文件系统的一个目标是组织和存储数据。文件系统通常支持在用户和应用之间共享数据,以及持久化它们以让重启后数据仍然可用。
xv6文件系统提供Unix风格的文件、目录以及路径名(查看第一章)并且将它的数据存储在virtio磁盘上以持久化(查看第四章)。文件系统面临多种挑战:
- 文件系统需要磁盘数据结构来表示命名文件夹和文件的树;记录持有每一个文件内容的块的标识符;并且记录磁盘上的哪个区域是空闲的。
- 文件系统必须支持崩溃恢复。就是如果崩溃(比如电源故障)发生,文件系统必须在重启之后仍然正常工作。这里的风险是崩溃可能打断一个更新序列,留下不一致的磁盘数据结构(比如一个块既被一个文件使用又被标记为空闲)。
- 不同的进程可能在同一时间操作文件系统,所以文件系统代码必须协作以维护不变性。
- 访问磁盘比访问内存慢几个数量级,所以文件系统必须在内存中维护常用块的缓存。
本章的余下部分解释xv6如何解决这些困难。
8.1. 概览
如图8.1所示,xv6文件系统实现由很多个层构成。磁盘层在virtio硬盘驱动之上读取和写入块;buffer cache层缓存磁盘块以及维护它们的同步访问,确保在任一特定块中,在同一时间只有一个内核进程可以修改存储在其中的数据;日志层允许更高的层次将多个块的更新封装到一个事务中,以确保块在面临崩溃时被原子更新(所有块要么都被更新,要么都没被更新);inode层提供了独立文件,每一个文件表示为一个具有唯一i-number的inode以及一些持有着文件数据的块;文件夹层将每一个文件夹实现为一个特殊类型的inode,它的内容是一个目录条目序列,其中的每一个包含一个文件名和一个i-number;路径名层提供路径名的层次结构,如/usr/rtm/xv6/fs.c,并且通过一个递归查找来解析它们;文件描述符层使用文件接口抽象了许多Unix资源(比如管道、设备、文件等),简化了应用程序员的生活。
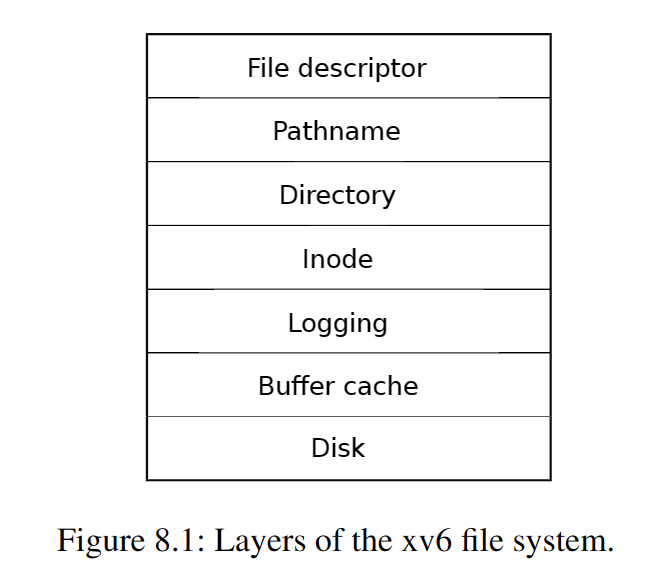
文件系统必须有一个将inode以及内容块存在磁盘的哪个部分的计划,为了做到这一点,xv6将磁盘分成多个区域,如图8.2。文件系统不使用块0(它持有着boot区),块1被称作superblock,它包含了文件系统的元数据(以块为单位的文件系统大小,数据块数量,inode数量以及日志块数量等),从块2开始的块持有日志,在日志块后面是inode,每一个块中有多个inode,再之后是跟踪哪一个数据块正在被使用的位图块,剩下的块就是数据块,每一个数据块要么在位图块中被标记为空闲,要么就持有着文件或目录的内容。超级块被一个独立的程序填充,我们称它mkfs,它构建了一个初始文件系统。
本章的余下部分讨论每一层,我们从buffer cache开始。注意在较低层次上的精心抽象可以简化高层的设计。
8.2. buffer cache层
buffer cache层有两个任务:(1) 同步到磁盘块的访问以确保一个块只有一个在内存中的拷贝,并且在同一时间只有一个内核进程可以使用这个拷贝;(2) 缓存常用块以让它们无需每次从慢速磁盘中重新访问。代码在bio.c中。
buffer cache暴露的主要接口包括bread和bwrite;前一个获取buf,这个buf包含可以在内存中被读或修改的一个块的拷贝,后面一个将一个已经修改的buffer写入到磁盘上合适的块中。一个内核线程必须在处理完后调用brelse释放buffer。buffer cache为每一个buffer使用一个sleeplock来确保在同一时间只有一个线程可以使用每个buffer(因此也可以说是每一个磁盘块);bread返回一个已锁定的buffer,brelse释放锁。
我们回到buffer cache,buffer cache具有固定数量的buffer来持有磁盘块,这意味着如果文件系统请求了一个目前不在缓存中的块,buffer cache必须清理当前持有其它块的buffer,buffer cache回收最近最少使用的buffer来保存新块,它假设最近最少使用的buffer是最不可能稍后被用到的。
8.3. 代码:buffer cache
buffer cache是一个buffer的双向链表。被main(kernel/main.c:27)调用的binit使用NBUF个buffer初始化链表,它们被保存在静态数组buf中(kernel/bio.c:43-52)。所有到buffer cache的其它访问都需要通过bcache.head引用到链表,而不是buf数组。
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
一个buffer有两个与其相关的状态属性,vaild属性表示buffer包含一个块的拷贝;disk属性表示buffer内容已经被传递到磁盘中,我们现在可以修改buffer了(比如将磁盘中的数据写入到它的data中)。
// kernel/buf.h
struct buf {
int valid; // 具有从磁盘中读取的数据?
int disk; // 磁盘是否“拥有”这个buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU缓存列表
struct buf *next;
uchar data[BSIZE];
};
bread(kernel/bio.c:93)调用bget从一个给定sector获取buffer(kernel/bio.c:97)。如果buffer需要从磁盘中读取,bread在返回之前调用virtio_disk_rw来做这件事。
// 返回具有指定块内容的一个已经加锁的buf
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
bget(kernel/bio.c:59)使用给定设备和sector扫描buffer列表(kernel/bio.c:65-73)。如果有这样一个buffer,bget获取该buffer的sleeplock,随后bget返回已锁定的buffer。
如果没有一个给定sector的已缓存buffer,bget必须创建一个buffer,有可能是重用持有着不同sector的buffer。它第二次扫描一个buffer列表,查找一个没有被使用的buffer(b->refcnt = 0),任何这样的buffer都可以被使用。bget编辑buffer元数据来记录新设备和sector号,获取它的sleeplock。注意b->valid = 0这个赋值确保了bread会从磁盘读取数据,而不是错误的使用buffer之前的内容。
// 遍历buffer cache寻找在dev设备上的block
// 如果没找到,分配一个buffer
// 不论在哪种情况下,返回锁定的buffer
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock); // 锁整个列表
// block已经在缓存中了吗?
// 遍历buffer列表,找出是否已经有该block的缓存
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock); // 加锁
return b;
}
}
// 尚未缓存
// 重用最近最少使用的buffer
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0; // 将buffer.valid设置为0
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock); // 加锁
return b;
}
}
panic("bget: no buffers");
}
译者:注意,
sector一般代表磁盘硬件上的一个术语,意为“扇区”,它通常是512字节,代表硬件层面可对磁盘进行原子读写的最小单位,而block通常是操作系统层面对磁盘划分的最小读写单位,在xv6中是1024字节。但是,这里的sector和block术语有些混淆,就统一当作block处理吧。还有,貌似这个buffer链表本身就是一个LRU链表,最近使用的在前面,没使用的在后面。
比较重要的一点是,对于一个磁盘sector,最多只有一个缓存的buffer,并且因为文件系统在buffer上使用锁来同步,这保证了读取者能看到写入。bget能通过持有bache.lock从第一次检查是否块已经被缓存的循环到第二次块已经被缓存(通过设置dev、blockno以及refcnt)的循环定义过程中持续的保证这个不变式。这导致了检查块是否存在并且(如果不存在)指定一个buffer来持有块的这一操作是原子的。
对于bget来说,从bcache.lock的临界区外获取buffer的sleeplock是安全的,因为非零的b->refcnt阻止了buffer被不同的磁盘块重用。sleeplock保护的是块缓冲内容的读写,而bcache.lock保护的是哪一个块被缓存的信息。
如果所有的buffer都忙,这代表太多的进程同时执行文件系统调用;bget将会panic。一个更加优雅的响应可能是睡眠直到buffer变空闲,虽然这可能带来死锁风险。
一旦bread已经读取了磁盘(如果需要的话)并且返回buffer到它的调用者,caller就会吃的使用buffer,它可以读写数据字节。如果caller修改了buffer,它必须在释放该buffer前调用bwrite将修改的数据写入到磁盘。bwrite(kernel/bio.c:107)调用virtio_disk_rw与磁盘硬件交流。
// 将b的数据写入到磁盘,必须被锁定
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
当调用者用完一个buffer,它必须调用brelse来释放它(brelse是b-release的一个简写,它很神秘,但是值得学习:它起源于Unix并在BSD Linux和Solaris中也有被使用)。brelse(kernel/bio.c:117)释放sleeplock并且将buffer移动到链表最前端(kernel/bio.c:128-133)。移动buffer导致列表被通过buffer的最近使用情况排序:列表中的第一个buffer是最近最多使用的,最后一个是最近最少使用的。bget的两个循环利用了这个优势:扫描一个一致buffer在最坏情况下必须处理整个列表,但是先检查最近使用的缓冲区(从bcache.head以及随后的next指针开始)将在具有良好的引用局部性时减少扫描时间。选择要重用的缓冲区时,通过反向扫描(跟随prev指针)来选择最近最少使用的buffer。
8.4. 日志层
在文件系统设计中,一个最有趣的难题就是崩溃恢复。由于许多文件操作会卷入多次写磁盘,在一个部分写入后的崩溃可能在让磁盘上的文件系统进入不一致的状态,难题就这样产生了。举个例子,假设崩溃在文件截断过程中发生(设置文件长度为0并且释放它的内容块),依赖于磁盘写入的顺序,此次崩溃可能留下一个inode,这个inode具有到某个内容块的引用,但这个内容块已经被标记为空闲了;或者,可能留下一个已分配但没有被inode引用的内容块。
后一个相对来说没什么杀伤力,但是引用到一个空闲块的inode会在重启后导致严重问题。在重启后,内核可能将这个块分配给其它文件,现在,我们有两个不同的文件潜在的指向了相同的块。如果xv6支持多用户,这个情况将会是一个安全问题,因为老文件的拥有者可以读写被其它用户拥有的新文件的块。
xv6通过一个简单形式的日志来解决在文件系统操作期间崩溃的问题。一个xv6的系统调用不直接写磁盘上的文件系统数据结构,而是对于所有它想做的磁盘写,都在磁盘上的一个日志中放置一个描述,一旦系统调用记录了它所有的写入,它需要写入一个特殊的commit记录到磁盘,代表日志包含了一个完整的操作。此时,系统调用复制这些写入到磁盘上的文件系统数据结构中,在这些写入完成后,系统调用擦除磁盘上的日志。
如果系统崩溃并重启,在运行任何进程前,文件系统的代码像下面所述的一样从崩溃中恢复。如果日志被标记为包含一个完整的操作,那么恢复代码将写入复制到磁盘上的文件系统中它们本应所属的位置,反之,恢复代码忽略日志,擦除日志,完成操作。
为什么xv6的日志解决了文件系统操作过程中的崩溃难题呢?如果崩溃在操作提交前发生,那么磁盘上的日志没有被标记为完成,恢复代码将会忽略它,磁盘状态将会如操作从未开始过一样,如果崩溃在操作提交后发生,那么恢复代码将会重放所有操作中的写入,如果操作已经将开始将它们(中的部分)写入到磁盘数据结构中,也许会重复写入。在每种情况中,日志都让操作相对于崩溃是原子的:在恢复后,要么所有操作的写入都出现在磁盘上,要么一个写入都没出现。
8.5. 日志设计
日志在一个固定的位置,在超级块中被定义。它包含一个头块,后面跟着一个被更新的块的拷贝(日志块)的序列。头块中包含一个sector号数组,每一个对应一个日志块,头块中还包含日志块的数量——count。磁盘中的头块里的count,要么是0,代表日志中没有事务;要么是非0,代表日志中包含一个完整的已提交事务,此时count代表日志块的数量。xv6在日志提交时写入头块,并非在提交前写入,然后,它会在复制日志块到文件系统之后将count设置为0,因此在一个事务中途发生的崩溃将导致日志头块中的count为0,在提交后的崩溃将导致非0的count。
每一个系统调用代码都需要指明必须在崩溃中保持原子性的写入序列的开始和结束。为了允许不同进程的文件系统操作的并发执行,日志系统可以累计多个系统调用的写入到一个事务中,因此,一个单独的提交可能包含多个完整系统调用中的写入,为了避免将系统调用跨事务分割,日志系统仅仅在没有正在执行中的文件系统系统调用时提交。
一起提交多个事务的思路被称为组提交。组提交减少了磁盘操作的次数,因为它将一个提交的固定消耗分摊在多个操作上。组提交也给了磁盘系统在同一时间更多的并发写入,也许可以允许磁盘在一次磁盘旋转中将它们全部写入。xv6的virtio驱动不支持这种批处理,但是xv6的文件系统设计允许。
xv6拿出固定数量的磁盘空间来持有日志,一个事务中的系统调用写入的块总数必须适配这个空间。这带来两个结果,一是没有单独的系统调用能被允许写入超过日志空间的独立块。对于大部分系统调用来说这不是个问题,但是有两个系统调用可能潜在的写入很多块:write和unlink。一个大文件写入可能会写入很多数据块、位图块以及inode块;unlink一个大型文件可能写入很多位图块和一个inode块。xv6的write系统调用将大型写入分割成多个更小的,可以适配日志的写入,unlink并不受影响,因为在实际的xv6文件系统中只使用了一个位图块。受限日志空间的第二个问题是,日志系统不能允许一个系统调用开始,除非系统调用的写入可以适配日志中剩余的空间。
8.6. 代码:日志
一个典型的系统调用中的日志用例应该像下面这样:
begin_op(); // 开启事务
...
bp = bread(...); // 读块到buffer cache
bp->data[...] = ...; // 在buffer cache上操作
log_write(bp); // 在内存中写入日志
...
end_op(); // 结束事务(提交)
begin_op(kernel/log.c:126)会等待,直到当前日志系统没有在提交,并且直到有足够的未被占用的日志空间可以持有本次调用的写入。log.outstanding记录了已经占用了日志空间的系统调用数量;总的占用空间是log.outstanding * MAXOPBLOCKS。增加log.outstanding既占用了空间,也阻止了在当前系统调用期间发生提交。代码保守地架设了每一个系统调用也许会写入最多MAXOPBLOCKS个独立的块。
// 在每一个文件系统调用的开始处被调用
void
begin_op(void)
{
acquire(&log.lock); // 对内存中的日志加锁,避免竞态条件
while(1){
if(log.committing){ // 如果当前有日志正在提交,睡眠
// 正在提交的过程包括
// 1. 将buffer cache中的日志块写入磁盘日志结构
// 2. 向磁盘中的日志头写入提交
// 3. 安装日志(实际将日志中的内容写入到磁盘中的文件系统数据结构)
// 4. 清除日志(写日志头中的count = 0)
sleep(&log, &log.lock);
} else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS > LOGSIZE){
// 这个操作可能耗尽日志空间,等待当前日志中的事务提交,空出日志空间
sleep(&log, &log.lock);
} else {
// begin_op成功 outstanding += 1
log.outstanding += 1;
release(&log.lock);
break;
}
}
}
译者:有必要先介绍一下xv6是如何在内存中保存磁盘日志的缓存的,要不看起来会很懵逼。
xv6会在内存中缓存磁盘中用于日志的块中的日志头块,
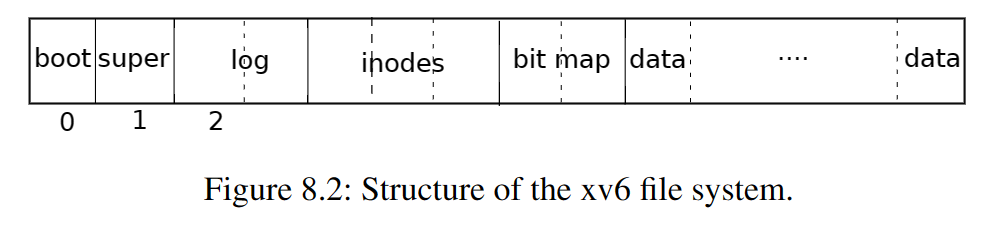
log.lh就是这个日志头块在内存中的缓存。其中的n代表之前咱们说的头块中的count,即目前日志中有多少个独立块,而其中的block是一个int数组,它就是头块中的sector号数组序列。对于任意一个i(i>=0 && i < log.lh.n),第i个日志块保存了磁盘块号为log.lh.block[i]的磁盘块的写入。为了性能起见,xv6不会在每次写入时就直接将写入落到磁盘上的日志块中,对于日志头块,它操作
log.lh,对于其它日志块,它在buffer cache中保存。只有在提交时(end_op会引发提交),它才会实际的将这些日志写入磁盘,后面我们会看到xv6是如何在这样的写入方式下提供日志的原子写入的。
通过
write_log操作,buffer cache中的所有日志块会被按照log.lh.block中的顺序写入到磁盘上的实际日志块中,write_head操作可以把log.lh中的状态写入到实际的日志头块中。读者可能听得云里雾里,但你只需要了解xv6中的日志块写入会在内存中的buffer cache和log.lh上缓存,直到日志提交时才会实际写入磁盘即可。
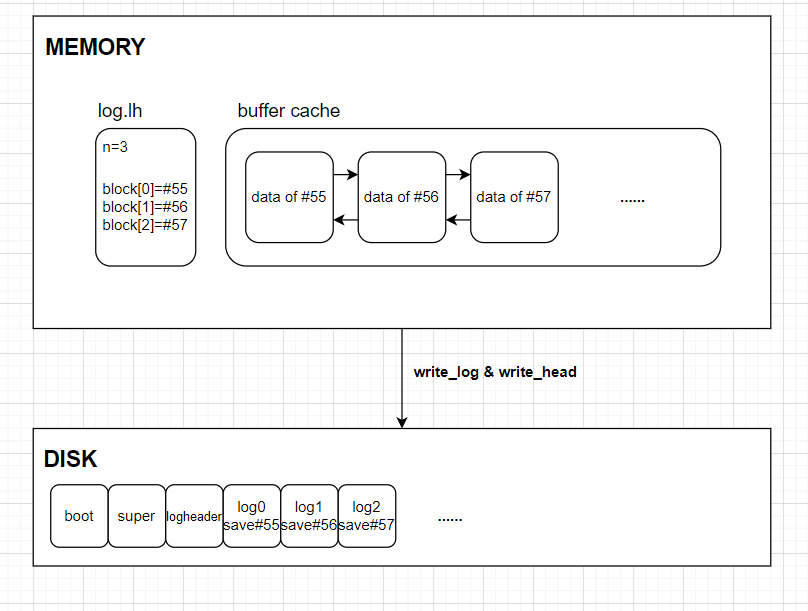
log_write(kernel/log.c:214)扮演了bwrite的一个代理。它在内存中记录了块的sector号,为它在磁盘中的日志上保留了一个槽,并且在块缓存中固定这个buffer以阻止块缓存过期。直到提交,块都必须呆在缓存中:在提交之前,缓存副本是块修改的唯一记录;直到提交后才能将它写入到它磁盘上的位置,并且修改必须对同一事务中的其它读取可见。log_write能够注意到一个块在单一事务中被写入了多次,它将为这个块分配log中相同的槽。这个优化被称作合并(absorption)。举个例子,在一个事务中,包含多个文件的inode的块会被写入多次,通过合并多次磁盘写入到一个,文件系统可以节省日志空间,并且由于只需要将磁盘块的一个副本写入到磁盘中,可以达到更好的性能。
// 调用者已经修改了b->data,并且已经用完了buffer
// 记录块号,并通过增加refcnt来将该块固定在缓存中
// commit()/write_log()将会做磁盘写
//
// log_write() 替换 bwrite();一个常见的用例如下:
// bp = bread(...)
// modify bp->data[]
// log_write(bp)
// brelse(bp)
void
log_write(struct buf *b)
{
int i;
if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)
panic("too big a transaction");
if (log.outstanding < 1)
panic("log_write outside of trans");
acquire(&log.lock);
// 如果目前已经为这个块分配过日志槽位,那么直接复用
for (i = 0; i < log.lh.n; i++) {
if (log.lh.block[i] == b->blockno) // log absorbtion
break;
}
// 否则,分配一个新的槽位
log.lh.block[i] = b->blockno;
// 如果刚刚添加了一个新块到log中
if (i == log.lh.n) {
// 将该块固定在buffer中
bpin(b);
// 递增log.lh.n
log.lh.n++;
}
release(&log.lock);
}
end_op(kernel/log.c:146)首先递减了未完成的系统调用数量,如果这个数量现在是0,那么它通过调用commit()提交当前事务。这个过程有四个阶段,write_log()(kernel/log.c:178)将事务中每一个在buffer cache里的已修改的块拷贝到它在磁盘日志上的槽位中,write_head()(kernel/log.c:102)写入header块到磁盘中:这就是提交点,在这次写入后的崩溃将导致恢复程序重放日志中的事务写入,install_trans(kernel/log.c:69)从日志中读取每一个块,并将它们写入它们在文件系统中对应的位置,最后,end_op使用0大小写入日志头(擦除日志头),这会在下一个事务开始写入日志块前发生,所以崩溃不会导致恢复代码使用一个事务的头以及后续事务的日志块。
// 在每个文件系统调用结尾被调用
// 如果目前是最后一个未完成的操作,提交
void
end_op(void)
{
int do_commit = 0;
acquire(&log.lock);
log.outstanding -= 1;
if(log.committing)
panic("log.committing");
if(log.outstanding == 0){
// 如果是当前最后一个未完成事务,打开committing状态
do_commit = 1;
log.committing = 1;
} else {
// begin_op() 可能在等待日志空间
// 递减log.outstanding也递减了被占用的空间数量
wakeup(&log);
}
release(&log.lock);
if(do_commit){
commit();
acquire(&log.lock);
log.committing = 0;
wakeup(&log);
release(&log.lock);
}
}
static void
commit()
{
if (log.lh.n > 0) {
write_log(); // 将缓存写入到日志中
write_head(); // 将头写入到磁盘——实际提交
install_trans(); // 将写入装载到对应位置
log.lh.n = 0;
write_head(); // 擦除事务
}
}
recover_from_log(kernel/log.c:116)被initlog(kernel/log.c:55)调用,而后者又被fsinit(kernel/fs.c:42)在启动时,第一个用户进程运行前(kernel/proc.c:539)调用。它读取日志头,如果头表明日志中包含一个已提交的事务,它就模仿end_op的动作。
static void
recover_from_log(void)
{
read_head();
install_trans(); // if committed, copy from log to disk
log.lh.n = 0;
write_head(); // clear the log
}
日志的一个使用示例在就是filewrite(kernel/file.c:135),事务看起来像下面这样:
begin_op();
ilock(f->ip);
r = writei(f->ip, ...);
iunlock(f->ip);
end_op();
这段代码被包裹在一段循环中,这段循环将大写入分割成一次只有少量sector的独立事务,以避免日志溢出。调用writei写入本次事务中的一些块:文件inode、一个或多个bitmap块、以及一些数据块。