1 数据介绍

首先看看这个数据,是从2005年到2008年的每一个小时的电力消耗值。
2 实现思路
- 1.加载数据集、预处理
- 2.特征工程
- 3.构建模型
- 4.模型编译、训练、验证
- 5.模型测试
- 6.结果可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score
import tensorflow as tf
from tensorflow.keras import Sequential, layers, utils
import warnings
warnings.filterwarnings('ignore')
2.1 加载数据集、预处理
dataset = pd.read_csv('DOM_hourly.csv')
# 显示shape
dataset.shape
# 默认显示前5行
dataset.head()
# 显示数据描述
dataset.describe()
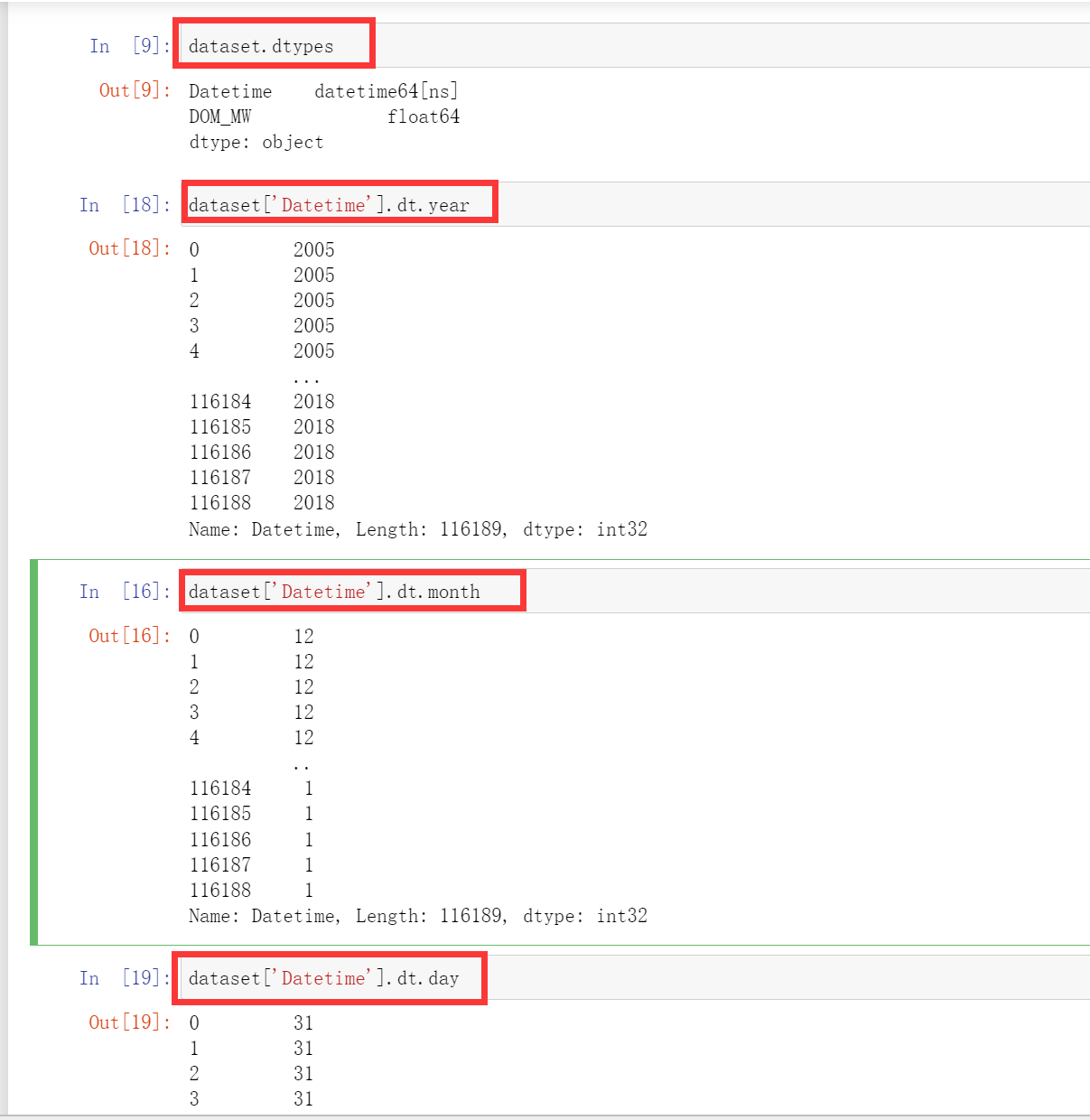
# 显示字段数据类型
dataset.dtypes

这里我们发现这个这个Datetime这里列并不是datetime类型,而是object类型,这里我们需要把他给转化成datetime类型,这里转化成datetime类型还有一个好处就是,我们非常方便取数据中的年、月、日。只需要.dt.year、dt.month、dt.day.
这里就需要用到一个API:
df['date_formatted']=pd.to_datetime(df['date'],format='%Y-%m-%d')
或者说我们在读取数据的时候就可以将这一列变成Datetime类型
dataset = pd.read_csv('DOM_hourly.csv',parse_dates=[0])
然后我们发现这样他读进来就是这个类型
# 将字段Datetime数据类型转换为日期类型
dataset['Datetime'] = pd.to_datetime(dataset['Datetime'], format="%Y-%m-%d %H:%M:%S")
# 再次查看字段的数据类型
dataset.dtypes
# 将字段Datetime设置为索引列
# 目的:后续基于索引来进行数据集的切分
dataset.index = dataset.Datetime
# 将原始的Datetime字段列删除
dataset.drop(columns=['Datetime'], axis=1, inplace=True)
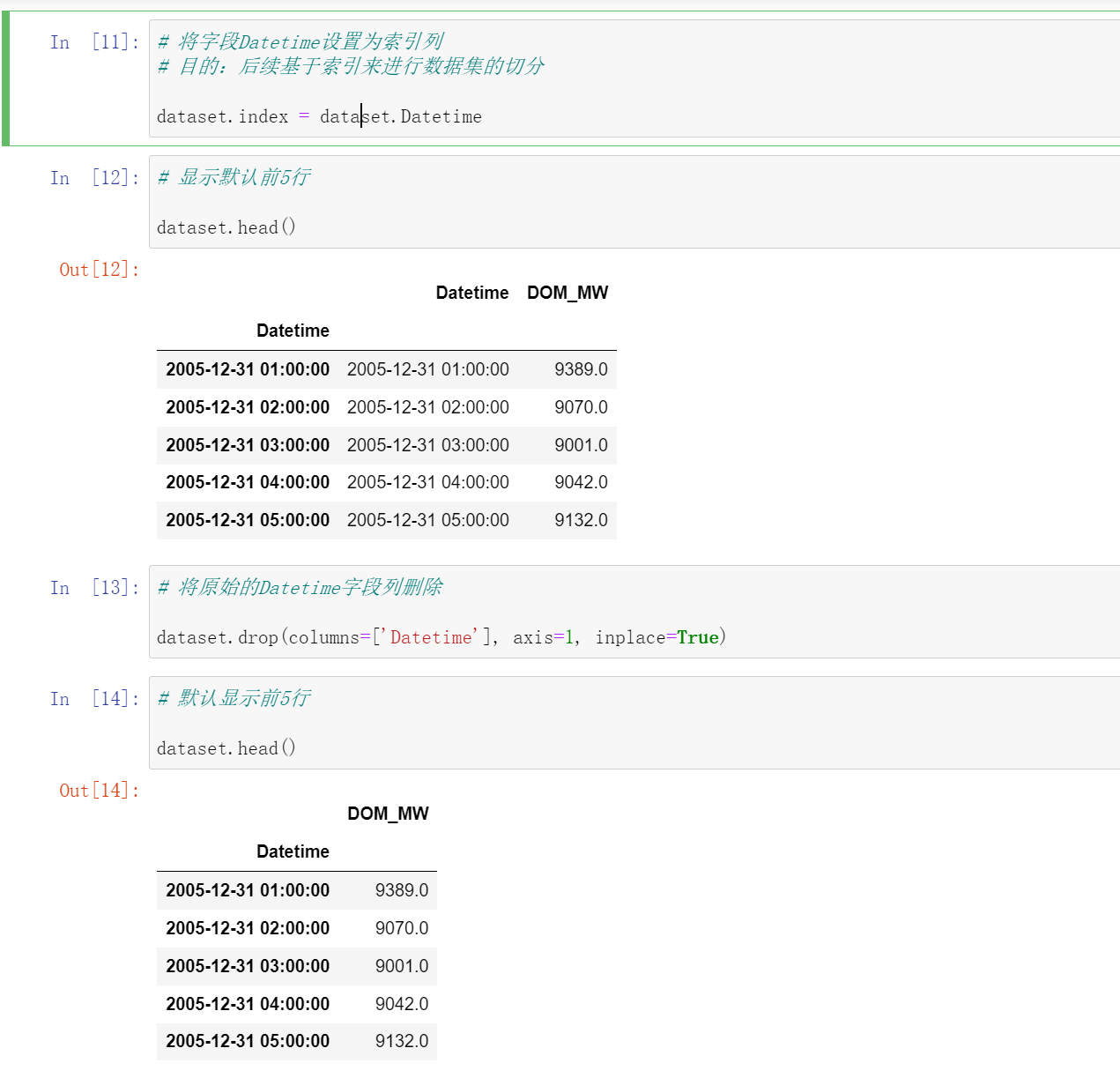
然后我们可视化这些数据:
# 可视化显示DOM_MW的数据分布情况
dataset['DOM_MW'].plot(figsize=(16,8))
plt.show()
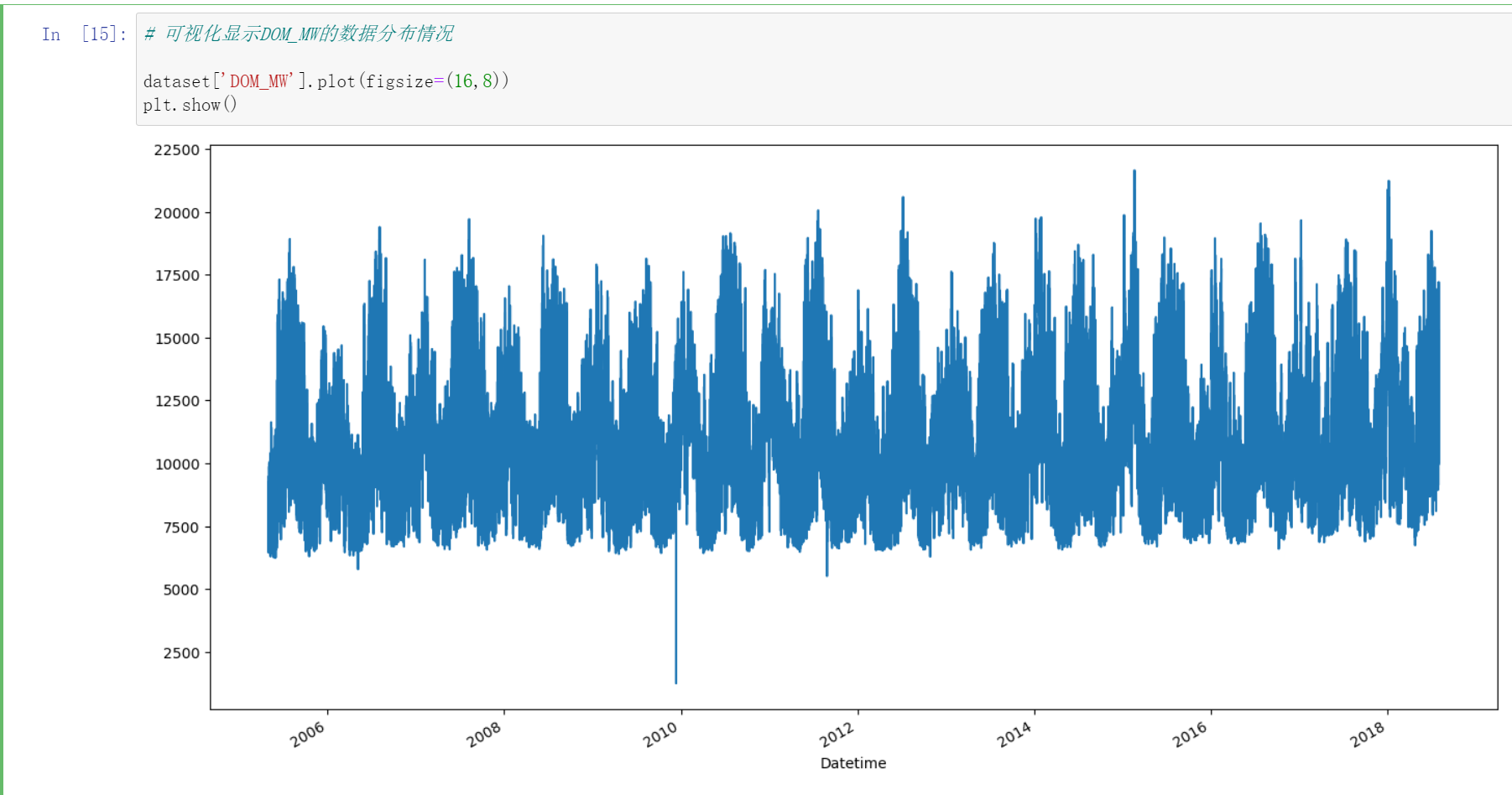
数据归一化
这里我们使用的是sklearn.preprocessing中的MinMaxScaler函数
# 数据进行归一化
scaler = MinMaxScaler()
dataset['DOM_MW'] = scaler.fit_transform(dataset['DOM_MW'].values.reshape(-1, 1))
# 均值为0,标准差为1
dataset.head()
我们可以发现他的总体分布不变。
这里的dataset['DOM_MW'].values是取这一列的值,然后.reshape(-1,1)是将他转化成一列。
我们可以看看这三个的区别:
2.2 特征工程
这里我们定义了三个函数:
1.构造特征数据集和标签集
# 功能函数:构造特征数据集和标签集
def create_new_dataset(dataset, seq_len = 12):
'''基于原始数据集构造新的序列特征数据集
Params:
dataset : 原始数据集
seq_len : 序列长度(时间跨度)
Returns:
X, y
'''
X = [] # 初始特征数据集为空列表
y = [] # 初始标签数据集为空列表
start = 0 # 初始位置
end = dataset.shape[0] - seq_len # 截止位置
for i in range(start, end): # for循环构造特征数据集
sample = dataset[i : i+seq_len] # 基于时间跨度seq_len创建样本
label = dataset[i+seq_len] # 创建sample对应的标签
X.append(sample) # 保存sample
y.append(label) # 保存label
# 返回特征数据集和标签集
return np.array(X), np.array(y)
这个函数的意思就是我们通过前seq_len个当样本来预测第seq_len+1个。比如说上面的seq_len等于12,也就是第[0,12)为sample,然后这个label就是第dataset[12]。
2.划分数据集
# 功能函数:基于新的特征的数据集和标签集,切分:X_train, X_test
def split_dataset(X, y, train_ratio=0.8):
'''基于X和y,切分为train和test
Params:
X : 特征数据集
y : 标签数据集
train_ratio : 训练集占X的比例
Returns:
X_train, X_test, y_train, y_test
'''
X_len = len(X) # 特征数据集X的样本数量
train_data_len = int(X_len * train_ratio) # 训练集的样本数量
X_train = X[:train_data_len] # 训练集
y_train = y[:train_data_len] # 训练标签集
X_test = X[train_data_len:] # 测试集
y_test = y[train_data_len:] # 测试集标签集
# 返回值
return X_train, X_test, y_train, y_test
3.基于新的X_train, X_test, y_train, y_test创建批数据(batch dataset)
# 功能函数:基于新的X_train, X_test, y_train, y_test创建批数据(batch dataset)
def create_batch_data(X, y, batch_size=32, data_type=1):
'''基于训练集和测试集,创建批数据
Params:
X : 特征数据集
y : 标签数据集
batch_size : batch的大小,即一个数据块里面有几个样本
data_type : 数据集类型(测试集表示1,训练集表示2)
Returns:
train_batch_data 或 test_batch_data
'''
if data_type == 1: # 测试集
dataset = tf.data.Dataset.from_tensor_slices((tf.constant(X), tf.constant(y))) # 封装X和y,成为tensor类型
test_batch_data = dataset.batch(batch_size) # 构造批数据
# 返回
return test_batch_data
else: # 训练集
dataset = tf.data.Dataset.from_tensor_slices((tf.constant(X), tf.constant(y))) # 封装X和y,成为tensor类型
train_batch_data = dataset.cache().shuffle(1000).batch(batch_size) # 构造批数据
# 返回
return train_batch_data
在这个函数中我们分成测试集和训练集本别进行处理,dataset.cache()这个是代表着数据集将缓存在内存中,这样处理比较快,然后shuffle(1000)代表着打散,.batch(batch_size)构造成批处理
。
# ① 原始数据集
dataset_original = dataset
print("原始数据集: ", dataset_original.shape)
# ② 构造特征数据集和标签集,seq_len序列长度为12小时
SEQ_LEN = 20 # 序列长度
X, y = create_new_dataset(dataset_original.values, seq_len = SEQ_LEN)
X.shape
y.shape
这里我们序列长度为20,也就是通过前20个来,推测下一个。
然后我们观察一下样本:
数据划分:
# ③ 数据集切分
X_train, X_test, y_train, y_test = split_dataset(X, y, train_ratio=0.9)
X_train.shape
X_test.shape
y_train.shape
y_test.shape
# ④ 基于新的X_train, X_test, y_train, y_test创建批数据(batch dataset)
# 测试批数据
test_batch_dataset = create_batch_data(X_test, y_test, batch_size=256, data_type=1)
# 训练批数据
train_batch_dataset = create_batch_data(X_train, y_train, batch_size=256, data_type=2)
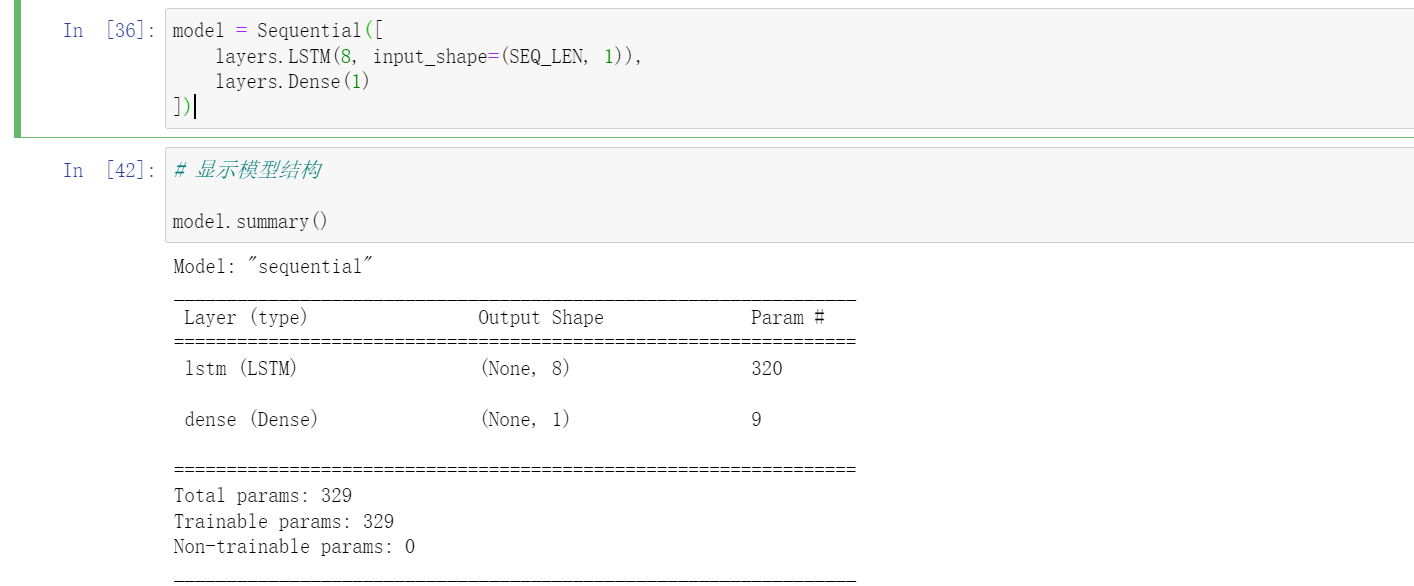
2.3 构建模型
model = Sequential([
layers.LSTM(8, input_shape=(SEQ_LEN, 1)),
layers.Dense(1)
])
# 显示模型结构
model.summary()
这里设计到一个API:
tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_loss', verbose=0, save_best_only=False,
save_weights_only=False, mode='auto', save_freq='epoch',
options=None, initial_value_threshold=None, **kwargs
)
monitor:本意是监控,这里是指用来保存最好的模型的最好的评估指标,也就是model.compile()函数中的metrics。如compile()函数中指定metrics=["accuracy"],则这里的为monitor="accuracy"就行;
save_best_only:设为True或False,为True就是最好的模型会覆盖之前的模型,如果用像weights.{epoch:02d}-{val_loss:.2f}.hdf5这样的格式化名,因为每个文件名字不同,就不会覆盖;
save_weights_only:如果为True,则只保存模型参数,如果为False就是保存整个模型。区别在于,如果只是保存参数,那么想用的时候,需要写出来网络的整个结构,然后将模型参数文件导入到网络中。
# 定义 checkpoint,保存权重文件
file_path = "best_checkpoint.hdf5"
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(filepath=file_path,
monitor='loss',
mode='min',
save_best_only=True,
save_weights_only=True)
就是如果这个save_weights_only=True,只保存模型的参数,如果下次调用的时候要先定义网络的整个结构:
像这样:
2.4 模型编译、训练、验证
# 模型编译
model.compile(optimizer='adam', loss="mae")
# 模型训练
history = model.fit(train_batch_dataset,
epochs=10,
validation_data=test_batch_dataset,
callbacks=[checkpoint_callback])#这个就是上面定义的函数
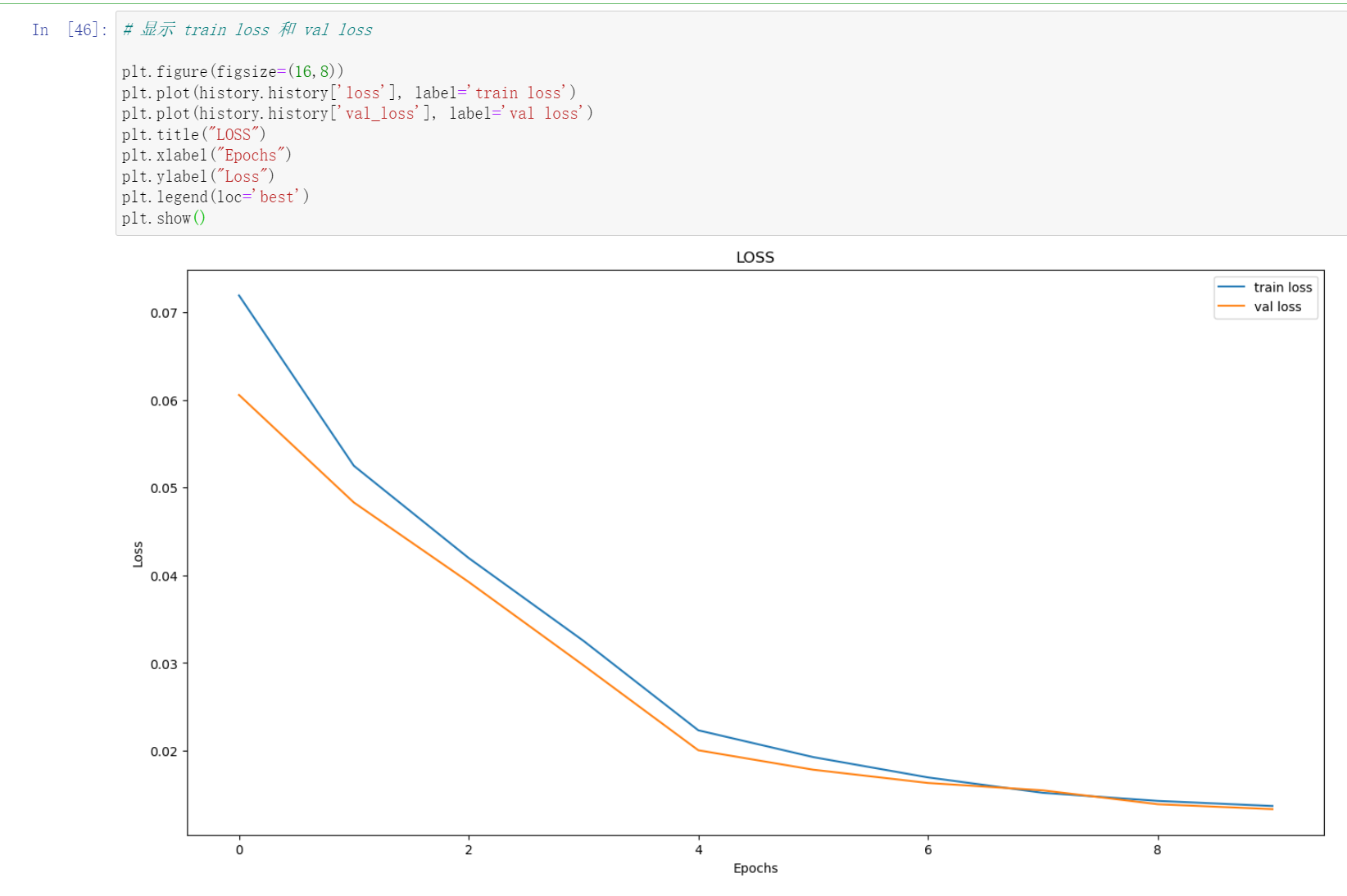
画图:
# 显示 train loss 和 val loss
plt.figure(figsize=(16,8))
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.title("LOSS")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(loc='best')
plt.show()
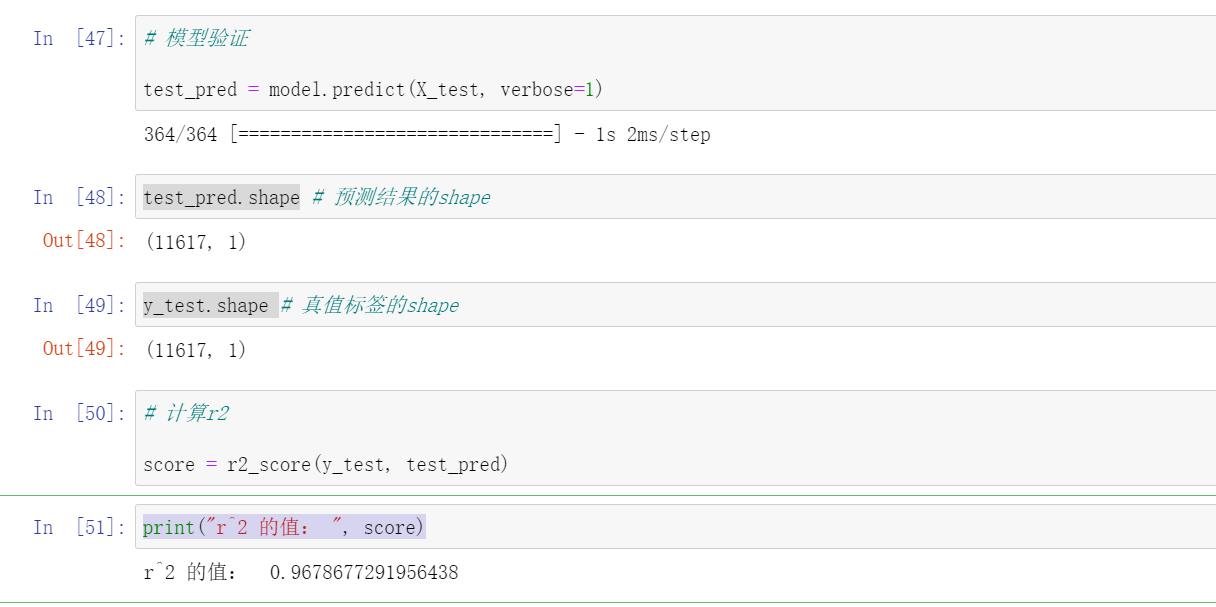
模型验证:
# 模型验证
test_pred = model.predict(X_test, verbose=1)
test_pred.shape
y_test.shape
# 计算r2
score = r2_score(y_test, test_pred)
print("r^2 的值: ", score)
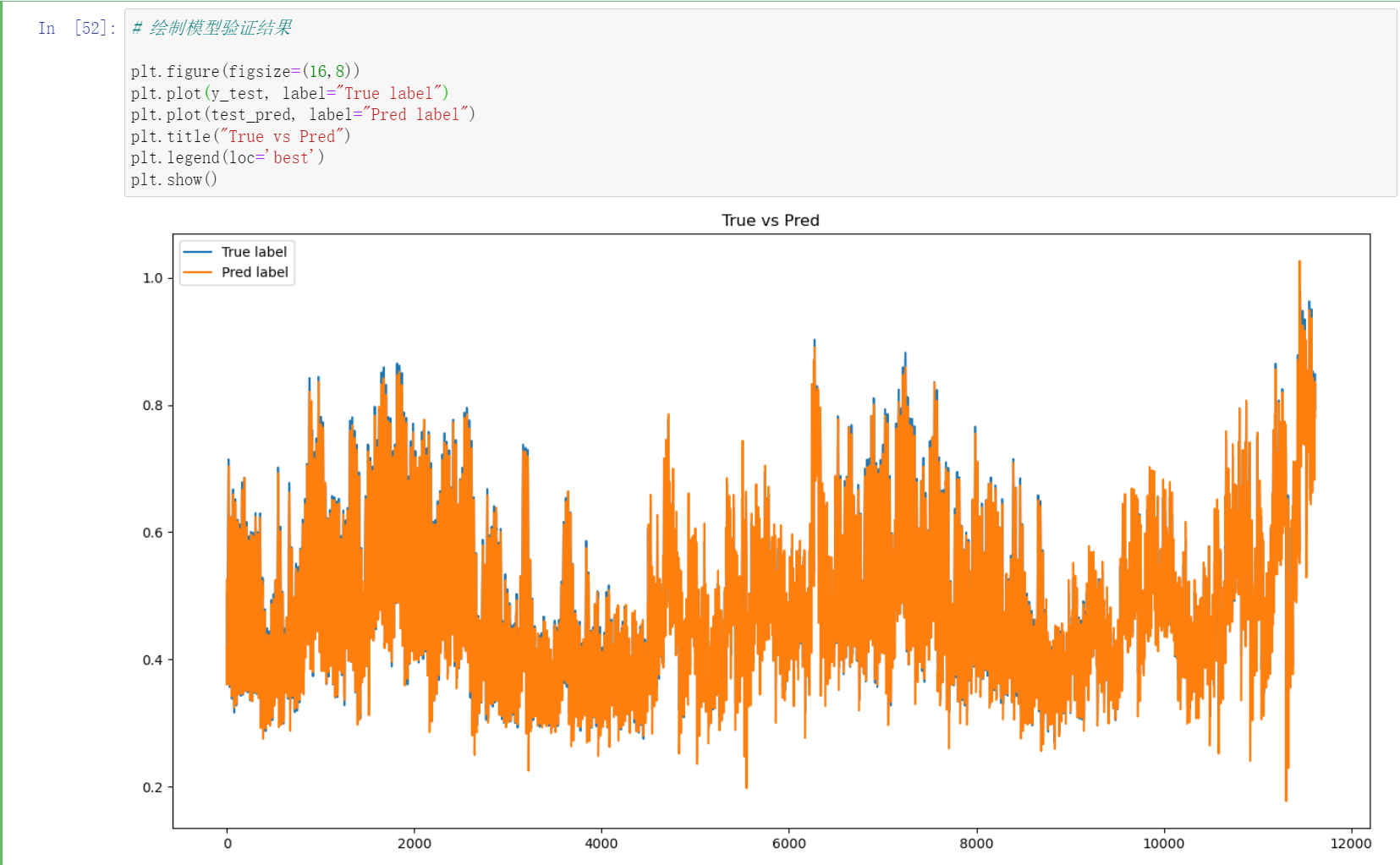
# 绘制模型验证结果
plt.figure(figsize=(16,8))
plt.plot(y_test, label="True label")
plt.plot(test_pred, label="Pred label")
plt.title("True vs Pred")
plt.legend(loc='best')
plt.show()
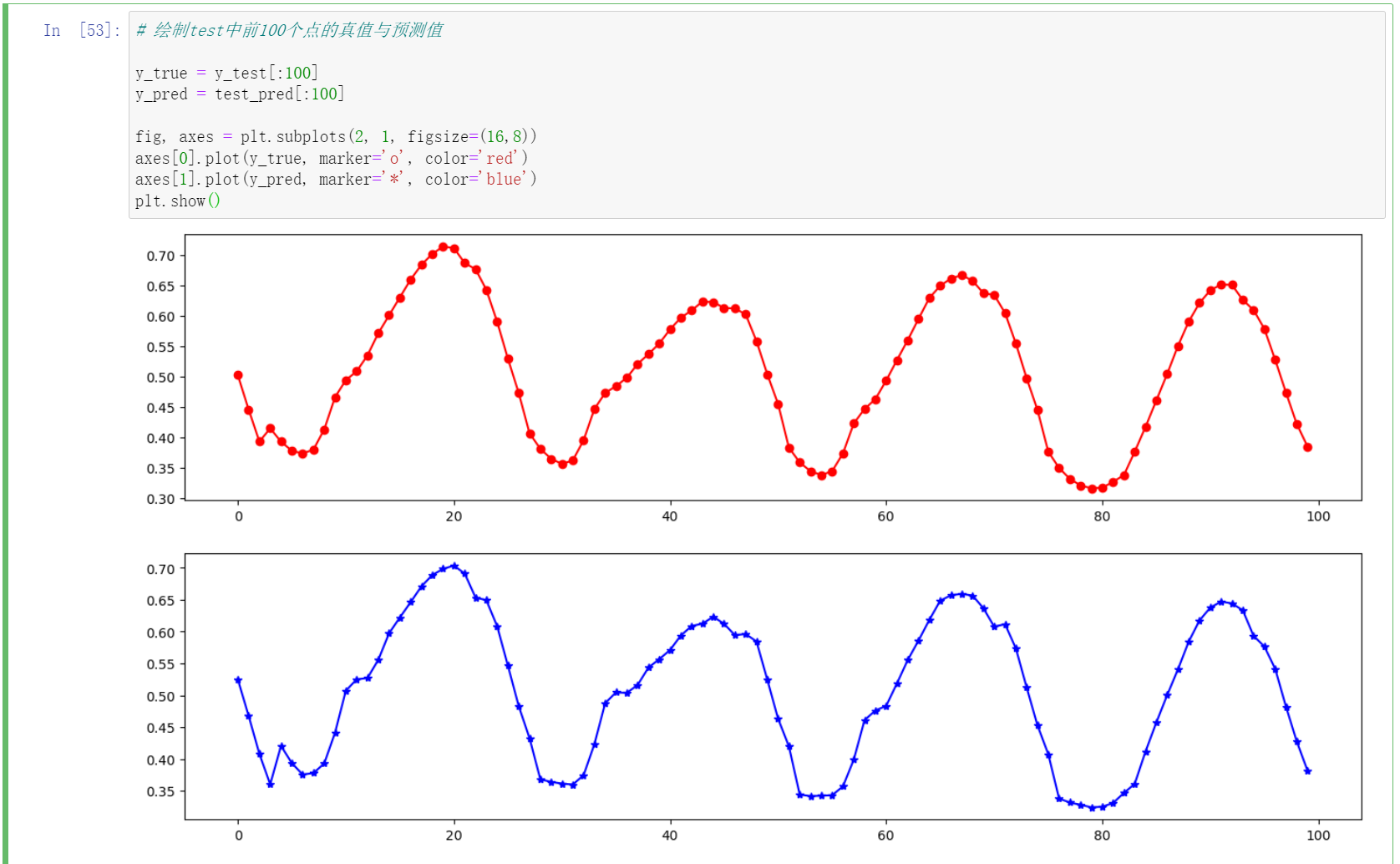
# 绘制test中前100个点的真值与预测值
y_true = y_test[:100]
y_pred = test_pred[:100]
fig, axes = plt.subplots(2, 1, figsize=(16,8))
axes[0].plot(y_true, marker='o', color='red')
axes[1].plot(y_pred, marker='*', color='blue')
plt.show()
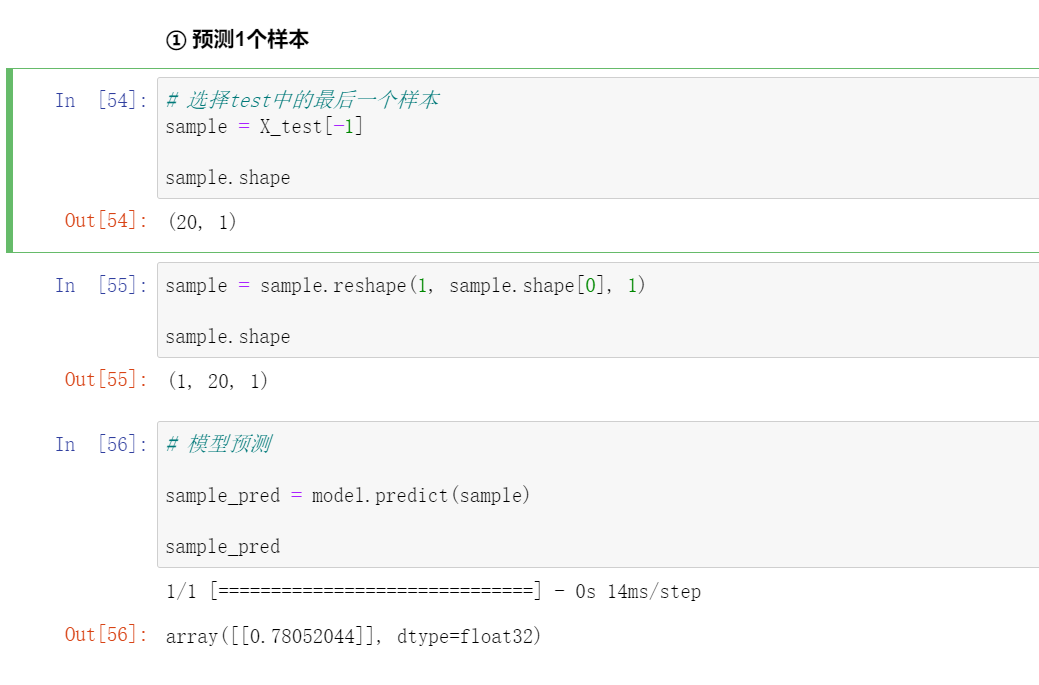
2.5 模型测试
① 预测1个样本
# 选择test中的最后一个样本
sample = X_test[-1]
sample.shape
sample = sample.reshape(1, sample.shape[0], 1)
sample.shape
# 模型预测
sample_pred = model.predict(sample)
sample_pred
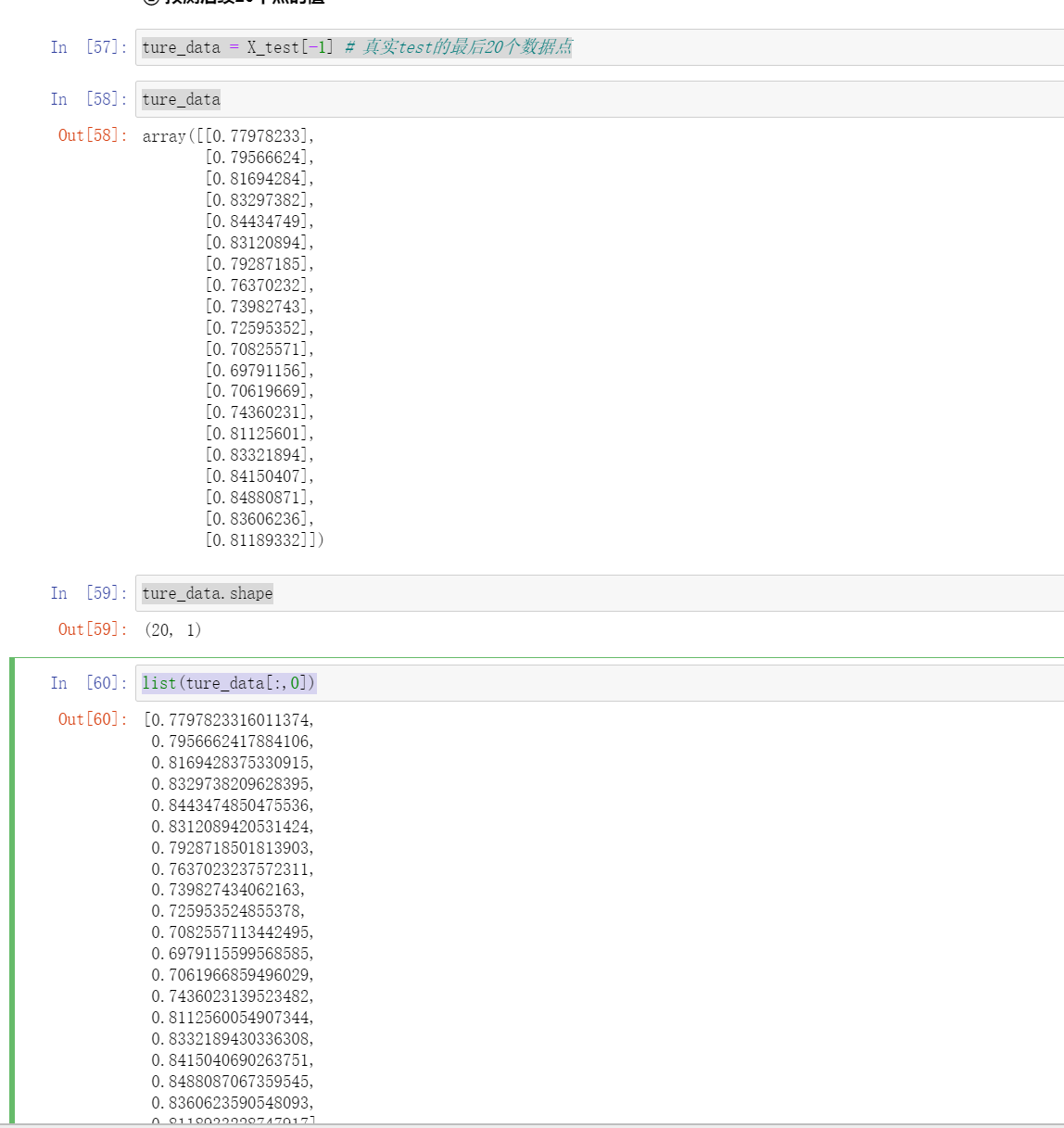
② 预测后续20个点的值
ture_data = X_test[-1] # 真实test的最后20个数据点
ture_data
ture_data.shape
list(ture_data[:,0])
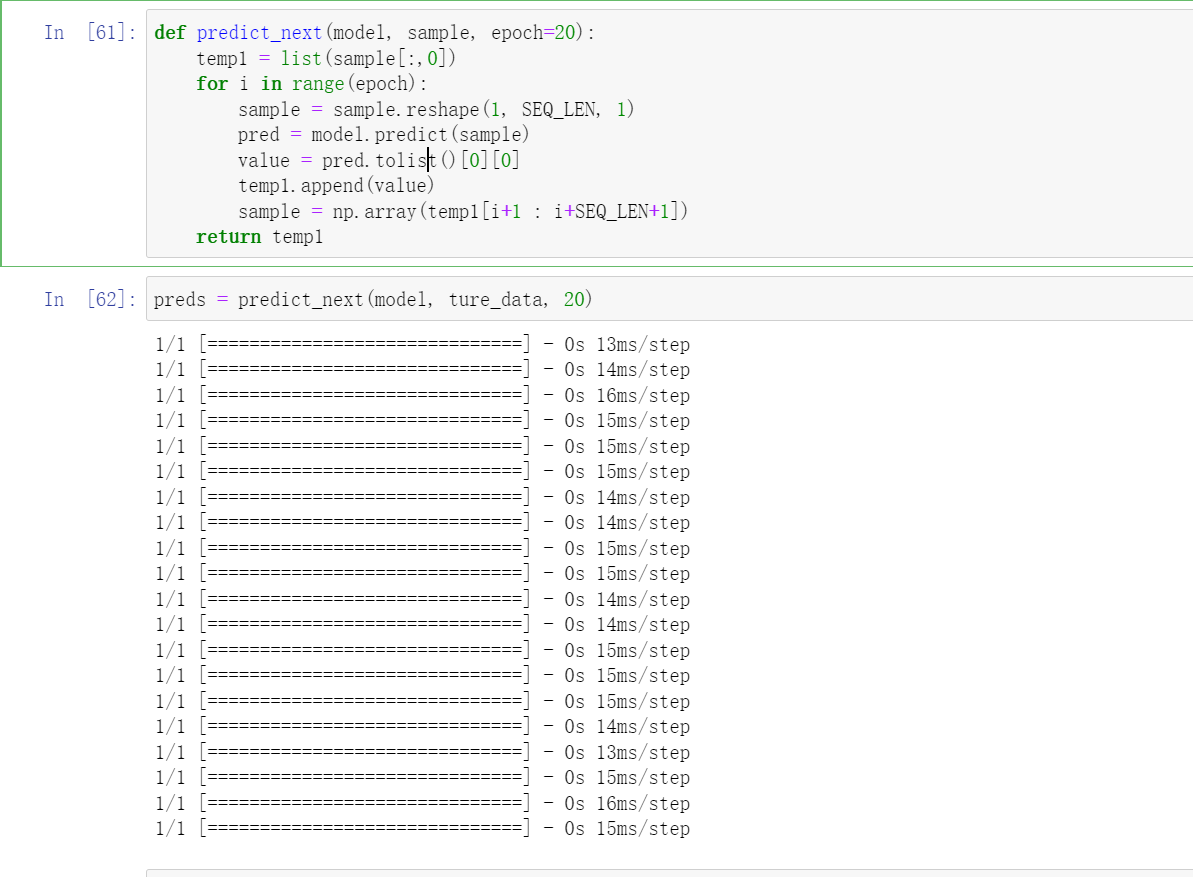
这个函数的意思是我们再向下预测20个。
def predict_next(model, sample, epoch=20):
temp1 = list(sample[:,0])
for i in range(epoch):
sample = sample.reshape(1, SEQ_LEN, 1)
pred = model.predict(sample)
value = pred.tolist()[0][0]
temp1.append(value)
sample = np.array(temp1[i+1 : i+SEQ_LEN+1])
return temp1
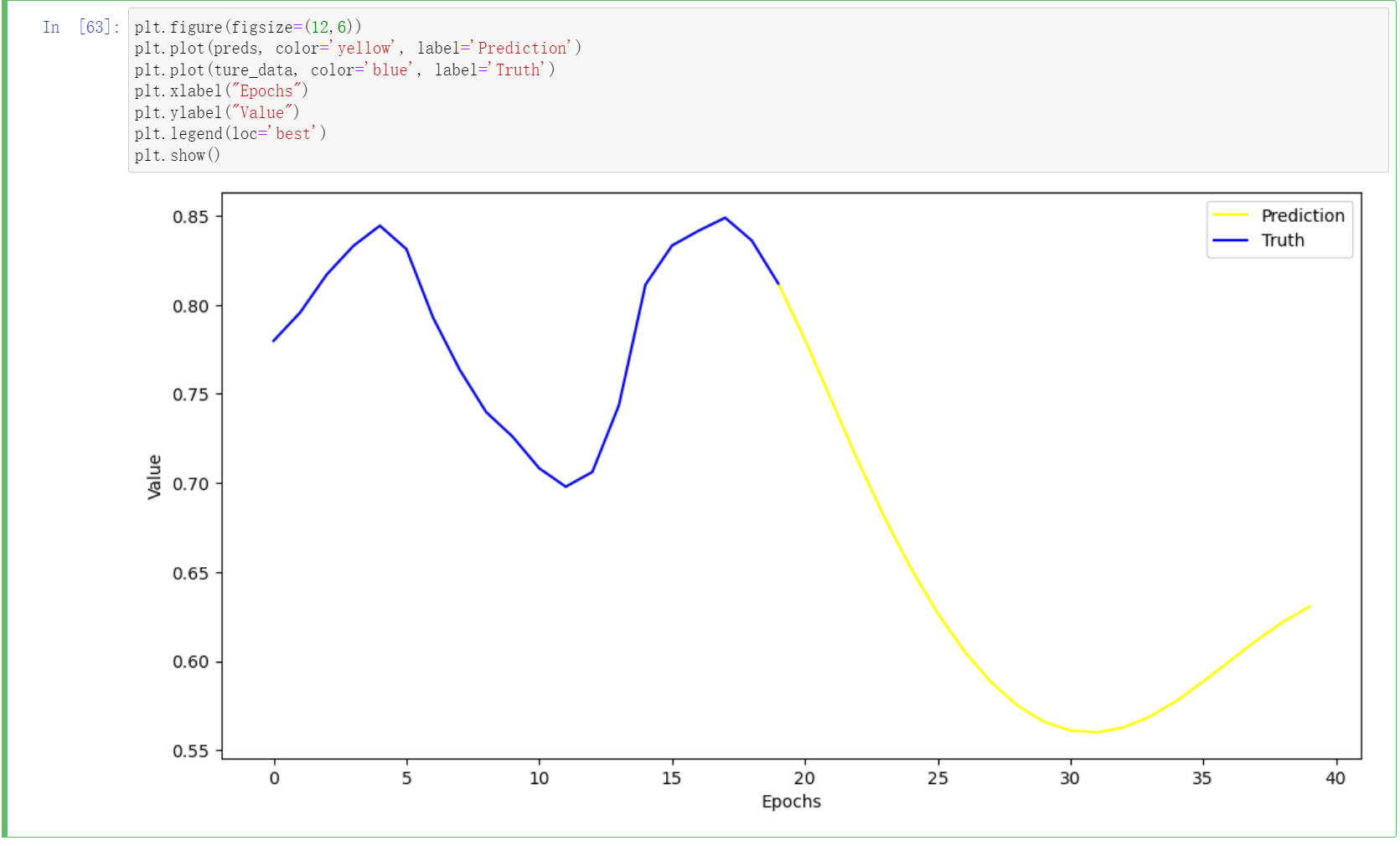
preds = predict_next(model, ture_data, 20)
plt.figure(figsize=(12,6))
plt.plot(preds, color='yellow', label='Prediction')
plt.plot(ture_data, color='blue', label='Truth')
plt.xlabel("Epochs")
plt.ylabel("Value")
plt.legend(loc='best')
plt.show()