Self-Supervised Bidirectional Learning for Graph Matching
动机
Graph Matching(GM)是个NP难问题。随着机器学习的兴起,该问题也有望被更高效地解决。然而,现有的监督学习仍然需要为了训练去计算大量的ground truth。本文最大的目标是实现一个无监督的GM算法。
前置
-
文中默认source graph小于target graph,即subgraph matching
-
GM问题可以被抽象为二次分配问题(QAP):
\[max J(Z) = vec(Z)^{\top}K vec(Z), \\ subject to Z 1_{n_2} = 1_{n_1}, Z^{\top} 1_{n_1} \leq 1_{n_2} \]其中\(Z \in \mathbb{R}^{n_1 \times n_2}\)是排列矩阵,用来编码点和点之间的对应关系,并且\(Z \in \{0, 1\}^{n_s \times n_t}\),只有匹配的i和j,\(z_{ij}=1\),否则是0。\(vec(Z)\)是列向量版本,\(K \in \mathbb{R}^{n_1n_2 \times n_1 n_2}\)叫亲和矩阵,对角线表示点点相似度,其他的表示边边相似度。
这里的点和边的相似度并没解释清原理,但按照式子来看,应该是在vec(Z)做内积前做了一套先验的权重。
- 定义中,点和边都有特征向量,而K也会被简化成点对点的\(M \in \mathbb{R}^{n_s \times n_t}\)矩阵。
模型
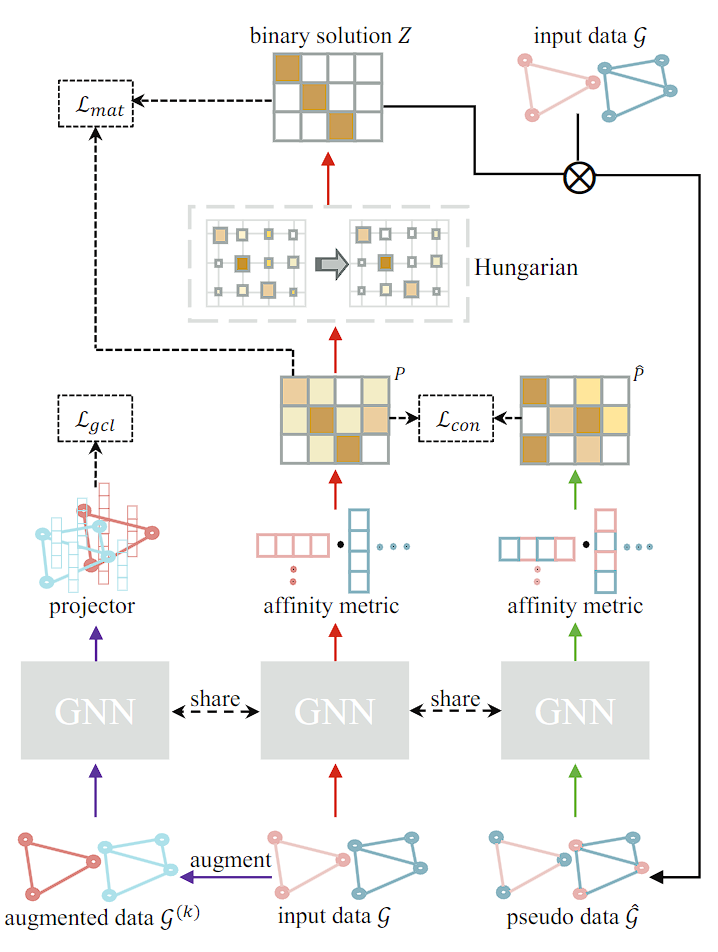
Pseudo Correspondence Generation
先用GNN学出两个图的特征\(H_s\)和\(H_t\),然后做内积得到\(M=H_s H^{\top}_t\),然后对它进行行的softmax得到矩阵P,也就是每个source图的点对所有target图的匹配概率。
最后,利用匈牙利算法计算伪对应标签:
匈牙利算法是指在一个二部图上通过递归的方式实现最大匹配(两侧顶点一一对应的最优解)
这个标签可以当作ground truth进行模型训练:
文中补充证明了匈牙利算法来生成伪对应关系的有效性,已知如下结论:
其中\(z_{opt}(\omega)\)是在给定参数\(\omega\)后(也就是给定一个K)Z的最优解,\(V(\omega)\)是\(K(\omega)\)的特征向量
然后因为P表示的是匹配概率,所以能替代\(V(\omega)\),而匈牙利算法的目标是最大化\(Z^{\top}P\),所以模型最后会使得上述式子的lower bound趋向最大值1,也就是排序z和配对的概率相吻合,也就是会让式子左边的z逼近\(z_{opt}(\omega)\)
Bidirectional Recycling Consistency
毕竟是无监督的,所以作者再加了一块自监督模块
这些假特征实际就是将认为对齐的点的特征做了聚合变成了被对齐的点的特征。理论上如果Z是完美的话,那么\(\hat{P}\)和\(P\)也应该是完美对齐的:
同样的,文中也进行了一波可以这么干的证明,基本思路是两图embedding和俩伪图embedding做内积后彼此过行的softmax后再相减,差的二范数为J,J最小的时候就是预测的Z和实际的Z完全相等的时候。而内积的行softmax就是P,所以P和\(\hat{P}\)靠拢会让Z的预测和精准值靠拢。
Graph Contrastive Learning (GCL) to Enhance Graph Representation Learning
这里作者又加了个增强无监督学习能力的模块GCL。
具体来说,每个batch的图都会被由两组映射模型映射成一对图,把他们传进GNN里,得到的结果除以结果的二范数来归一就可以得到\(y_{i}^{(k)}\),其中i是图的id,k可以是1和2,表示一张图分出的两个结果。第三个loss:
其中\(\psi(y,y')=\exp(\langle y, y' \rangle)\), \(\langle y, y' \rangle\)是点乘。
loss
最后的loss就是上面三个loss的加权求和。因为前两个都是对P,也就是连续化的Z做文章,所以作者将他们的权重设置成了一样,所以第三个的权重就是1减去这俩权重了。
对于第三部分,作者的思路是,希望在前期更多地使用GCL来优化GNN,但在后期就应该更专注于另外俩,毕竟GCL只是自监督的增强模块,本体还是前俩。所以最后的权重:
其中m是batch数量。
实验
实际的实验中用的全是图片数据集,就不多关注实验结果了
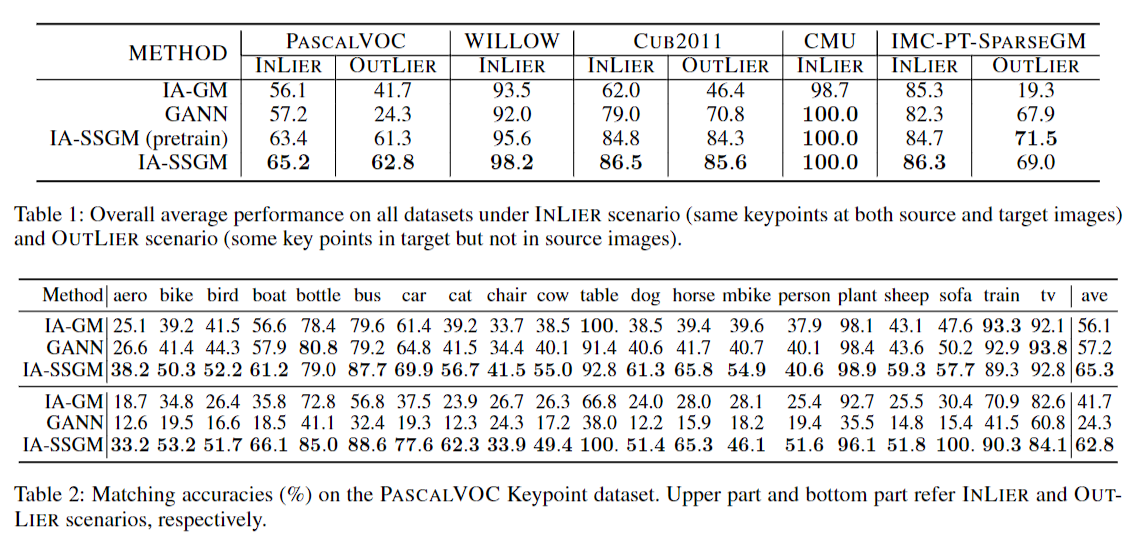
INLIER和OUTLIER的区别是要不要删去source图中的异常点
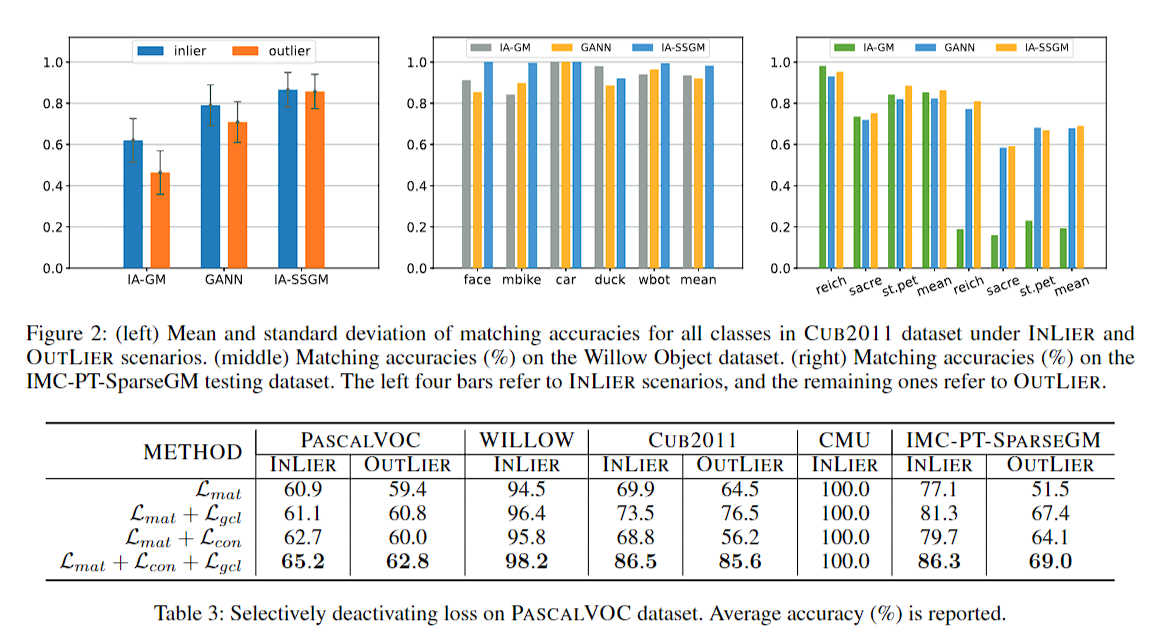
- Self-Supervised Bidirectional Supervised Learning Matchingself-supervised bidirectional supervised learning self-supervised self-supervised exploration generative supervised self-supervised transformers lightweight supervised self-supervised interpretable adversarial generative self-supervised transformers supervised empirical language-guided self-supervised segmentation self-supervised recommendation session-based self-supervised recommendation convolutional self-supervised quantization augmentation randomized