| 这个项目属于哪个课程 | 2023数据采集与融合技术 (福州大学 - 福州大学计算机与大数据学院) |
|---|---|
| 组名、项目简介 | 组名:你在跟我作队 项目需求:(1)音视频转文字准确性 (2)实时性 (3)多语种支持 (4)扩展性 项目目标:①搭建轻量级网站平台提供交互。②利用大模型及第三方库解析音视频及图片。③性能测试及优化 项目开展技术路线:(1)HTML/CSS/JavaScript前端编写(2)Python flask请求处理、URL路由、模板渲染,快速搭建轻量级交互式web。(3)Whisper大模型解析视频,多语言语音识别、翻译。pytesseract库及Tesseract识别引擎提取图片文字。 |
| 团队成员学号 | 组长:陈星宇 102102135 组员: 冯展 052101102 王剑瑜 102102113 吴钦堋 052106102 李嘉骏 102102122 戴坤松 032004111 |
| 这个项目的目标 | (1)搭建轻量级网站平台。(2)输入视频网址,利用大模型解析视频,将音视频转文字,概括视频主要内容,同时获取评论,提炼观看者对视频内容看法。输入图片网址,提取图片上文字。(3)将上述处理结果通过搭建的web网页进行交互式输入输出。(4)性能测试与优化,提高转文字准确性,实时性,多语种,可扩展性和灵活性 |
| 其他参考文献 | 《语音识别技术的研究与发展》 《基于深度学习的语音识别研究》 《Whisper: A Self-supervised Speech Pre-training Method》 《Large-scale Weakly Supervised Pre-training for Speech Recognition》 《Improving the Robustness of Whisper with Domain-Adaptive Training》 |
码云链接:
具体任务
制作ppt,测试,调研
需求分析
在视频总结方面,用户有以下需求:
视频摘要/概述生成:用户需要对长时间的视频进行压缩和摘要,以便于快速了解视频内容。
关键词提取:用户需要从视频中提取关键词,以便于快速了解视频主题或内容。
文字转语音/语音转文字:用户需要将视频中的文字转换为语音或将语音转换为文字,以便于在不方便查看视频时获取视频信息。
文本信息是最直接的信息,不管对于视频总结摘要还是最终呈现给用户,文字都是最简短的。
考虑到目前大部分视频网站上的视频存在内置字幕、无字幕等问题优先考虑从视频中直接获取音频再将音频转为文本。
项目概述:
致力于打造一个简单而灵活的Web网页,用于采集需要处理的视频和图片的网址。通过运用相关第三方库和大模型技术,深入解析这些视频和图片,实现音视频转文字,音视频内容提炼,观众情感判断。同时提取图片文字,为后续的数据分析和处理提供便利。最后通过Web网页将处理结果反馈给用户,帮助他们更好地理解和利用这些视频和图片资源。
项目需求:
(1)音视频转文字准确性
(2)实时性
(3)多语种支持
(4)扩展性
项目目标:
(1)搭建轻量级网站平台。
(2)输入视频网址,利用大模型解析视频,将音视频转文字,概括视频主要内容,同时获取评论,提炼观看者对视频内容看法。输入图片网址,提取图片上文字。
(3)将上述处理结果通过搭建的web网页进行交互式输入输出。
(4)性能测试与优化,提高转文字准确性,实时性,多语种,可扩展性和灵活性。
技术路线:
(1)HTML/CSS/JavaScript前端编写
(2)Python flask请求处理、URL路由、模板渲染,快速搭建轻量级交互式web。
(3)Whisper大模型解析视频,多语言语音识别、翻译。pytesseract库及Tesseract识别引擎提取图片文字。
工具及算法调研
视频音频提取
可选择的有:
音频提取工具:如FFmpeg或Librosa
视频解码器:FFmpeg、OpenCV等
音频特征提取算法:如STFT、MFCC、声谱图等
预训练模型:如DeepSpeech、LAS等
在本次项目中,我们选择使用FFmpeg作为音频提取工具。
FFmpeg是一套开源的音视频处理工具,它可以记录、转换数字音频和视频,并能将它们转化为流。它采用了LGPL或GPL许可证,因此,用户可以自由地使用、修改和分发该软件。 FFmpeg提供了一套完整的解决方案,用于录制、转换以及流化音视频。无论是处理音频还是视频,FFmpeg都提供了丰富的功能和选项。 FFmpeg包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移植性和编解码质量,libavcodec里很多code都是从头开发的。因此,无论是处理音频还是视频,FFmpeg都提供了丰富的功能和选项。
音频转文本
我们采用的是whisper
Whisper是OpenAI在2022年发布的一款强大的语音预训练大模型。它使用了大量的多语言和多任务的监督数据进行训练,使其在英语语音识别上达到了接近人类水平的鲁棒性和准确性。此外,Whisper不仅可以实现多语言语音识别,还能处理语音翻译和语种识别等任务。 Whisper语音识别模型的优点非常显著。它有极高的语音识别准确性和稳定性,无论处理的是清晰的语音录音还是嘈杂的环境音,都能够高效地将语音转换为文本 。在实际应用过程中,Whisper也表现出了便捷性,支持GPU加速。 同时,Whisper因为它不需要联网就可以进行语音识别,这保证用户不会泄露隐私。
测试和相关输出
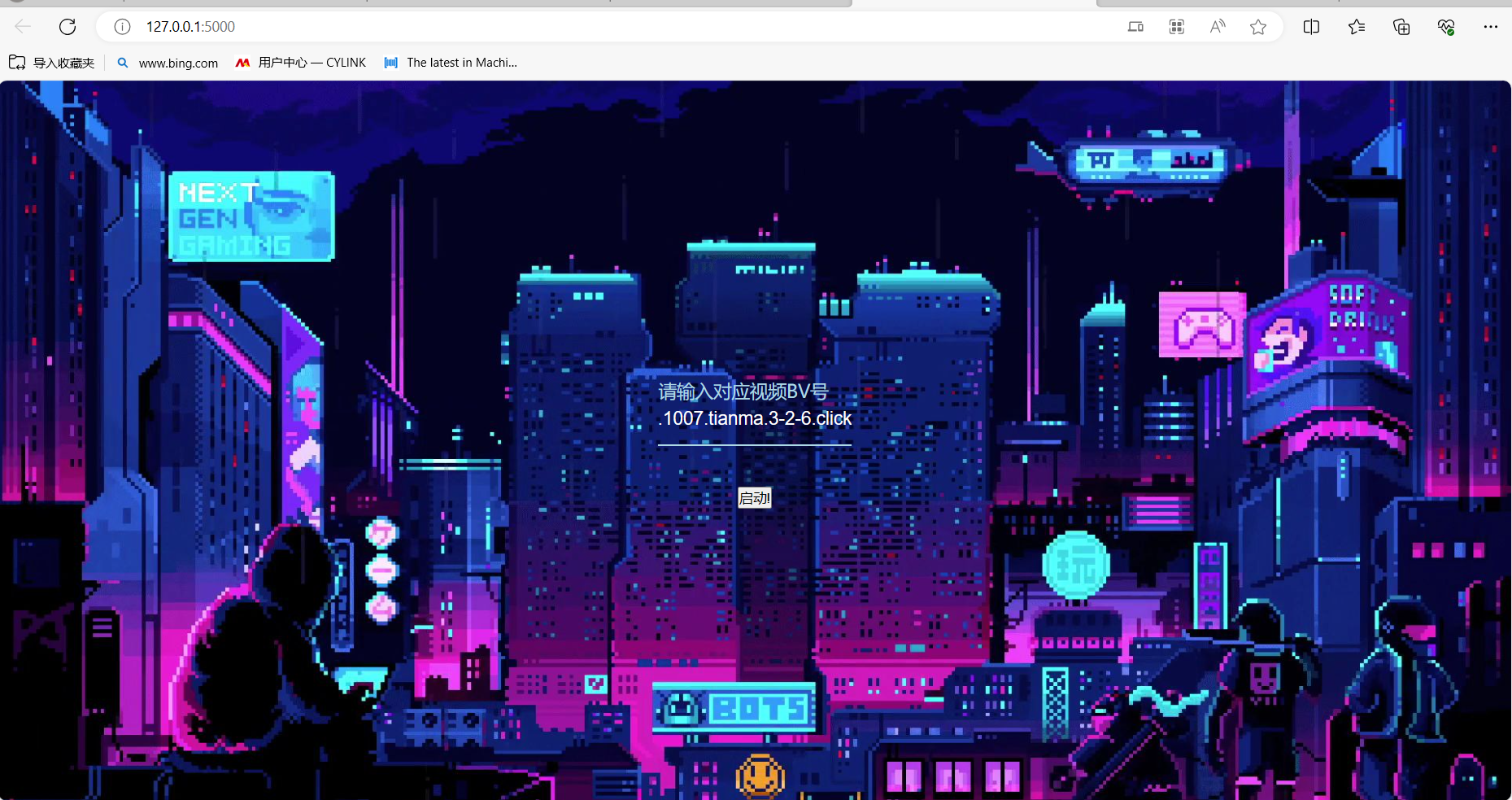
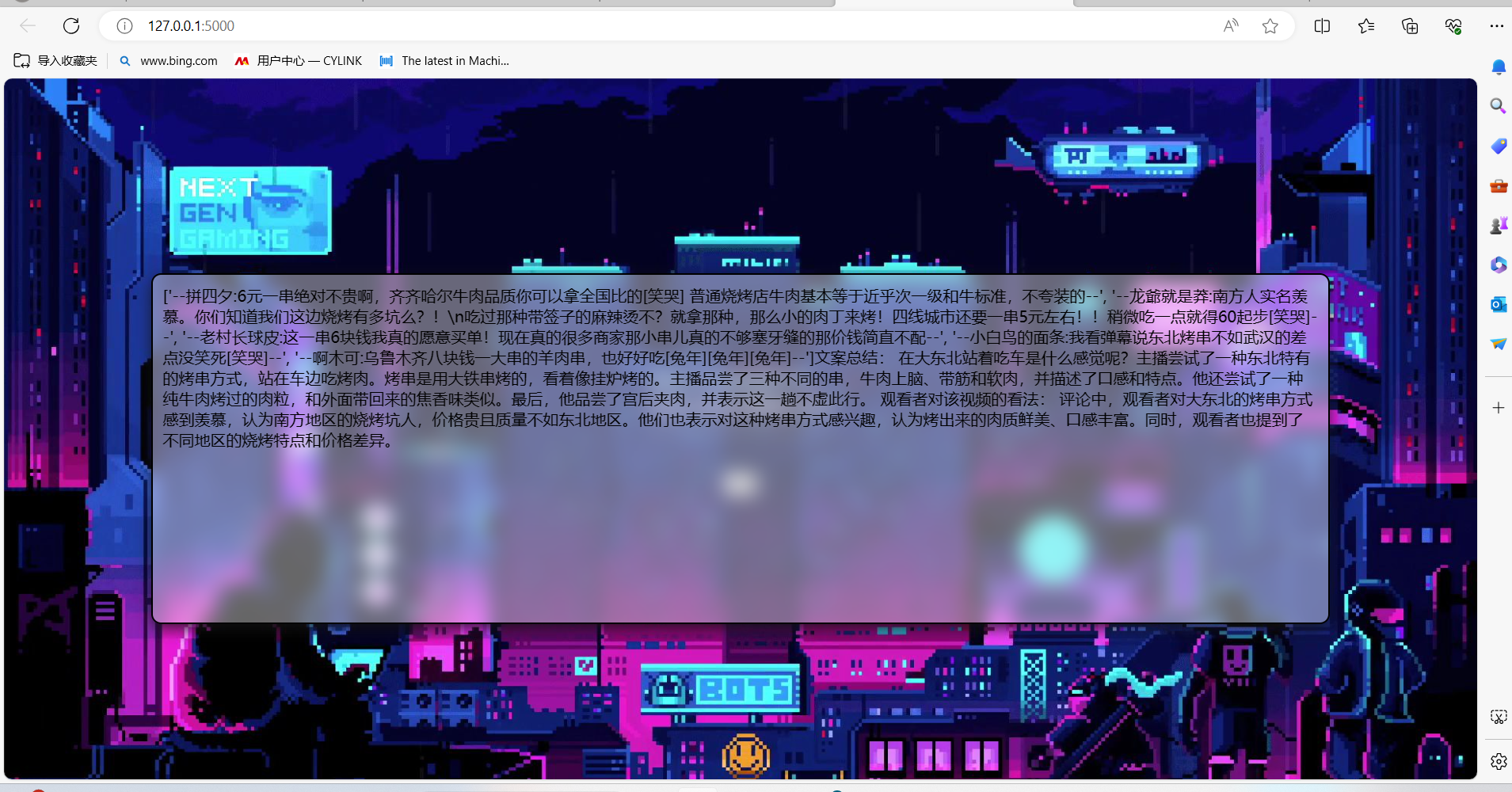


程序测试
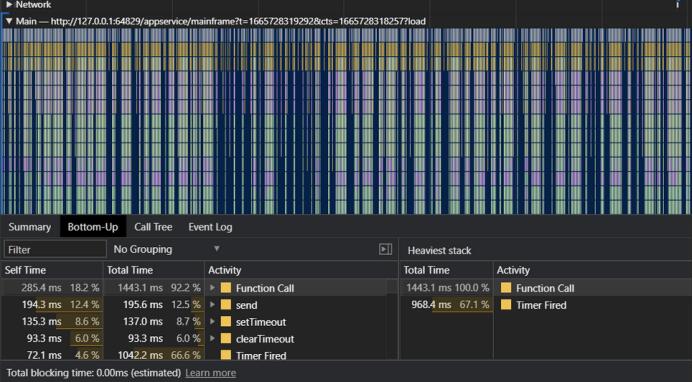
1.网络性能测试与优化
2.简单功能测试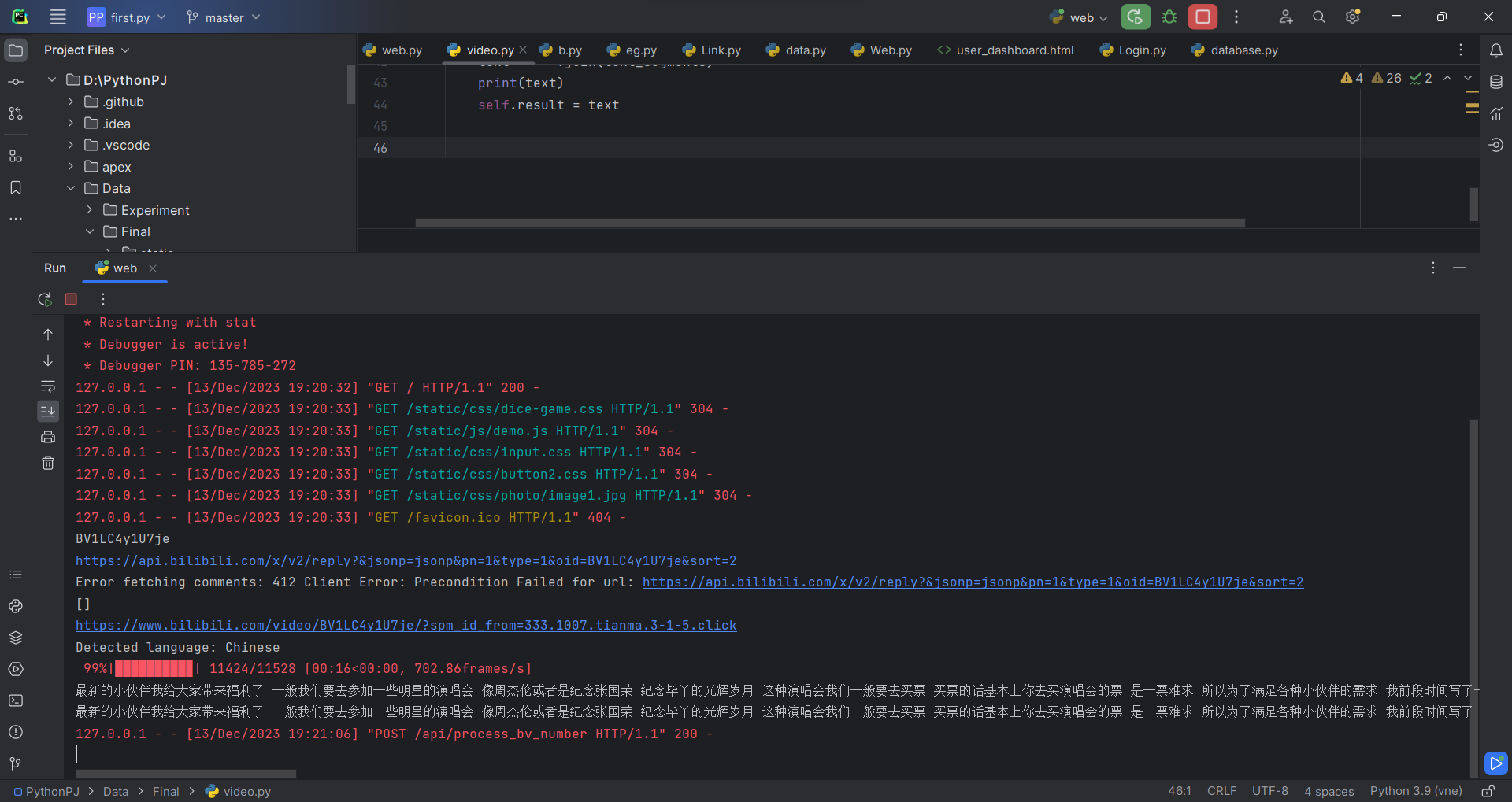
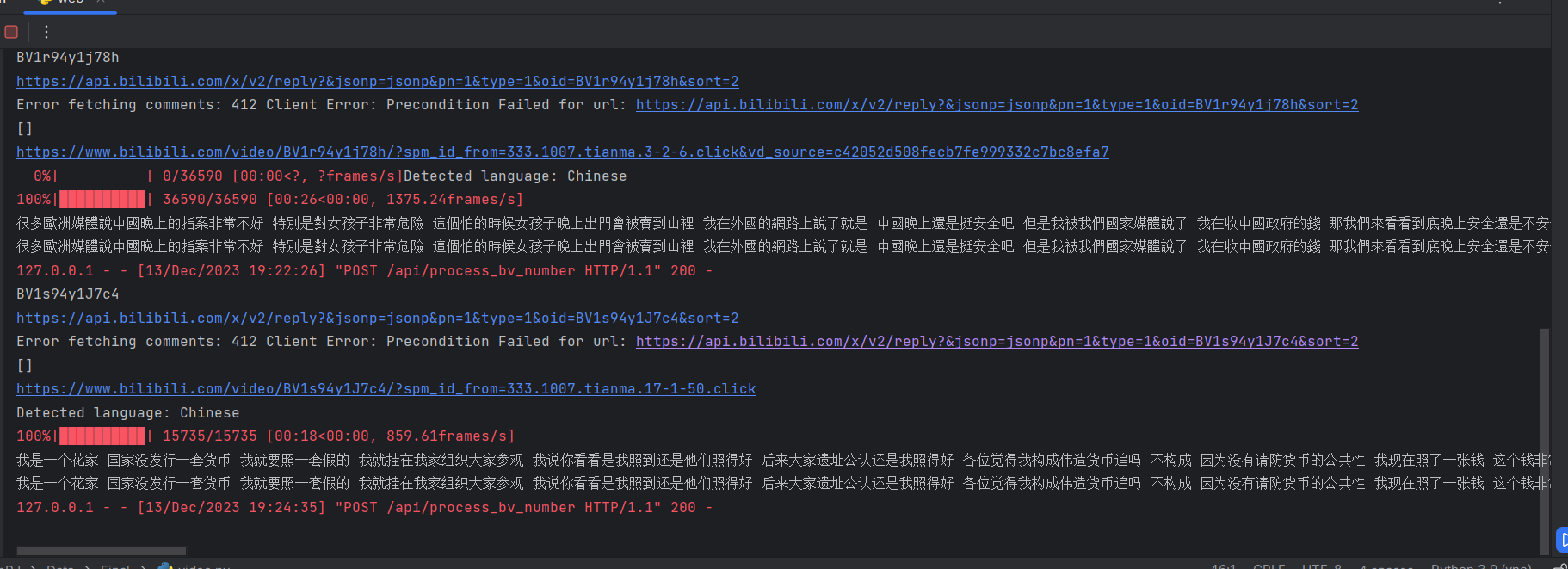
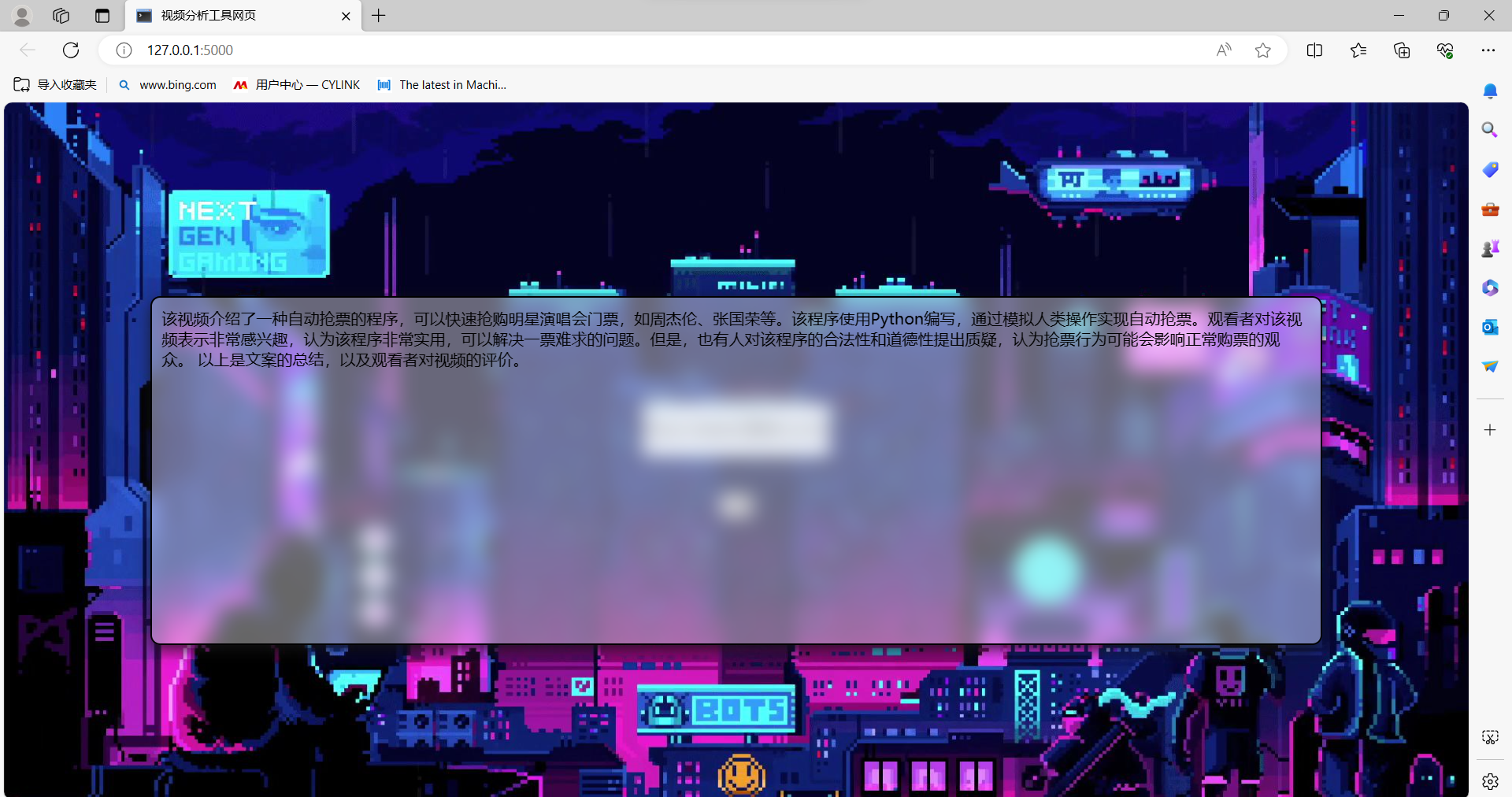
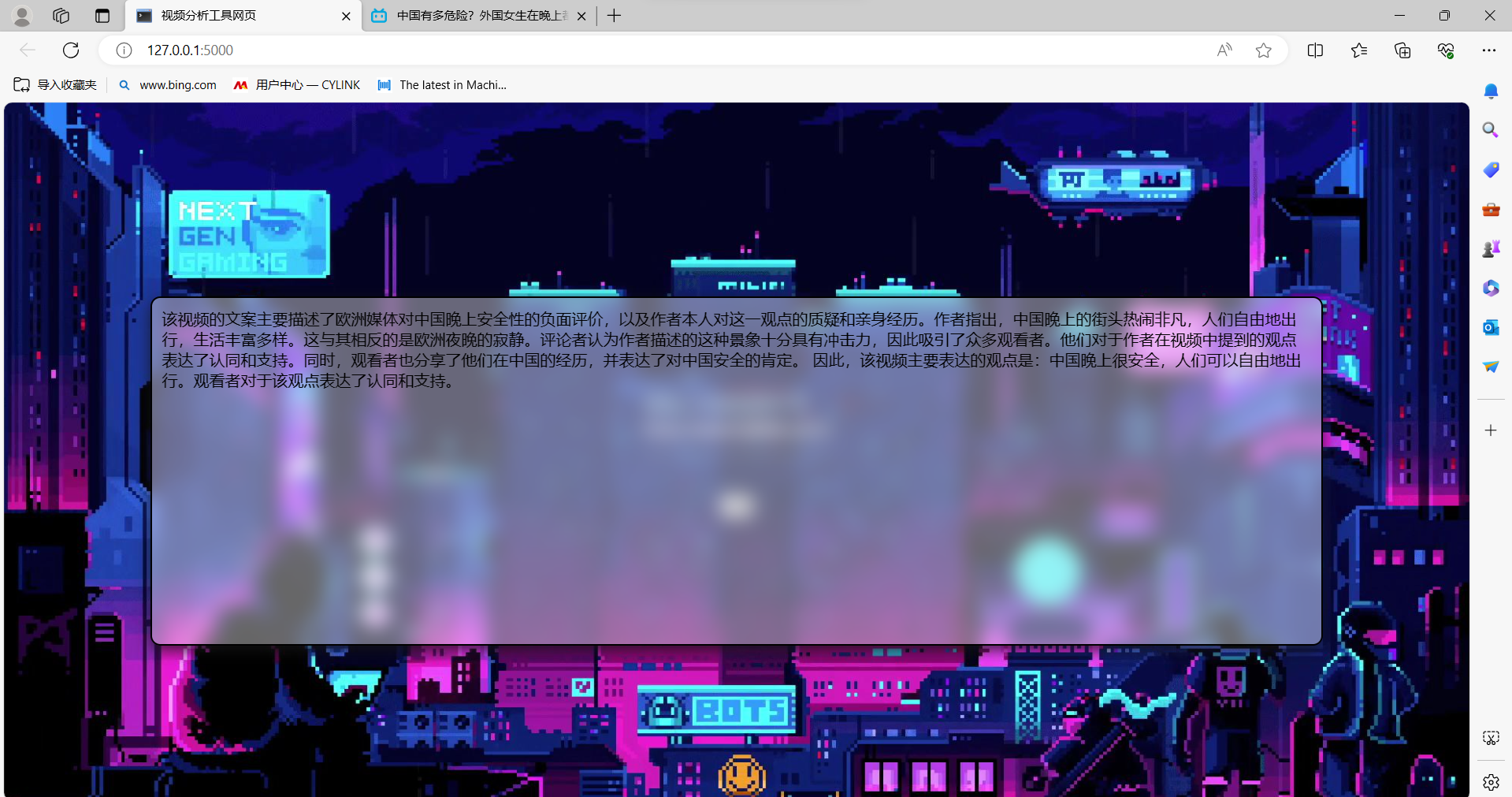
测试中遇到的问题
1.由于python本身存在Whisper包用于处理Whisper数据库文件,Whisper是Graphite项目使用的一种时间序列数据库格式。该模块提供了一系列操作Whisper数据库文件的方法,包括创建新文件、更新数据、合并、比较等。
故在使用openai-whisper时要使用:
pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple 进行安装
2.由于openai-whisper使用深度学习方法,如电脑不使用GPU运行则运行速度较慢。
云服务器的尝试
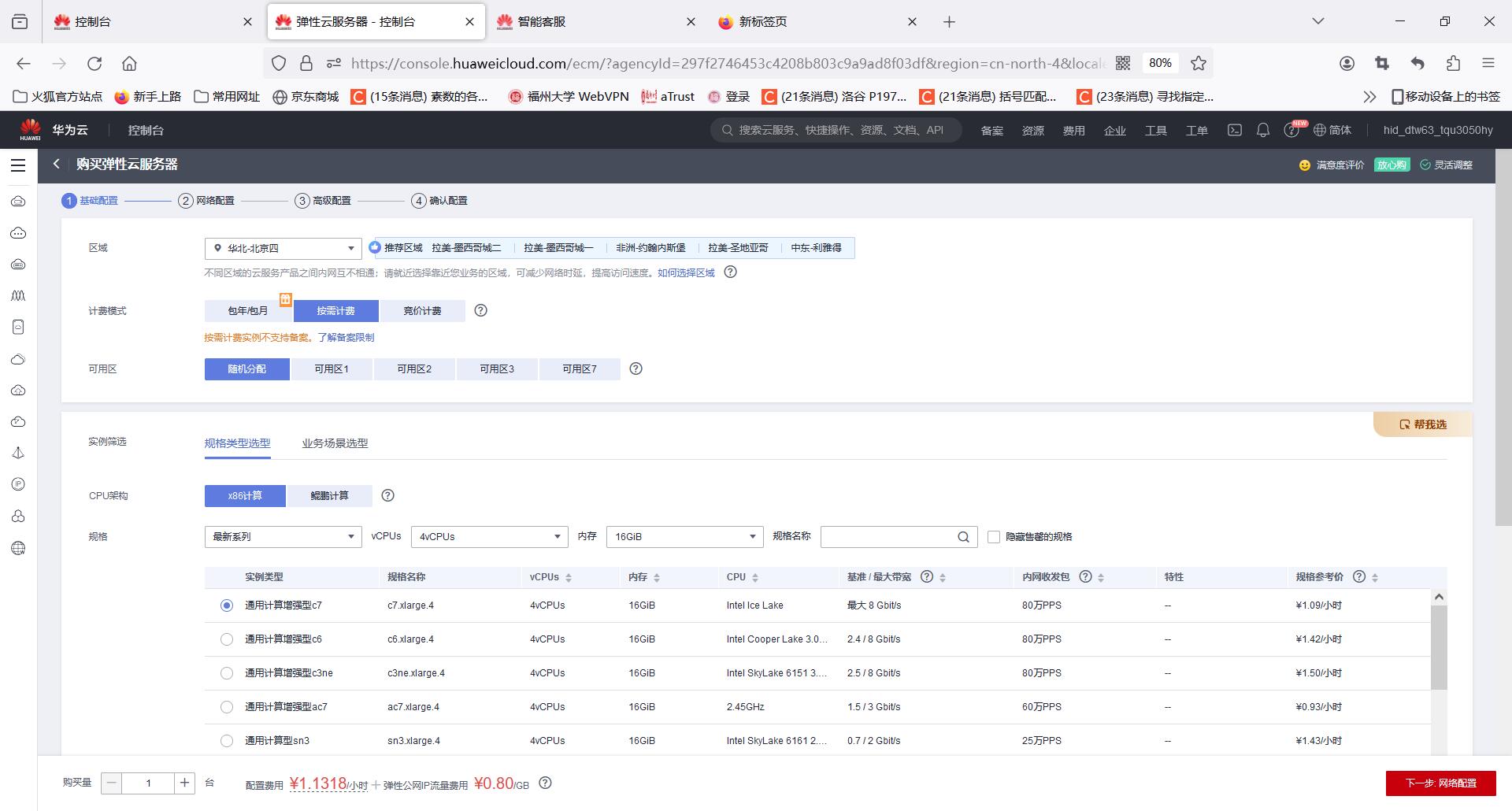


云服务器的尝试是比较失败的,因为硬件问题,速度一直达不到要求,不过还在尝试改进。
总结
本次项目也算是现学现卖,虽然在沟通选题和制作方面讨论了许久,不过还算不错。因为大家能力不同导致分工过程中出现了分歧,常见的重复工作、多次代码重构也有出现但是最后都完美解决了。尤其对冯展同学、吴钦鹏同学在技术上的支持与帮助表示感谢。感谢大家对这次作业的讨论和付出,希望以后有机会能再次配合。