本文做个简单总结,博主不是做自监督领域的,如果错误,欢迎指正。
链接
Code:
Official:
MMpretrain:
Paper:
EVA01:
EVA02:
EVA01
成就:
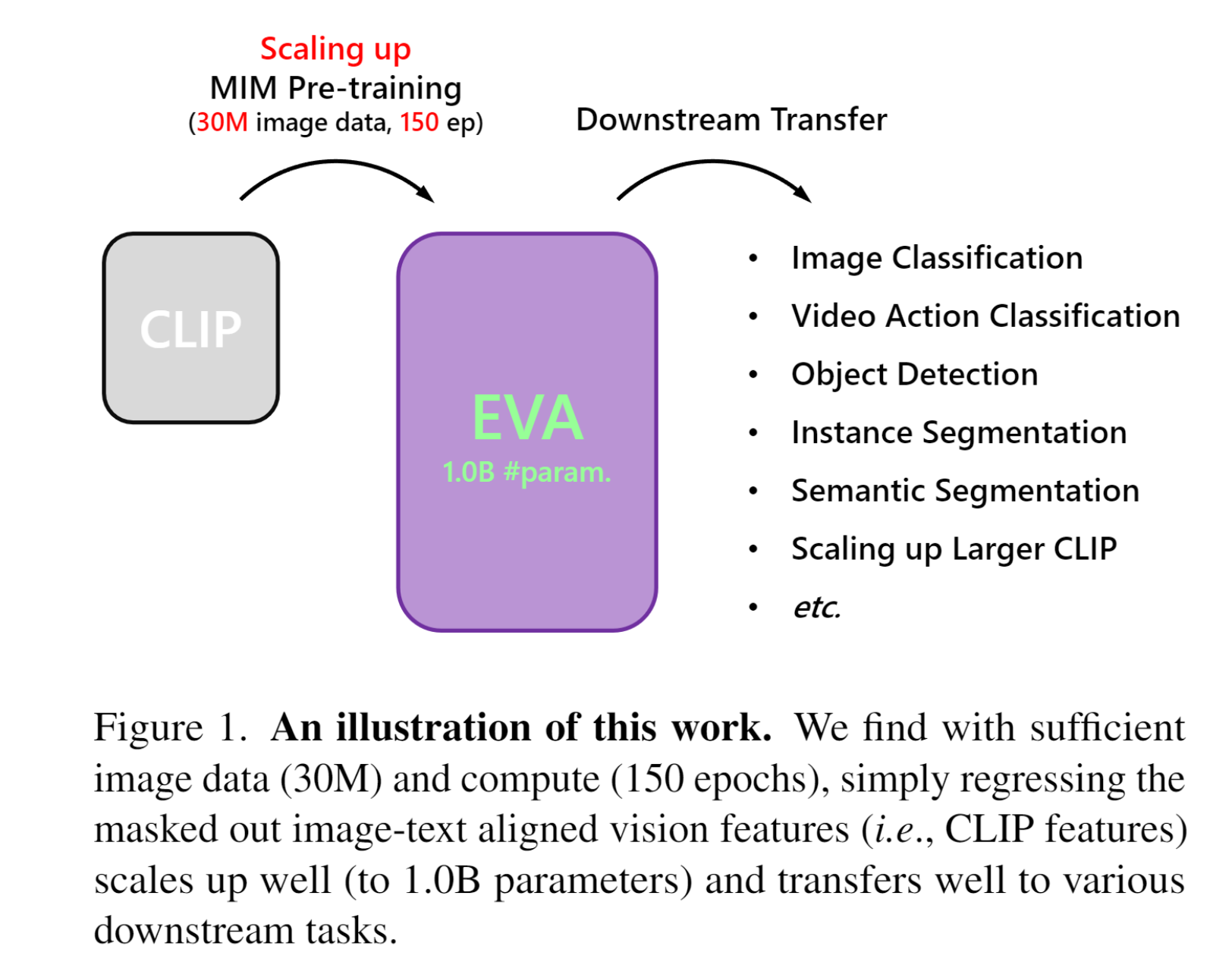
EVA 是第一个开源的十亿级视觉基础模型,在广泛的下游任务上实现了最先进的性能。
改进:
-
EVA是基于CLIP的预训练,而不是MIM预训练。
-
MIM(Masked Image Modeling)预训练,即MAE做的事情,随机mask掉图片中一部分,生成原图。
-
缺点:MIM预训练只包含底层细节信息,没有高层语义信息。
-
-
CLIP预训练,用“图像-文本”进行对比学习训练,
-
使用场景:根据文本搜索相关图片,根据图片生成相关描述。
-
优点:文本补充了MIM缺乏的高层语义信息,CLIP预训练细节和语义信息都有。CLIP预训练中的高层语义信息能够给下游任务提供更大的帮助。
-
-
-
EVA 不需要昂贵的监督训练阶段,仅利用来自开源数据集的图像就可以。
-
EVA 的迁移学习性能强。
-
EVA 可以充当以视觉为中心的多模态支点
EVA02
成就:

-
使用可公开访问的训练数据,仅具有 304M 参数的 EVA-02 在 ImageNet-1K 验证集上实现了惊人的 90.0 微调 top-1 精度。
-
EVA-02-CLIP 在 ImageNet-1K 上可以达到高达 80.4 的零样本 top-1,优于之前最大、最好的开源 CLIP,仅需要约 1/6 的参数和约 1/6 的图像文本训练数据。
改进:
-
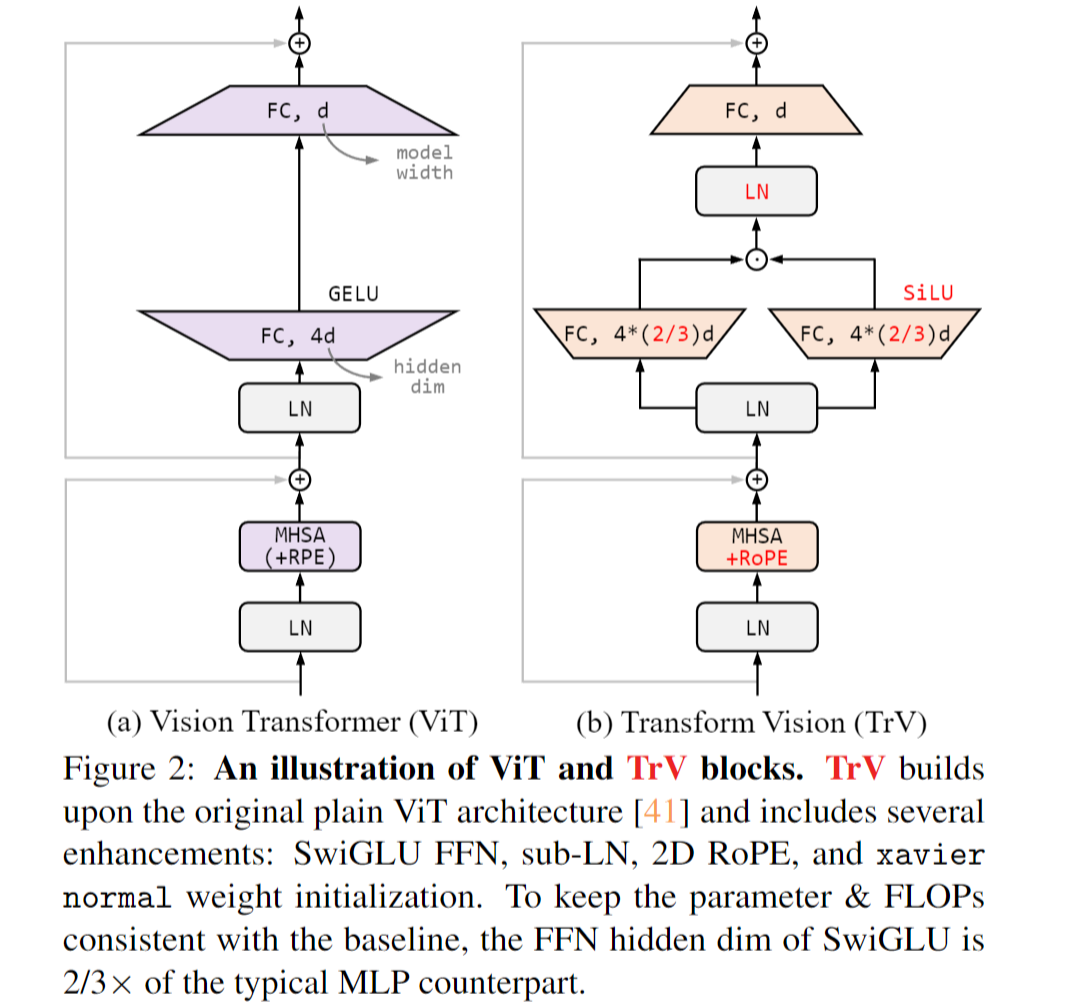
EVA02对原始ViT改进了结构(借鉴NLP上的一些改进Tricks)
-
EVA V1使用模型的视觉Encoder作为Teacher,EVA V2使用作为Teacher。EVA-CLIP 与之前的 CLIP 模型相比性能更强大,参数数量相同,但训练成本显著降低
-
EVA V2使用了更多的数据,多个开源公开的数据集合并到一起组成 Merged-38M,累计3800万张图片。
-
训练分为多阶段,
-
在Merged-38M上进行MIM预训练,
-
在ImageNet21K上进行finetuning,
-
在ImageNet1K上做最后的finetuning。
-
EVA V2还支持微调多项下游任务,如目标检测,语义分割、实例分割等。
-
- Representation Fantasies Visual BAAI fromrepresentation fantasies visual baai baai fantasies representation representation transformers perform really representation enhanced quantum novel representation deserialize cannot string representation incremental classifier learning representation unsupervised momentum contrast representation recommendation degeneration contrastive