/profile
source /etc/profile
3. 测试qps
服务器端gunicorn使用60个worker,显存占用接近80%
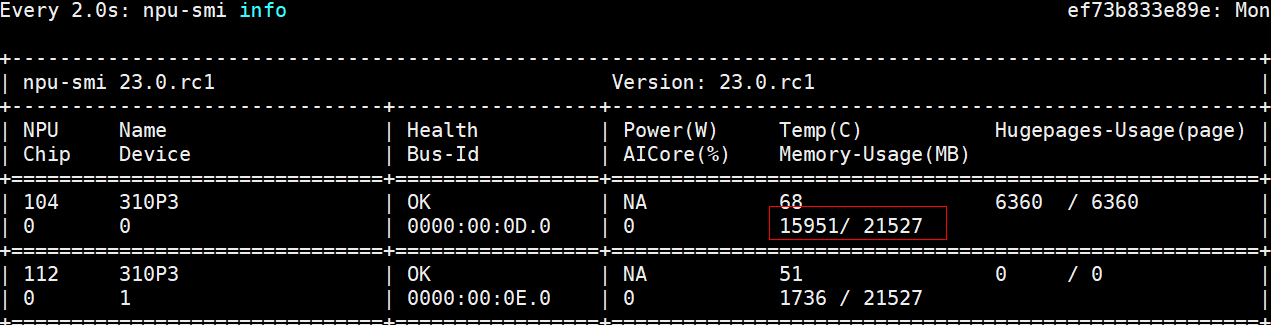
客户端jmeter使用一个进程压测 iops为248 平均时延为4ms
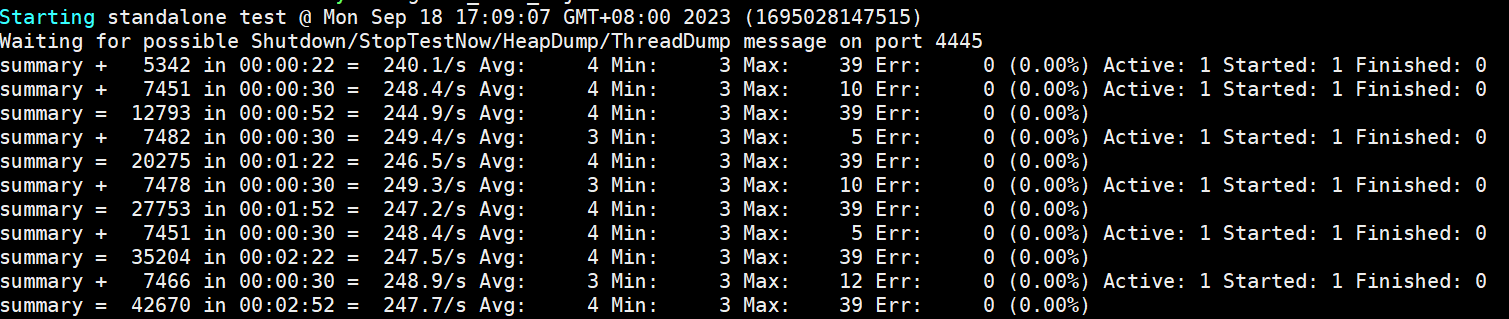
客户端使用2个进程, npu使用率到71%,qps到356 平均时延5ms
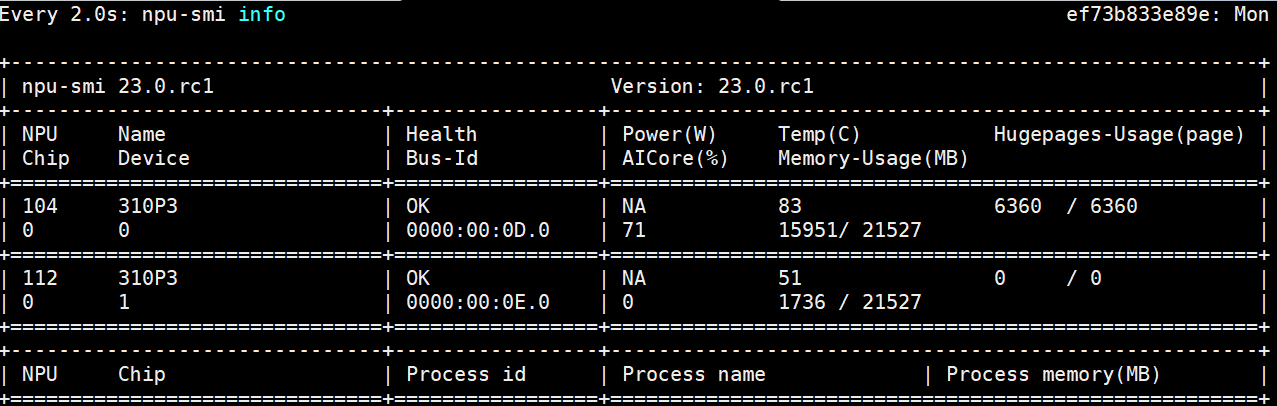

客户端使用4个进程,npu使用率已经到了97%,qps到429 平均时延9ms
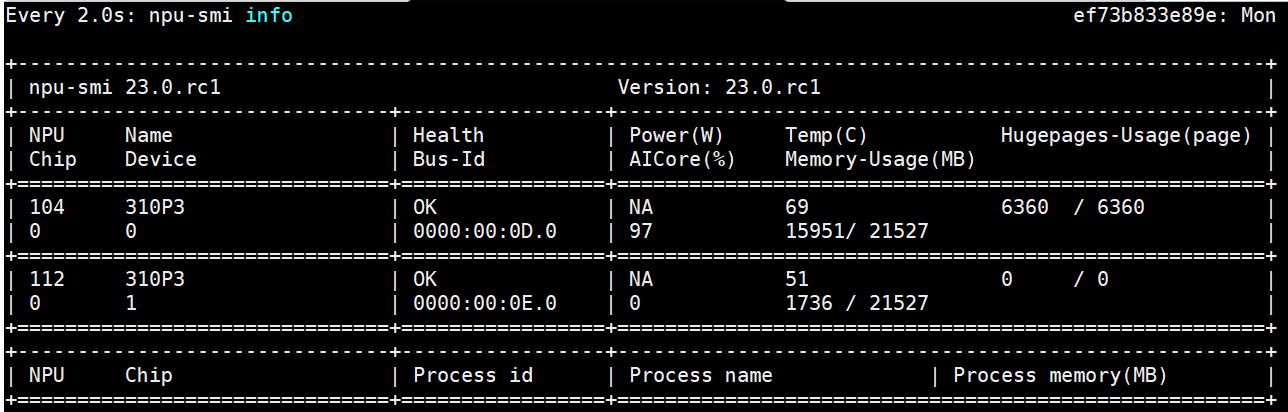

进一步加大进程个数到8个,性能开始下降:

综上,bert poc模型在D310p 单卡qps可以达到429。